




概述
在前文PostgreSQL 性能优化(一):vacuum & autovacuum中,对 vacuum 的优化方向进行了阐述,其本质在于对 I/O 的优化,旨在降低后台进程在运用相应功能时所产生的额外 I/O 开销对业务造成的影响。本文亦将继续围绕优化 I/O 这一方向展开。在 PostgreSQL 的进程结构中,除 autovacuum 外,脏页写进程、检查点进程以及 wal 日志写进程对 I/O 的开销相对较大,故而属于重点优化对象。
checkpoint 介绍
首先,我们得清楚 checkpoint 进程的作用是:通过不断触发,将内存中的脏数据写入磁盘,得到一个较新的“数据快照”,当发生异常停机时需要进行实例恢复,会从最新的一个检查点开始恢复(需要回放的xlog就会更少),所以检查点有利于推进数据更新,加速恢复。
其次,我们得清楚 checkpoint 进程做了什么。当其触发时:
- 首先会更新控制文件记录Latest checkpoint’s REDO location信息
- 将脏数据从内存中的共享缓冲区写入磁盘,以确保数据的持久性
- 一旦脏数据成功写入磁盘,数据库会更新数据文件头信息(pd_lsn),等到脏数据全部回写完成,再次更新控制文件记录Latest checkpoint location及其附加信息,以记录检查点的位置和相关状态信息,如下图:
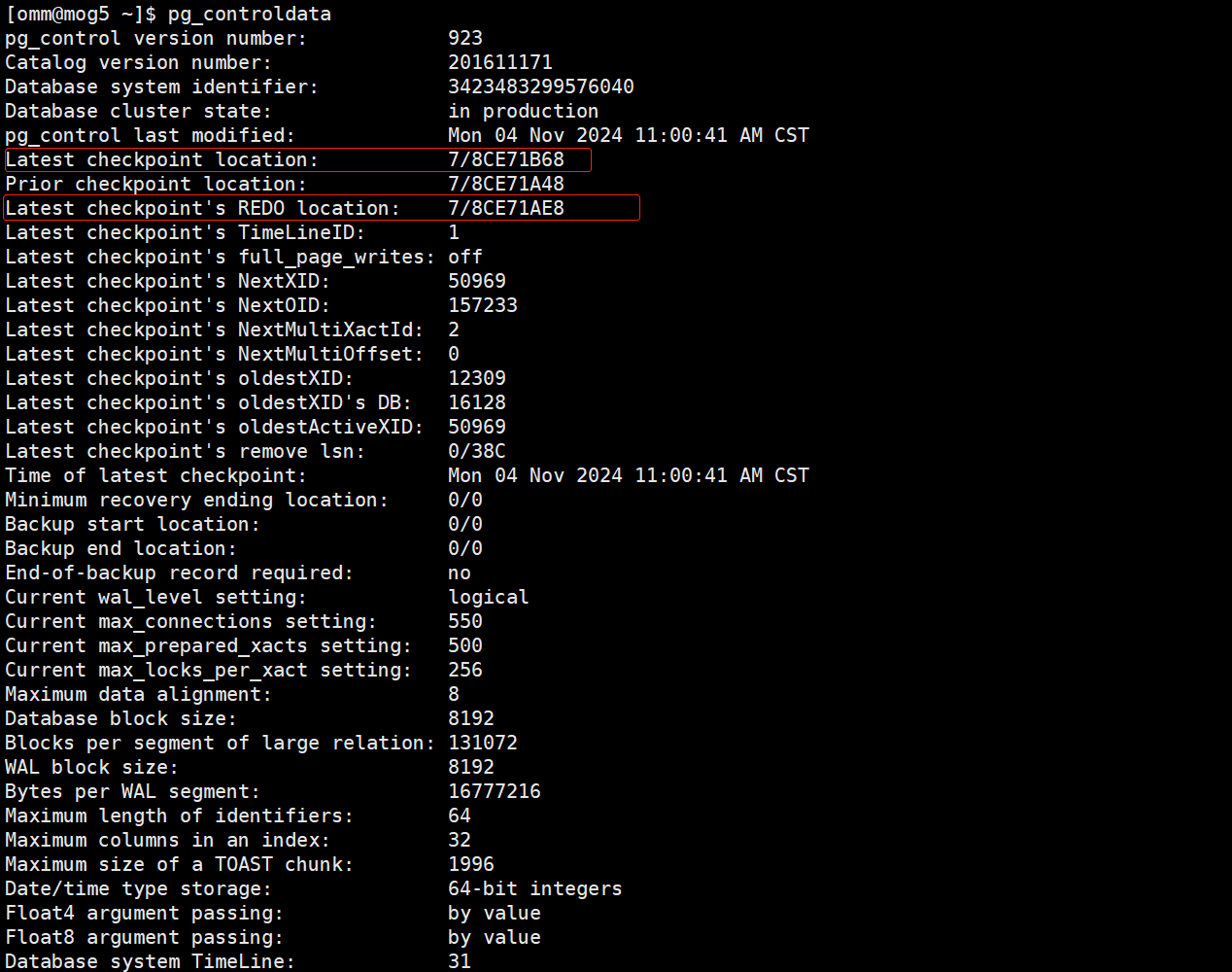
初学者可能并不理解触发一次检查点为何需要进行两次记录,这是因为检查点并不是一瞬间的行为,脏页写过程往往会持续一定的时间(检查点的开始和完成对应Latest checkpoint’s REDO location和Latest checkpoint location),检查点持续期间如果数据库继续对外提供服务,会产生xlog,如果遇上IO压力比较大的情况,检查点会持续更久,期间产生的xlog也会更多,“完成时间”相较于“开始时间”在xlog位置上就有更大的偏移量,下图是基于上图控制文件信息最后一次有效检查点进行的偏移量计算:

但是有部分情况下触发的检查点会让Latest checkpoint’s REDO location和Latest checkpoint location记录的位置信息是相同的,如数据库的正常关闭。
正常关闭数据库会先断开所有的业务连接,对未提交的事务进行回滚,然后触发全量检查点进行脏页落盘,最后释放后台进程和物理资源。因检查点持续期间数据库对外没有提供任何的服务,xlog没有任何新增,即使脏页落盘持续了很长的时间,检查点的完成位置相对于开始位置也没有任何的偏移,那么这会产生什么样的影响呢?
数据库正常关闭后,再次启动数据库,后台会解析控制文件信息,发现Latest checkpoint’s REDO location和Latest checkpoint location记录的位置信息一致,且无后续xlog,说明无需进行实例恢复,整个启动过程会非常快。
相反,如果是因为一些故障导致的数据库宕机,启动阶段会解析控制文件得到最后一次检查点的开始位置和结束位置不一致,则需要进行实例恢复(如下图)。实例恢复的起始点是基于Latest checkpoint’s REDO location,往后不断回放xlog日志直到故障时间点,整个的启动时间就会受到需要回放的xlog日志量的影响。
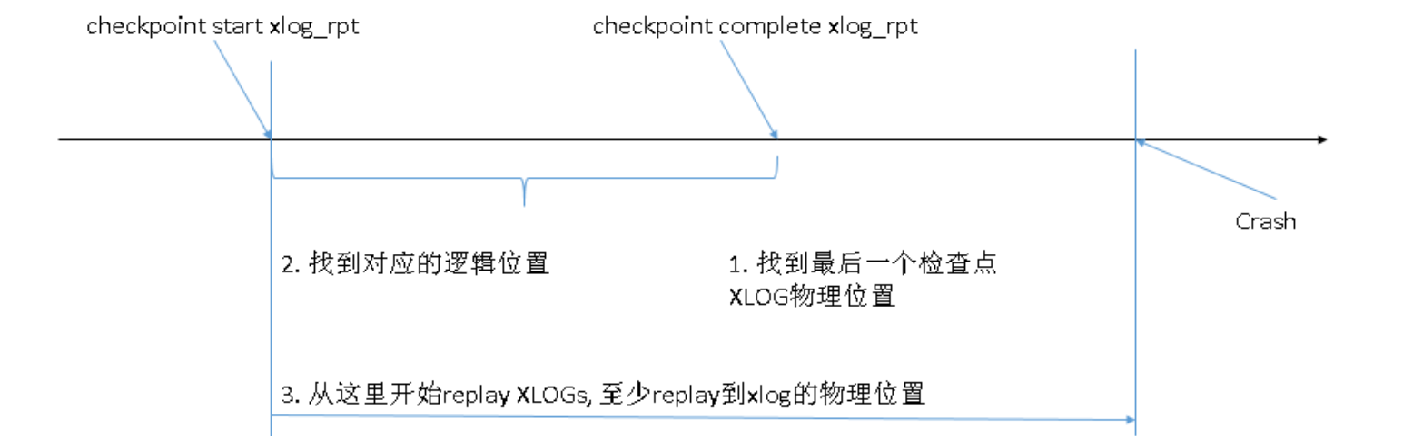
综上:检查点触发时会立马记录开始位置即此时的xlog位置,写入到Latest checkpoint’s REDO location,这会作为实例恢复的起点,在脏页刷盘完成后再次记录此时的xlog位置写入到Latest checkpoint location,其可以用来判定是否需要进行实例恢复,也可以作为实例恢复期间恢复数据一致性的标志性位置
checkpoint 触发场景
- 手动触发:手动执行checkpoint;
- 自动触发:通过参数checkpoint_timeout设置的时间周期性触发,注意:pg没有增量检查点的概念,在opengauss/mogdb中默认开启增量检查点enable_incremental_checkpoint=on,所以会以incremental_checkpoint_timeout周期性触发增量检查点
- 被动触发:当xlog日志新增个数超过参数checkpoint_segments设定的值(pg9.4版本及之前)或新增日志量达到max_wal_size的一半左右(pg9.4版本之后)
- 其他:物理备份、数据库停库、select pg_switch_xlog()等
可以通过视图pg_stat_bgwriter查询检查点触发的次数以及性能。
checkpoint 性能优化
发生检查点时,需要把所有的脏页写入磁盘,会产生一定的IO开销。为了减小可能带给业务的影响,通过参数checkpoint_warning监控两次检查点实际发生的间隔是否过于频繁,可适当调大参数checkpoint_timeout(opengauss:incremental_checkpoint_timeout)让检查点定期触发频繁放缓。虽然调大这两个参数可以减小触发频率,但是这么做可能会导致一个检查点周期内内存中产生更多的脏页个数,检查点触发时更多的写操作会导致单次检查点产生较高的IO开销。为了解决这个问题,PostgreSQL引进参数checkpoint_completion_target限制全量检查点的性能,检查点进行脏页写入的操作会被均匀分散到一段时间内,而非立马完成,用长时间的平滑IO替代短时间的高IO冲击,减少对数据库性能的干扰。通过以上两种方式基本可以控制检查点带来的影响,但是需要注意的是checkpoint_timeout不要设置的太大(生产中常见配置30min~60min),不然遇到业务高峰期时,xlog增长迅速,如果此时发生宕机事件,实例恢复的时间会更长。
当然,在业务高峰期间,xlog生成速率明显加快,检查点可能会被动触发,可通过视图pg_stat_bgwriter的checkpoints_req字段查询检查点强制性被动触发的次数(非周期性触发)。根据需求适当调整checkpoint_segments或max_wal_size的值,比如查看业务高峰期间整体IO占用并不高,为了应对异常宕机带来的影响可以调小这两参数提高检查点频率,如果IO压力比较大,可以适当调大这些参数。
在opengauss系列国产数据库中引进了增量检查点的机制,其目的是减少下一次全量检查点到来时需要处理的脏页数,由于增量检查点也会更新控制文件,从一定程度来可以防止因两次检查点间隔太长致使的实例恢复过慢,解决了两个检查点之间脏页累积过多和实例恢复太久的问题。在增量检查点机制下,会维护一个脏页队列(dirtypagequeue),脏页是按照LSN 递增的顺序放到队列中的,并由一个专门刷脏页面的后台线程页面刷盘线程(pagewriter)进行定期定量的刷脏页下盘操作。所以,在增量检查点触发时,并不需要等待脏页刷盘,而是交由pagewriter后台处理。增量检查点的存在使得整个系统中的IO更加平滑,并且系统的故障恢复时间更短,可用性更高。
checkpoint 写保护
在一般情况下,Linux操作系统的存储单元是4k,但是一个数据库的page页面是8k(相当于对应着两个操作系统页面),在检查点刷脏的过程中,一个数据库page页面需要同时对应修改2个操作系统page,这样就可能在修改了其中一个操作系统page时发生故障,导致另一个仍然是旧数据,对于既有新数据又包含旧数据的数据库page页情况,我们称为半页写问题。PostgreSQL使用了全页写机制来应对半页写问题,通过参数full_page_writes来指定是否开启。全页写就是把即将成为脏页的数据库块内容预先写入到xlog中做一个数据块层面的备份,如果后期在实例恢复期间检查到了坏块,可以通过这个特性恢复初始数据,然后进一步回放xlog完成恢复。打开这个参数虽加强了数据安全,但也会导致xlog写入量变多,额外IO开销增大。
在opengauss系列国产数据库中,当增量检查点开关打开时,同时enable_double_write打开,则使用enable_double_write双写特性保护,不再使用full_page_writes防止半页写问题。
总结
本文介绍了检查点进程的触发场景和功能,着重强调检查点在实例恢复中的应用,针对检查点的优化,从多个角度分析如何降低检查点带来的性能开销如触发频率(checkpoint_timeout、max_wal_size)、脏数据处理效率(checkpoint_completion_target)、全页写(full_page_writes)等。在生产中,或许我们希望查点发生的频率足够低,以免影响用户,但也要足够频繁,以限制恢复持续时间和磁盘空间要求,这是权衡后的结果。
