





孙旭
腾讯云数据库专家工程师
腾讯云数据库 TDSQL Oracle 兼容性技术负责人。深耕数据库内核研发十多年,目前主要负责 TDSQL 数据库的 Oracle 兼容能力研发。
近十年来,"去 O 化"是全球数据库行业,尤其是国内数据库领域最关注的主题之一。随着国产数据库的崛起和云原生、分布式计算技术的发展,越来越多的行业和企业开始使用国产数据库替代传统的 Oracle 方案。在这一过程中,国产数据库突破了哪些难关,做了哪些工作,有哪些成功经验分享?
在 2022 年第四期 DBTalk 技术公开课中,腾讯云数据库专家工程师孙旭带来了主题为《只有时代的 Oracle, 没有 Oracle 的时代,看国产数据库如何突出重围!》的分享,对以上问题做出回答。
“去 O”背景简介
1977 年,数据库软件实验室,就是我们后来大家所熟知的 Oracle 诞生,第二年就由人民大学的萨师煊教授把数据库理论引入中国。那时候只有理论还没有正式的产品。1989-1998 年,Oracle 在金融行业和电信行业占比已经比较高了。1999-2012 年,国内就出现了一些国产数据库厂商,如金仓、达梦、南大和神通,开始了早期的去 O 工作。彼时国家也推出了核高基专项,对国产数据库和基础软件的发展都起了非常大的作用。
互联网兴起让 MySQL 成为目前为止非常流行的开源数据库,原因就是 Oracle 太贵了。2013 年到现在,微软、谷歌,Infomix 等国外厂商和阿里云、腾讯云和华为云等国内厂商都推出了数据库产品。中国跟国外数据库的差距也是在逐步缩小的状态。
数据库是比较重要的基础软件,购物、买票等常见应用后台都有数据库支撑。数据库对数据存储、数据安全都起了比较关键的作用,行业普遍认为数据库是基础软件皇冠上的明珠。数据库和操作系统、中间件是三大基础软件,其中数据库起到了“大动脉”的作用。
数据库是计算产业的基础,对性能、稳定性的要求非常之高。现在还有很多数据库天生就是用来做大数据分析的,所以数据库和大数据发展是相互融合的,也是大数据发展之魂。目前国外数据库技术走在前列,所以我们要实现数据库的自主可控,防止技术垄断和卡脖子问题。
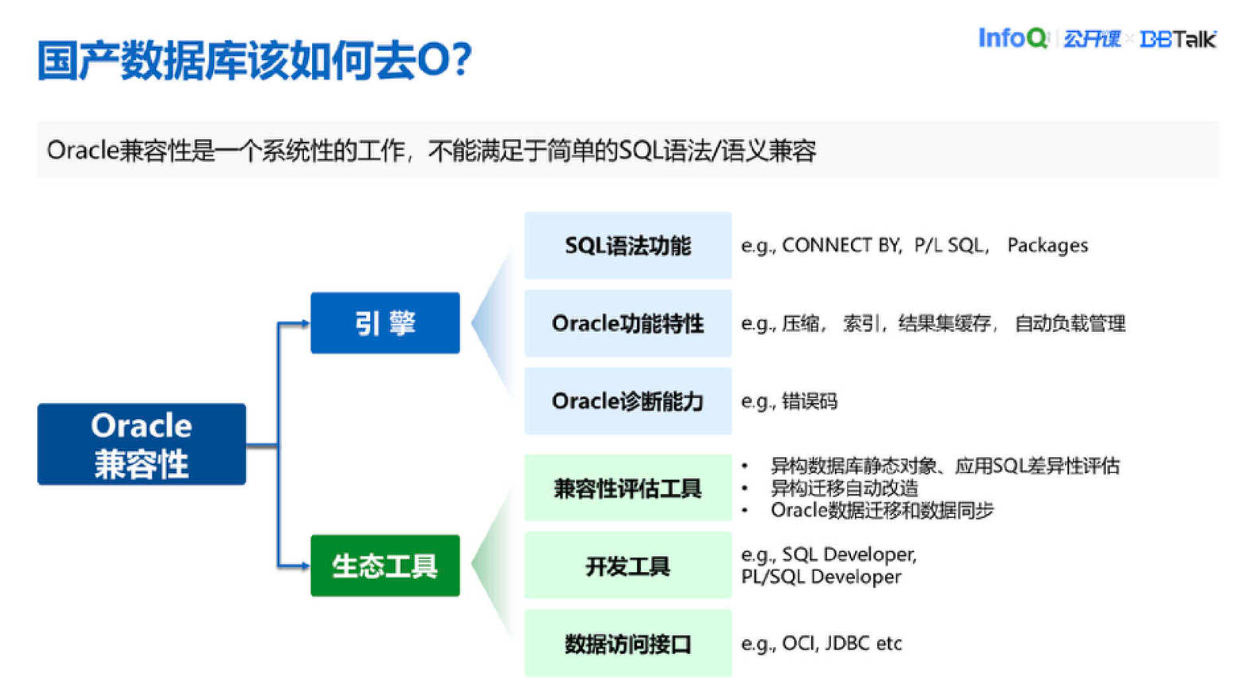
目前 Oracle 在国内市场占比较大,所以我们认为去 O 应该是国产数据库发展的一条道路。去 O 是一个系统性工作,不是简单满足于某一个 SQL 语法兼容或者语义兼容就完成的。从上图可以看到,Oracle 兼容是从引擎和生态工具两方面考虑的。引擎就是数据库内核,有 SQL 语法功能上的兼容,比如说支持层次查询、Packages;还有一些 Oracle 功能相关的,像全局索引、结果集缓存、自动负载,这些我们都会考虑做兼容,因为它跟性能、维护性都联系紧密。还有诊断能力,因为用户会根据 Oracle 的一些数据库反馈错误码去做不同的错误处理,这一块也是我们需要考虑的兼容点。
生态工具比较重要的点是兼容性评估工具的支持,因为去 O 意味着我们需要把用户的应用从 Oracle 迁到我们自己的数据库,这时候就会有数据迁移和同步,并且在这个过程中也要考虑数据库静态对象兼容性和应用 SQL 差异性。还需要考虑对用户友好的一些开发工具,如 SQL Developer。数据访问接口这里主要考虑 ODBC、JDBC、OCI,OCI 的兼容。

TDSQL 的 Oracle 兼容能力如上图所示,从宏观来看 TDSQL 针对 Oracle 兼容所做的事情就是这些。
TDSQL 内核层面 Oracle 兼容能力
先来看 TDSQL 在内核层面对 Oracle 的兼容能力,首先是数据类型。数据类型在数据库里是比较基础的,一般来说数据类型的改变会导致整个应用行为也会产生一些变化。我们在内核里面增加了 Oracle 相关的数据类型,因为原生内核里绝大多数数据类型都做了兼容。
● 数值类型:NUMBER、FLOAT、BINARY_FLOAT、BINARY_DOUBLE;
● 字符类型:CHAR、NCHAR、VARCHAR2、NVARCHAR2、LONG;
● 大对象类型:BLOB、CLOB、NCLOB;
● 兼容了 DATE、TIMESTAMP、INTERVAL 等;
● 其他如:RAW、LONG RAW、BFILE、ROWID、UROWID。
下面看一下 SQL 语法相关的兼容。SQL 语法用的比较多,也比较复杂,所以我们在这里做的工作不少。
● 语法支持:MERGE INTO、CONNECT BY、INSERT ALL/FIRST、FORCE VIEW、PIVOT/UNPIVOT 子句、OFFSET…FETCH子句等;
● 增强了分区功能,例如:MERGE/SPLIT 分区,DEFAULT 分区维护;
● 各种伪列支持:ROWNUM、CONNECT BY 相关伪列 如:LEVEL 等;
● 支持 HINT 功能;
● 同义词、DBLINK、系统函数、系统表支持;
● 空串与 NULL 等价。
还有 PLSQL 语法兼容。用户用 PLSQL 比较多,在我们项目适配过程中有些用户可以达到几十万、上百万行的 PLSQL 语法,所以我们在这里做的工作甚至比 SQL 做的工作都会多一些。
● 存储过程、函数的创建,如:以 IS 作为 PLSQL 块定义开始、可以用/作为定义结束;
● 存储过程、函数支持 COMMIT、ROLLBACK 事务控制;
● 兼容游标属性支持:isopen、found、notfound、rowcount;
● 函数、存储过程支持 OUT 出参;
● 支持集合类型、包;
● 其他 PL 语句支持,如:BULK COLLECT、语句 LABEL;
● 支持预定义的系统包:dbms_output、dbms_assert、dbms_lob、存储过程调试包 dbms_debug 等。
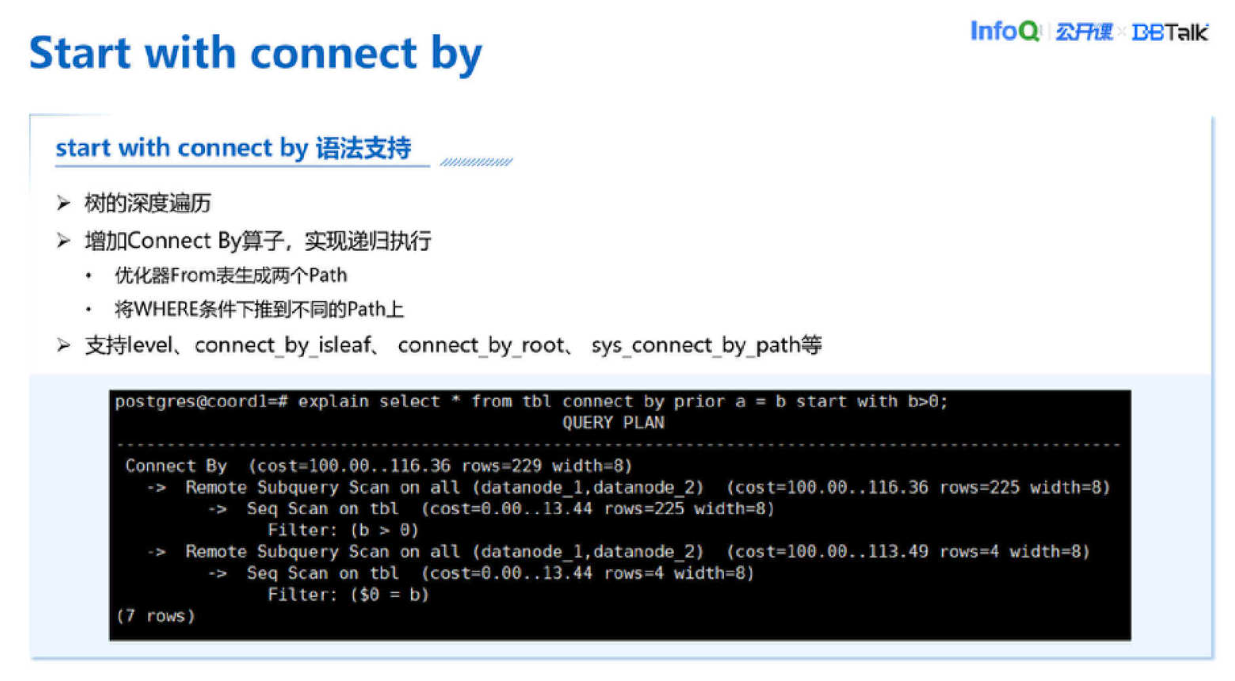
Start with connect by 就是层次查询,在 Oracle 这个层次查询执行后就是把整个数据按照一个树形的结构选择出来。它的执行办法是树的深度优先遍历,就像上图下面这个查询,Connect by A=B 其实就是通过 A=B 递归查询,对这个数进行深度优先遍历。我们在实现的时候增加了一个 Connect By 算子实现递归查询。优化器会对 From 表生成两个 Path,上面这个 Path 会输出这棵树的 Root,就是根元组;下面这个 Path 是一个递归 Path,通过根元组递归调用这个 Path 去把下层结果都输出来,递归算法都在 Connect By 算子里面实现。Oracle 有个比较特殊的地方,在 Connect By 的时候 WHERE 条件会有不同处理,比如 WHERE 里条件如果是涉及两个表,它会先于 Connect By 算子计算,就相当于 push 到 Connect By 下面去做,然后剩下的就可以作为过滤条件。我们支持伪列比较多,层次查询都支持,像 level、connect by is leaf、connect by root、sys connect by path 这些都是支持的;sys connect by path 是函数,它不是个伪列,用于把当前的从根到叶元组路径输出。

MERGE INTO 就是把一个表的数据 MERGE 到另一个表里。我们把 MERGE INTO 实现成一个 LEFT JOIN,就像上图这个例子,MERGE INTO T1 USING 子查询,或者一个表,然后 ON 一个条件。USING 可以认为是一个 source,INTO 是一个目标表,生成这个 LEFT JOIN 就是 source 和 target 表的 join,因为 source 表都要被处理,所以会生成这么一个执行计划。在这里面我们扩充了一个 Modify Table 算子功能,因为之前 Modify Table 是处理 insert、update、delete,就没有 MERGE 功能,所以我们增加一个 CMD MERGE 功能对它扩充。增加 MERGE 之后它会根据 tuple 是否跟 merge 条件 match 选择更新或者删除 tuple。match 的时候更新或删除,不 match 的时候会插入。

上图是 ROWID 和 ROWNUM。ROWID 表示元组物理位置,元组生成完之后它的物理位置或者 ROWID 是不变的。而 TDSQL 中,元组生成后一旦被更新,新元组就会挪到那个位置,它的物理位置其实是变化的。针对这个问题我们做了另一种方式去兼容 ROWID 特性,比如说在每个表创立的时候都会为这个表指定一个序列,ROWID 是由这个序列号组成的,通过这种方式可以完成一个兼容特性,就是更新的时候 ROWID 不变。ROWNUM 对返回记录编号,就像上图下面这个例子。比如说我写一个查询,select ROWNUM from A,它的第一条记录的 ROWNUM 就表示为 1,每出一条记录都会有一个编号。JOIN 也是一样,页面优化器会把查询里所有跟表相关的一些列都下推到下层跟这个表最近的算子上面去执行,所以 ROWNUM 可以认为它不是跟任何表相关的,它是最后去计算的,通过这种方式我们就可以把每条元组进行编号。
分区表我们支持 RANGE、LIST、HASH 分区,以及这些类型的组合分区,也支持多层分区。我们支持分区的单独访问,也支持分区键更新。新增分区后自动维护 DEFAULT 分区是什么意思?如果分好区的时候有元组不属于任何分区,那么它会自动落到 DEFAULT 分区里面。比如说这个分区表里有 10 月份的数据和 11 月份的数据,两个分区再加一个 DEFAULT 分区。如果来了 8 月份或者 9 月份的数据,因为只有 10 和 11 分区,因此 8、9 月份都会在 DEFAULT 分区里。如果我再把 8 月份的分区建起来,内核会自动把 DEFAULT 分区里 8 月份的数据挑出来放到新的 DEFAULT 分区里,这个分区就只剩下 9 月份的数据,这样方便用户对分区的维护。再一个是分区合并和分裂,可能在系统运行过程中分区会变得越来越多,然后有些分区数据可能不会再访问了,分区多的话还可以通过分区合并把一些分区合并成一个分区,比如把老数据或者冷数据都合并,冷数据涉及的多个分区都合并成一个分区。分裂就是就是分区合并的逆操作。分裂和合并还有点不同。合并可以一次把多个分区合成一个分区。分裂只会把一个分区分成两个分区,因为我们分裂的时候只能指定一个分裂点。

下面看一下我们在 PLSQL 里做的一些工作。Oracle 的一个存储过程是用 IS、begin、null、end myproc 这种语法创建的,它的基本特点就是以 IS 作为代码块的起始定义,用/作为结束定义,用 END procname 作为函数代码块结束,还有比如说它可以不用 declare,如果有变量也不用写 declare,等等。TDSQL 之前不是这样的语法特点,就像下面这个例子,它以 AS 作为代码块的起始定义,下面这个 create or replace as 作为定义,$$作为整体代码块定义,下面还有 language plpgsql,这些都不能少,再来一个分号作为定义结束。这样看它的语法结构,大的结构差别还是比较多的。做里的兼容不是说在数据库内核改一下内核代码就能支持的,因为它要在客户端工具做相应的支持。
执行过程中如果是用 PG 的话会有 psql 工具,TDSQL 也是 psql 工具,用这个发送命令给服务器端。psql 处理命令的是 psqlscan.l,它会解析用户输入的语句,然后原生逻辑发一个分号就认为是一个完整的 SQL 语句结束了,它就可以发到服务器。但引入 Oracle 之后这个形式完全不是这样,首先它会把 SQL 进行语法分析过程中判定用户在 psql 输入这一串字符串是不是 Oracle 语法,如果是 Oracle 语法就不会遇到分号就往服务器发,而是等到斜线才认为这是一个完整的命令,可以往服务器里发。这里面我们改动了 PSQL 的 scan.l,改动了一些词法分析行为,做到客户端兼容。TDSQL 内核这一部分也在语法层和词法层做了类似的逻辑。另外 JDBC 里有一个断句逻辑跟 psql 逻辑是一样的,它也要判断这条语句到哪里是一条完整的 SQL 语句,然后发给服务器端,所以我们对那个逻辑也做了兼容适配。
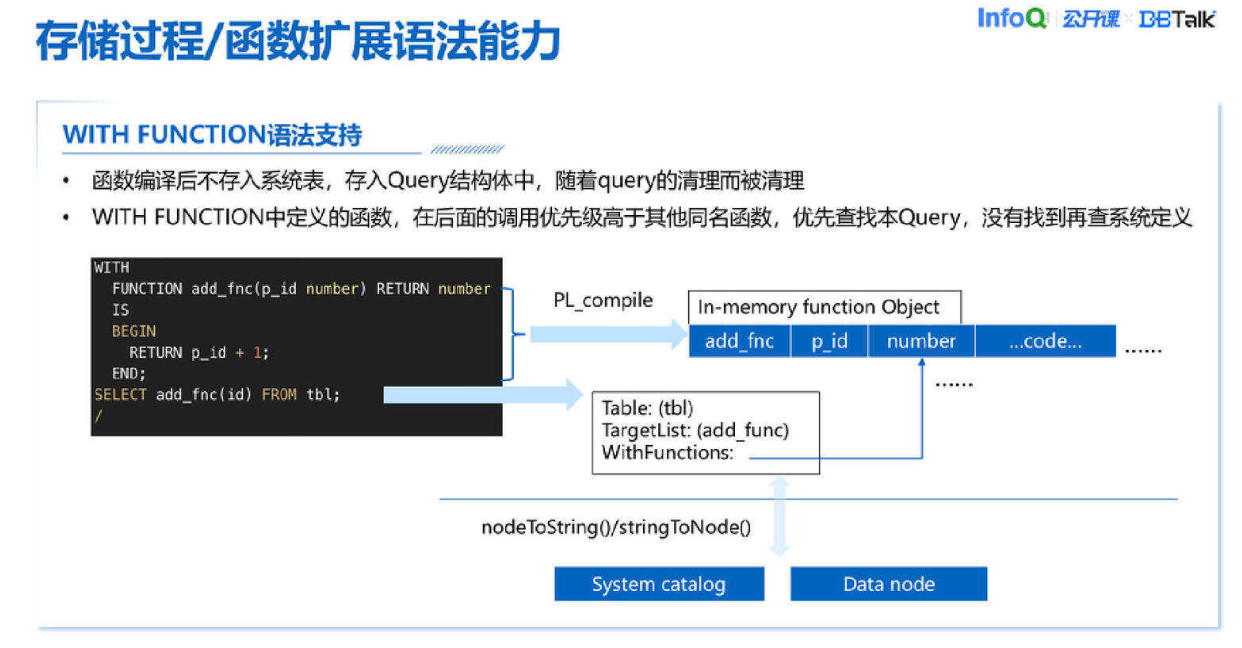
一般来说我们使用一个 FUNCTION 都会用 CREATE FUNCTION,先把 FUNCTION 在系统里定义好再去用。WITH FUNCTION 是不一样的,比如我用 WITH FUNCTION 生一个 FUNCTION,在 SQL 里面可以直接用这个 FUNCTION,而不需要先建函数定义,全部运行完之后也不会在系统里留下任何痕迹。
这个特性是怎么做的?首先 WITH FUNCTION,再来一个 SELECT add fnc(id),首先在内核里它会对 WITH FUNCTION 编译,每次走 PL 编译以及相关的一些 FUNCTION DDL 处理逻辑,然后把它做成一个叫 In-memory function Object 内存函数的对象,放在内存里面。然后在 Query,每一个查询会对应内核里的 Query 结构,在 Query 结构里增加一个 field 去记一下 Query 都有哪些 WITH FUNCTION,通过这种方式把整个数据结构建立起来。在后续 Transform 的时候,因为它要在遍历 TargetList,并解析 add func,这时候它会先在自己的 Query 结构里的 With Function 里去找,找到之后就用 Query 里自己的 Function,如果找不到再查系统表中的函数。通过这种方式我们完成了 WITH FUNCTION 语法支持。
WITH FUNCTION 里还有一个用法,像上图左边黑框里的语句如果是 create view 的一部分,因为 view 也是被编译好放到系统表里,所以我们把 WITH FUNCTION 放到 Query 里,实际上 view 把 Query 序列化,这样 WITH FUNCTION 内存对象就可以随着 Query 一起序列化,并存放到系统表里,所以说这样的话 create view 也会顺利支持 with function。
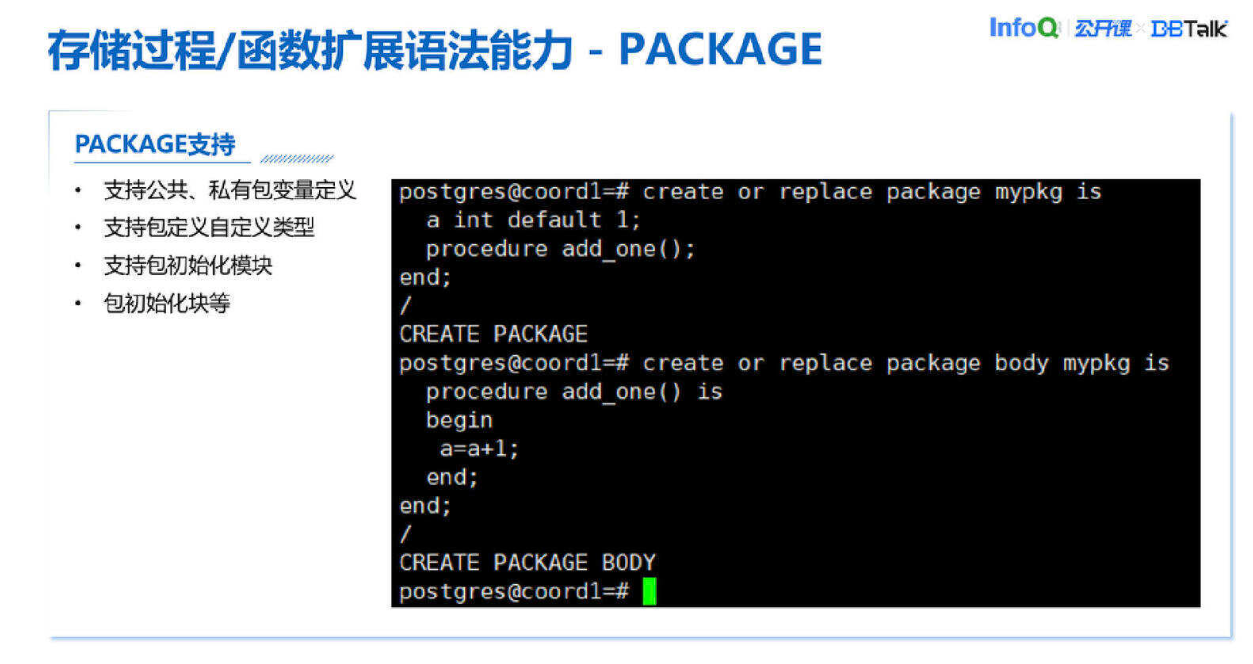
PACKAGE 就是一个变量和函数存储过程的集合,一个包一个集合,所以我们支持公共、私有包变量定义,可以在包里自定义类型,包里面的自定义类型可以用于函数定义、包外函数定义、包内函数定义。我们也可以支持包的初始化模块。第一次访问这个包的时候先初始化,然后把一些变量都初始化再去用。包也可以用在其他 PLSQL 对象里,比如说函数、存储过程都可以使用的。
自治事务是相对来说复杂一些的特性,它跟 PLSQL 相关,但又跟事务管理相关,所以它两方面都会有一些修改。一般数据库执行查询的时候,这个查询是在一个事务里面,并且当前只能执行一个事务,当前这个事务结束之后才能启动另一个事务。自治事务不太一样,比如说当前事务执行的时候,如果当前事务触发了自治事务,我们称它为主事务,它会挂起暂停执行,先去执行自治事务;自治事务执行结束之后主事务再被内核调度恢复起来,接着执行主事务。
自治事务和主事务之间是相互独立的。第一个,它们访问的资源是独立的。自治事务对资源占有到自治事务资源池里面,它不会进到主事务的资源池里面,完全相互独立。并且主事务没有提交的插入元组,因为主事务没有提交,当前它启动自治事务也看不到元组,事务隔离性还是有的,可以认为自治事务也是一个事务,完全符合事务的 ACID 的特性。
自治事务可以用在很多地方,可以支持存储过程、函数、匿名块。我们触发器也可以支持自治事务,在触发器里面可以去声明一个自治事务,跟主事务脱离关系。
驱动层面应用兼容

下面我们看一下驱动层面兼容,这里需要着重说一下 JDBC 的兼容。数据库类型需要考虑 JDBC 兼容,比如更改内核的数据类型行为,或者新增一个数据类型,相应的 JDBC 也要做改动。比如新增一个类型数据库返回的数据之后,JDBC 里面需要封装成 JAVA 对象,如果新增类型 JDBC 的对象可能没有,需要新增。或者是修改一个类型的行为,那 JDBC 对应的 JAVA 对象就要做一些相应的改动,就做一些兼容适配。再一个是适配 Oracle 方式创建函数、存储过程包括 WITH FUNCTION 这些语句,在 JDBC 里面有个断句逻辑,所以我们要保证 JDBC 收到的语句被正确断开,然后发给服务器协调,不能把未处理的发给服务器。
Oracle to TDSQL 迁移
迁移工作有这些问题。迁移工程工作量大,Oracle 用户可能会有几十万百万行的 PLSQL 代码,所以工作量确实非常大。迁移场景比较复杂,兼容程度也不明确,因为系统不知道都用 Oracle 哪些特性,迁移过程中如果没有配合,迁移标准化流程也没法很好地建立起来。所以面对这些问题,TDSQL 提供了一个简单易用的数据库迁移平台,让整个迁移平台化,减少人工工作量介入。我们也提供一些运维和研发经验比较丰富的工程师,负责解决迁移过程中遇到的一些问题。迁移工具能够给出数据库对象兼容报告和应用评估兼容报告,通过可视化报告让用户知道整个迁移过程中可能会遇到的兼容问题。我们在整个迁移过程中评估、改造、迁移、校验,每一步都会有报告输出,迁移工具就已经把流程标准化了。
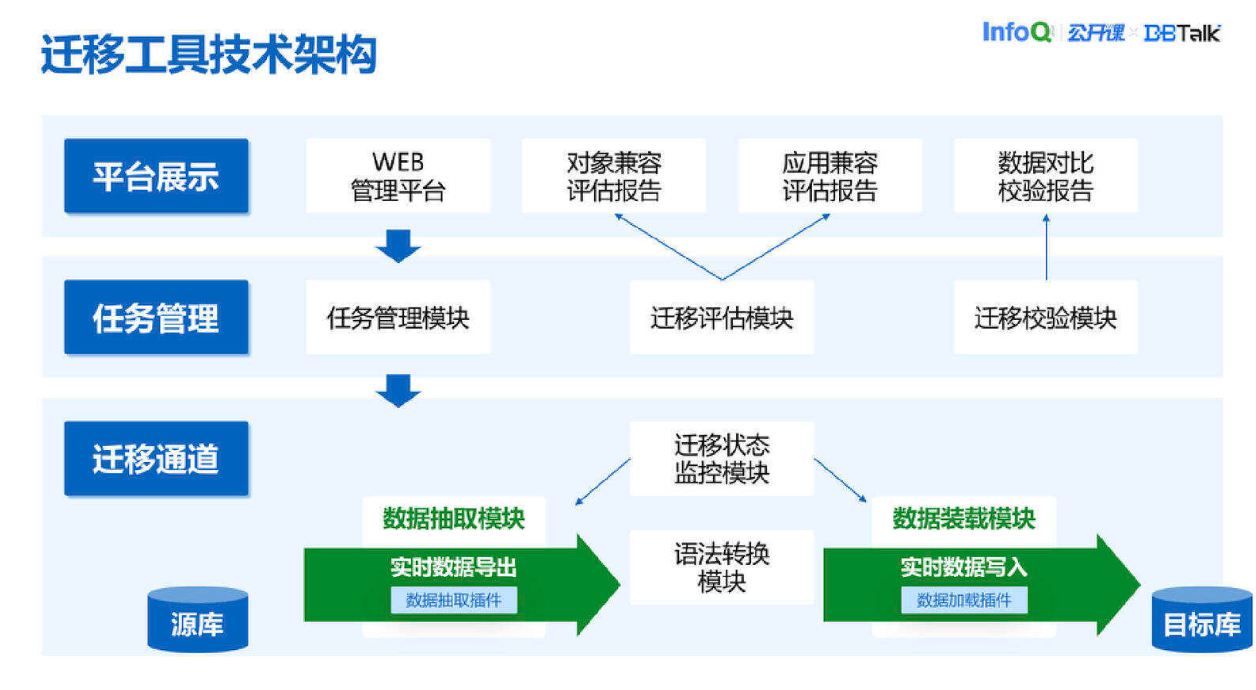
以上是我们迁移工具的技术构架。迁移工具会从源库把数据抽取出来,通过数据装载模块把数据写入到目标库中,在这个过程中我们会有一些语法转换,比如说 DDL 语法转化或者其他一些对象类型的语法转换,这些对象也会写入到目标库中。
兼容性评估第一步是进行数据采集加工,然后再对数据进行分工,输出评估结果。
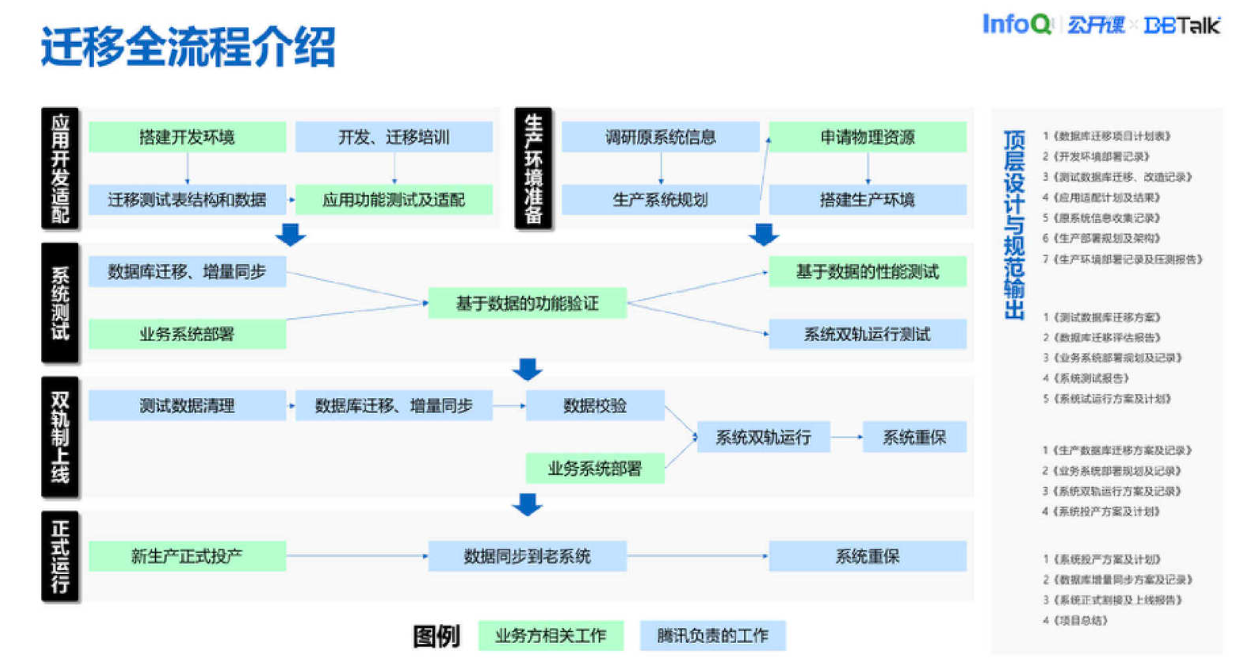
上图是我们迁移的全流程介绍,这里 Oracle 和 TDSQL 两个数据库同时跑,系统双轨运行,给业务一个选择。最后是正式运行,数据同步到老系统,从 TDSQL 同步到 Oracle 这个需要用户决定,我们可以支持把这个数据同步过去。
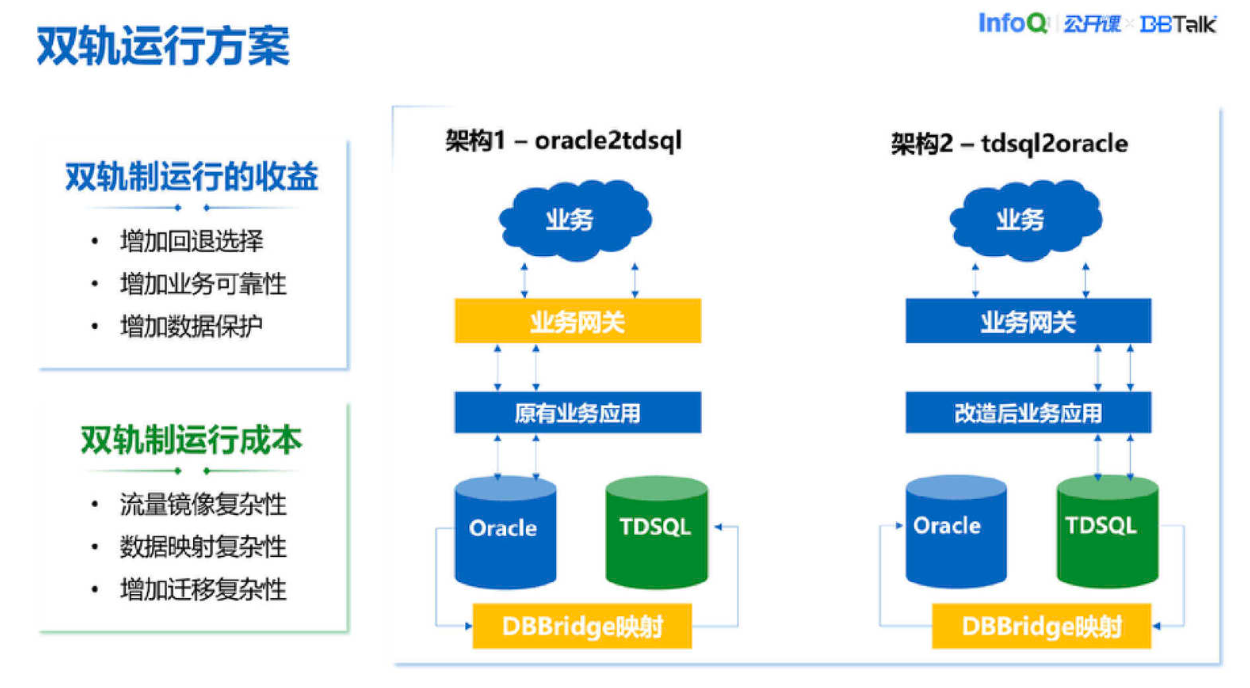
上图就是双轨运行方案,意思是说迁移完之后 Oracle 和 TDSQL 是两套数据库同时运行,业务可以通过开关把相应的流量指向到 Oracle 或 TDSQL。比如说有业务流到 TDSQL,数据可以从 TDSQL 反向同步到 Oracle,Oracle 的数据也可以反向同步到 TDSQL,这样两套系统同时运行,增加业务可靠性,给用户可以回退的选择。这样可能会增加运行成本,比如说镜像流量比较复杂,数据映射也可能会复杂一些,并且需要数据同步。
TDSQL 已经在金融证券、政务、公安系统、保险都有应用。介绍一些案例,第一个是国信证券。它是个 HTAP 混合的应用场景,还有 Oracle 兼容的场景,我们在两个维度对证券 Oracle 应用系统进行适配。案例中存储过程、函数等都比较多,数据容量巨大。我们帮用户平滑迁移,性能也有了很大的提升。第二个案例是阳光保险,做完之后它的效果就是更新表结构效率提升 50%,数据库扩展性也得到提升。由于 TDSQL 兼容能力已经有一些积累,帮助用户业务在短期迁移上线,给用户提供容灾双中心,提升系统的可靠性。第三个案例是某省公安系统,这里面包含治安、党建、人口、缉毒系统,最终的效果是查询速度可以到 3.9W 条/秒,物理节点超过 300 台。
TDSQL 将来会进一步实现 Oracle 深度兼容,也会在性能和稳定性上做更大提升,相信将来用户用到的是一个更好的 TDSQL 数据库。
