





伍旭飞
腾讯云专家工程师
十余年工作经验,在游戏和数据库领域有丰富的开发经验,目前专注数据库内核方向的开发和技术演进。
云数据库 KeeWiDB 是腾讯云自研、100% 兼容 Redis 协议的新一代分布式 KV 存储数据库,实现了数据的冷热分级,满足业务高性能、持久化、低成本、大规模的四大诉求,完美平衡性能和成本之间的冲突。在 2022 年第六期 DBTalk 技术公开课中,腾讯云专家工程师伍旭飞带来了主题为《KeeWiDB 轻 TP 技术实践》的分享,介绍该数据库在 TP 场景中应用的实践经验。
KeeWiDB 特性介绍与 TP 目标
KeeWiDB 兼容 Redis 4.0 集群版的协议,所以从 Redis 4.0 或者 4.0 以下的版本迁移过来几乎完全是无缝的。它还支持命令级持久化,具备大容量的特点,目前单节点达到了 1TB,未来可能会再放开;单集群目前是 128 个集点 128T,对比在云上运营的 Redis 来说,它能承载的数据量要大非常多倍。因为 KeeWiDB 是一个存储型的数据库,所以它的数据大部分是存储在磁盘上,成本比 Redis 低非常多。因为这个产品主要面向传统 Redis 客户的痛点,所以也具备 Redis 高性能、低延迟的特征。
Redis TP 的现状是把命令压到 server,但是先不执行,等到 Exec 这条命令收到的时候,server 再去执行,保证了原子执行。在这个执行过程中不会被别的命令打断,因为 Redis 架构其实是单线程的数据逻辑。
还有一个办法是通过 Lua 这样一个脚本语言,把代码先在 Redis 里编译好,再把参数传过去,在 Redis 那端,server 端通过 Lua 也是原子执行,中间不会被别的命令插进来打断。但这个方法其实还是有很多问题,首先不能真正保证原子性。真正的原子性是说事务要么执行要么不执行,无论是 Multi 或者 Exec 这种组合模式,还是 Lua 方式。如果在过程中执行,比较常见的一个错误是类型错了,当场就会把整个操作终止,但已经执行过的命令是不会回滚的。执行到一半了,一半的数据被改,剩下一半没有执行,这是一个比较常见的情况。另外持久化能力也是没有的,达不到客户对真正的存储型数据库的要求。
KeeWiDB 作为一个数据库,一定要实现 TP 的能力。我们的目标是高吞吐、低延迟,因为大部分客户对吞吐和延迟的要求是非常高的。Redis 单节点吞吐一般在 10 万以上,我们可以达到 14 万甚至更多。KeeWiDB 的延迟目标是在 3 到 4 毫秒这个区间。我们还支持事务的一些语义。
轻 TP 研发实践介绍
我们并没有想到要做这个数据库,就马上把这些可选的技术拿过来直接去用,我们还是分析一下这个存储模型该怎么做?因为 KeeWi 是要接入 Redis 数据库的,那么传统的数据库存储模型是怎么样的?
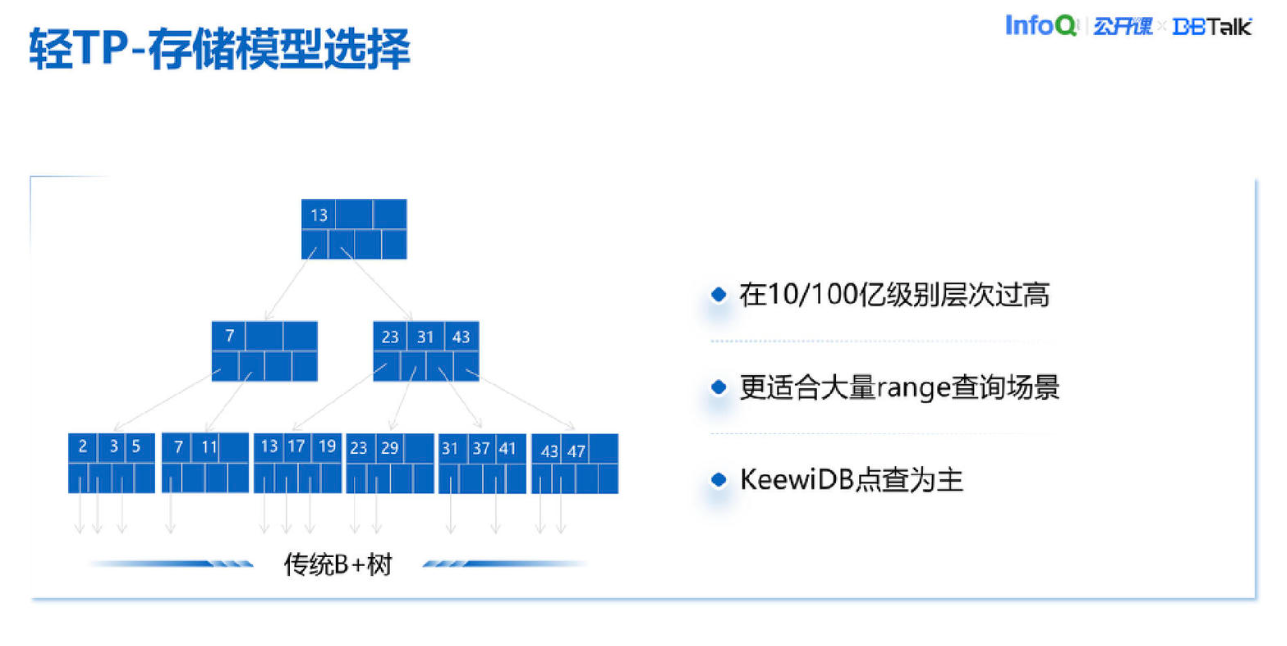
首先来看一下传统像 MySQL 这种 B+树或 B+树的派生这类数据库,我们评估一下觉得不适合。因为我们的用户数量是非常多的,我们迁过的一个客户实例单节点上百亿级别的数量,把这样的数量如果放到一个 B+树里,层次会非常高。B+树的优点是更适合大量 range 查询的场景,这个优点在我们这里没有那么重要,或者客户在大概率情况下是没有可感知的优势的。
我们的场景是点查点写为主。从这个角度来说,如果使用 B+树会把它的缺点暴露,但是优点却没有拿到,所以我们觉得不能直接盲目地采用这样一个存储模型,虽然它在历史上很成功,主流 SQL 数据库都是用这个。
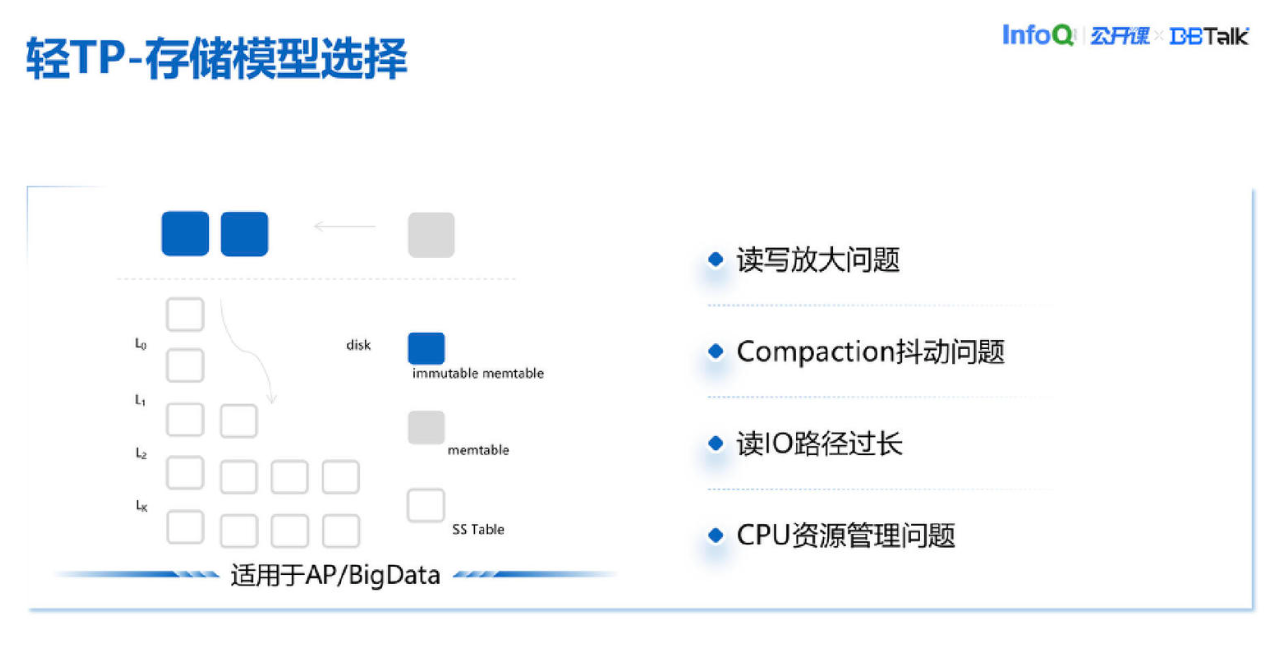
还有比较常见的一个模型是 RocksDB,这里用 LSM Tree 来指代。目前看大部分的nosql数据库都是用 RocksDB 来做 KV 上面的封装。但这个存储模型也会带来一些问题,首先它的读写放大比较严重,像 KeeWi 的目标场景热点客户其实数量是有限的,会反复地去写入的。在这种情况下我们的写放大还是挺大的。
运营中,包括我们和友商都发现另外一个致命问题,它的 Compaction 抖动非常明显。我们作为云厂商是要装箱的,装箱之后每个实例给多少资源是非常讲究的。一般来说会在给用户承诺资源之上,额外多一点资源,主要是应对 Compaction 抖动。但这个问题没有那么好处理,经常 Compaction 抖动起来会超过我们的预期。它是与生俱来的,是跟着整个 LSMtree 这样一个模型天然存在的。紧急情况下一般只能放 CPU,CPU 加大是一个临时方案,但这个方案在运营上对我们会有很大困扰,CPU 资源管理也会有很大的挑战,不同客户之间因为临时调资源甚至会有互相影响,CPU 隔离的规则也很容易被打破。所以这个模型我们最终也没有采用。
Redis 本身是 Hash 为主的数据结果,我们在想能不能用 Hash。Redis 自身就是一个静态 Hash,就是它的 Hash 表扩充的时候是 double 上面那一层索引层的。内存级的 Redis 在 double 的消耗也是非常大的,也会经常因为 ReHash 导致更多消耗。Redis ReHash 上面那一层的数据结构,索引层那一层是要 double 的,可能 double 一下分配几百兆,这个分配本身也是耗时的,所以静态 Hash 方式依然是不可取的。
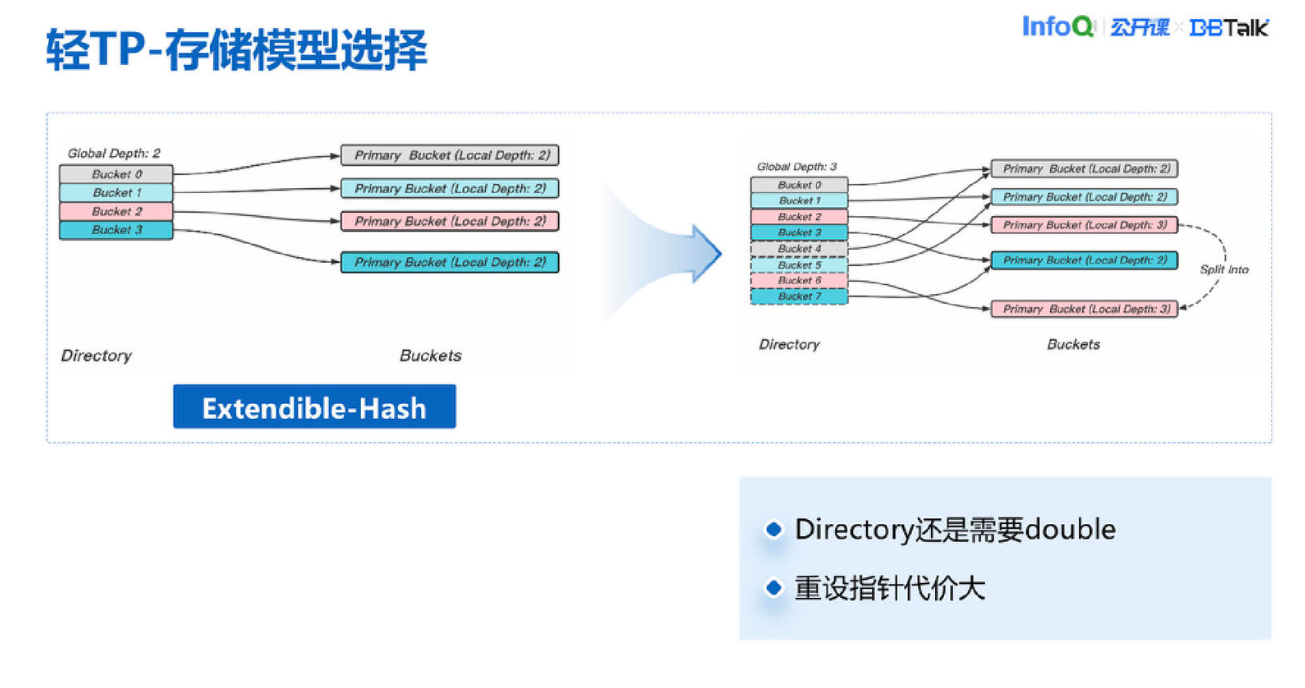
动态 Hash 在业界有不少方案,比如 Extendible Hash 是比较常见的动态 Hash。这个 Hash 我们评估下来还是有一个问题,在 Directory 这一层的时候还会有 double,在几百亿这样一个场景下,本身的 Directory 也会非常大,如果需要去连续并且 double,这个消耗也是不可接受的。

还有一个动态的 Linear Hash,它的扩充会有一点不一样。举个例子,假设一开始只有两个比特位的 Hash 大小,只有 00,01,10,11,在这个时候我们都是把 Hash code 与运算 11 得到桶的位置再插到对应的位置。扩充是怎么扩充?当不够的时候,一般是 overflow 过长这种情况,linear hash 是一次只加一个,比如在两位的基础上再加一个桶 100,100 固定从 000 前面的 bucket 里面,把数据按照 Hash 规则,大概插一半就到 100。它是一个渐进式的 Hash,即使是在索引这一层,它也是一次只加一个,这就会给我们带来很多优化空间。
IO 路径和数量无关就是对比 B+树的一个优势。我们后面其实都是一个比较固定的复杂度,IO 链路的长度固定,在点查这个场景它是天然适合的。它的扩展也是比较平滑的,而且兼容 Redis 所有的协议非常方便。我们选用一个合适的数据结构,既要有它的优点,又能够在兼容性上做得非常好,就是它了。
另外,编程模型怎么做?我们是一个新的数据库,没有特别多的负担。典型的选项就是 MySQL 单进程多线程。举个例子,最常见的就是每连接一线程,这个线程就处理连接的 SQL 请求,然后同步去编程,有 IO 的时候等一下,类似的有其它锁也等一下。在等的时候,这个线程把 CPU 调度出去。用的锁基本是 System 的 Mutex 锁或者还有一些可能会用 spinlock 自旋锁。
这个形态对 CPU 的数量要求是比较高的。很多数据库都会面临的一个问题是对线程和 CPU 消耗比较大,而且系统切换比较频繁,遇到 IO 就会切换。它对编程的要求比较高,稍不留神就可能死锁,如果是 spinlock,CPU 也会打非常高,有时候写得不好会导致不可用,所以这样一个模型的优缺点是比较明显的。
还有一种是 PG 多进程这样,但是我们是单线程。它的编程确实挺简单,代码可以写得比较清晰好看,比较典型例子就是 PG 数据库。编程也是一样同步编程,收到请求之后一条路走到黑,遇到 IO 就等。进程间共享内存是在 cache 上来做锁,像 PG 有 lightweight 锁,还有 spinlock,核心还是基于共享内存的变量来做锁。这个锁其实一样对 CPU 的消耗很大,而且多进程的管理方式会有很大问题。我们的客户经常会有成千上万个链接,如果这个时候突然要起上万个进程,对我们的管理、资源的分配都是一个非常大的挑战,所以我们觉得这种方式也不是很完美。
还有一条路,单进程但是多线程,我们在一个线程内会做多协程这样一个框架。这个思路是怎么样的?最开始我们想到 Redis QPS 在纯粹的内存级别是非常高的,十几万甚至百万都有可能达得到。为什么能达到?主要是因为单纯内存运算是非常快的。但我们是一个存储型数据库,不能直接按照 Redis 单进程单线程的架构,因为这样做,等待 IO 的时间会占大部分,导致 CPU 根本没办法有效利用起来。
所以我们在用的多协程架构,比如在处理一个请求,哪怕是一个线程内在读取 IO 的时候,走的是异步编程模型,所以 CPU 会让出去,让到别的协程去调度,充分把 CPU 利用起来。因为是协程,这里协程是用的 C++20 的协程机制。
我们用这个方法还有一个动机是我们不想写 Mutex 锁,我们不希望有线程系统锁、有系统的信号量这样一些东西。我们完全是无锁编程,没有任何系统锁。但是逻辑上的数据库层面锁依然还需要。数据库层面锁是什么意思?比如两个连接可能同时访问同一个 key,同时写,这种情况下还是会有数据库层面这个锁存在的。这个锁我们用的什么?因为我们是一个单线程多协程的,我们没办法用 Mutex 这样的系统锁,用了就会把整个线程卡住了。我们用的是协程锁,并不是系统锁,而是纯粹在用户态的一个锁,是不会把整个线程卡住的,也不会出现在用户态和系统内核态之间的一个 context 切换的代价,所以我们最终在这个点上是采用了这样的设计。
前面解决了存储模型也解决了编程模型的设计问题,我们在想要不要实现分布式事务。我们分析下来,其实主流的实现基本都是参照谷歌论文实现的,一般是在 Proxy 或者在客户端实现,是按两阶段提交的。我们前面讲过,我们这个数据库是兼容 Redis 4.0 集群版的,如果用这样的一个分布式事务,延迟至少多了一次或者多次网络交互,依然还是会有很大的影响。
另外在场景上,我们的用户用的是社区开源库来作为客户端框架连接,如果是用社区的 Redis 4.0,它本身对分布式诉求没有那么大。但在集群版场景下都是要求操作的单条命令的多个 key 都是在同一个 slot 上,在 KeeWiDB 这里也是一样,和 Redis 类似,也是存储在一个相同节点上,不存在数据分布情况。所以在目前客户需求和用户场景下,我们暂时没有支持分布式事务。
单机的事务是怎么实现的?因为我们是一个新的数据库,这些细节都是要自己考虑。事务的实现依然是用了两阶段封锁,在 Key 级别的封锁这样一个策略,和其它数据库也差不多。但是我们的锁在编程模型里提到过,用的是协程锁,避免了系统切换,实现了真正的无锁编程。在 DB 级别还是有flushDB 这样一些操作,还是有一个意向锁。意向锁概念跟传统数据库差不多。
隔离级别这里怎么处理?Redis 其实不存在这个问题,因为它就是标准的一条一条来顺序执行,所以它的隔离级别是最高的。我们目前是要实现命令级持久化,在存储级的数据库实现的级别是 Read Committed 级别,只要提交了就可以读到。在这里我们跟传统数据库有一点不一样,没有用 MVCC 这样一个技术手段,主要是想缩短读 io 的路径,降低复杂度避免了多版本 gc 等其他操作。
根据上面的一些方案我们把这个数据库做出来之后,延时这里我们还做了哪些工作来优化?除了前面讲的无锁协程,还有像传统数据库提交部分的一些优化,比如组提交,组提交可以减少在日志持久化这个地方的一些消耗,我们还引入了软硬一体化的持久内存来降低延迟。持久内存的速度是远远超过我们磁盘的,持久化一次基本就是一微秒左右,有了这个加持之后才能够真正做到 P100 在 10 毫秒以下,P99 在 2 到 3 毫秒左右这样一个水平,单节点的 QPS 能到十几万甚至二十几万。
回顾一下,我们从存储模型、编程模型和事务的一些策略的选择上,做了一些最适合 KeeWiDB 应用场景的优化,再把通用的优化技术加入进来,最后再加上新硬件的加持,这样我们才有信心做出高性能、低延迟、低成本的数据库。
KeeWiDB 其他能力解读
顺便再讲一下其它的一些能力。作为一个云上数据库,我们的扩容能力是一个标准能力。我们把它叫做 3D 扩容。首先我们支持单个节点纵向扩容,也支持集群水平扩容,扩容过程对用户无感知,他不会感受到有错误这些东西,只是在切换那一瞬间会有几十毫秒的延迟,我们觉得基本是比较极致的水平。
在数据安全这块,首先我们的主从模式会支持多种模式,有的客户会喜欢偏性能型的,对数据安全的要求没有那么高,这个时候我们可以让用户选择一个异步同步的模式,性能会更高一些,延迟会更低一些。如果对于数据安全要求很高,比如金融场景、电商的一些核心场景,可以采用半同步或者全同步这两个模式,客户可以根据自身的长期业务场景和重要性来选择。
除了刚讲的单个实例级别之外,我们还在 AZ 级别支持多 AZ 部署,我们会经常演练,可以在更高层面去保证用户的数据可靠性。
