




点击上方“IT那活儿”公众号--专注于企业全栈运维技术分享,不管IT什么活儿,干就完了!!!
Zabbix使用ES作为数据源,运行一段时间后写入报错:
elastic_writer_flush() cannot send data to elasticsearch;
该机器之前为32G内存已扩容至64G,JVM参数调整为32G。
报错详情:

此示例输出表明要处理的数据太大,以致于父断路器无法处理。父断路器(断路器类型)负责集群的整体内存使用情况。
[<http_request>] 的数据 客户端向集群中的节点发送 HTTP 请求。OpenSearch Service 会在本地处理请求,或者将其传递到另一个节点进行其他处理。 将为 [#] 处理请求时堆大小的外观。 [#] 的限制 当前断路器限制。 实际使用量 JVM 堆的实际使用量。 预留新字节 处理请求所需的实际内存。
我们不能继续增加内存,因为这样没有效果,所以需要从释放内存开始入手。
Elasticsearch缓冲区描述: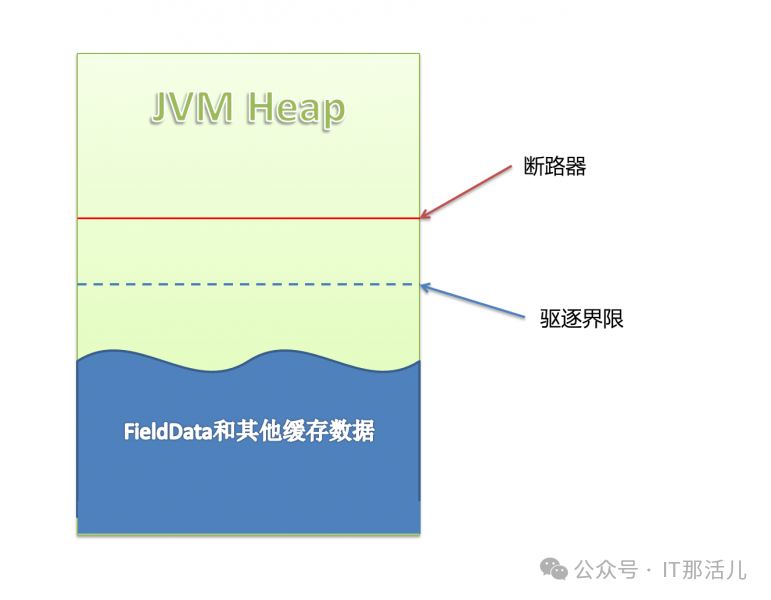 断路器共分为3个:
断路器共分为3个:
indices.breaker.fielddata.limit
fielddata断路器默认限制fielddata占用堆内存的60%。
indices.breaker.request.limit
请求断路器,估算请求或者聚合占用内存大小,默认限制大小为堆内存的40%。
indices.breaker.total.limit
默认情况下,total断路器保证请求和fielddata断路器的和小与堆内存的70%。
ES在查询时,会将索引数据缓存在内存(JVM)中。
当缓存数据到达驱逐线时,会自动驱逐掉部分数据,把缓存保持在安全的范围内。当用户准备执行某个查询操作时,缓存数据+当前查询需要缓存的数据量到达断路器限制时,会返回Data too large错误,阻止用户进行这个查询操作。ES把缓存数据分成两类,FieldData和其他数据,我们接下来详细看FieldData,它是造成我们这次异常的“元凶”。
ES配置中提到的FieldData指的是字段数据。当排序(sort),统计(aggs)时,ES把涉及到的字段数据全部读取到内存(JVM Heap)中进行操作。相当于进行了数据缓存,提升查询效率。
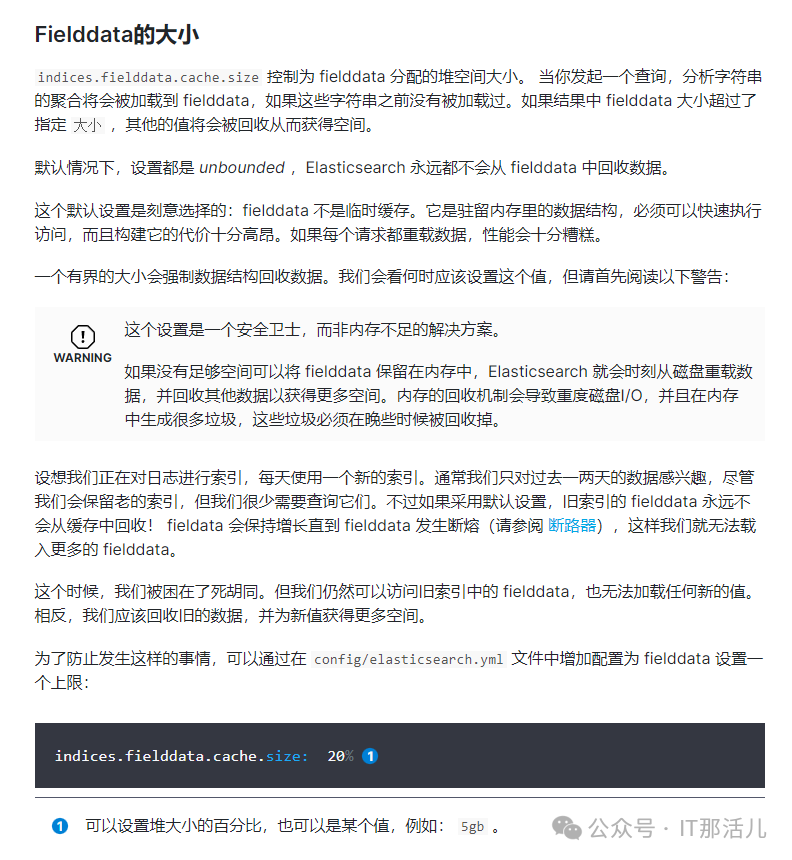
indices.fielddata.cache.size控制分配给fielddata多少堆内存。当在一个字段首次执行查询时,es会把它加载到内存中,同时添加到fielddata。如果fielddata超过了指定的堆内存,会从fielddata占用的内存中删除掉一些值。但是默认,这个设置是undounded,也就是没限制。这样,fielddata就会一直增加。但是,一旦它占用的内存超过了断路器规定的内存,就不会往里面加载更多fielddata了。
所以基本判断为indices.fielddata.cache.size问题,默认是不回收缓存的。缓存到达限制大小,无法往里插入数据。将大小设置成30%,观察下效果。
indices.fielddata.cache.size: 30% # 为分配JVM的30%,该值要小于indices.breaker.fielddata.limit
官网注解:https://www.elastic.co/guide/cn/elasticsearch/guide/2.x/_limiting_memory_usage.html#fielddata-size书签:限制内存使用 | Elasticsearch: 权威指南 | Elastic
 参考文档:
参考文档:https://blog.51cto.com/u_14886891/5283252书签:Elasticsearch 断路器报错了,怎么办?_铭毅天下的技术博客_51CTO博客
https://blog.csdn.net/sdlyjzh/article/details/48035723书签:CircuitBreakingException[[FIELDDATA] Data too large, data for [proccessDate] would be larger than li_sdlyjzh的博客-CSDN博客
https://aws.amazon.com/cn/premiumsupport/knowledge-center/opensearch-circuit-breaker-exception/书签:解决 Amazon OpenSearch Service 中的断路器异常
本文作者:刘玉翀(上海新炬中北团队)
本文来源:“IT那活儿”公众号

