




导语|Elasticsearch 8.x 引入了强大的向量搜索功能,使得在大规模数据集上进行高效的 k 近邻(kNN)搜索成为可能。向量搜索在许多应用场景中都非常重要,例如 RAG、推荐系统、图像搜索等等。本文旨在深入浅出地剖析 Elasticsearch 8.x 的 kNN 搜索和混合搜索功能,介绍其实现原理和关键技术点。同时,我们还将解读腾讯云 ES 对社区做出的相关贡献,通过源码级别的解读,帮助读者更好地理解和应用 Elasticsearch 的向量搜索功能。
kNN 查询流程分析
熟悉 Elasticsearch 的朋友对查询的几个阶段一定不陌生:Query Phase 和 Fetch Phase。
这两个 Phase 是 query_then_fetch(默认的search_type)会产生的两个阶段。而另一个 search_type,dfs_query_then_f-etch,顾名思义,它的阶段分为三个:DFS Phase,DFS Query Phase 和 Fetch Phase。
{"error": {"root_cause": [{"type": "illegal_argument_exception","reason": "cannot set [search_type] when using [knn] search, since the search type is determined automatically"}],"type": "illegal_argument_exception","reason": "cannot set [search_type] when using [knn] search, since the search type is determined automatically"},"status": 400}
可以看到提示 kNN 搜索有固定的 search_type。在 Elasticsearch 的源码中可以看到 kNN 查询会必然分配 DFS_QUERY_THEN_FETCH 的查询模式。org.elasticsearch.action.search.TransportSearchAction#adjustSearchType
static void adjustSearchType(SearchRequest searchRequest, boolean singleShard) {// if there's a kNN search, always use DFS_QUERY_THEN_FETCHif (searchRequest.hasKnnSearch()) {searchRequest.searchType(DFS_QUERY_THEN_FETCH);return;}...}
在传统的 BM25 类搜索中,分布式频率统计(Distributed Frequency Statistics,简称 DFS)阶段,系统会在实际执行查询之前,从所有的分片中收集额外的信息,这个阶段的目的是为了使得 score 更加准确。由于每个分片都是独立的,它们只知道自己的局部数据,没有全局视图。对于文档的评分可能会因为分片内部的因素(如逆文档频率 Inverse Document Frequency,简称IDF),分片无法准确计算 IDF,这可能导致跨分片评分不一致。通过 DFS 阶段,可以收集这些分片特有的统计信息,以便在后续的查询阶段能够更公平地比较来自不同分片的评分,确保评分的准确性和一致性。
而在 kNN 查询中,DFS 阶段的目的则略有不同。由于 kNN 搜索依赖于向量空间中的距离计算,而不是基于文本的词频统计,DFS 阶段在这里的作用是从每个分片中收集最佳的 k 个候选结果。这些候选结果随后会被合并,以确定全局最佳的k个结果。然后,这些全局最佳的 k 个命中结果会被传递到 DFS Query Phase。
private void executeKnnVectorQuery(SearchContext context) throws IOException {...List<KnnSearchBuilder> knnSearch = context.request().source().knnSearch();List<KnnVectorQueryBuilder> knnVectorQueryBuilders = knnSearch.stream().map(KnnSearchBuilder::toQueryBuilder).toList();...List<DfsKnnResults> knnResults = new ArrayList<>(knnVectorQueryBuilders.size());for (int i = 0; i < knnSearch.size(); i++) {...// 构建并执行向量查询Query knnQuery = searchExecutionContext.toQuery(knnVectorQueryBuilders.get(i)).query();knnResults.add(singleKnnSearch(knnQuery, knnSearch.get(i).k(), context.getProfilers(), context.searcher(), knnNestedPath));}context.dfsResult().knnResults(knnResults);}
DFS Phase 会将合并后的候选结果,传递到下一个阶段:DFS Query Phase。
org.elasticsearch.action.search.SearchDfsQueryThenFetchAsyncAction#getNextPhase`
@Overrideprotected SearchPhase getNextPhase(final SearchPhaseResults<DfsSearchResult> results, SearchPhaseContext context) {final List<DfsSearchResult> dfsSearchResults = results.getAtomicArray().asList();final AggregatedDfs aggregatedDfs = SearchPhaseController.aggregateDfs(dfsSearchResults);// 合并每个分片收集到的最佳的k个候选结果final List<DfsKnnResults> mergedKnnResults = SearchPhaseController.mergeKnnResults(getRequest(), dfsSearchResults);return new DfsQueryPhase(dfsSearchResults,aggregatedDfs,mergedKnnResults,queryPhaseResultConsumer,(queryResults) -> new FetchSearchPhase(queryResults, aggregatedDfs, context),context);}
DFS Query Phase 则会通过 KnnScoreDocQueryBuilder 构建候选结果的评分查询。
ShardSearchRequest rewriteShardSearchRequest(ShardSearchRequest request) {...for (DfsKnnResults dfsKnnResults : knnResults) {List<ScoreDoc> scoreDocs = new ArrayList<>();// 拆分DFS阶段合并后的结果for (ScoreDoc scoreDoc : dfsKnnResults.scoreDocs()) {if (scoreDoc.shardIndex == request.shardRequestIndex()) {scoreDocs.add(scoreDoc);}}...// 携带DFS阶段的结果构建评分查询QueryBuilder query = new KnnScoreDocQueryBuilder(scoreDocs.toArray(new ScoreDoc[0])).boost(source.knnSearch().get(i).boost()).queryName(source.knnSearch().get(i).queryName());...subSearchSourceBuilders.add(new SubSearchSourceBuilder(query));i++;}source = source.shallowCopy().subSearches(subSearchSourceBuilders).knnSearch(List.of());request.source(source);return request;}
尽管 DFS 阶段的原始设计目的是收集词频信息,kNN 搜索实际上并没有这个概念,有点“货不对板”。但 DFS 阶段基本思想是收集和合并全局信息,kNN 搜索也有这个需要。因此,Elasticsearch 选择在 DFS 阶段进行 kNN 搜索的全局向量信息收集和合并操作。
目前,我们了解了 kNN 搜索会在:
1. DFS Phase:使用 KnnVectorQuery-Builder 构建分片级别的向量查询,利用 HNSW 算法来快速找到与查询向量最近的文档向量,最终再全局归并。HNSW 算法本篇不作分析。
kNN 功能分析
GET hybird_test/_search{"query": {...},"knn": {"field": "vector","num_candidates": 5,"k": 5,"query_vector": [...]}}
private List<KnnSearchBuilder> knnSearch = new ArrayList<>();
引入了和 query 子句平级的 kNN 子句后,一次 DSL 查询会“兵分多路”,这就是我们所说的混合搜索,Elasticsearch 8.x 的版本支持原生的混合搜索,这是众多向量数据库所不能及的。混合搜索结合了 BM25 和向量搜索各自的优势,实现了比 BM25 搜索的召回更具语义性,比向量搜索的召回更加精准。
GET hybird_test/_search{"size": 5,"query": {"bool": {"must": [{"match": {...}},{"knn": {"field": "vector","num_candidates": 5,"query_vector": [...]}}]}}}
Query 中 KNN 查询也不再使用 DFS 阶段进行近邻搜索,收集全局信息。
进行 kNN 搜索的首选方法是使用顶层 kNN 查询。Query 中的 KNN 查询作为 ES 支持的能力,只做介绍不做展开。腾讯云 ES 刚刚发布了 8.13.3 版本,也自然支持了这个专家级的功能。
RRF 分析
Reciprocal Rank Fusion(RRF)是一种融合算法,用于将多个查询结果进行融合,以提高搜索结果的准确性。RRF 的基本原理是对每个查询结果进行排序,并根据排名分配权重,最终将各个查询结果的权重进行累加,生成融合后的结果。
RRF 的数学公式如下:
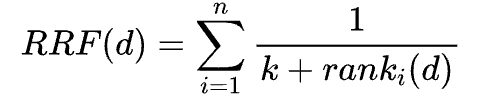
GET hybird_test/_search{"query": {...},"knn": {...},"rank": {"rrf": {"window_size": 100,"rank_constant": 60}}}
RRF 算法只采用了各路召回的排名,不关注得分,启用了 RRF 的查询会抹除过程中的所有得分信息,最终只保留融合后的排名。
不知道融合结果中每个文档的具体得分,也就无法知道融合后的结果来源于哪路召回,查询过程就“黑盒化”了,查询分析会受到很大阻碍。RRF 查询结果示例:
{..."hits": {..."hits": [{"_index": "hybird_test","_id": "999006","_score": null,"_rank": 1},{"_index": "hybird_test","_id": "999005","_score": null,"_rank": 2}]}}
RRF 功能增强
笔者通过提交 issue 与社区讨论,得出了最短改造路径:通过“命名查询”(Named queries)的实现方式。命名查询通俗讲,允许对 DSL 的查询子句命名,从而从最终结果中得到已命名子句的匹配信息,包括命中、子句的具体得分情况。
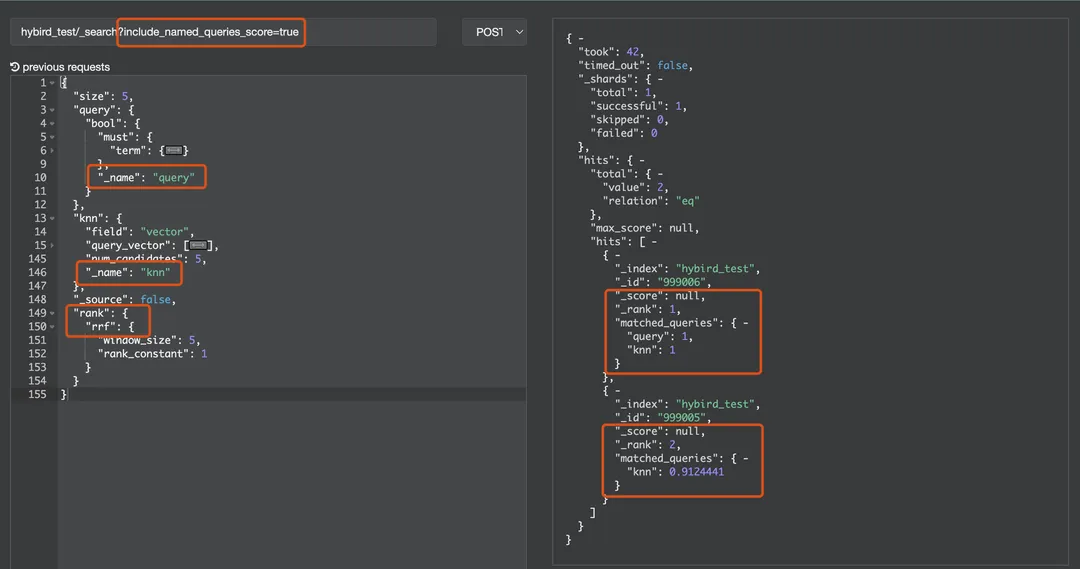
功能实现后,开启 RRF 的混合搜索的效果如下,可以在 matched_queries 中直观看到召回文档来源于哪路搜索:
{..."hits": {..."hits": [{"_index": "hybird_test","_id": "999006","_score": null,"_rank": 1,"matched_queries": ["query","knn"]},{"_index": "hybird_test","_id": "999005","_score": null,"_rank": 2,"matched_queries": ["knn"]}]}}
通过 _search 中指定 include_named_q-ueries_score=true 参数,还可以获得各路搜索的具体得分:
{..."hits": {..."hits": [{"_index": "hybird_test","_id": "999006","_score": null,"_rank": 1,"matched_queries": {"query": 1,"knn": 0.9124442}},{"_index": "hybird_test","_id": "999005","_score": null,"_rank": 2,"matched_queries": {"knn": 1}}]}}
由于 Query 中 kNN 查询和传统DSL子句有着一样的使用方式,在源码中也是直接继承了传统 DSL 子句的命名查询的能力:org.elasticsearch.index.query.AbstractQueryBuilder#queryName(java.lang.String)。
所以功能改造任务就简化为,只需实现顶层kNN查询的 queryName 功能,也就是在 DFS 阶段和 DFS Query 阶段,让 kNN 查询支持并有效传递 queryName。
得益于 Elasticsearch 源码优良设计和复用能力,这一改造最终简化为 3 点:
● 将 _name 字段添加到 KnnSearchBuilder 中。
● 修改序列化以包含 _name 。
● 确保 _name 在跨阶段的查询执行期间得到处理并包含在响应中。
笔者按照以上思路完成开发和测试验证,提交了 PR,最终这一功能也被社区所采纳。
该功能已贡献给社区,按 Elasticsearch 官方的计划,将会在 8.15 版本进行功能的发布。
而腾讯云 ES 自发完成了该功能的提出与实现,在腾讯云 ES 新发布的 ES 8.13.3 版本,和 8.11.3 的新内核版本上,均能提前使用到该功能特性。
腾讯云 ES 也率先将该功能特性服务于内部微信某平台的客户,快速支持了客户业务的顺利上线。
总结
关注腾讯云大数据公众号
邀您探索数据的无限可能

点击阅读原文,了解更多相关产品详情
↓↓↓
