




接上一篇:PolarDB-X 列存索引 | 列存引擎的诞生(一)
2. 列存引擎
列存引擎从大的功能方向上看,主要负责两件事:事务同步,列式存储。同步指能够从行存数据中同步到列存,保证行列数据一致。存储指可以将行存数据转成列式存储,形成一个个列式存储文件。当然,列存存储引擎作为一个产品,还需在高可用、持久化、数据校验、存储空间等方面进行设计,逐步将产品优化并完善,以最终满足业务生产的所有需求,从而发展为成熟的工业级解决方案。
2.1 事务同步
PolarDB-X属于MySQL生态的分布式数据库产品,数据同步是MySQL生态不同产品进行数据流动的重要手段,MySQL 通过 Binlog 机制实现了与下游系统的实时增量数据同步,例如Kafka、Canal、DTS等同步工具,都支持通过binlog进行上下游同步。PolarDB-X在早期便启动全局binlog计划,已经有CDC节点,将分布式数据库下的多个DN的Binlog进行合并排序,形成全局一致的binlog,可供其它Mysql生态系统或工具进行增量数据同步。更多CDC相关内容可查看以往CDC历史文章。
PolarDB-X为了实现分布式事务的高可用和一致性,引入了全局时间戳功能(TimeStampOracle,TSO),每一个事务提交时都包含一个TSO值(Commit TSO,CTS),CDC节点对事务的排序也是按照CTS值顺序,形成全局binlog,可行的理论分析可见PolarDB-X 全局 Binlog 解读之理论篇。这意味着PolarDB-X的全局binlog相比于普通binlog,为每一个事务新增了CTS值记录,CTS值代表该事务的提交时间戳,该值有序递增,CTS值也可认为是行存的一个快照点,进而可衍生为行存快照的一个快照版本,请记住该值,该值和列存索引也息息相关。
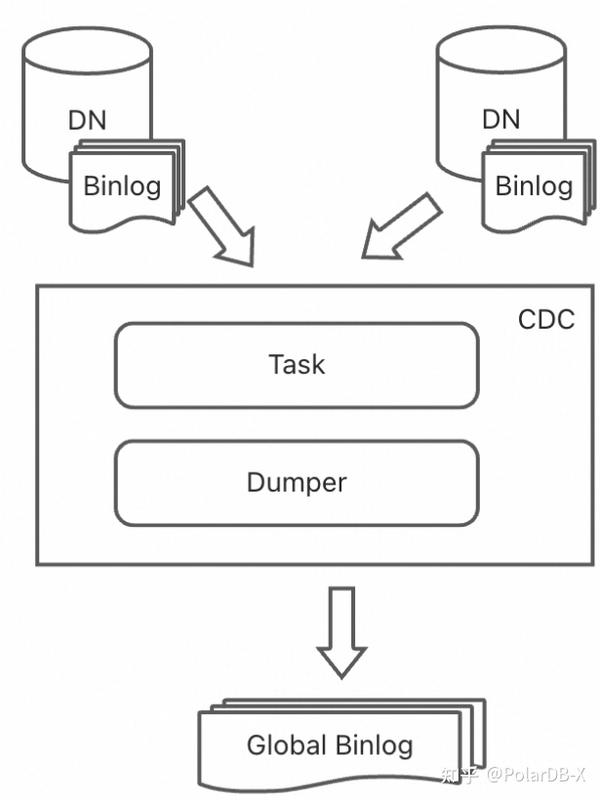
列存引擎继续兼容MySQL生态,将通过binlog来进行增量数据同步,而在PolarDB-X中,则通过全局binlog来进行数据消费,让列存索引的数据和行存数据一致,全局binlog可看成是所有DML操作的日志记录,简单理解可认为是一个个事务操作记录,如下图所示:
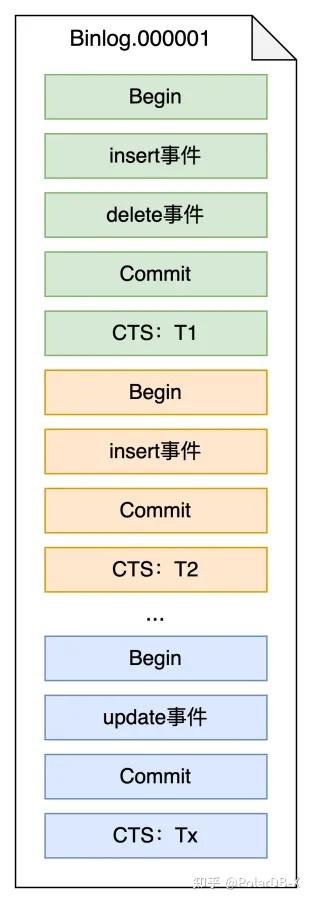
所有的数据修改记录成一个个事务方式,且每个Commit事件后会有一个CTS记录,代表该事务的提交TSO值,列存引擎则通过消费一个个binlog文件,检测到包含列存索引的表,则对应的Insert/Delete/Update事件需要进行数据同步,完成数据写入列存。列存引擎消费binlog将会以事务为单位,以保证事务一致性,不会在事务中间提交。消费binlog事件是一个串行操作,为了提高消费效率,攒批消费,通过batch方式能够极大提高消费速度,但是攒批意味着需要等待时间,如何平衡性能和行列延迟也是需要考虑的。
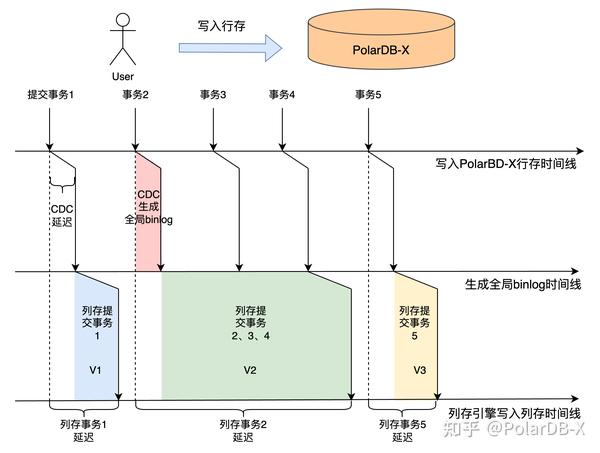
如上图所示,用户写入PolarDB-X行存,依次提交事务1~5,PolarDB-X的CDC节点需要一定时间生成全局binlog,这部分延迟比较小,一般在几百毫秒以内,列存引擎消费binlog事件,可以发现,如果列存引擎攒批一起提交,需要等一定时间,会导致列存与行存之间的延迟增大,而Batch攒批方式能够加速消费binlog速度,所以列存引擎会根据流量来判断提交时机,当数据量达到一定大小或者列存延迟达到阈值,便触发一次提交,以保证列存与行存之间的延迟不会太大。同时,每一次列存引擎提交数据,都会产生一个列存版本快照,如图中所示V1、V2、V3,binlog事件包含CTS值,所以列存版本会以该值作为版本号,记录下TSO值,该事务提交TSO值与行存事务可见性相关,因此,可以得到一个列存版本快照对应的行存快照,为后续列存和行存数据校验是否一致提供了理论基础。
2.2 列式存储
列存引擎的数据输入有了,通过消费binlog事件,以一个或多个事务为间隔进行提交,每一个事务包含Insert/Delete/Update事件,这三种事件代表了DML操作,可以发现,这些事件的组合是以行存为基础,一行一行数据进行消费,列存引擎需要将这些数据转成列式存储,上传到共享存储OSS中。
首先,在列式存储文件格式上,PolarDB-X选择了Apache ORC格式,Apache ORC是一种高效的列式存储格式,专为Hadoop生态系统设计,旨在提高大规模数据存储和处理效率,在数仓场景和分析型查询方面应用广泛。
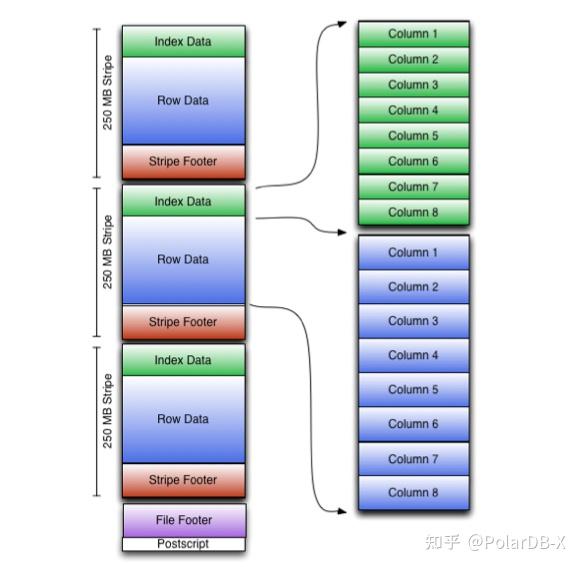
Orc格式以stripe为单位,每个stripe内存储数据,并包含索引信息,文件尾部记录了每个stripe的位置,便于快速定位到数据位置,具有如下几个特点:
- 高性能:经过长期优化,已是较为成熟的产品,IO读写性能较高
- 高压缩率:支持多种压缩算法,例如ZLIB, SNAPPY, LZO, LZ4, ZSTD等
- 灵活的索引结构和统计信息:支持多种索引,内嵌多种统计信息,例如最大值、最小值等
- 数据结构丰富:支持复杂数据类型,包括structs、lists、maps等
列式存储格式确定,下面需要考虑如何高效行存转列存,设计合适的存储模型,考虑几个限制:
- 共享存储OSS只支持追加写,不支持随机修改
- Orc列式格式一般是批量数据,单个文件内容较大
想象一种最简单的场景,只包含Insert操作,所有数据都是有效数据,最直接的存储结构如下图所示:
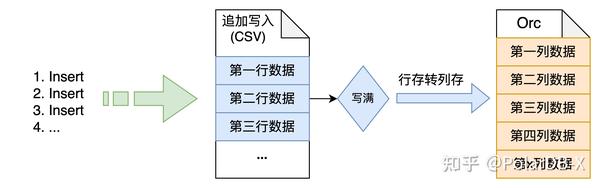
可以通过先追加写入CSV文件,等文件写满,把整个文件的行式存储转成ORC列式存储文件,就是一个完整的流程。实际场景则有Delete操作,Update操作,对已有数据的修改,将会增加存储架构的复杂度,常见做法有如下几种:
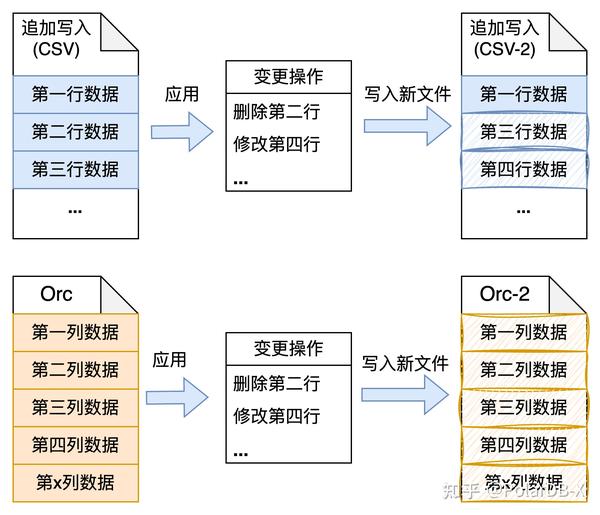
第一种,Copy on write(COW)模型:指当执行数据更新时,从原来的数据复制出来一个副本,在副本上进行数据更新,当副本更新完成后把原始数据替换为当前副本。如下图所示,该方式对于文件更新来说是灾难性的操作,往往每个文件可能只会更改少部分数据,但是需要重写整个文件,写放大问题严重,所以COW更适合数据块单位较小的数据结构,例如B+树结构,对某个数据节点进行更新时,则可通过COW方式更新数据,带来的写放大也可以接受。
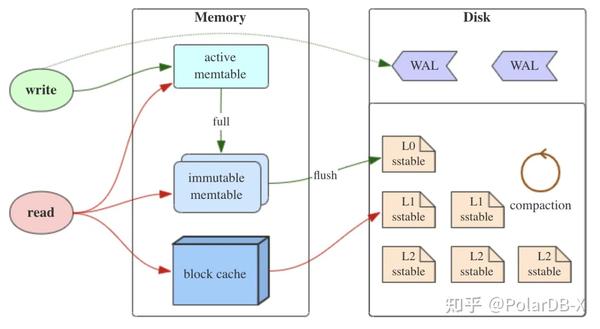
第二种方式,LSM树方式:指使用LSM树结构存储数据,将随机写入改成顺序写入,Delete/Update也可以追加写入数据,代表该值的新版本数据,在内存中写满阈值后,形成一个个SST文件,后台通过compaction进行数据合并,去除冗余数据和排序数据。如下图所示,将SSTable文件格式改成列式存储,能够较好适配写入,但是读取性能由于需要读多层数据,涉及文件较多,需归并处理,对读性能牺牲较大。
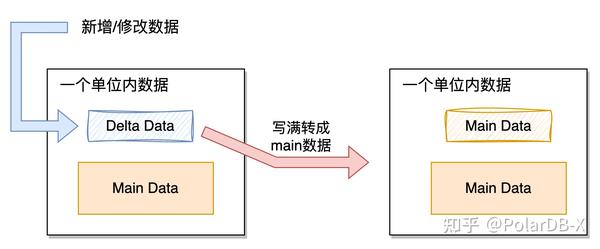
第三种方式,Delta Main模型(类LSM树结构):利用LSM树思想,写入时依然顺序写入数据,数据更改也是追加记录,追加记录认为是Delta Data(增量数据),等Delta Data写满阈值,转成Main Data数据(主体数据),一个单位内的数据可以认为是一段范围内的数据、一个分区内的数据或者一个文件内的数据,可根据实际情况进行分隔,这样对读性能进行优化,一段范围内的数据只需要读取Main Data和Delta Data,需要归并的数据大大降低,并且利用后台异步线程尽可能将Delta Data数据转成Main Data,进一步减少读开销。
PolarDB-X的列存引擎采用Delta Main模型(类LSM树结构),兼顾写性能与读性能。在此基础上,设计通过binlog同步列存数据的存储结构,在该场景下尽可能找到最合适的存储模型。
首先在数据布局方面,列存引擎沿用了PolarDB-X的分区策略,可通过特定的分区规则将数据切割成若干个分区,可将列存索引数据分割成一个个分区数据,对于并行写入和并行读取都能有收益,目前支持Hash/Key/Range/List等分区策略,更多分区相关内容可参见。
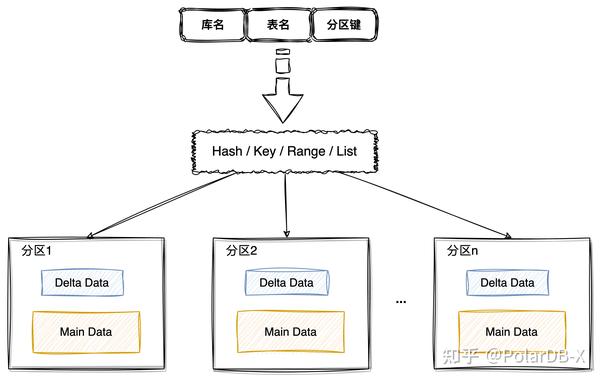
在单个数据分区内,随着不断同步binlog数据,列存引擎会批量提交事务,这个动作称为Group Commit,会把Insert/Delete/Update操作在数据所在分区进行写入,所有分区更改一起并行事务提交,数据写入文件,元数据(列存索引元信息、文件元信息等)写入MetaDB,事务提交需保证原子性,同时提交会让列存数据版本进行更新,记录下同步到的binlog位点,如果提交出错,列存引擎重新从已提交版本的binlog位点开始同步即可。具体的Group Commit操作如下图所示:
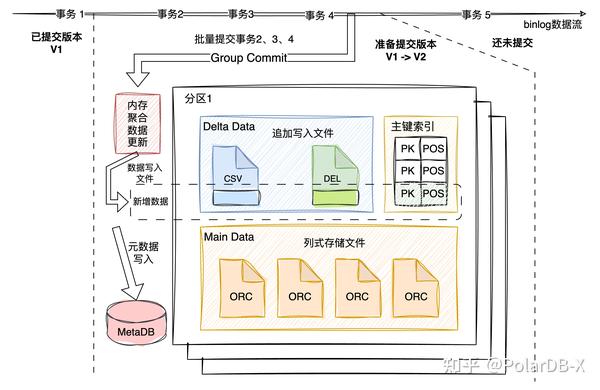
Group Commit操作对binlog事件类型进行不同处理:
- Insert事件,代表新增数据,将数据追加写入CSV文件(代表追加写入的新增数据)。
- Delete事件,代表删除某行数据,需要增加删除标记,删除标记为哪个文件的哪行数据是无效的,所以会为每个文件构建bitmap标记,需要删除,则增加标识,bitmap采用的RoaringBitmap,RoaringBitmap支持序列化、反序列化,OR操作合并bitmap等,每次提交某文件需要增加删除标记,则新增该bitmap的序列化数据,读取时,将该文件的所有bitmap通过OR操作合并成一个bitmap,则是该文件的所有删除标记,一个分区内的所有文件bitmap数据会不停追加写入DEL文件中(实际为bitmap序列化数据),因为bitmap数据一般比较小,聚合到一个文件中,以避免小块数据写入。
- Update事件,Update事件实际转为Delete操作+Insert操作。
- DDL事件,ddl事件会单独提交,不会和数据更改操作一起提交,所以DDL事件会单独执行DDL操作。
可以发现,图中还存在一个主键索引,该作用便是Delete事件快速定位到该行数据的位置(哪个文件,文件位置),才方便增加删除标记,所以列存引擎会维护一个<主键,位置>的键值存储(Key-Value Store),每行数据都会有一个主键值代表其唯一性,而位置信息则是{文件id,第几行index},4B+4B字节大小即可,所以主键索引是一个小value的KV持久化存储。
Group Commit由于是批量事务一起提交,包含多个Insert/Delete/Update操作,所以列存引擎可以先在内存聚合更改,对于同一个主键值的不同操作,可直接在内存就去除中间的冗余历史版本,以减少提交操作,例如insert,然后Delete该行数据,无需额外写入,对于同一主键的任意写入行为,可拆解成一下几种情况:
| 操作类型(同一主键值) | 操作 | merge结果 |
| Insert | mem.add(pk, row) | \ |
| Delete | mem.remove(pk) | \ |
| Update | mem.remove(pk, row1)mem.add(pk, row2) | \ |
| Insert-Insert | \ (主键冲突,非预期) | \ |
| Insert-Delete | mem.add(pk, row)mem.remove(pk) | nothing |
| Insert-Update | mem.add(pk, row1)mem.remove(pk, row1)mem.add(pk, row2) | mem.add(pk,row2) |
| Update-Insert | \ (主键冲突,非预期) | \ |
| Update-Delete | mem.remove(pk, row1)mem.add(pk, row2)mem.remove(pk, row2) | mem.remove(pk,row1) |
| Update-Update | mem.remove(pk, row1)mem.add(pk, row2)mem.remove(pk, row2)mem.add(pk, row3) | mem.remove(pk,row1)mem.add(pk,row3) |
| Delete-Insert | mem.remove(pk)mem.add(pk, row) | mem.remove(pk)mem.add(pk, row) |
| Delete-Delete | \ (重复删除,非预期) | \ |
| Delete-Update | \ (修改不存在数据,非预期) | \ |
可以发现,有一些操作之间可以合并简化,减少中间数据提交。
从列存只读节点读取列存数据视角来看,列存数据版本中,每个分区内包含三种文件:
- CSV文件:追加写入的行式存储数据,因为数据是一行一行写入的多列数据组合,看起来和csv格式类似,所以称呼csv文件,但并不是大家通常理解的文本格式的文件。PolarDB-X的csv数据格式,采用了特殊二进制的序列化,可以避免常用csv格式下的分隔符之类的问题。同时当csv文件长度或行数达到阈值时,会进行compaction,转成列式存储的ORC文件。
- ORC文件:列式存储格式的文件数据,一旦生成,不会再修改,也是列式存储的主体数据,一个个文件代表了一段范围的数据,文件内是有序排列的。
- DEL文件:记录一个分区内所有文件的删除bitmap标记数据,相当于每一个CSV或ORC文件都有一个对应的bitmap数据,数据存储在DEL文件中。
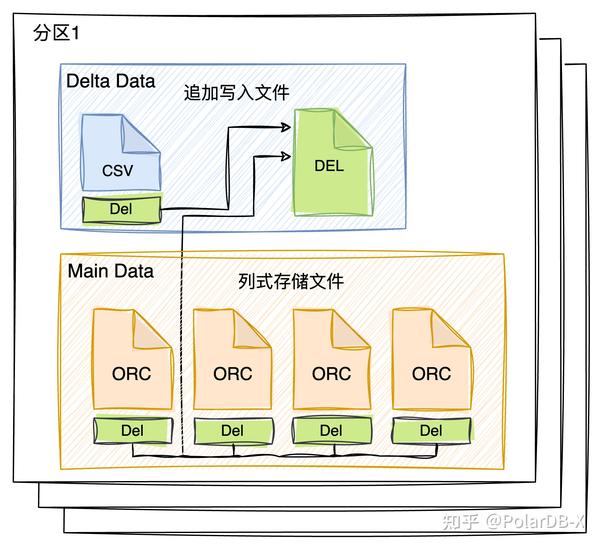
可以发现,读取时应尽可能缓存Delta Data,特别是DEL数据,这样读取某个ORC文件时,便能快速过滤无效数据,所以让DEL数据常驻内存是收益较大的,同时ORC文件是范围有序的,通过排序键进行排序,能够较好地进行裁剪,读取符合条件的数据,而CSV文件是无序的,无法裁剪,这部分数据缓存起来也能提高读取性能,因此,Delta Data应尽量小,且优先缓存。
列存的主键索引不参与列存读节点进行读取,原因:
- 目前功能是为了列存引擎写节点定位主键所在文件位置,如果读节点也可访问KV存储,分布式并发读写访问KV存储,无疑增加KV存储结构复杂度。
- 该KV存储只记录了主键和所在文件位置,对于单个KV读取必然高效,但是这是列存,更多用于大批数据分析查询场景,单行数据查询不如使用行存,也能高效读取。
2.3 列存主键索引
前文讲到,列存引擎包含主键索引来快速定位删除的主键的所在文件位置,方便较快给该文件的bitmap增加删除标记,所以列存的主键索引是一个小value的KV存储,该KV存储结构也是需要进行设计,首先考虑KV存储的使用场景特征:
- KV是主键+文件位置,文件位置信息为{文件id,第几行index},4B+4B=8B字节大小
- KV存储结构需具备持久化特性,存储在共享存储中
- 请求包括Read/Insert/Delete,无需范围读取
- 高性能读取,每次请求可批量操作
常用的KV存储结构主要有:Hash、B+Tree、Radix-Tree、LSM树等。不用范围读取情况下,采用Hash结构无疑是性能最佳的选择,但是目前存在的持久化Hash产品较少,常用于内存中的缓存,持久化还需结合共享存储只能顺序写入的特点,所以PolarDB-X选择自研适用于该场景下的KV存储,结合Hash结构的高性能与LSM树的IO优化,设计了Hash-LSM树的KV存储,无需范围读取的LSM树结构,如下图所示:
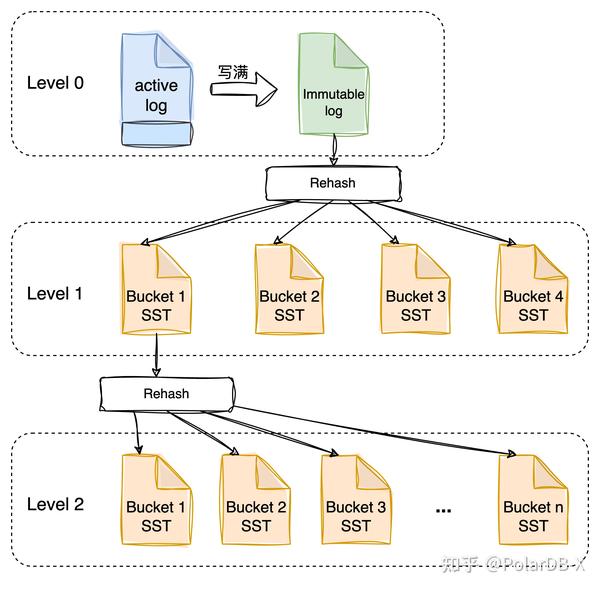
在LSM树结构的基础上进行变化,无需范围排序,当追加写日志写满后,通过hash规则分散数据,每一个Hash Bucket使用SST文件存储数据,如果单个SST文件较大后,又可再次通过hash规则分散数据,可以控制每一个SST的数据大小,以防Hash Bucket过大,导致读取性能下降,读取时,可根据key通过hash规则快速定位到Hash Bucket所在的SST数据中,快速读取该KV值。关于列存主键索引更多设计细节,可查看《PolarDB-X 列存索引 | 高效更新的秘密(PkIndex) 》,大家敬请期待 。
2.4 compaction
列存引擎中还包含一个较为重要的操作,便是compaction,它是文件重新组织的重要操作手段,无论是空间回收,文件排序,都得通过后台异步compaction任务来完成,如下图所示。
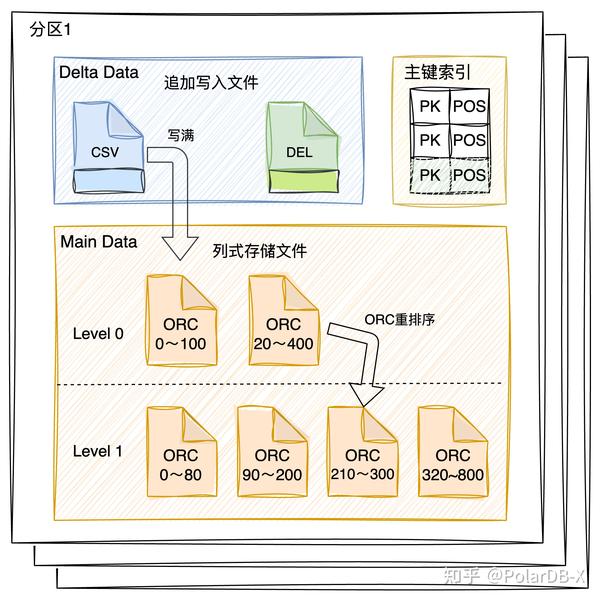
数据会先写入行式存储的csv文件,该文件内的数据是无序的,当一个行式CSV文件写满,需要转成列式存储文件的ORC文件,ORC文件内部是有序的,这个行转成列式的操作,可称为csv compaction。
列存ORC文件组织目前只有两层:
level 0: 该层内文件之间范围可重叠;
level 1: 该层内文件之间范围不可重叠;
只设计两层的原因,尽可能让orc文件间范围不重叠,增加读请求的裁剪能力,提高读性能。大部分情况都是随机写入数据,所以level 1层文件/level 0层文件比例越大,会导致写放大也越大,需要平衡读写性能,常见做法是增加层数,但是PolarDB-X的列存索引还有分区能力,可控制一个分区的数据量大小,所以不会导致数据无限膨胀,导致写放大倍增,两层结构能够适应数据量。
为了防止level 0层文件无限增多,orc文件之间范围不重叠,则需要将对多个orc文件进行重排序,具体操作为选取level 0层的文件,和level 0层所选文件范围有交集的level 1层文件,进行orc文件重排序,最后放入level 1层文件,可称为orc compaction。
PolarDB-X的列存引擎是通过增加delete bitmap来标记每个文件中的删除空洞,当orc文件内的空洞较大时,也可通过重写orc文件,来达到去除无效数据空洞,回收存储空间,可称为delete compaction。
总之,PolarDB-X列存引擎对于需要重新组织文件数据的方式,都可称为comapction,这些任务以后台异步方式调度运行,还有多种不同目的性的compaction任务,这里不再一一概述。
2.5 如何构建列存索引
前面讲述了列存引擎如何同步数据,如果新建列存索引,初始数据为空,开始通过binlog导入数据是可正常服务的,但是实际场景则存在,表内已有数据,或者历史binlog文件已过期不存在,这种情况则需要特殊处理,列存索引的构建流程如下图所示:
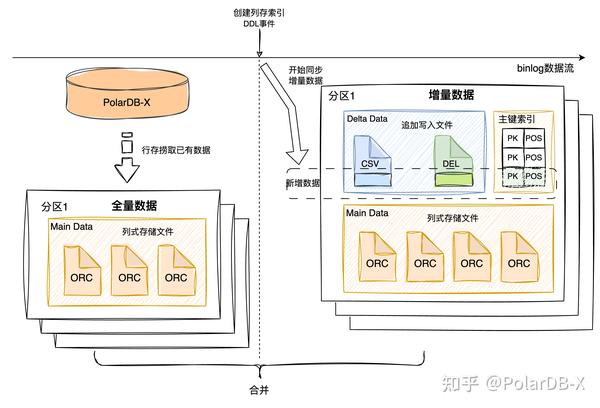
当列存引擎在binlog事件流中,检测到创建列存索引ddl事件后,便开始同步该表DML操作,形成的数据称为增量数据,同时会另起线程去PolarDB-X行存通过select逻辑捞取已有的全部数据,称为全量数据。等全量数据捞取完毕,最后将全量数据和增量数据进行合并,便是该列存索引的所有数据,后续继续同步binlog数据即可。其中,还有挺多实现细节,后续会再出一篇文章详细介绍构建流程。
2.6 高可用
列存引擎在高可用方面采用主备架构,如下图所示,常驻备节点处于启动状态,一旦主节点故障,备节点可迅速选主进行行到列的数据同步,保证列存延迟不高,热备方式能够满足大部分应用场景。只用两节点原因:列存引擎不存储任何数据,无状态的,列存的元数据存储在MetaDB中,MetaDB是三节点paxos架构,具备高可用性,列存的文件数据存储在共享存储中,OSS也具备极高的可用性,随时可通过增加列存引擎写节点,参与选主成为主节点,所以平时一个备节点足够。
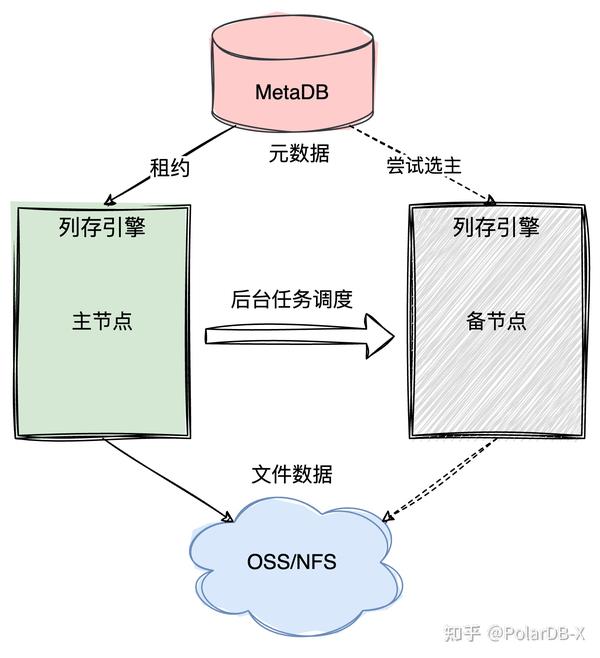
列存引擎节点选主采用租约机制,在MetaDB中存在系统表,记录列存引擎的所有节点信息,同一时刻有且只有一个节点可用选为主节点,其余节点为备节点,主节点可不断续约以避免频繁主备切换(HA),备节点也会每隔一段时间尝试选为主节点,当主节点出现故障,租约过期,则备节点可获取租约,成为主节点,完成一次主备切换。
考虑到备节点处于热备状态,没有负载,资源利用率低,只有主节点在提供服务,所以PolarDB-X的列存引擎还支持主节点将一些后台任务调度到备节点进行执行,例如一些compaction任务,以减轻主节点压力,同时提高备节点资源利用率。
