




可观察性平台类似于免疫系统。就像免疫细胞在人体中无处不在一样。可观察平台会巡逻设备、组件和架构的每个角落,识别任何潜在威胁并主动缓解它们。然而我这个比喻可能有点过分了,因为直到今天,我们还没有发明出像人体一样复杂的系统,但我们总能取得进步。
升级可观测平台的关键是提高数据处理速度、降低成本。这是基于两个原因:
从数据中识别异常的速度越快,就越能遏制潜在的损害。
可观测性平台需要存储大量数据,而低存储成本是实现可持续发展的唯一途径。
关策数据库
GuanceDB 是一个全方位的可观测性解决方案。它提供包括数据分析、数据可视化、监控警报、安全检查等服务。从 GuanceDB 中,用户可以了解其对象、网络性能、应用程序、用户体验、系统可用性等。
从数据管道的角度来看,GuanceDB 可以分为两个部分:数据摄取和数据分析。我将一一了解它们。
数据整合
对于数据集成,GuanceDB 使用其自制工具 DataKit。它是一款一体化数据收集器,可以从不同的终端设备、业务系统、中间件和数据基础设施中提取数据。它还可以预处理数据并将其与元数据关联起来。它为数据提供广泛的支持,从日志、时间序列指标到分布式跟踪数据、安全事件以及来自移动应用程序和 Web 浏览器的用户行为。为了满足多场景的多样化需求,它保证了与各种开源探针和收集器以及自定义格式数据源的兼容性。
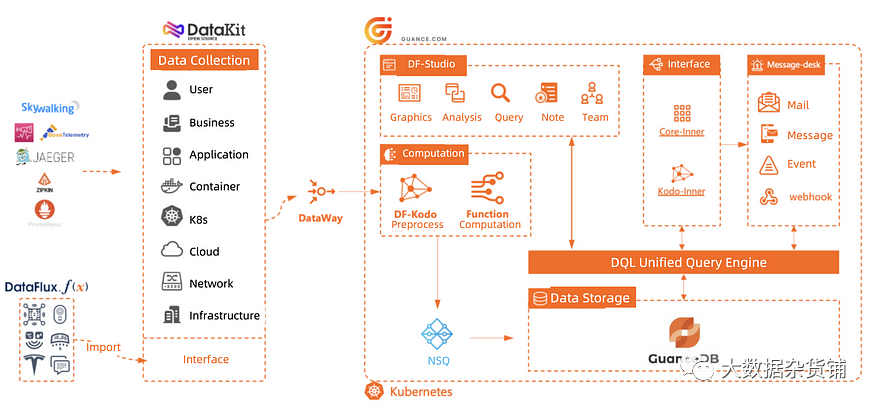
查询和存储引擎
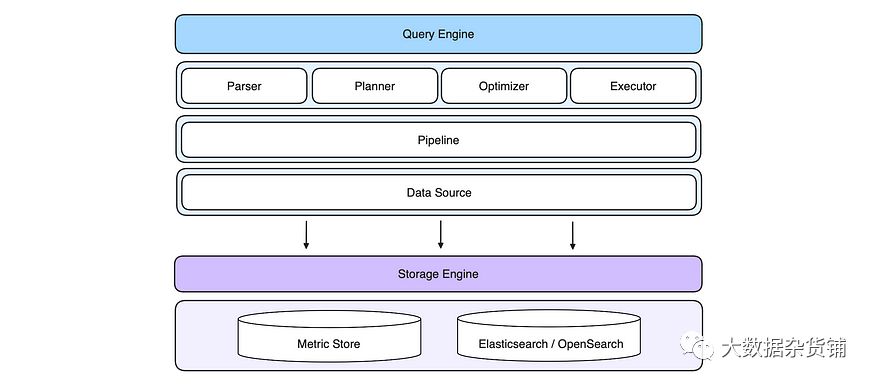
数据写入:Elasticsearch 消耗大量 CPU 和内存资源。它不仅成本高昂,而且还会破坏查询执行。 无模式支持:Elasticsearch 通过动态映射提供无模式支持,但这不足以处理大量用户定义的字段。在这种情况下,可能会导致字段类型冲突,从而导致数据丢失。 数据聚合:大型聚合任务经常会在Elasticsearch中触发超时错误。
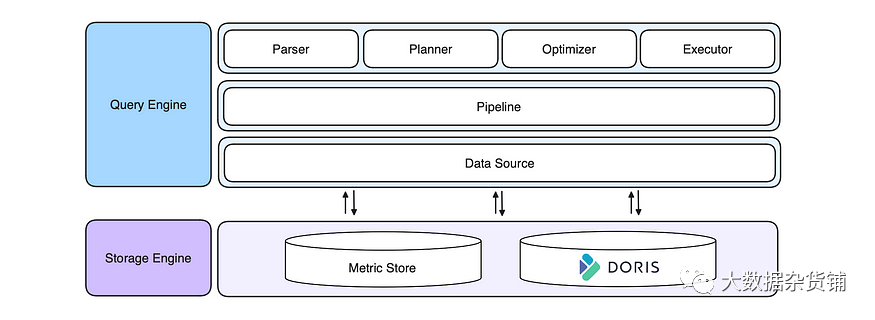
数据查询语言
Guance-Insert:允许不同租户的数据分批次累积,在写入吞吐量和写入延迟之间取得平衡。当日志大量产生时,可以保持2~3秒的低数据延迟。 Guance-Select:对于查询执行,如果 Doris 支持查询 SQL 语义或函数,Guance-Select 会将查询下推到 Doris Frontend 进行计算;如果没有,它将选择后备选项:通过 Thrift RPC 接口获取 Arrow 格式的柱状数据,然后在 Guance-Select 中完成计算。问题是它无法将计算逻辑下推到 Doris Backend,因此它可能比在 Doris Frontend 中执行查询稍慢。
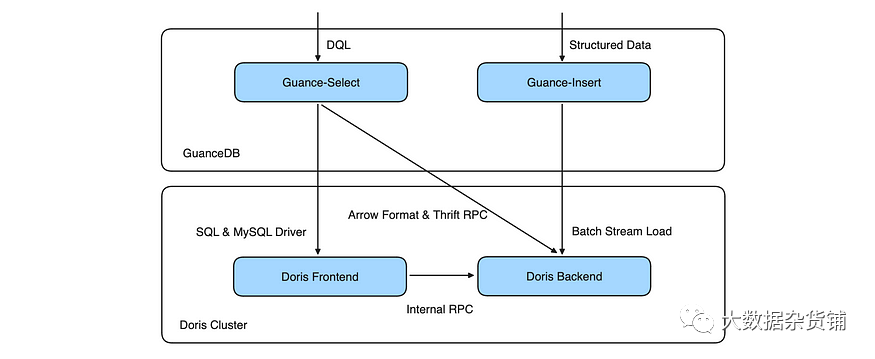
观察结果
存储成本降低 70%,查询速度提高 300%
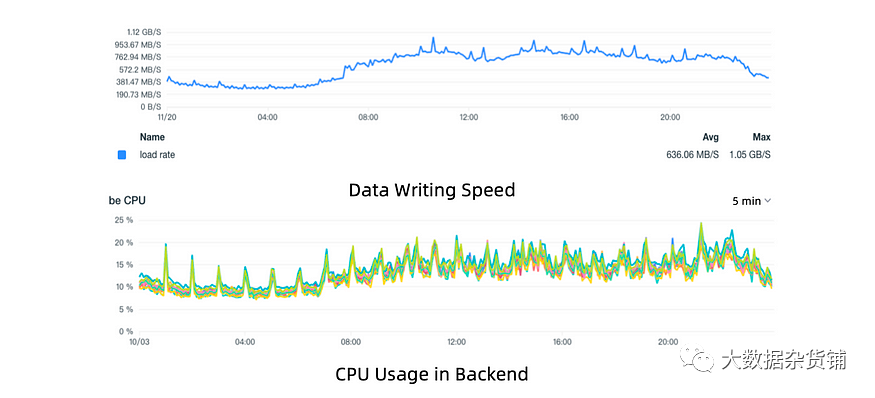
高写入吞吐量:在1GB/s的一致写入吞吐量下,Doris保持CPU占用率低于20%。这相当于 2.6 个云虚拟机。CPU占用率低,系统更稳定,更能应对突发的写入高峰。
高数据压缩比:Doris在列式存储之上采用ZSTD压缩算法。可实现8:1的压缩比。与 Elasticsearch 中的 1.5:1 相比,Doris 可以降低 80% 左右的存储成本。
分层存储:Doris允许以更经济有效的方式存储数据:将热数据放在本地磁盘,冷数据对象存储。一旦设置了存储策略,Doris 就可以自动管理热数据的“冷却”过程,并将冷数据移至对象存储。这样的数据生命周期对于数据应用层来说是透明的,因此对用户友好。此外,Doris 通过本地缓存加速冷数据查询。
用于全文搜索的倒排索引
MATCH_ALL通过、MATCH_ANY和进行全文搜索MATCH_PHRASE。MATCH_PHRASE与倒排索引相结合是 Elasticsearch 全文搜索功能的替代方案。 等价查询(=、!=、IN)、范围查询(>、>=、<、<=)以及对数字、日期时间和字符串的支持。
CREATE TABLE httplog(`ts` DATETIME,`clientip` VARCHAR(20),`request` TEXT,INDEX idx_ip (`clientip`) USING INVERTED,INDEX idx_req (`request`) USING INVERTED PROPERTIES("parser" = "english"))DUPLICATE KEY(`ts`)...-- Retrieve the latest 10 records of Client IP "8.8.8.8"SELECT * FROM httplog WHERE clientip = '8.8.8.8' ORDER BY ts DESC LIMIT 10;-- Retrieve the latest 10 records with "error" or "404" in the "request" fieldSELECT * FROM httplog WHERE request MATCH_ANY 'error 404' ORDER BY ts DESC LIMIT 10;-- Retrieve the latest 10 records with "image" and "faq" in the "request" fieldSELECT * FROM httplog WHERE request MATCH_ALL 'image faq' ORDER BY ts DESC LIMIT 10;-- Retrieve the latest 10 records with "query error" in the "request" fieldSELECT * FROM httplog WHERE request MATCH_PHRASE 'query error' ORDER BY ts DESC LIMIT 10;
作为全文搜索的强大加速器,Doris 中的倒排索引非常灵活,因为我们见证了按需调整的需要。在Elasticsearch中,索引在创建时是固定的,因此需要很好地规划哪些字段需要建立索引,否则,对索引的任何更改都将需要完全重写。
用于动态模式更改的新数据类型
JSON 数据存储:Doris中的Variant列可以容纳任何合法的JSON数据,并且可以自动识别子字段和数据类型。 字段过多导致模式爆炸:频繁出现的子字段会以列的方式存储,以方便分析,而不太常见的子字段将合并到同一列中,以简化数据模式。 数据类型冲突导致写入失败:Variant列允许同一字段存在不同类型的数据,并且针对不同的数据类型采用不同的存储。
变体映射和动态映射之间的区别
结论
原文作者:Apache Doris
