




前言
在现代的搜索和分析应用中,Elasticsearch 已经成为不可或缺的组件。
随着 Elasticsearch 8.X 的发布,其 Java 客户端 API 也有了显著的更新。

本文将基于完整的 Java 代码,详细介绍如何在工程中使用 Elasticsearch 8.X 的最新 Java API Client。
干货 | Elasticsearch Java 客户端演进历史和选型指南
通过替换示例代码中的部分内容,可以将其直接应用于实际的项目开发中。
一、8.X 最新 Java API Client特性概览
1. 强类型请求和响应
类型安全
自动完成支持
针对所有的 Elasticsearch API,客户端都提供了强类型的请求和响应对象,减少了运行时错误的可能性。
强类型的设计使得 IDE 可以更好地提供代码提示和自动完成,提高开发效率。
2. 同步和异步 API
同步操作
异步操作
适用于需要按照顺序执行的操作,确保每个请求都在前一个请求完成后执行。
提供非阻塞的方式执行 API 调用,适用于需要高并发或对响应时间敏感的应用。
3. 流式构建器和函数式编程模式
流式接口
函数式编程
使用链式调用方式,可以简洁地构建复杂的请求。
通过 Lambda 表达式,简化代码编写,提高可读性。
4. 无缝集成对象映射器
Jackson 支持
默认使用 Jackson 作为 JSON 解析库,方便将自定义的 Java 对象与 JSON 数据相互转换。
JSON-B 支持
也可以选择使用任何实现了 JSON-B 标准的库,满足不同项目的需求。
5. 基于底层 REST 客户端的协议处理
协议抽象:
连接管理:
连接池管理:自动管理 HTTP 连接池,提高性能。 重试机制:在请求失败时,客户端可以自动重试 节点发现:支持自动发现集群中的节点,实现负载均衡。
将协议处理委托给底层的 HTTP 客户端,如 Java Low Level REST Client。
处理 HTTP 连接池、重试机制、节点发现等底层细节,开发者无需关注。
二、环境准备
在开始之前,确保我们已经在本地或服务器上成功安装并运行了 Elasticsearch 8.X。同时,我们的开发环境需要具备以下条件:
Java 版本:JDK 1.8 或更高版本 依赖库:Elasticsearch Java API Client 在 pom.xml 文件中添加以下依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.mingyi.cn</groupId>
<artifactId>ESJavaClient</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.11.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>
</project>
三、Elasticsearch 客户端初始化
1. 基于 HTTPS 的客户端初始化
Elasticsearch 8.X 默认开启了安全特性,需要通过 HTTPS 进行通信。以下是初始化客户端的主要步骤:
设置认证信息:使用用户名和密码进行身份验证。
加载 CA 证书:用于建立安全的 SSL 连接。
配置 SSL 上下文:创建 SSLContext,用于 HTTP 客户端构建。
// 设置用户名和密码
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials("elastic", "your_password"));
// 加载 CA 证书
Path caCertificatePath = Paths.get("path/to/http_ca.crt");
CertificateFactory factory = CertificateFactory.getInstance("X.509");
Certificate trustedCa;
try (InputStream is = Files.newInputStream(caCertificatePath)) {
trustedCa = factory.generateCertificate(is);
}
// 配置 SSL 上下文
KeyStore trustStore = KeyStore.getInstance("pkcs12");
trustStore.load(null, null);
trustStore.setCertificateEntry("ca", trustedCa);
SSLContextBuilder sslContextBuilder = SSLContexts.custom()
.loadTrustMaterial(trustStore, null);
final SSLContext sslContext = sslContextBuilder.build();
// 构建 RestClient
RestClientBuilder builder = RestClient.builder(
new HttpHost("localhost", 9200, "https"))
.setHttpClientConfigCallback(httpClientBuilder -> httpClientBuilder
.setSSLContext(sslContext)
.setDefaultCredentialsProvider(credentialsProvider)
.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE));
RestClient restClient = builder.build();
// 创建 Elasticsearch 客户端
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
ElasticsearchClient client = new ElasticsearchClient(transport);
2. 使用 API Key 的客户端初始化(可选)
如果希望使用 API Key 进行认证,可以按照以下方式配置:
String apiKeyId = "your_api_key_id";
String apiKeySecret = "your_api_key_secret";
String apiKeyAuth = Base64.getEncoder().encodeToString(
(apiKeyId + ":" + apiKeySecret).getBytes(StandardCharsets.UTF_8));
Header[] defaultHeaders = {
new BasicHeader("Authorization", "ApiKey " + apiKeyAuth)
};
builder.setDefaultHeaders(defaultHeaders);
四、基本操作示例
1. 创建索引
public void createIndex(String indexName) throws IOException {
client.indices().create(c -> c.index(indexName));
}
2. 索引文档
public void indexDocument(String indexName, String id, Map<String, Object> document) throws IOException {
client.index(i -> i.index(indexName).id(id).document(document));
}
3. 搜索文档
public SearchResponse<Object> search(String indexName, List<Query> queries, List<SortOptions> sortOptions, int page, int pageSize) throws IOException {
SearchRequest.Builder searchRequestBuilder = new SearchRequest.Builder()
.index(indexName)
.from(page * pageSize)
.size(pageSize)
.query(q -> q.bool(b -> b.must(queries)));
if (sortOptions != null && !sortOptions.isEmpty()) {
searchRequestBuilder.sort(sortOptions);
}
return client.search(searchRequestBuilder.build(), Object.class);
}
4. 聚合查询
public SearchResponse<Object> aggregateSearch(String indexName, List<Query> queries, Map<String, Aggregation> aggregations) throws IOException {
return client.search(s -> s
.index(indexName)
.query(q -> q.bool(b -> b.must(queries)))
.aggregations(aggregations), Object.class);
}
5. 脚本排序示例
public SearchResponse<Map> searchWithScriptSort(String indexName, String fieldName, String queryText, String scriptSource, double factor) throws IOException {
Query query = MatchQuery.of(m -> m.field(fieldName).query(queryText))._toQuery();
Script script = Script.of(s -> s.inline(i -> i
.source(scriptSource)
.params("factor", JsonData.of(factor))));
SortOptions sortOptions = SortOptions.of(so -> so.script(ss -> ss
.script(script)
.type(ScriptSortType.Number)
.order(SortOrder.Asc)));
SearchRequest searchRequest = new SearchRequest.Builder()
.index(indexName)
.query(query)
.sort(sortOptions)
.build();
return client.search(searchRequest, Map.class);
}
五、完整代码示例
以下是完整的代码示例,大家可以根据需要进行替换和修改,以适应咱们自己的工程需求。
public class ElasticsearchService {
private static final Logger logger = LoggerFactory.getLogger(ElasticsearchService.class);
private ElasticsearchClient client;
// 构造函数,初始化客户端
public ElasticsearchService() throws CertificateException, IOException, KeyStoreException, NoSuchAlgorithmException, KeyManagementException {
// 初始化代码(参考前文)
}
// 创建索引
public void createIndex(String indexName) throws IOException {
client.indices().create(c -> c.index(indexName));
}
// 索引文档
public void indexDocument(String indexName, String id, Map<String, Object> document) throws IOException {
client.index(i -> i.index(indexName).id(id).document(document));
}
// 搜索文档
public SearchResponse<Object> search(...) throws IOException {
// 实现代码(参考前文)
}
// 聚合查询
public SearchResponse<Object> aggregateSearch(...) throws IOException {
// 实现代码(参考前文)
}
// 脚本排序示例
public SearchResponse<Map> searchWithScriptSort(...) throws IOException {
// 实现代码(参考前文)
}
// 主方法示例
public static void main(String[] args) {
try {
ElasticsearchService service = new ElasticsearchService();
String indexName = "my-index";
// 创建索引
service.createIndex(indexName);
// 索引文档
Map<String, Object> document = new HashMap<>();
document.put("title", "Elasticsearch Basics");
document.put("author", "John Doe");
document.put("content", "This is a tutorial for Elasticsearch.");
service.indexDocument(indexName, "1", document);
logger.info("Document indexed.");
// 刷新索引
service.client.indices().refresh(r -> r.index(indexName));
// 搜索示例
Query query = QueryBuilders.match(m -> m.field("title").query("Elasticsearch"));
List<Query> queries = Arrays.asList(query);
SearchResponse<Object> response = service.search(indexName, queries, null, 0, 10);
response.hits().hits().forEach(hit -> logger.info(hit.source().toString()));
// 聚合查询示例
Aggregation aggregation = AggregationBuilders.terms(t -> t.field("author.keyword"));
Map<String, Aggregation> aggMap = new HashMap<>();
aggMap.put("author_count", aggregation);
SearchResponse<Object> aggResponse = service.aggregateSearch(indexName, queries, aggMap);
aggResponse.aggregations().forEach((key, agg) -> logger.info(key + ": " + agg));
// 脚本排序示例
String scriptSource = "doc['content.keyword'].value.length() * params.factor";
double factor = 1.1;
SearchResponse<Map> scriptSortResponse = service.searchWithScriptSort(indexName, "content", "Elasticsearch", scriptSource, factor);
scriptSortResponse.hits().hits().forEach(hit -> logger.info(hit.source().toString()));
} catch (Exception e) {
logger.error("Error occurred:", e);
}
}
}
六、注意事项
6.1 认证方式
Elasticsearch 8.X 默认开启了安全认证,我们需要根据实际情况选择使用用户名密码认证或 API Key 认证。
6.2 SSL 证书
确保正确加载了 Elasticsearch 提供的 CA 证书,以建立安全的 SSL 连接。
6.3 依赖版本
请确保使用的 Elasticsearch Java API Client 版本与 Elasticsearch 服务器版本匹配。
七、总结
本文详细介绍了如何使用 Elasticsearch 8.X 的最新 Java API 进行客户端初始化、索引操作、搜索和聚合查询。
通过完整的代码示例,我们可以直接将其应用于工程开发中。希望本文能对大家在使用 Elasticsearch 进行开发时提供帮助。
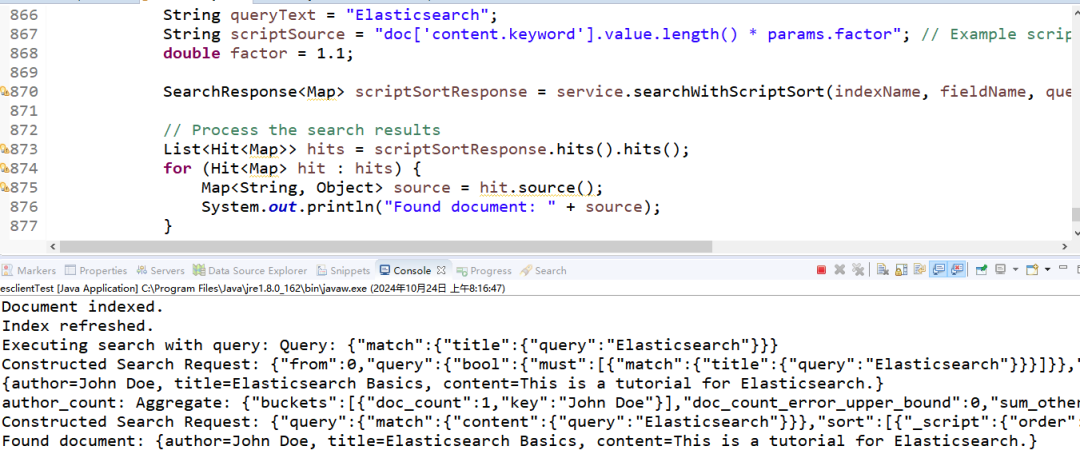
执行成果截图
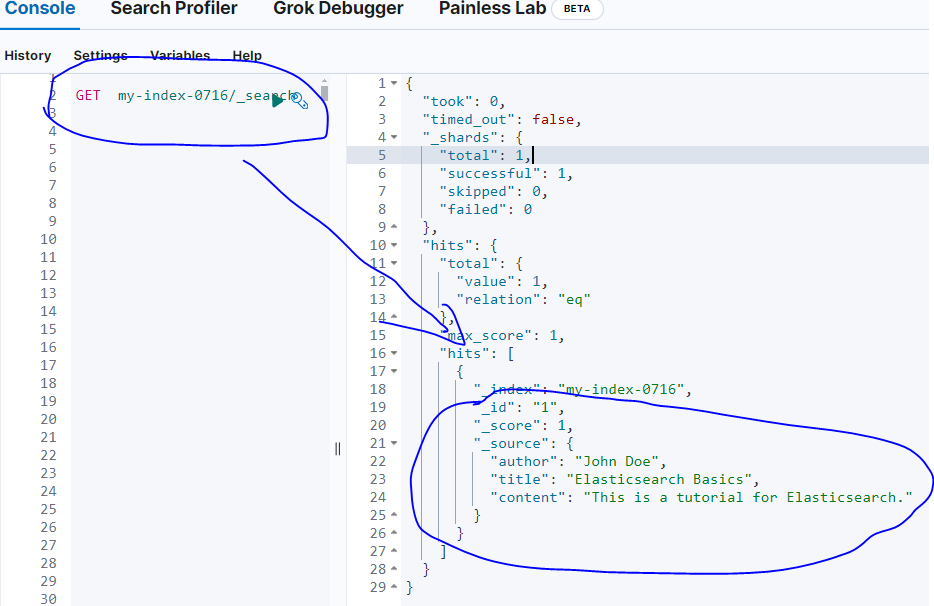
新写入索引数据
完整可用工程下载地址:https://t.zsxq.com/yLZmm
七、参考资料
Elasticsearch Java API Client 官方文档 https://www.elastic.co/guide/en/elasticsearch/client/java-api-client/current/index.html 干货 | Elasticsearch Java 客户端演进历史和选型指南 Elasticsearch 安全通信配置 云服务器 Centos7 部署 Elasticsearch 8.0 + Kibana 8.0 指南 Elasticsearch 聚合查询 基于儿童积木玩具图解 Elasticsearch 聚合

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

