导语

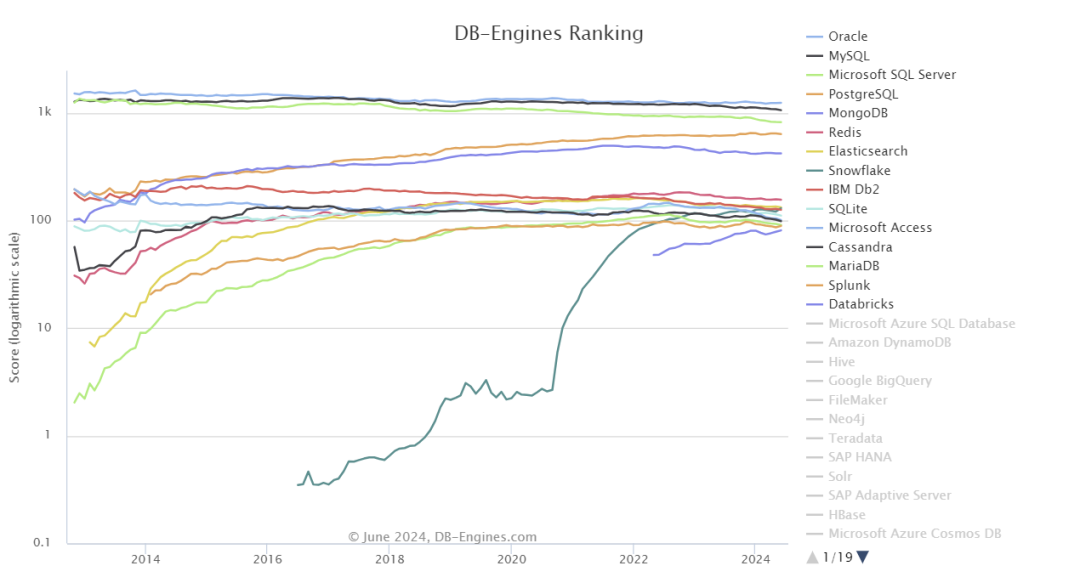
MongoDB在所有Nosql数据库中排名靠前,DB-Engines排名如下:
基于MongoDB优秀的性能和no-schema特性,当前腾讯云上有大量用户使用MongoDB做为用户主存储服务,不仅仅大量腾讯内部业务使用MongoDB,同样有大量外部用户使用MongoDB。
随着用户业务的快速增长,MongoDB存储和处理的数据量大大增加,用户对性能也提出了更高要求。作为MongoDB在中国的亲密伙伴,过去几年,腾讯云针对MongoDB内核优化的贡献达到了全球第一。
腾讯云MongoDB内核贡献全球第一
MongoDB/WiredTiger内核核心代码(不包括测试代码)数百万行左右,除了MongoDB原厂工程师外,全球能给MongoDB内核(含Mongo server及WiredTiger存储引擎)提交深度优化的开发人员屈指可数。
在过去的一年,结合腾讯云线上MongoDB遇到的性能问题,腾讯MongoDB团队为MongoDB内核贡献了接近60个PR优化,其中包括一些长期没有彻底解决的性能问题。
过去一年腾讯云给MongoDB内核贡献覆盖涵盖稳定性、性能、功能和可观测性等诸多方面,涉及B+tree、checkpoint、reconcile持久化、block、page锁、api、事务、wtperf性能压测、wt问题分析工具、系统诊断分析、分片路由、索引等,贡献数总结如下:
性能优化:10个
新特性:7个
可观察性及问题诊断: 18个
Bug fix:13个
其他:10个
截止目前,除了MongDB官方,腾讯云是全球唯一一家能同时对MongoDB及WiredTiger存储引擎进行深度PR贡献优化的厂商。根据github,腾讯云是除MongoDB官方外,MongoDB/WiredTiger内核贡献全球第一的厂商,还是全球给MongoDB/WiredTiger存储引擎PR贡献最多的外部云厂商。
MongoDB官方感谢腾讯云
基于腾讯云过去对MongoDB内核的贡献,MongoDB官方接连用3封感谢信表达对腾讯云的认可和感激。MongoDB高管表示:感谢腾讯云团队对WiredTiger存储和内核的关注和贡献,腾讯云团队提交的性能改进方案非常出色,双方的共同努力可以让更多问题一一浮现,以实现对开源的承诺。

腾讯云MongoDB团队PR贡献列表
1.1. MongoDB分片集群路由底座优化,性能千倍提升
1.1.1. 优化背景
MongoDB分片集群为了维持集群路由全局一致性,在扩缩容、split拆分等关键逻辑都会进行路由版本号更新及路由刷新操作,路由刷新过程所有客户端请求阻塞等待,如果刷路由过程耗时较长,客户端将会有大量超时。
下面是收集到的线上不同MongoDB分片集群扩缩容、split等过程路由更新耗时数据:
内核版本 | 数据量 | Chunk数 | 抖动耗时 |
3.6 | 80T | 450W | 4500ms |
4.0 | 1.2T | 25W | 300ms |
4.2 | 25T | 150W | 1200ms |
5.0(测试数据) | 30T | 200W | 750ms |
5.0(测试数据) | 100T | 600W | 2400ms |
官方从3.4开始后的多个内核版本都在努力对路由刷新进行了优化,使用BSONObjIndexedMap、map、vector、bsonmap等数据结构,每次迭代都有一定性能提升,但还是存在秒级集群阻塞问题。
对应jira: SERVER-71627
1.1.2. 优化收益
性能收益
增量路由刷新可实现性能数百上千倍性能提升,彻底解决分片集群chunks较多时引起的抖动。该功能最终贡献给社区,并应用于腾讯云内外部用户,包括各个头部大客户。同时得到了MongoDB官方肯定:

腾讯云路由优化后效果:
内核版本 | 数据量 | Chunk数 | 官方版本时延 | 优化后时延 | 性能提升结果 |
3.6 | 80T | 450W | 4500ms | 2ms | 提升2200倍 |
4.0 | 1.2T | 25W | 300ms | 2ms | 提升150倍 |
4.2 | 25T | 150W | 1200ms | 2ms | 提升600倍 |
5.0(测试数据) | 30T | 200W | 750ms | 2ms | 提升450倍 |
5.0(测试数据) | 100T | 600W | 2400ms | 2ms | 提升1200倍 |
其他收益
MongoDB官方以该功能为基础后续又开发了之前无法完成的新功能,例如自动mergeChunk功能。
1.2. MongoDB点查性能优化,性能提升一倍磁盘节省80%
1.2.1. 优化背景
某用户在做数据库选型,写入同样的数据到MongoDB和外部某数据库,然后用同样的SQL进行查询。由于候选数据库只存储历史订单数据,因此对写入性能要求不高,但是对读性能有要求。
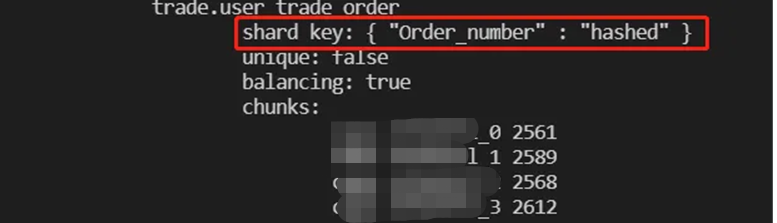
该业务以order_number做片建,分片方式为hashed分片,总数据量数亿条,用户反馈大部分SQL请求MongoDB更优。
但是有一类大量点查场景,MongoDB性能更差。
由于耗时全部由读磁盘引起,从日志看一次性读磁盘16.6G确实也很夸张,因此优化该SQL的方法就是看如何减少磁盘数据读取。
由于查询条件为{"billCode":"XXXXXXXXXXXXXXXXX"},并且billCode为hash分片方式,由于数据量较大并且查询字段billCode为hash方式,因此从B+ tree原理来看,很可能访问的这12W条数据离散到了12W个leaf page中,同时访问这12W数据访问了更多的internale page,总的page数上百万。
为了减少读磁盘的数据量,对存储引擎leaf page大小调整到4K,这样单条数据读取的磁盘量会减少8倍。优化后,该SQL查询性能提升了1-2倍,也可以满足用户要求,但是发现新的问题: 磁盘占用膨胀了4-5倍.
分析WiredTiger存储引擎,确认问题由B+tree reconcile持久化引起,腾讯云贡献PR支持32K以下page压缩功能。
1.2.2. 优化收益
通过对32K以下page的压缩功能支持,整体效果良好,具体收入如下:
收益1
点查性能提升1-3倍,延迟减少60%左右
收益2
磁盘占用减少80%,节省80%磁盘空间
WT-12653
1.3. MongoDB写入性能提升20%,磁盘节省35%
1.3.1. 优化背景
腾讯云某用户从其他数据库(非MongoDB)迁移到MongoDB。迁移到MongoDB后,用户发现磁盘使用率提高了35%左右,而写性能和查询(主要是range查询)性能有所下降。
1.3.2. 优化过程
为了分析这个问题,我用Mongo shell临时打开了Mongo的存储日志阈值,信息如下:
db.adminCommand({setParameter:1, WiredTigerEngineRuntimeConfig:'verbose=[block=5,write=5]'})
日志输出如下:
{"t":{"$date":"2024-03-13T21:51:58.068+08:00"},"s":"D2", "c":"WT", "id":22430, "ctx":"conn8","msg":"WiredTiger message","attr":{"message":{"ts_sec":1710337918,"ts_usec":68421,"thread":"1732:0x7f2e52053700","session_dhandle_name":"file:user/index/7-3409874514835487866.wt","session_name":"WT_CURSOR.insert","category":"WT_VERB_WRITE","category_id":42,"verbose_level":"DEBUG_2","verbose_level_id":2,"msg":"write: data/mongodb-data/mongodb-7.0.0/data/user/index/7-3409874514835487866.wt, fd=59, offset=1306624, len=8192"}}}{"t":{"$date":"2024-03-13T21:51:58.114+08:00"},"s":"D2", "c":"WT", "id":22430, "ctx":"conn8","msg":"WiredTiger message","attr":{"message":{"ts_sec":1710337918,"ts_usec":114105,"thread":"1732:0x7f2e52053700","session_dhandle_name":"file:user/index/7-3409874514835487866.wt","session_name":"WT_CURSOR.insert","category":"WT_VERB_WRITE","category_id":42,"verbose_level":"DEBUG_2","verbose_level_id":2,"msg":"write: data/mongodb-data/mongodb-7.0.0/data/user/index/7-3409874514835487866.wt, fd=59, offset=1290240, len=12288"}}}
从上面的mongod.log可以看出,我们的写磁盘块大小在8到12K之间,比max leaf page(默认值32K)小得多,这是一个问题。结合WiredTiger存储引擎reconcile原理,可以确定该问题图形化总结如下:
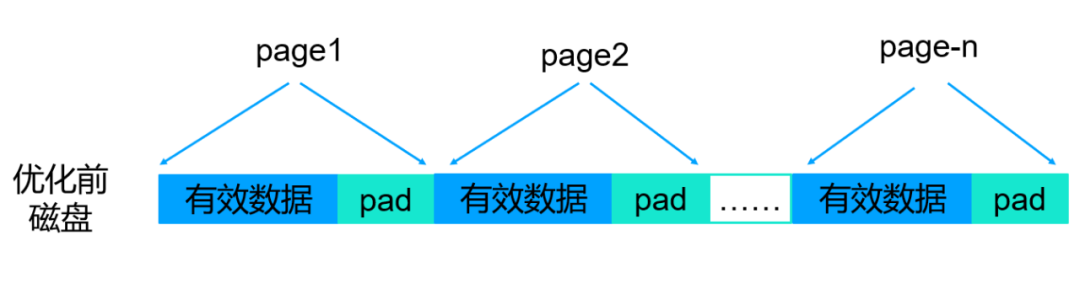
问题形成原因:
默认情况下WiredTiger存储引擎最多一次对4倍maxleafpage的内存空间为单位进行持久化,磁盘持久化时候以4K为单位分配磁盘空间,假设文档压缩率很高,远远超过4倍压缩,则4 X maxleafpage = 128K,则这128K的内存可能压缩后的大小为5006(4096+10)字节,那么这里就会由4096-10=4086字节的pad空间,这部分空间就是浪费的,如下:
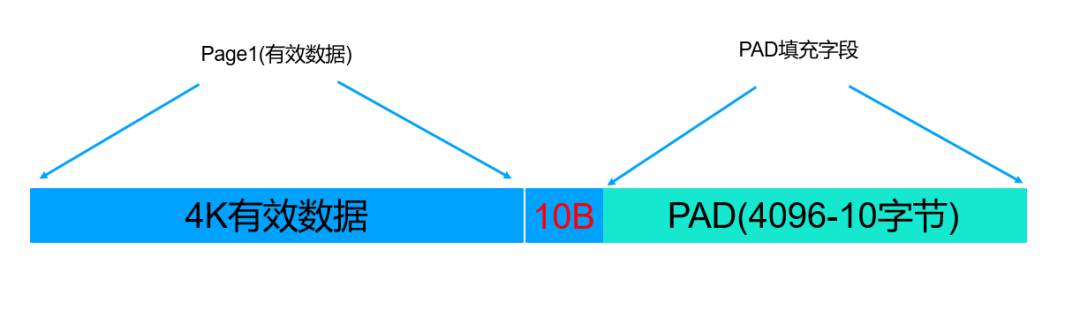
优化方法:
在对内存page数据进行reconcile到磁盘page中的时候,尽最大化把最后一块4K单元填充满,这样就可以解决磁盘浪费的问题。最终效果如下:
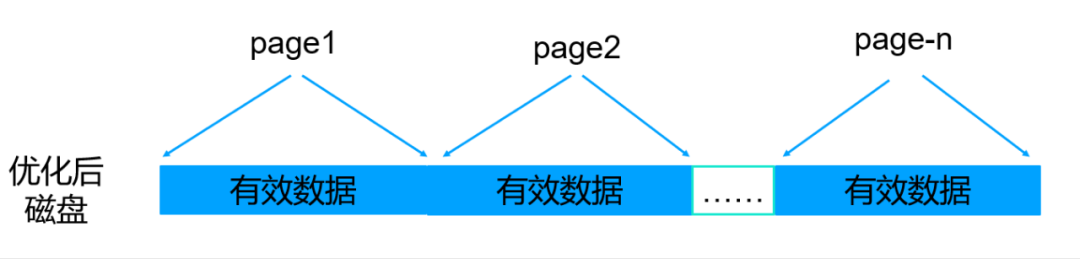
1.3.3. 优化收益
在存在PAD数据的场景下,主要收益如下:
收益1
磁盘空间节省10%-50%
收益2
写性能提升20-30%
收益3
范围查询性能有利
就该问题最初我们提交了2个PR:
PR1(WT-12651):
自动调整压缩比算法,最大化填充max leafpage对应磁盘空间大小32K。官方最终没有接收,原因是他们认为这样会增加内存负担,原因是磁盘32K是压缩后的,加载到内存后解压缩后可能会占用更多内存,因为之前只支持最大4倍,但是突破这个限制后,例如10倍压缩,则读磁盘32K空间到内存解压缩后会占用320K内存,这样内存压力会很大。
该优化只对insert场景收益到,但是查询场景可能会增加内存压力,因此最终建议用户自己根据实际场景决定:
db. createCollection ("sbtest4", {storageEngine: {WiredTiger: {configString: "memory_page_image_max: 320K"}})
PR1(WT-12839):
增加PAD空间诊断统计功能,该PR作用是确定PAD空间占比过高后,我们通过memory_page_image_max动态调整来解决问题。该PR最初被官方接收,后面官方认为可以通过工具来分析WT文件进而发现问题。我个人不支持用工具来分析WT文件识别问题,我给出的理由如下:
1. 云上用户访问不了云上服务器,atlas用户访问不了aws的MongoDB服务器,也获取不到wt文件。
2. 我们何时去运行这个分析工具,假设线上数百万个集群,上亿WT文件,工具分析不太现实。
3. 分析WT文件费时费力,会增加机器负载等
后续会继续和官方讨论跟进wt-12839这个PR,因为我们线上经常遇到同样数据集群迁移后磁盘空间占用变化很大的情况。
1.4. MongoDB小page场景优化,磁盘空间节省20%,解决磁盘碎片问题
问题现象
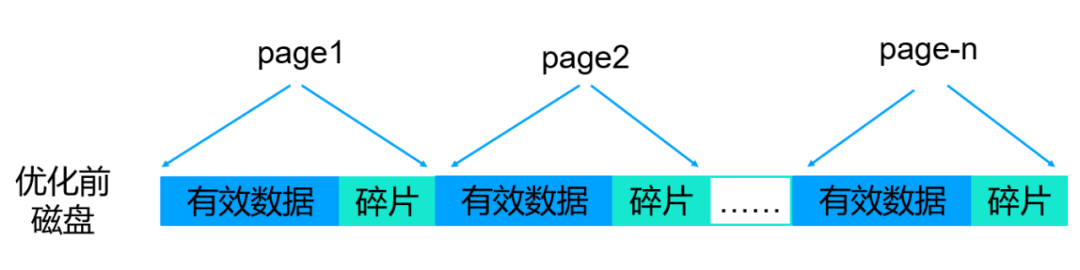
问题形成原因:
当内存page配置小于磁盘page配置的时候,reconcile持久化或者checkpoint持久化的时候磁盘上的一个完整page无法写满,最终造成磁盘空间浪费。
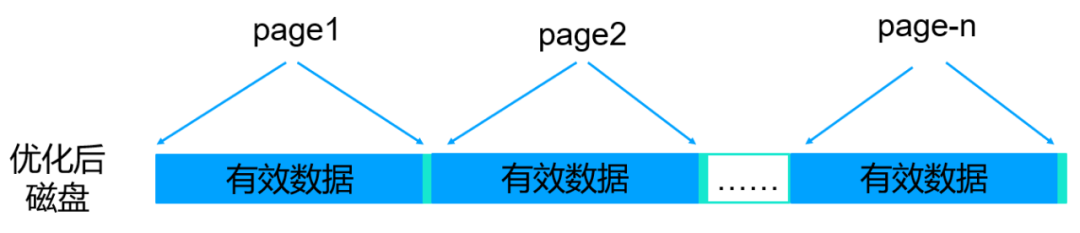
优化方法
提前判断比较内存page和磁盘page差异,最大化填充上图的碎片空间。
1.5. Io_capacity刷盘引起的抖动问题优化
WiredTiger启用io_capacity功能后,默认刷盘策略相对比较激进,该PR可以平滑的完善IO sync持久化功能,极大的减少磁盘刷盘引起的业务抖动和慢查毛刺问题。
WT-11877
WT-13182
1.6. 新增WAL预写日志文件预创建功能,解决WAL文件创建引起的MongoDB秒级抖动问题
当WiredTiger存储引擎的WAL日志WiredTigerPreplog.xxxx写满后,如果WiredTigerPreplog.xxxx不够用,则用户线程需要创建WiredTigerPreplog.xxxx文件,代码逻辑中会调用posix_fallocate接口创建100M的WAL日志文件。用户线程创建WAL日志文件耗时1-2秒,这期间客户端请求会阻塞。
优化方法:”log server”线程后台提前准备好指定数量的WAL文件(新增prealloc_init_count,支持动态配置)。
WT-12562
1.7. 新增一次开启all verbose功能,方便问题排查
MongoDB存储引擎WiredTiger拥有50个核心模块,每个模块拥有各自的verbose开关,如果存储引擎有问题,我们得一个模块一个模块的去打开日志开关分析问题,极大的增加了问题分析难度。
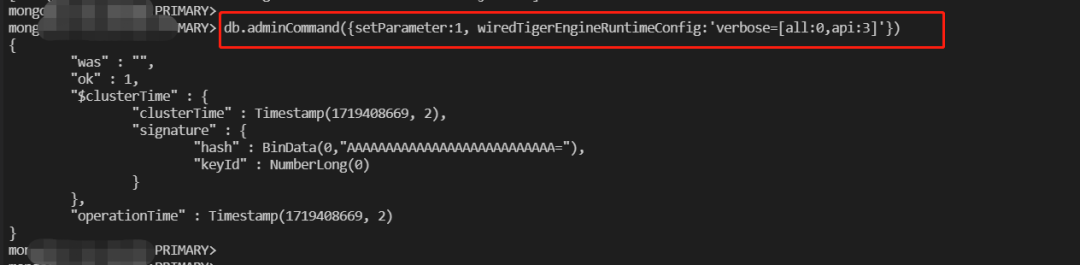
该功能为了很好的保持50项配置的易用性,支持如果某个模块没有设置verbose,则以all配置为准,如果子模块有配置,则以子模块配置为准。
1.8. 新增MongoDB请求维度全链路重点模块耗时分析功能,慢日志中直观体现”慢在哪儿”,减少问题分析难度(流程中)
该PR收益:
1.直观定位问题是由mongo server引起还是WiredTiger存储引擎引起
2.Wt引擎引擎的具体那个子模块引擎的抖动
WT-13122
1.9. 新增存储引擎page锁阻塞诊断功能
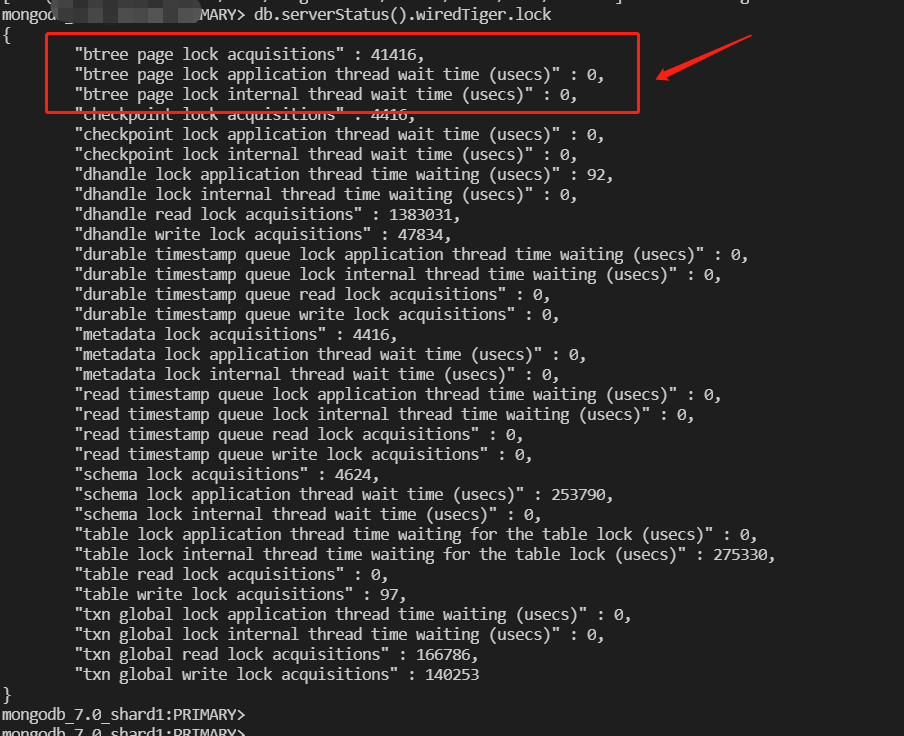
Page锁阻塞等待诊断功能支持以下三个维度的诊断分析:
lock_btree_page_count
获取page锁的次数
lock_btree_page_wait_application
用户请求在page锁等待耗时
lock_btree_page_wait_internal
MongoDB存储引擎WiredTiger内部线程page锁等待耗时
WT-13022
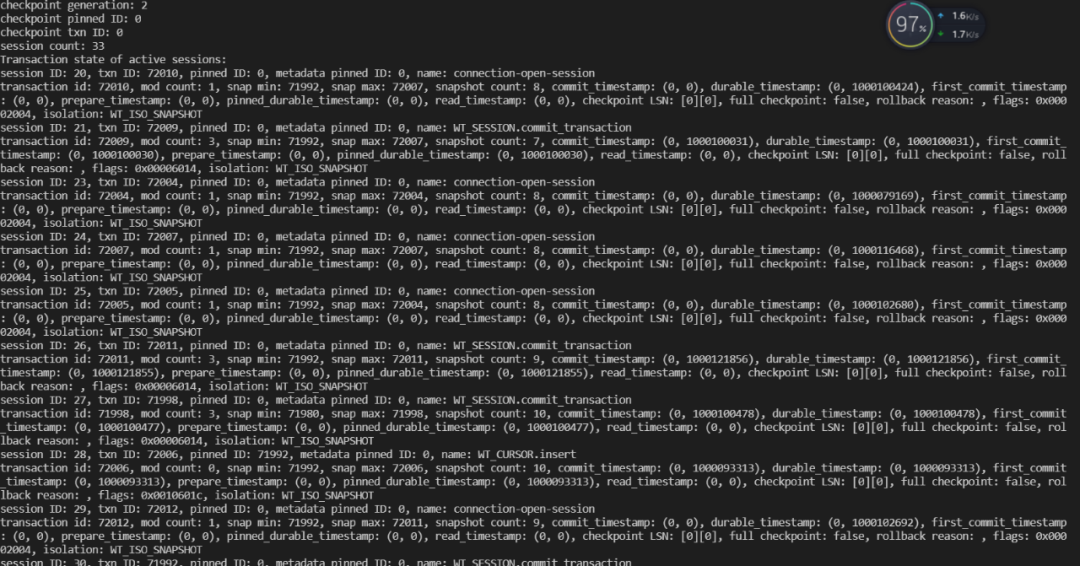
1.10. 新增事务异常快照列表信息,直观分析事务异常
该PR优化前
该PR优化后
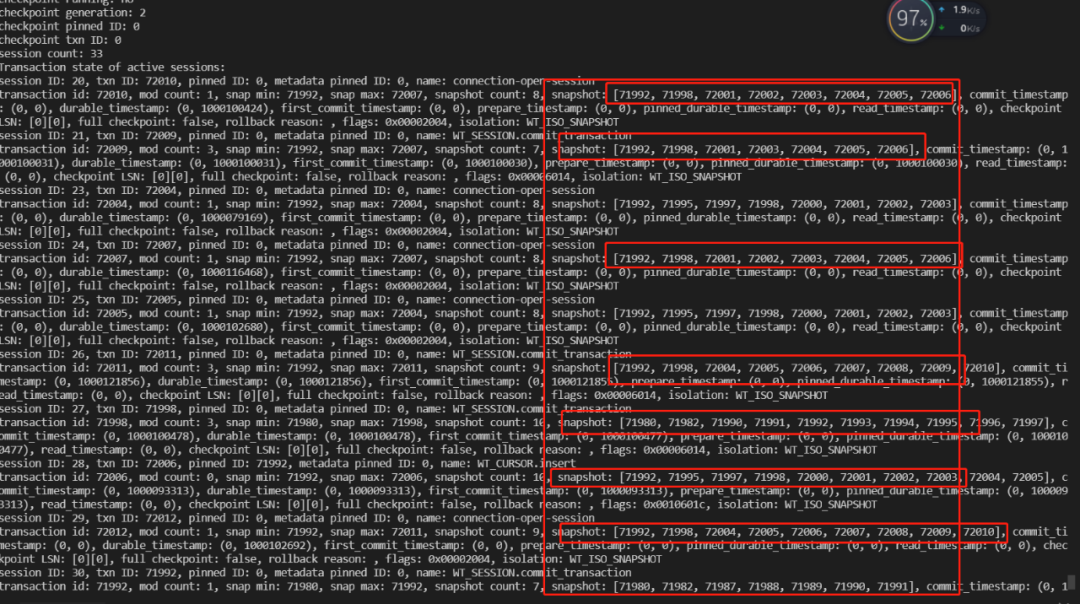
通过该功能能直观定位事务异常原因,那些事务异常,异常的事务有哪些。
WT-12961
1.11. WiredTigerEngineRuntimeConfig支持记录所有历史配置修改功能,解决多次优化WiredTiger引擎配置后遗忘历史优化记录
该PR功能优化前:
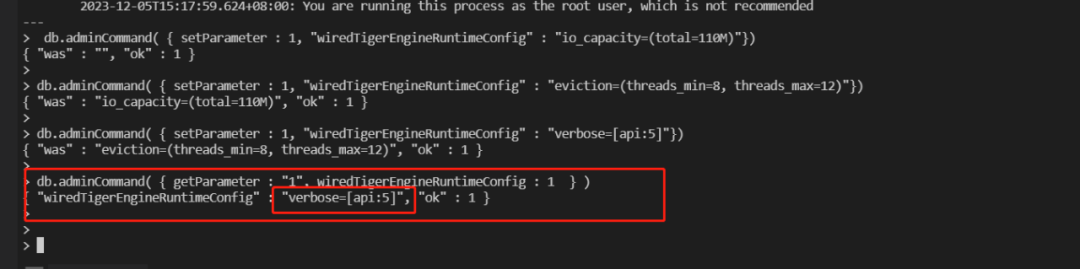
如上图,当前WiredTigerEngineRuntimeConfig只会保存最后一次对存储引擎优化的参数信息,历史的优化记录无法获取。
该PR功能优化后:
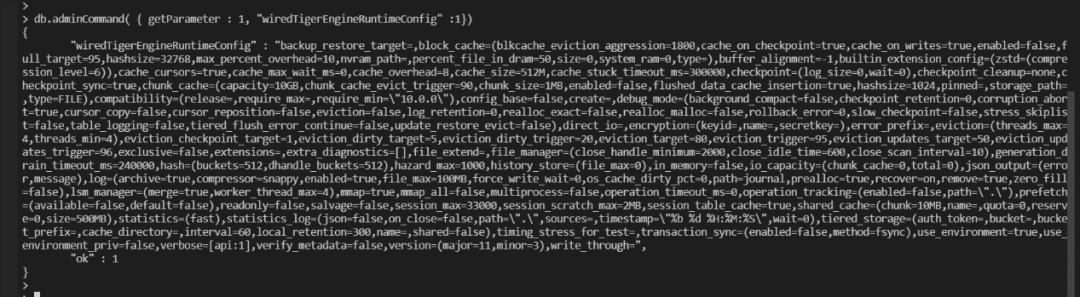
该PR功能优化后,我们可以获取全局的所有存储引擎配置记录信息。
SERVER-84220
WT-12141
1.12. Block重叠检查及可视化优化
增加block重叠检查,diagnose模式下直观判断重叠异常原因,减少分析问题的难度和分析问题的时间。
WT-12044
1.13. 新增请求阻塞情况下零时evict及checkpoint verbose调整恢复功能
Diagnose模式下,当用户请求阻塞的时候,WiredTiger存储引擎会自动调整evict和checkpoint的verbose级别来分析阻塞异常原因,verbose调整后,mongod.log会有大量evict和checkpoint日志。
当阻塞恢复后,wt遗漏了evict和checkpoint的verbose级别还原功能,会引起因为日志写入引起系统负载增加问题。
WT-12012
1.14. Checkpoint状态异常修复,新增btree checkpoint耗时诊断统计功能
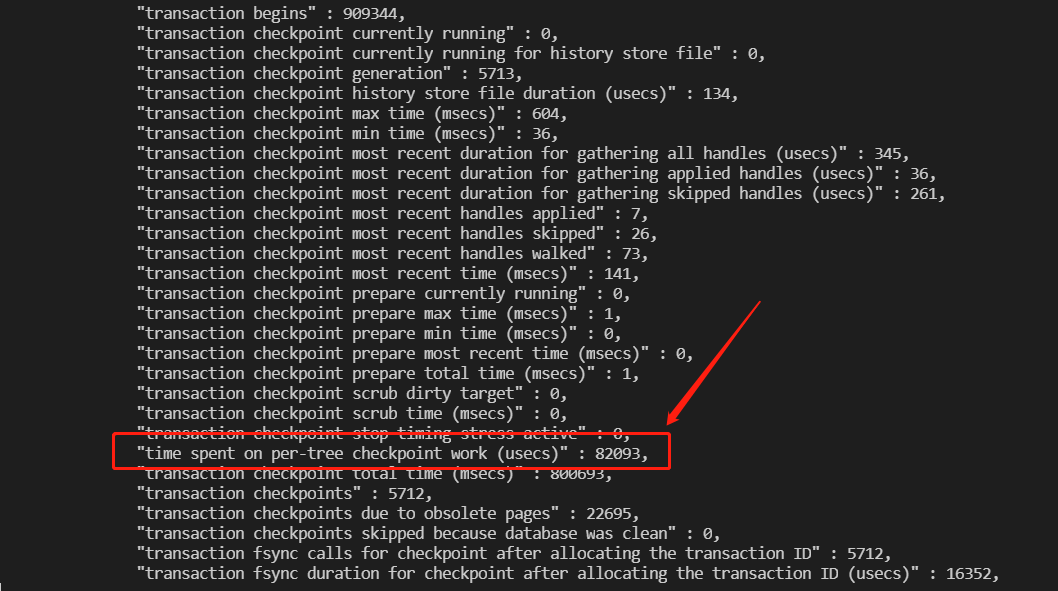
新增单个表checkpoint持久化的耗时统计,同时新增” checkpointing individual trees”单个tree的verbose跟踪定位功能。
WT-12001
1.15. 新增磁盘IO阻塞耗时诊断功能

磁盘IO读写快慢影响整个mongodb性能,该PR在原有基础上增加以下诊断统计:
perf_hist_fsread_latency_total_msecs
增加读磁盘总耗时统计(ms级)
perf_hist_fswrite_latency_total_msecs
增加写磁盘总耗时统计(ms级)
perf_hist_opread_latency_total_usecs
增加读磁盘总耗时统计(us级)
perf_hist_opwrite_latency_total_usecs
增加写磁盘总耗时统计(us级)
通过给PR可以快速定位磁盘是否存储瓶颈。
WT-11834
1.16. MongoDB存储引擎磁盘ext元数据优化,解决大量ext遍历引起的业务抖动和磁盘碎片问题
问题
在存在大量写入和删除操作的场景,如果删除了B+tree的最后一块数据,内存中的avail跳表需要清理这个ext-n + 1这个最末尾的ext元数据,同时avail跳表指针会指向NULL。
当有新的数据写入,由于MongoDB默认_id为自增写入,新数据会写到磁盘文件末尾,同时内存中会新生成一个ext元数据,这时候就需要遍历整个avail跳表找到最后一个ext,然后新创建的ext添加到ext-n后面,这是个非常高频的操作并且跳表中ext元素个数上千万个,因此非常消耗CPU并影响性能。
该PR优化前
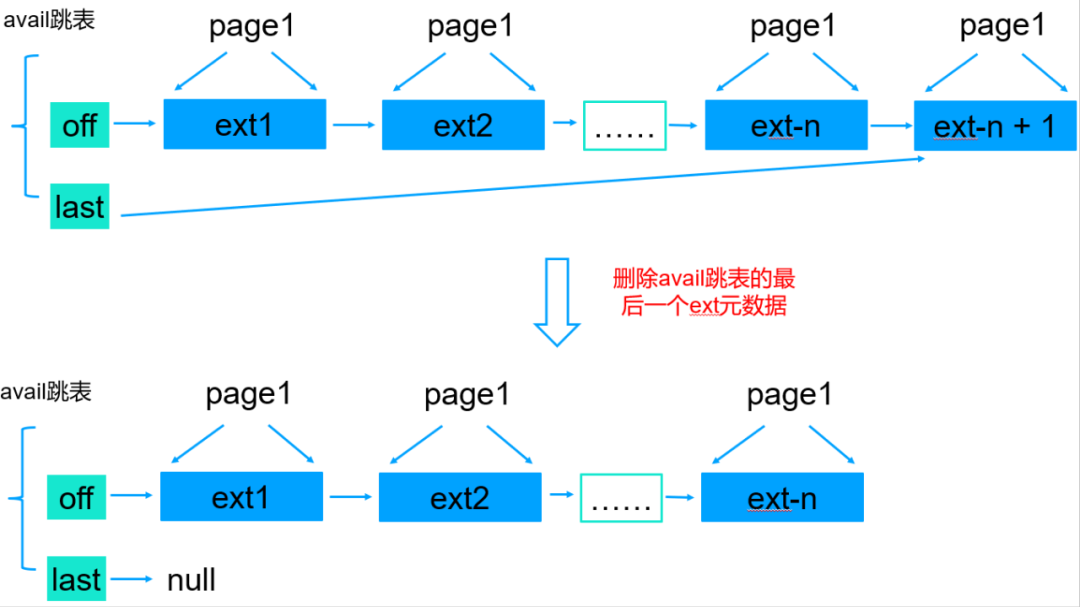
该PR优化后
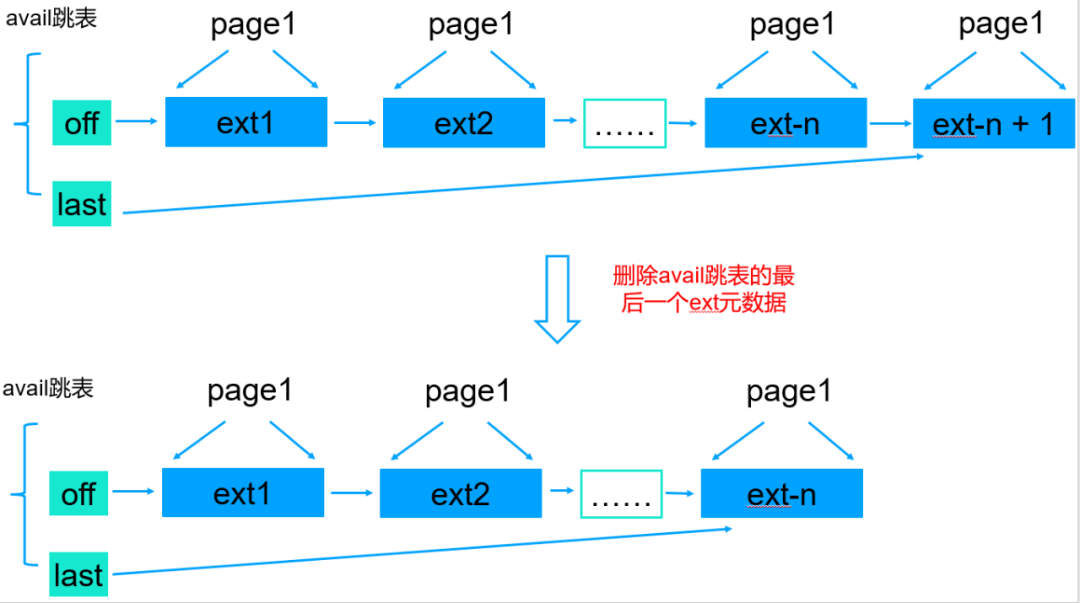
从上面的优化可以看出,删除最后一个ext元数据的时候,last指针指向倒数第二个ext,这样当新的数据追加到文件末尾的时候就不需要遍历整个跳表了。
说明: 上图中我用链表表示的,实际上WiredTiger存储引擎使用的跳表管理磁盘block块的元数据,也就是ext avail跳表,跳表图形化不太好展示,因此这里我用链表代替,不影响理解。
1.17. Checkpoint scrub状态异常修复,并新增scrub诊断统计功能
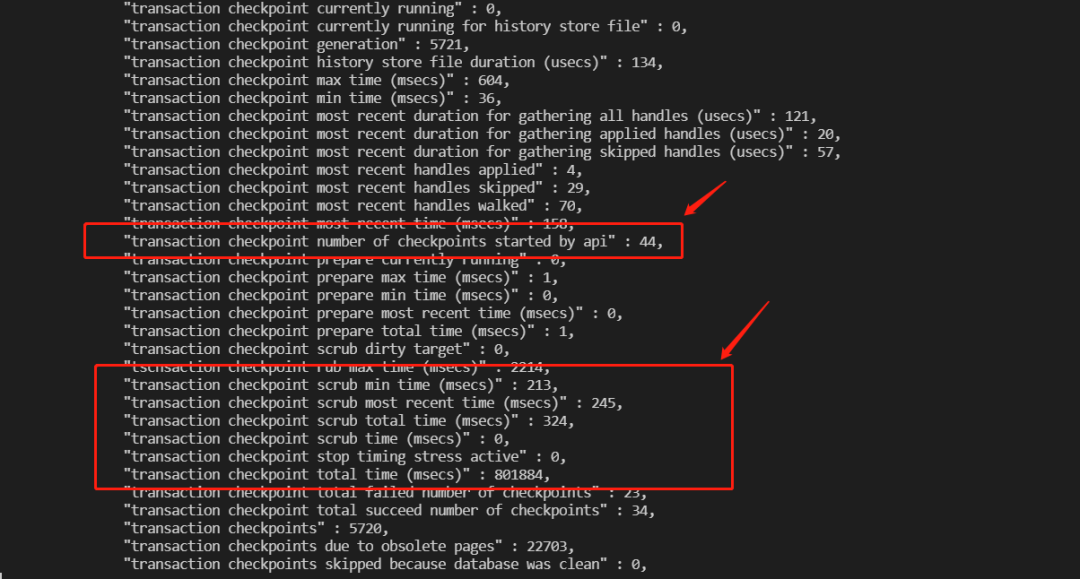
除了修复异常问题,我们还新增了对checkpoint crub的诊断统计功能,帮助用户快速分析checkpoint crub问题。
1.18. Wtperf新增性能耗时分析功能
该PR优化前
该PR优化后
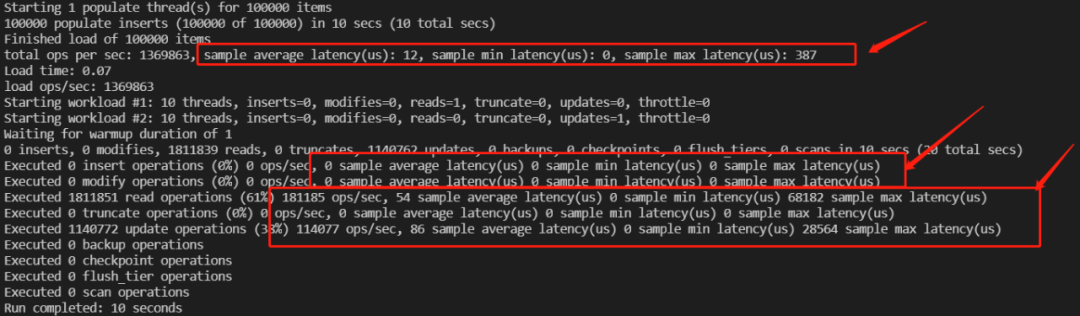
在不影响性能的情况下,在wtperf中新增采样耗时统计功能,帮助用户直观分析WiredTiger存储引擎时延性能。
1.19. wt block支持明文分析wt文件功能
PR优化前
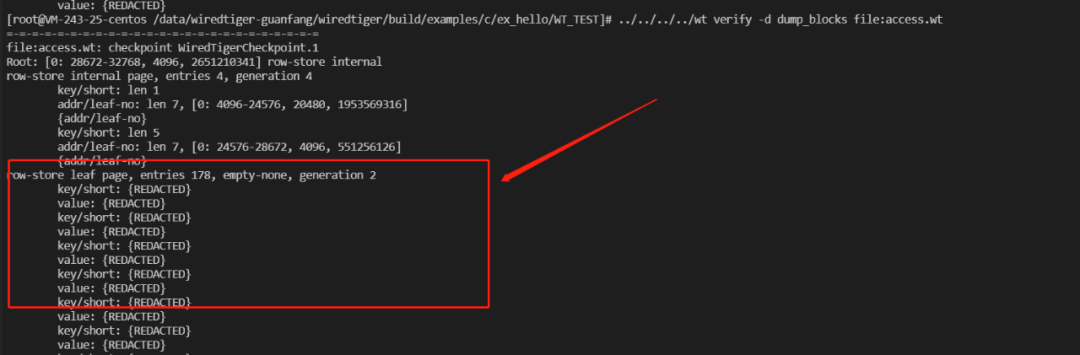
PR优化后
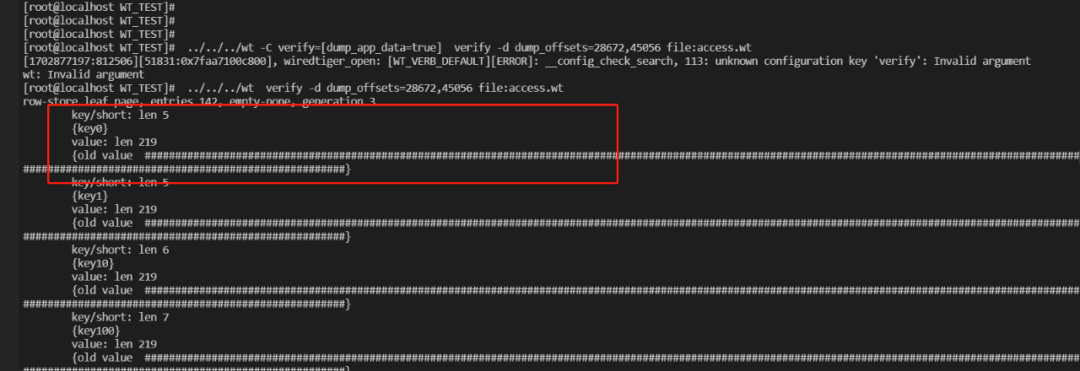
支持该功能后,wt dump block能直观获取MongoDB文档真实内容。
WT-12176
1.20. 解决WiredTiger存储引擎findAndModify耗时不一致问题
Mongod.log有大量1秒以上的慢日志,但是WiredTiger的写延迟没有变化,mongod.log慢日志统计如下:

WiredTiger存储引擎写延迟统计如下:
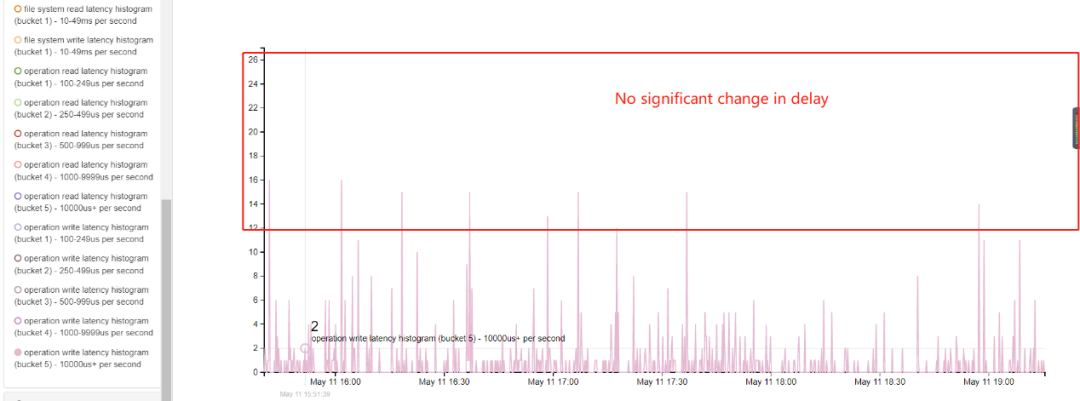
WT-13023
1.21. 优化遍历计数,减少CPU开销
原有计数方式是每个txn事务做一次计数,优化后计数直接一次性计数,减少了for遍历循环。
WT-12782
1.22. Dump KV可视化输出优化,增加内容可读性
该PR优化前

该PR优化后

1.23. 解决history_store verbose调整报错异常问题
该PR优化前
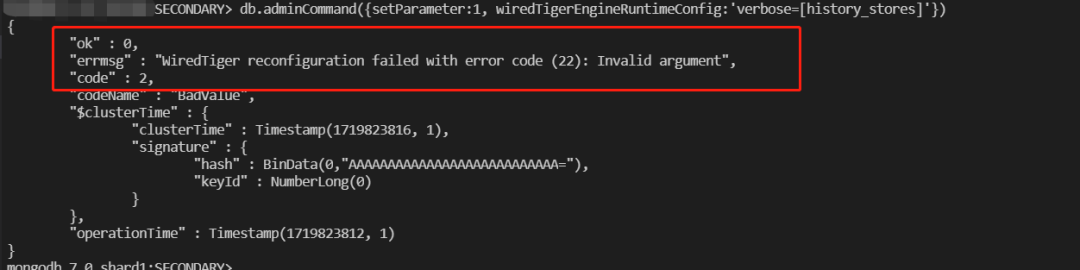
该PR优化后
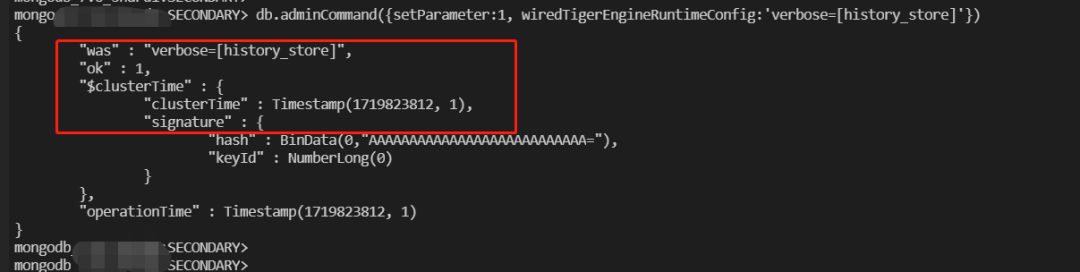
WT-11705
1.24. 解决cursor异常统计不一致问题
解决cursor统计不一致问题。
WT-12566
1.25. Evict评分状态原子状态优化,减少状态异常引起的evict影响
evict_aggressive_score为evict相关线程评估cache压力的重要指标信息,状态异常会影响整个evict server线程和evict worker线程的脏数page淘汰,对用户线程的访问影响较大,原子操作避免不一致带来的evict影响。
WT-12280
1.26. 解决大事务currenid不一致引起的日志分析异常

对大事务进行检测前需要二次加载currenid,确保currenid和oldest id保持最新一致。
WT-13169
1.27. 解决evict worker线程热点数据评分不合理问题
WiredTiger为了尽量选择冷数据(也就是长时间不访问的数据),因此整个设计思路是evict server主线程选择所有的脏page,evict worker线程对这些脏page进行评分,评分低的直接从内存淘汰。
该问题可能引起评分较高的热数据被从内存中淘汰,引起热数据频繁的读盘和写盘。
WT-12279
1.28. 解决evict阻塞情况下无法诊断异常
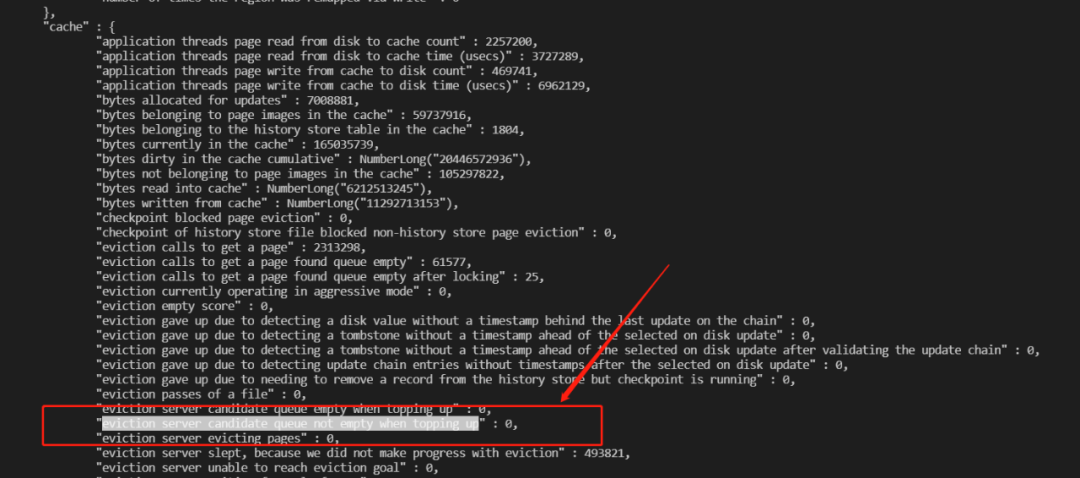
当evict阻塞,cache压力过大的情况,这里会忽略evict阻塞这个验证问题的诊断,我们讲无法通过接口识别。该PR主要是修复这个bug,当evict阻塞,我们可以通过cache_eviction_queue_not_empty统计直观定位该问题。
WT-12250
1.29. 解决eviction_updates_trigger配置过高引起的evict性能问题
当前WT引擎evict相关的配置支持eviction_dirty_trigger、eviction_target、eviction_dirty_target、eviction_target_trigger、eviction_updates_target、eviction_updates_trigger,如果配置eviction_updates_trigger大于eviction_trigger,update将失效。
该PR在配置入口进行配置检测,严格限制eviction_updates_trigger的范围,避免evict潜在风险。
WT-12224
1.30. 解决split异常统计问题
当前不管split正常还是异常都会进行split统计,该PR优化为只有split正常才进行统计操作,这样可以和全局的统计保持一致。
WT-11959
1.31. 解决wt异常引起的mongod进程crush问题

WT-11878
1.32. API_CALL不一致问题修复
Wt api接口调用不一致问题修复。
WT-11402
1.33. 优化事务快照输出信息,收敛无用信息,降低事务分析难度
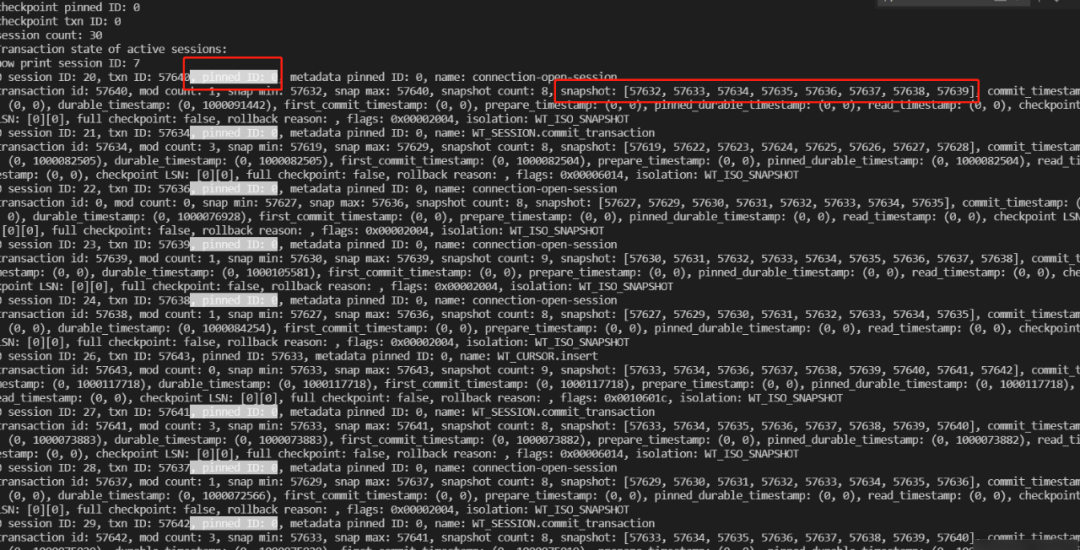
线上服务事务众多,如果无用信息太多,直观影响分析问题的难度,通过优化输出收敛功能,极大降低事务问题分析难度。
WT-13176
1.34. MongoDB新增WiredTiger存储引擎版本信息
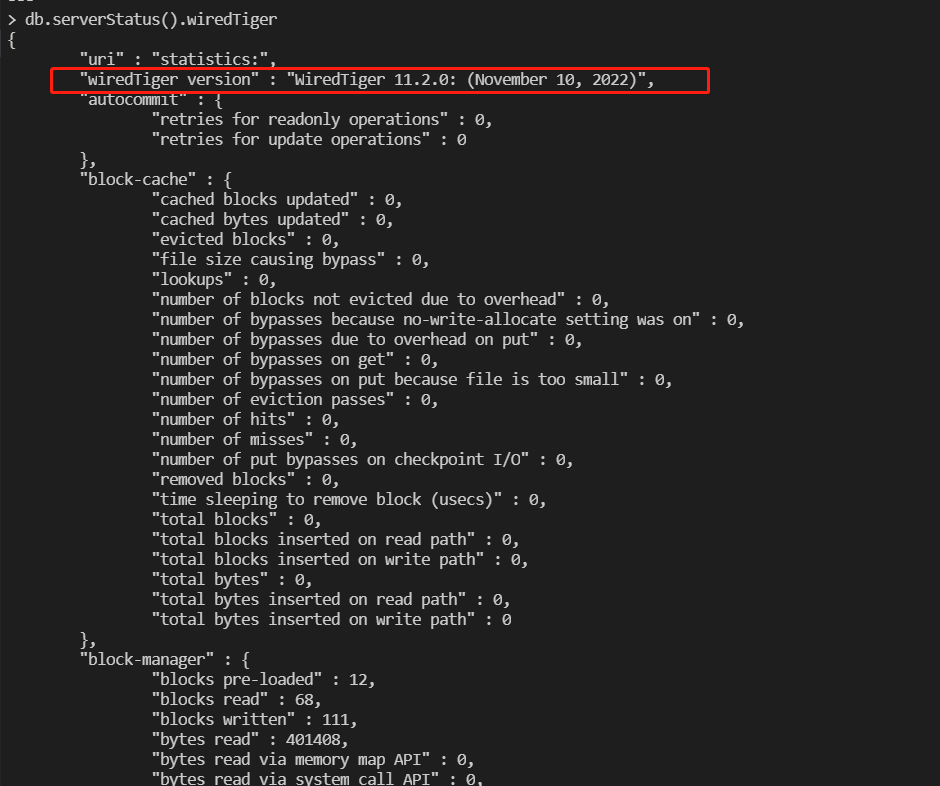
1.35. 其他流程中的PR优化、新feature等
1.35.1. 大事务优化,增加大事务主动回滚功能
当一个update或者delete操作满足的数据非常多的时候,所有被update或者delete的数据会封装到一个事务中,当一个SQL请求满足的条件非常多,例如几百万行,这时候WT引擎会瞬间卡死。
增加最大事务操作行数功能分析及自动回滚功能可以有效避免超大事务带来的整实例不可用问题:
db.adminCommand( { setParameter : 1, "WiredTigerEngineRuntimeConfig" : " max_transaction_modify_count=1000"})
WT-13179
1.35.2. 解决mongod.log慢日志耗时与WiredTiger存储引擎耗时不一致问题
WiredTiger存储引擎写操作主要流程分如下两步:
1.启用事务,KV添加到B+tree内存中
2.提交事务并写WAL日志到磁盘
WT写操作整体耗时只统计了步骤1的耗时,遗漏了事务提交流程和WAL日志落盘流程的耗时,其中WAL日志落盘耗时较长,因此造成了延迟不一致。
WT-13194
1.35.3. MongoDB新增平滑checkpint功能,解决checkpoint引起的CPU毛刺和抖动问题
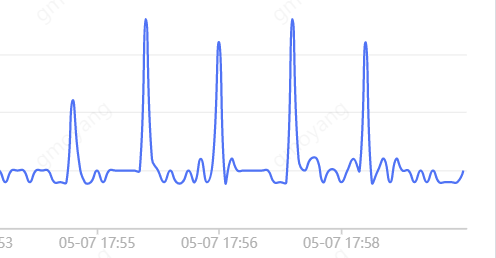
小规格实例,当一个checkpoint周期中如果做checkpoint时候的脏页比较多,这时候节点会有CPU毛刺,用户会有很多的工单上报。
针对该问题的优化方法:限制checkpoint后台线程每秒reconcile持久化的page数,拉长checkpoint执行时间,这样就可以避免checkpoint瞬间持久化所有的脏page引起的CPU消耗。
1.35.4. 新增超大page进行reconcile持久化的诊断统计
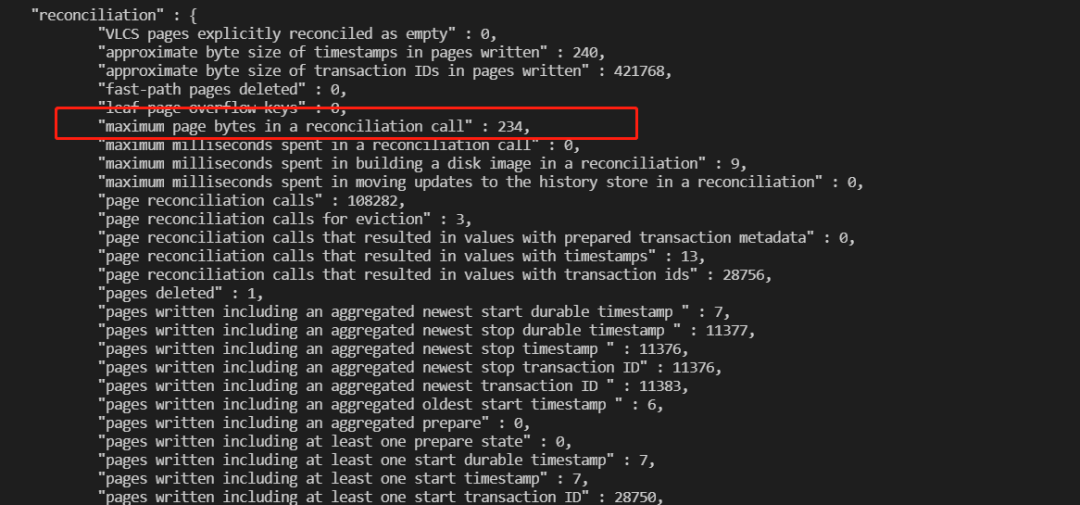
确定本次reconcile的page字节数,这样可以快速确定抖动是否和reconcile持久化大page相关。
WT-13120
1.35.5. rec_page_delete_fast诊断信息对应模块不合理问题修复及调整
rec_page_delete_fast诊断统计不是reconcile逻辑,优化该统计到cache模块统计,该诊断为cache模块统计功能。
WT-13118
1.35.6. 新增对b+tree做checkpoint的timestress模拟功能
当MongoDB定期做checkpoint的时候,如果数据量过大、脏页较多,单个表做checkpoint耗时会很长,该功能就是模拟这个过程,方便问题模拟和验证。
WT-13117
1.35.7. 修复wt引起的mongod数据丢失问题
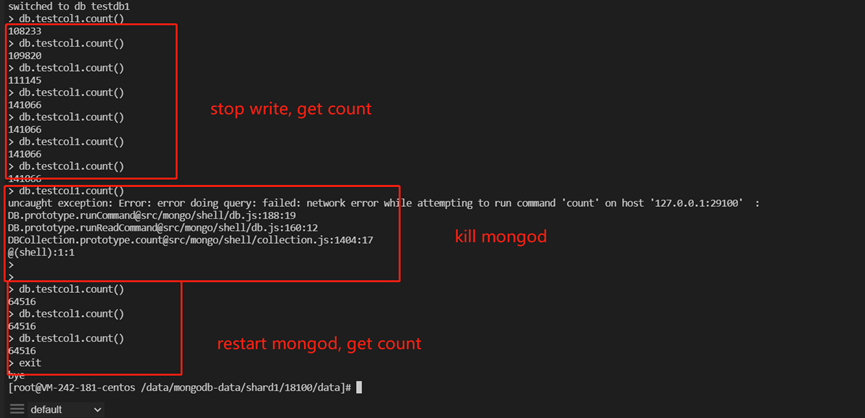
WT-13302
1.36. 其他更多
详见: 阅读原文
2. 后续MongoDB/WiredTiger社区贡献预告
结合腾讯云线上遇到的高频性能问题,腾讯云会持续输出已贡献PR的详细细节,以及MongoDB底层核心设计与实现系列技术文章,主要包括:
1、腾讯云MongoDB路由底座优化实现细节
2、腾讯云MongoDB存储引擎page优化实现细节
3、腾讯云MongoDB IO优化实现细节
4、MongoDB/WiredTiger底层核心设计与实现
3. 欢迎使用腾讯云MongoDB