




Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索、全站搜索等领域,本课程将会介绍ES相关原理。
一、ElasticSearch基本介绍
1.1 什么是ElasticSearch
Elasticsearch是使用Java编写的一种开源搜索引擎,它在内部使用Luence做索引与搜索,通过对Lucene的封装,提供了一套简单一致的RESTful API。Elasticsearch也是一种分布式的搜索引擎架构,可以很简单地扩展到上百个服务节点,并支持PB级别的数据查询,使系统具备高可用和高并发性。
1.2 主要功能及应用场景
主要特性
分布式:横向扩展非常灵活
全文检索:基于lucene的强大的全文检索能力;
近实时搜索和分析:数据进入ES,可达到近实时搜索,还可进行聚合分析
高可用:容错机制,自动发现新的或失败的节点,重组和重新平衡数据
RESTful API:JSON + HTTP
应用场景
网站搜索、垂直搜索、代码搜索;
日志管理与分析、安全指标监控、应用性能监控、Web抓取舆情分析。
1.3 ES基础概念
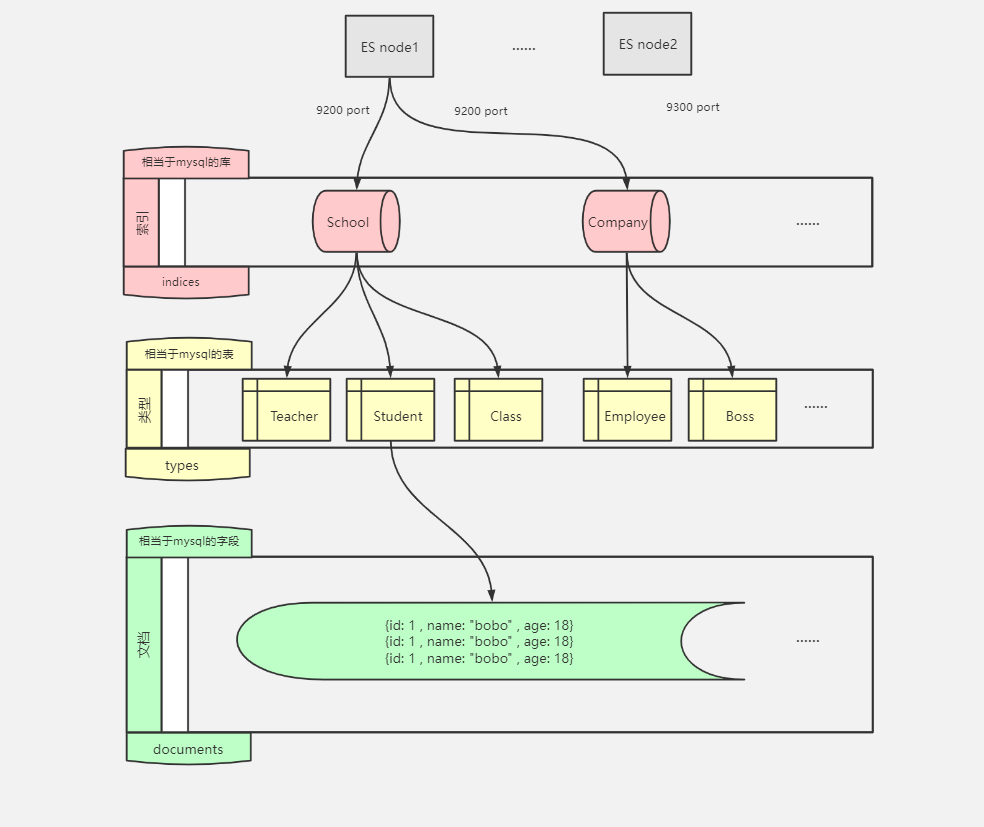
1.3.1 索引(Index):
索引是ES的一个逻辑存储,对应关系型数据库中的库,ES可以把索引数据存放到服务器中,也可以sharding(分片)后存储到多台服务器上。每个索引有一个或多个分片,每个分片可以有多个副本。
1.3.2 类型(Type):
ES中,一个索引可以存储多个用于不同用途的对象,可以通过类型来区分索引中的不同对象,对应关系型数据库中表的概念。但是在ES6.0开始,类型的概念被废弃,一个索引中只存放一类数据;ES7之后移除了type,type默认都是"_doc"。
1.3.3 文档(Document):
存储在ES中的主要实体叫文档,可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成,以JSON格式来表示。
1.3.4 字段(Field):
类比关系数据库里的field,每个field 都有自己的字段类型。常见的类型有:
1.3.4.1 text
当一个字段的内容需要被全文检索时,可以使用text类型,支持长内容的存储,比如检索文章内容、商品信息等。该类型的字段内容在保存时会被分词器分析,并且拆分成多个词项, 然后根据拆分后的词项生成对应的索引,根据关键字检索时可能会将关键字分词,用分好的词从之前生成的索引中去匹配,进而找到对应的文档。对于text类型的字段你可能无法通过指定文本精确的检索到。另外需要注意的是,text类型的字段不能直接用于排序、聚合操作。这种类型的字符串也称做analyzed字符串。
1.3.4.2 keyword
keyword类型适用于结构化的字段,比如手机号、商品id、用户id等,默认最大长度为256。keyword类型的字段内容不会被分词器分析、拆分,而是根据原始文本直接生成倒排索引,所以keyword类型的字段可以直接通过原始文本精确的检索到。keyword类型的字段可用于过滤、排序、聚合操作。这种字符串称做not-analyzed字符串。
1.3.4.3 日期类型
ES 中的date类型默认支持如下两种格式:
strict_date_optional_time yyyy-MM-dd'T'HH:mm:ss.SSSSSSZ yyyy-MM-dd
epoch_millis
1.3.4.4 数值类型
| 类型 | 取值范围 |
|---|---|
| byte | -2^7 ~ 2^7-1 |
| short | -2^15 ~ 2^15-1 |
| integer | -2^31 ~ 2^31-1 |
| long | -2^63 ~ 2^63-1 |
| float | 32位单精度IEEE 754浮点类型 |
| double | 64位双精度IEEE 754浮点类型 |
| half_float | 16位半精度IEEE 754浮点类型 |
| scaled_float | 缩放类型的的浮点数 |
一般情况下,如果可以满足需求,则优先使用范围小的类型,来提高效率。
1.3.4.5 数组类型
在 ES 中并没有数组类型,但我们却可以按数组格式来存储数据,因为 ES 中默认每个字段可以包含多个值,同时要求多个值得类型必须一致。例如可以按照如下方式指定一个字段的值为数组:
"label": [ "Elastcsearch", "7.9.3版本" ]
1.3.4.6 对象类型
由于 ES 中以 JSON 格式存储数据,所以一个 JSON 对象中的某个字段值可以是另一个 JSON 对象。
ES和mysql数据库概念对比
1.4 集群核心概念
1.4.1 集群(Cluster)
一个ES集群由多个节点(node)组成, 每个集群都有一个共同的集群名作为标识。
1.4.2 节点(Node)
一个ES实例即为一个节点,一台机器可以有多个节点,正常使用下每个实例都应该会部署在不同的机器上。
1.4.3 分片(Shard)
分片,当索引上的数据量太大的时候,我们通常会将一个索引上的数据进行水平拆分,拆分出来的每个数据库叫作一个分片。在一个多分片的索引中写入数据时,通过路由来确定具体写入那一个分片中,所以在创建索引时需要指定分片的数量,并且分片的数量一旦确定就不能更改。分片后的索引带来了规模上(数据水平切分)和性能上(并行执行)的提升。
1.4.4 副本(Replica)
副本,是指对主分片的备份。主分片和备份分片都可以对外提供查询服务,写操作时先在主分片上完成,然后分发到副本上。当主分片不可用时,会在备份的分片中选举出一个作为主分片,所以备份不仅可以提升系统的高可用性能,还可以提升搜索时的并发性能。但是若副本太多的话,在写操作时会增加数据同步的负担。
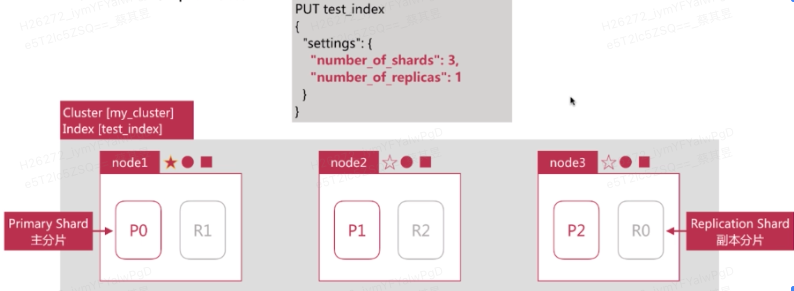
以下展示了 3 个节点的集群中分片分布的情况,创建时我们指定了 3 个分片和 1 个副本。为了防止出现单点故障,主分片与副本不会同时出现在同一个节点上。
二、ElasticSearch原理介绍
2.1 正排索引与倒排索引
正排索引:文档 Id 到文档内容、单词的关联关系
倒排索引:单词到文档 Id 的关联关系
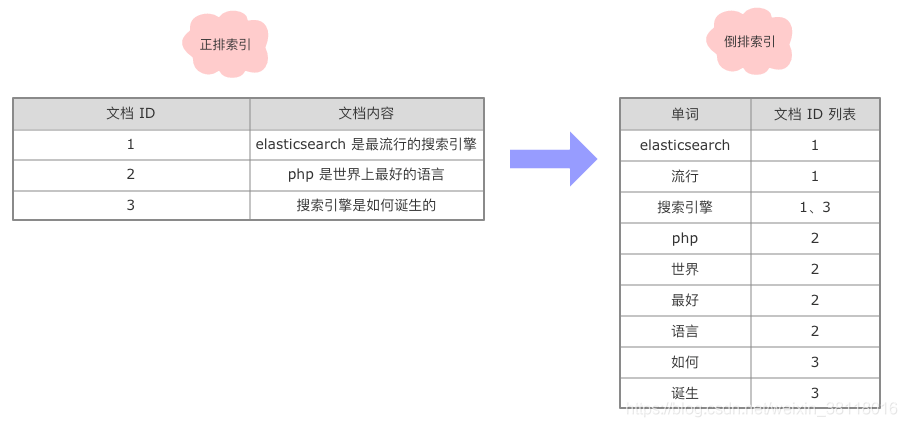
根据以上数据,假设我们现在要查询包含 “搜索引擎” 的文档,具体的查询流程如下:
通过倒排索引获得 “搜索引擎” 对应的文档 Id 有 1 和 3
通过正排索引查询 1 和 3 的完整内容
返回用户最终结果
2.2 倒排索引原理
倒排索引是搜索引擎的核心,主要包含两部分:
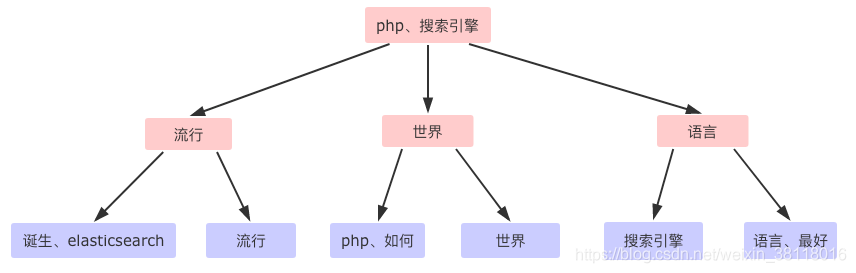
1、单词词典(Term Dictionary):是倒排索引的重要组成,记录所有文档的单词,一般都比较大,记录单词到倒排列表的关联信息。单词词典一般用 B+Trees 来实现:
2、倒排列表(Posting List):记录了单词对应的文档集合,由倒排索引项组成。
倒排索引项主要包含以下信息:
文档 ID,用来获取原始信息
单词频率(TF:Term Frequency),记录该单词在该文档中的出现次数,用于后续相关性算分
位置(Position),记录单词在文档中的分词位置(多个),用于做词语搜索
偏移(Offset),记录单词在文档的开始位置和结束位置,用于做高亮显示
以【搜索引擎】为例,我们来看一下倒排列表:
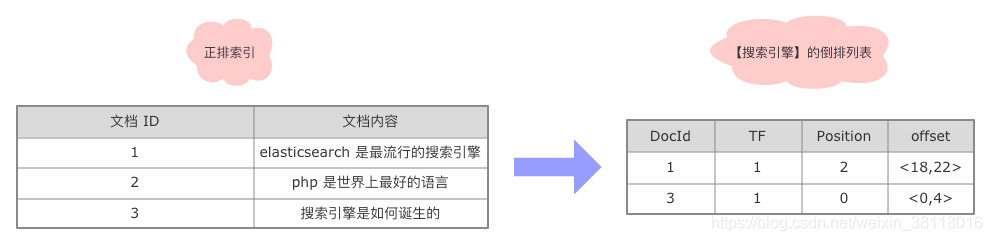
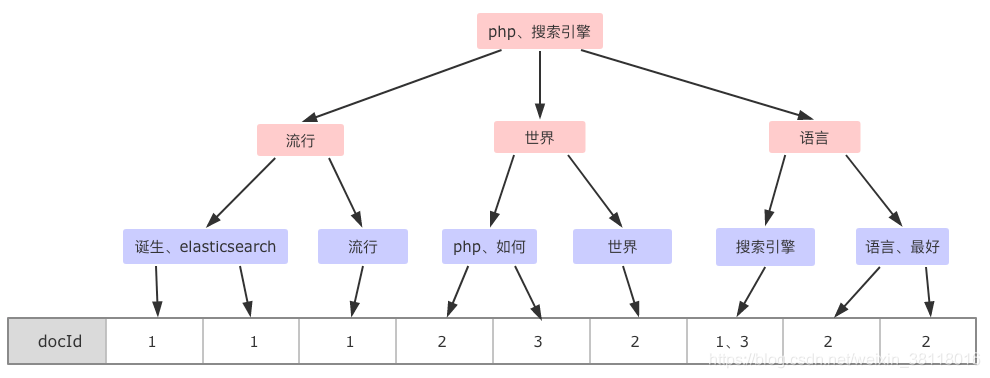
最后,单词字段和倒排列表整合在一起的结构如下(只列出了 docId):
2.3 集群状态
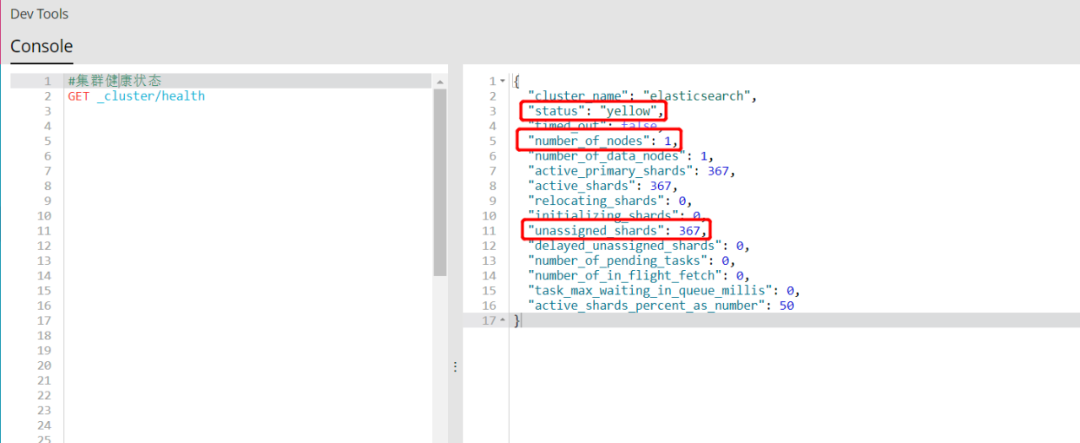
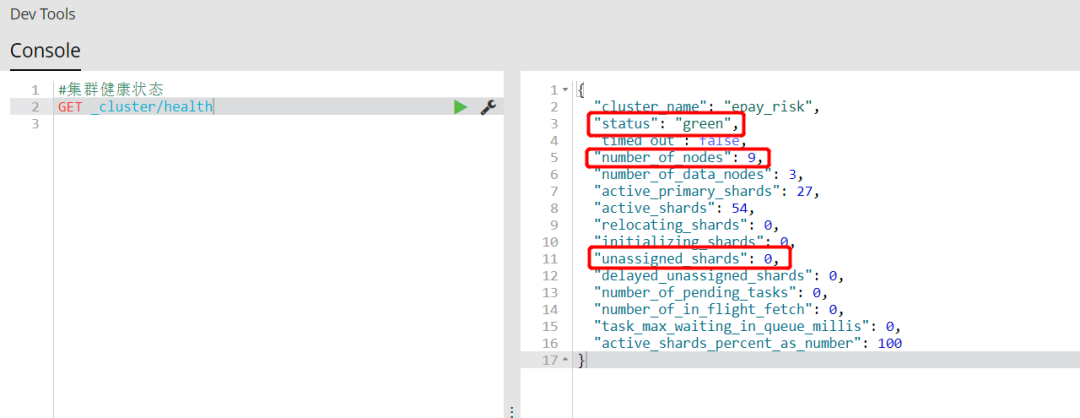
ES提供了一个api可以查看集群的状态,包括以下三种状态:
green 健康状态,指所有主副分片都正常分配
yellow 指所有主分片都正常分配,但是有副分片未正常分配
red 有主分片未分配
注意:这里的状态指的仅仅是主分片的状态,而不是集群是否能相应的状态,所以red并不是代表不能访问。
测试环境ES只有一个节点,由于主分片和副本无法在同一个节点,因此所有主分片的副本无法分配,此时status为“yellow”
线上环境ES有9个节点,没有未正常分配的分片,此时status为“green”。
2.4 故障转移
如下图集群有 3 个节点组成,此时集群状态是 green:
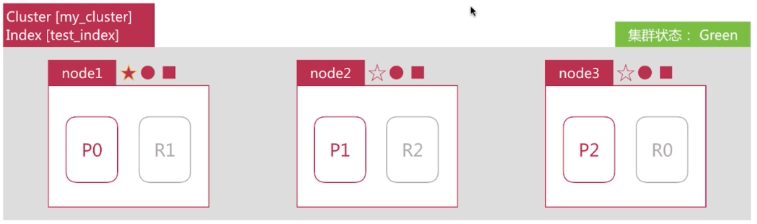
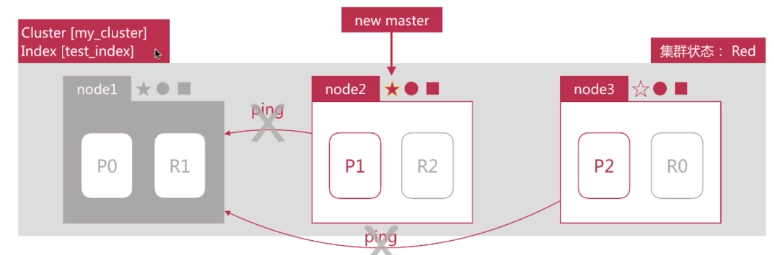
突然 node1(master)所在机器宕机导致服务终止,此时Node2 和 node3 发现 node1 无法响应一段时间后发起 master 选举,比如这里选择 node2 为 master 节点。此时由于主分片 P0 下线,集群状态转变为 Red。
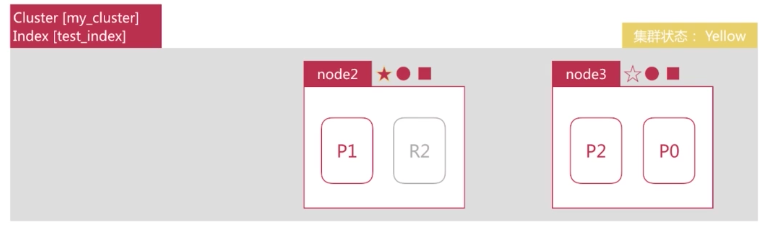
node2 发现主分片 P0 未分配,将副本分片 R0 提升为主分片。此时由于所有主分片都正常分配,集群状态变为 yellow。
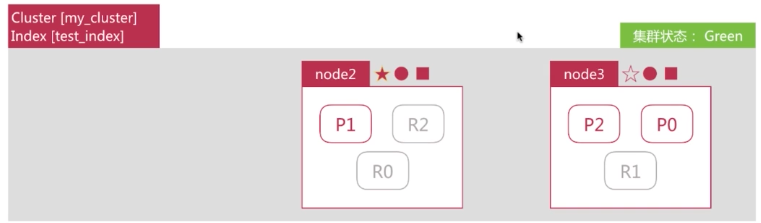
node2 为 P0 和 P1 生成新的副本,集群状态恢复为绿色。
2.5 分布式文档存储
2.5.1. 路由算法
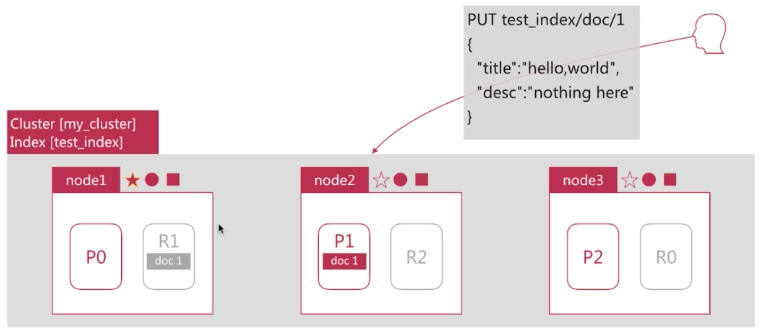
那么Document 1是如何存储到分片P1的?选择P1的依据是什么?
通过文档分片的Hash映射算法。
目的:使文档均匀的分布在所有分片上,以充分利用资源。
文档到分片的映射算法:
shard = hash(routing) % number_of_primary_shards
routing是一个关键参数,默认是文档id,可以自行指定
number_of_primary_shard 主分片数
hash算法可以保证将数据均匀的分散在分片中
该算法与主分片数量有关,这就是为什么之前说分片数一旦创建就不能修改的原因:如果主切片的数量发生改变,所有先前的路由值就会失效,文档数据也就无法定位到了。
2.5.2副本一致性
作为分布式系统,数据副本可算是一个标配。ES 数据写入流程,自然也涉及到副本。在有副本配置的情况下,数据从发向 ES 节点,到收到 ES 节点响应返回,流程如下图所示:
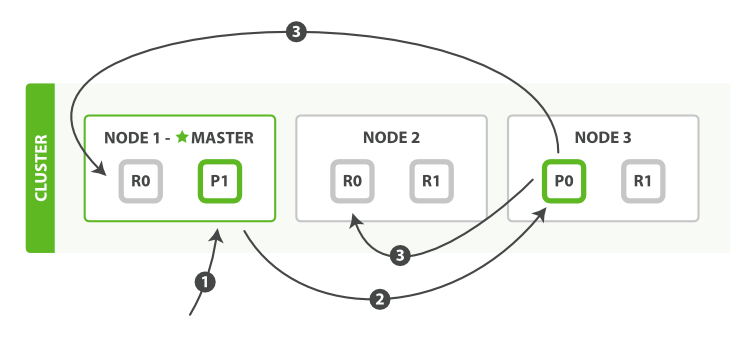
客户端请求发送给 Node 1 节点,注意图中 Node 1 是 Master 节点,但也完全可以不是。
Node 1 用数据的 _id 取余计算得到应该将该数据需存储到 P0 上。通过Cluster State 信息发现 P0 的主分片已经分配到了 Node 3 上。因此Node 1 转发请求数据给 Node 3。
Node 3 完成请求数据的索引过程存入主分片P0,然后并行转发数据给分配有P0副本分片的 Node 1 和 Node 2。当收到任一节点汇报副本分片数据写入成功,Node 3 即返回给初始的接收节点 Node 1,宣布数据写入成功。Node 1 返回成功响应给客户端。
2.6 脑裂问题
2.6.1 脑裂问题介绍
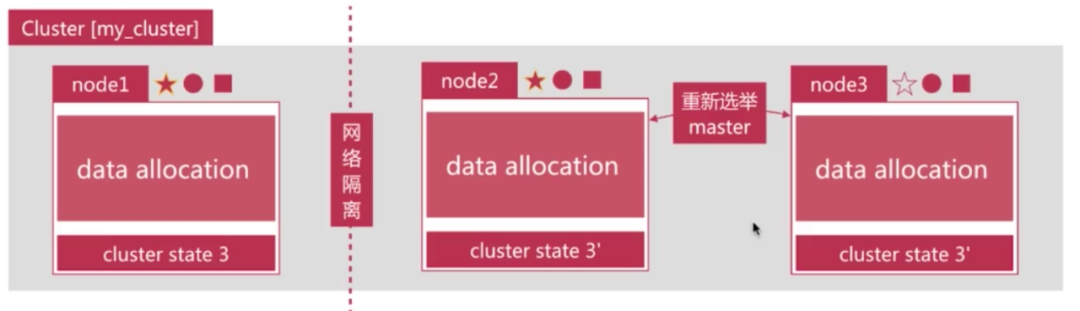
脑裂问题(split-brain),是分布式系统中的经典网络问题,如图:
3个节点组成的集群,突然node1的网络和其他两个节点断开了
node2 与 node3 会重新选举master,比如node2成为了新的master,此时会更新cluster state
node1 自己组成集群后,也会更新cluster state
同一个集群有两个master,而且维护不同cluster state,网络恢复后无法选择正确的master
2.6.2 解决方案
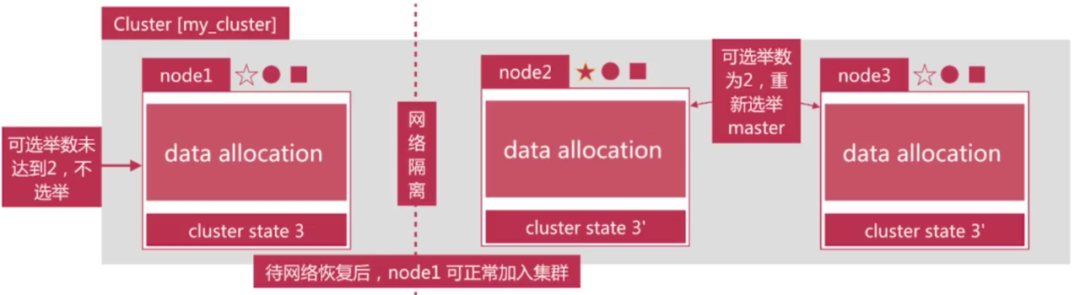
解决方案为仅在可选举master-eligible节点数大于等于quorum时才可以进行master选举:
quorum = master-eligible 节点数/2+1,例如3个master-eligible节点时,quorum为2
设定discovery.zen.minimum_master_nodes为quorum即可避免脑裂
-- End --
点击下方的公众号入口,关注「技术对话」微信公众号,可查看历史文章,投稿请在公众号后台回复:投稿
