






一、引言

HBase 是一个建立在 Hadoop 之上的分布式 KV 数据库系统,首个独立版本于2010年2月发布。凭借其高可用性、高扩展性和强一致性,以及在廉价 PC 服务器上的低部署成本,HBase 迅速成为物联网、社交网络和监控数据存储的首选方案,并在大规模数据分析领域得到广泛应用。然而,随着业务需求变化,HBase 在某些功能上显现不足,如缺乏二级索引和不支持跨行事务等。与此同时,随着数据库技术不断进步,NewSQL 日益崭露头角,TDSQL MySQL版(TDStore引擎)采用了主流 NewSQL 架构,具备容器化云原生管理能力,并100%兼容 MySQL 8.0 语法。此外,TDStore 支持原生 Online DDL ,可动态更改表结构,并具备高效的压缩存储能力,降低成本的同时支持海量存储。本文将深入探讨在历史库场景中使用 TDStore 替换 HBase 所带来的成本和性能优势。
二、使用HBase的业务场景和痛点
HBase在扩展性以及存储方面具备一定优势,能够满足业务系统的历史库使用需求。在过去的十多年里,许多大型公司和组织使用 HBase 作为海量数据的首选存储方案。例如,在金融领域,监管机构要求金融机构对交易记录、客户信息等敏感数据进行长期保存,以便在必要时进行追溯和核查。
腾讯金融科技业务系统的历史库也曾广泛采用HBase,但使用 HBase 后也出现了一些核心痛点。
1)、业务背景
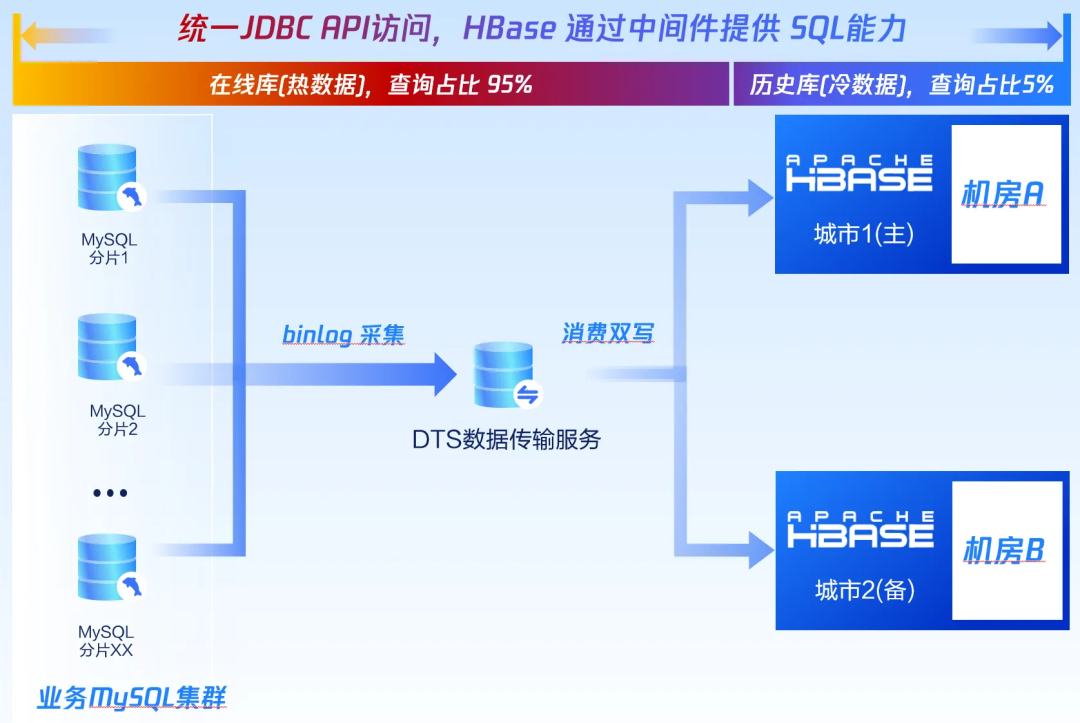
上图是腾讯金融科技的一个充值记录类型业务的架构图:
● 通过 binlog 采集以及 DTS 传输服务,增量数据消费双写到历史数据的两个 HBase 集群:一主一备,分布在两个城市,具备跨可用区的容灾能力。
● 超出保留时间的数据会从 MySQL 集群中删除,这些数据保存在 HBase 中成为静态历史数据。
● 在线库热数据的查询占比95%,历史库 HBase 冷数据的查询占比5%。
● 为方便业务开发,统一使用 HBase Proxy 通过 SQL 访问历史数据。
● 历史数据需要长期保存,不能删除;随着数据的不断增长,使用成本在快速扩张。
2)、业务痛点

● 组件多,运维复杂
1. HBase组件众多,支持复杂查询等功能还需引入额外工具,运维复杂。
2. 此外,HBase社区发展停滞,促使我们寻找更好的解决方案。
● 不支持二级索引
3. 业务需要先查询索引表,再查询主表,链路长、延迟高。
● 不支持跨行事务
4. 只能保证单行的原子性,主表与索引表的一致性无法保证。
● 容灾依赖双写
5. 跨可用区容灾依赖双写,加大了程序的复杂性,且难以保证主备HBase的数据一致性。
● 使用成本
6. 主备2套HBase集群,需配置5-6个副本,存储成本高昂。
7. 压缩算法默认为Snappy,如使用压缩率更优的ZSTD需依赖Hadoop 3.0,存在Core Dump的概率。
面对业务使用 HBase 的局限性,TDStore 团队主动深入分析业务痛点,最终为其提供了一套更合适的解决方案,采用 TDStore 替代 HBase 。
三、迁移后的性能和效率比较
在上述提到的充值记录业务场景中,我们已经成功地将 HBase 数据(使用 Snappy 压缩)迁移到了 TDStore(使用 LZ4+ZSTD 压缩)。以下是迁移后性能和效率的对比分析:
1)存储成本大幅降低
结果显示,单副本(不包括索引)的压缩率达到了47%,显著降低了腾讯金融科技业务系统的数据库使用成本。
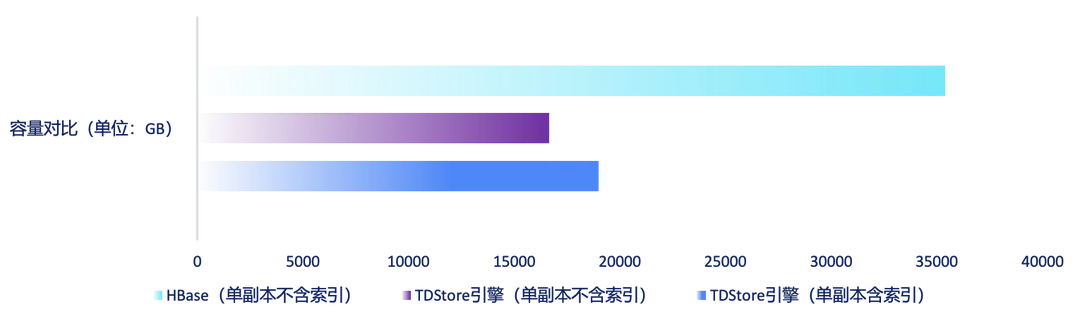
同时,由于原先需要双写主备两套HBase集群,现在只需一套 TDStore 实例即可满足跨 AZ 的高可用。在副本数上两者也有明显差异,将其纳入计算后,成本进一步降低。
2)业务访问延迟降低
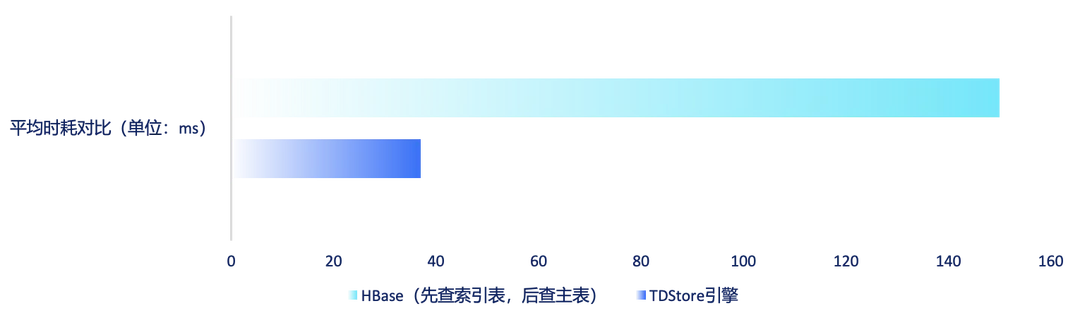
迁移前,业务需要先查询 HBase 的索引表,再查询主表,导致链路较长,平均耗时达到150毫秒。而迁移至 TDStore 后,平均耗时缩短至37毫秒,执行效率显著提升。
3)业务数据规范性大幅提升
HBase 作为 KV 数据库,其数据结构只有键和值两个元素,没有预定义的数据结构,任何可以转换为字节数组的内容都可以存储在 HBase 的单元格中;这就导致如果执行了错误的 PUT 操作,HBase 会无条件保存数据,并依赖滞后的数据校验程序去发现和校正。
TDStore 作为关系型数据库,使用表格形式来组织数据,每个表都有预定义的列,并且每列都有预定义的数据类型。这种结构化的数据组织方式使得数据更加规范,也避免了日常繁杂的数据校验工作。
四、总结
四、总结作为 TDSQL 新一代引擎,TDSQL TDStore版具有以下的特点 :
1)透明分布式
兼容性:兼容原生 MySQL 8.0 语法,对用户业务层无入侵。
分布式:业务层无须手动分库分表,使用时无需指定分片键,单机 MySQL 上的业务可以无损迁移到 TDStore 上。
2)高性能计算 + 海量存储
计算层:不同于传统的 M-S 模式,TDStore 为多主模式,每个节点均可读写;单实例可支撑千万级 QPS ,帮助用户应对突如其来的业务峰值压力。
存储层:采用高压缩比的分布式存储引擎,海量数据业务的性价比首选。
3)容器化云原生的弹性扩缩容
基于容器化平台的管控系统具备云原生能力,可根据业务需求弹性扩缩容,支持业务动态负载以及容量弹性伸缩。
4)原生Online DDL支持业务的频繁变化
支持在线加减列操作,支持在线加减索引,支持大部分 DDL 操作以原生 Online 方式执行。使用者在业务运行过程中有动态更改表结构的需求时,无须依赖如 pt 或 ghost 等外部工具组件。
也是因为TDStore有这些特点,历史库场景下的 HBase 业务非常适合迁移至TDStore。TDStore 与 HBase 的功能相比,主要具有以下特征:
● 长期数据保存:TDStore 具有极易扩展性。
● 提高数据质量 :TDStore 具有严格约束,避免问题或错误数据存入库中。从而节省修复数据的时间。
● 成本敏感 :TDStore 具有更高的压缩比,并在满足容灾需求的情况下减少副本数量,从而大幅降低使用成本。
● 统一SQL访问:上游数据来自 MySQL,业务希望统一使用SQL访问两侧数据库,HBase 需要加装 phoenix 或其他中间件来支持 SQL,TDStore 原生支持 SQL 接口,且性能更佳。
● 更便捷的运维体验:TDStore 自主研发,依托容器化管控平台,在日常运维和升级工作中更为便捷。
TDStore 正在快速发展,其在历史库场景中替代 HBase 的实践仅是成本效益和性能优势的一部分。未来,我们将致力于提升产品性能和用户体验。作为腾讯云数据库长期战略的核心,TDStore 将始终以业务需求为导向,专注产品打磨,为用户提供更高效、更稳定的服务。

