




背景
最近集群归档目录(ARCH)80%报警,随着业务交易的突增归档量由原来的80G+增涨为150G,因此对ARCH目录再扩容500GB。N次扩容操作都没出个问题,这次差点就载了。
RAC集群扩容归档空间-ARCH
一、存储划分500G arch2空间给RAC集群
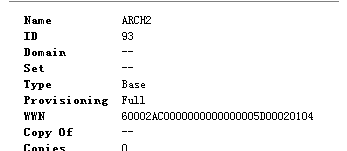
二、RAC 集群节点均操作
- 1、刷新发现新磁盘
[root@dbrac1 ~]# echo "- - -" > /sys/class/scsi_host/host0/scan [root@dbrac1 ~]# echo "- - -" > /sys/class/scsi_host/host1/scan [root@dbrac1 ~]# echo "- - -" > /sys/class/scsi_host/host2/scan [root@dbrac1 ~]# echo "- - -" > /sys/class/scsi_host/host3/scan [root@dbrac1 ~]# echo "- - -" > /sys/class/scsi_host/host4/scan [root@dbrac1 ~]# multipath -l mpathv (560002ac0000000000000007a00020406) dm-24 3PARdata,VV size=500G features='0' hwhandler='1 alua' wp=rw `-+- policy='round-robin 0' prio=0 status=active |- 1:0:0:17 sdbv 68:144 active undef unknown |- 3:0:0:17 sdbx 68:176 active undef unknown |- 1:0:1:17 sdbw 68:160 active undef unknown `- 3:0:1:17 sdby 68:192 active undef unknown
- 2、配置别名:/etc/multipath.conf
[root@dbrac1 ~]# vim /etc/multipath.conf defaults { user_friendly_names yes } multipaths { multipath { no_path_retry fail wwid 560002ac0000000000000007a00020406 alias ASM-ARCH2 } } -- 重新多路径 [root@dbrac1 ~]# /etc/init.d/multipathd restart ok 正在关闭multipathd 端口监控程序: [确定] 正在启动守护进程multipathd: [确定] [root@dbrac1 ~]# multipath -l ASM-ARCH2 (560002ac0000000000000007a00020406) dm-24 3PARdata,VV size=500G features='0' hwhandler='1 alua' wp=rw `-+- policy='round-robin 0' prio=0 status=active |- 1:0:0:17 sdbv 68:144 active undef unknown |- 3:0:0:17 sdbx 68:176 active undef unknown |- 1:0:1:17 sdbw 68:160 active undef unknown `- 3:0:1:17 sdby 68:192 active undef unknown
- 3、目录赋权
[root@dbrac1 ~]#chown grid.asmadmin /dev/mapper/ASM-ARCH2 [root@dbrac1 ~]#chmod 660 /dev/mapper/ASM-ARCH2
三、RAC 集群其中一节点操作扩容ARCH
- 1、查看数据磁盘组:
SQL> set linesize 200;
SQL> col name format a20;
SQL> select group_number,name,TOTAL_MB, FREE_MB from v$asm_diskgroup;
GROUP_NUMBER NAME TOTAL_MB FREE_MB
------------ -------------------- ---------- ----------
1 ARCH 512000 134955
......
6 rows selected.
- 2、查看数据磁盘目录:/dev/mapper/ASM-ARCH2
SQL> col name format a20;
SQL> col path format a30;
SQL> select name,path,mode_status,state,disk_number,failgroup from v$asm_disk;
NAME PATH MODE_ST STATE DISK_NUMBER FAILGROUP
-------------------- ------------------------------ ------- -------- ----------- -----------------------
/dev/mapper/ASM-ARCH2 ONLINE NORMAL 0
ARCH_0000 /dev/mapper/ASM-ARCH1 ONLINE NORMAL 0 ARCH_0000
......
- 3、ARCH 扩容平衡数据:
0-11表示平衡级别 11为最高级别,受初始化参数 ASM_POWER_LIMIT限制
SQL> alter diskgroup ARCH add disk '/dev/mapper/ASM-ARCH2' rebalance power 1;
- 4、查看扩容成功
SQL> set line 800
SQL> select group_number,name,TOTAL_MB, FREE_MB from v$asm_diskgroup;
GROUP_NUMBER NAME TOTAL_MB FREE_MB
------------ ------------------------------ ---------- ----------
1 ARCH 1024000 634424
......
6 rows selected.
- 5、查看ASM卷组平衡过程,平衡完后,该内容为空。
SQL> select * from v$asm_operation;
no rows selected
SQL> select group_number,name,total_mb,free_mb,total_mb-free_mb used_mb from v$asm_disk_stat;
GROUP_NUMBER NAME TOTAL_MB FREE_MB USED_MB
------------ ------------------------------ ---------- ---------- ----------
1 ARCH_0000 512000 317197 194803
1 ARCH_0001 512000 317227 194773
......
18 rows selected.
意外发生
4个节点的RAC集群,突然收到其它3个节点数据库宕机报警,唯一还支撑业务的仅有目前操作的节点,Session直接飙升到1300(幸亏数据库Sesssion最大配置比较高:2500)。当时最先怀疑的是:其它3个节点的新加磁盘路径权限没有赋权。
一、查看各节点历史操作命令均正常,排除权限问题
835 2024-11-20 14:49:34 echo "- - -" > /sys/class/scsi_host/host0/scan 836 2024-11-20 14:49:34 echo "- - -" > /sys/class/scsi_host/host1/scan 837 2024-11-20 14:49:34 echo "- - -" > /sys/class/scsi_host/host2/scan 838 2024-11-20 14:49:34 echo "- - -" > /sys/class/scsi_host/host3/scan 839 2024-11-20 14:49:35 echo "- - -" > /sys/class/scsi_host/host4/scan 840 2024-11-20 14:49:37 multipath -l 841 2024-11-20 14:49:50 /etc/init.d/multipathd reload 842 2024-11-20 14:49:54 multipath -l 843 2024-11-20 14:51:05 exit 844 2024-11-20 15:58:27 vim /etc/multipath.conf 845 2024-11-20 15:58:47 /etc/init.d/multipathd restart 846 2024-11-20 15:58:49 multipath -l 847 2024-11-20 15:58:58 vim /etc/multipath.conf 848 2024-11-20 15:59:09 /etc/init.d/multipathd restart 849 2024-11-20 15:59:11 multipath -l 850 2024-11-20 15:59:46 cat /var/log/messages 851 2024-11-20 16:02:08 chown grid.asmadmin /dev/mapper/ASM-ARCH2 852 2024-11-20 16:03:16 chmod 660 /dev/mapper/ASM-ARCH2
二、查看日志
- 部分系统异常日志
发现新增路径:mpathv(sdbr、sdbs、sdbt、sdbu)异常:couldn’t get asymmetric access state,由此判断是多路径的问题
Nov 20 14:42:24 dbrac2 kernel: sd 3:0:0:1: Warning! Received an indication that the LUN assignments on this target have changed. The Linux SCSI layer does not automatically remap LUN assignments.
Nov 20 14:42:24 dbrac2 kernel: sd 1:0:0:0: Warning! Received an indication that the LUN assignments on this target have changed. The Linux SCSI layer does not automatically remap LUN assignments.
Nov 20 14:42:24 dbrac2 kernel: sd 3:0:1:5: Warning! Received an indication that the LUN assignments on this target have changed. The Linux SCSI layer does not automatically remap LUN assignments.
Nov 20 14:42:24 dbrac2 kernel: sd 1:0:1:11: Warning! Received an indication that the LUN assignments on this target have changed. The Linux SCSI layer does not automatically remap LUN assignments.
Nov 20 14:47:16 dbrac2 puppet-agent[19326]: Finished catalog run in 4.88 seconds
Nov 20 14:47:23 dbrac2 sshd[22245]: Accepted password for hnyunwei from 10.10.6.15 port 10266 ssh2
Nov 20 14:47:28 dbrac2 kernel: scsi: host 0 channel 0 id 0 lun4194304 has a LUN larger than allowed by the host adapter
Nov 20 14:47:29 dbrac2 kernel: scsi: host 0 channel 3 id 0 lun4194304 has a LUN larger than allowed by the host adapter
Nov 20 14:48:55 dbrac2 kernel: scsi: host 0 channel 0 id 0 lun4194304 has a LUN larger than allowed by the host adapter
Nov 20 14:48:56 dbrac2 kernel: scsi: host 0 channel 3 id 0 lun4194304 has a LUN larger than allowed by the host adapter.
......
Nov 20 14:50:02 dbrac2 multipathd: sdbr: couldn't get asymmetric access state
Nov 20 14:50:02 dbrac2 multipathd: sdbs: couldn't get asymmetric access state
Nov 20 14:50:02 dbrac2 multipathd: sdbt: couldn't get asymmetric access state
Nov 20 14:50:02 dbrac2 multipathd: sdbu: couldn't get asymmetric access state
Nov 20 14:50:03 dbrac2 kernel: device-mapper: table: 253:24: multipath: error getting device
Nov 20 14:50:03 dbrac2 kernel: device-mapper: ioctl: error adding target to table
Nov 20 14:50:03 dbrac2 multipathd: mpatha: ignoring map
......
Nov 20 14:50:05 dbrac2 multipathd: mpathv: load table [0 20971520 multipath 1 queue_if_no_path 1 alua 1 1 round-robin 0 4 1 68:144 1 68:176 1 68:160 1 68:192 1]
......
Nov 20 14:50:05 dbrac2 multipathd: mpathv: event checker started
Nov 20 14:50:05 dbrac2 kernel: sd 1:0:0:17: alua: port group 01 state A preferred supports tolusnA
Nov 20 14:50:05 dbrac2 kernel: sd 3:0:0:17: alua: port group 01 state A preferred supports tolusnA
Nov 20 14:50:05 dbrac2 kernel: sd 1:0:1:17: alua: port group 01 state A preferred supports tolusnA
Nov 20 14:50:05 dbrac2 kernel: sd 3:0:1:17: alua: port group 01 state A preferred supports tolusnA
Nov 20 14:50:05 dbrac2 multipathd: dm-24: remove map (uevent)
Nov 20 14:50:05 dbrac2 multipathd: mpathv: stop event checker thread (140737345021696)
Nov 20 14:50:05 dbrac2 multipathd: dm-24: remove map (uevent)
Nov 20 14:50:05 dbrac2 multipathd: dm-24: devmap not registered, can't remove
Nov 20 14:50:05 dbrac2 multipathd: dm-24: adding map
Nov 20 14:50:05 dbrac2 multipathd: mpathv: event checker started
Nov 20 14:50:05 dbrac2 multipathd: mpathv: devmap dm-24 added
......
Nov 20 16:21:47 dbrac2 kernel: rport-1:0-16: blocked FC remote port time out: removing rport
Nov 20 16:21:47 dbrac2 kernel: rport-2:0-85: blocked FC remote port time out: removing rport
Nov 20 16:26:19 dbrac2 kernel: rport-4:0-2: blocked FC remote port time out: removing rport
Nov 20 16:26:19 dbrac2 kernel: rport-3:0-5: blocked FC remote port time out: removing rport
Nov 20 16:26:19 dbrac2 kernel: rport-2:0-4: blocked FC remote port time out: removing rport
Nov 20 16:26:19 dbrac2 kernel: rport-1:0-5: blocked FC remote port time out: removing rport
Nov 20 16:30:48 dbrac2 sshd[123983]: Accepted password for hnyunwei from 10.10.6.9 port 55959 ssh2
- 数据库日志
Wed Nov 20 16:06:36 2024
NOTE: ASMB terminating
Errors in file /u01/oracle/diag/rdbms/dbrac/rac2/trace/rac2_asmb_77922.trc:
ORA-15064: communication failure with ASM instance
ORA-03113: end-of-file on communication channel
Process ID:
Session ID: 2136 Serial number: 3
Errors in file /u01/oracle/diag/rdbms/dbrac/rac2/trace/rac2_asmb_77922.trc:
ORA-15064: communication failure with ASM instance
ORA-03113: end-of-file on communication channel
Process ID:
Session ID: 2136 Serial number: 3
Wed Nov 20 16:06:36 2024
System state dump requested by (instance=2, osid=77922 (ASMB)), summary=[abnormal instance termination].
System State dumped to trace file /u01/oracle/diag/rdbms/dbrac/rac2/trace/rac2_diag_77675.trc
ASMB (ospid: 77922): terminating the instance due to error 15064
Wed Nov 20 16:06:36 2024
opiodr aborting process unknown ospid (16621) as a result of ORA-1092
Wed Nov 20 16:06:36 2024
opiodr aborting process unknown ospid (80307) as a result of ORA-1092
Wed Nov 20 16:06:36 2024
opiodr aborting process unknown ospid (50410) as a result of ORA-1092
Wed Nov 20 16:06:36 2024
ORA-1092 : opitsk aborting process
Wed Nov 20 16:06:36 2024
opiodr aborting process unknown ospid (140718) as a result of ORA-1092
Wed Nov 20 16:06:36 2024
ORA-1092 : opitsk aborting process
Wed Nov 20 16:06:37 2024
ORA-1092 : opitsk aborting process
Wed Nov 20 16:06:37 2024
ORA-1092 : opitsk aborting process
Wed Nov 20 16:06:37 2024
ORA-1092 : opitsk aborting process
Wed Nov 20 16:06:38 2024
- 集群日志
2024-11-20 16:06:36.265:
[/u01/grid/11.2.0.3/product/bin/oraagent.bin(11611)]CRS-5011:Check of resource "+ASM" failed: details at "(:CLSN00006:)" in "/u01/grid/11.2.0.3/product/log/dbrac2/agent/ohasd/oraagent_grid/oraagent_grid.log"
2024-11-20 16:06:36.689:
[ohasd(10948)]CRS-2765:Resource 'ora.asm' has failed on server 'dbrac2'.
2024-11-20 16:06:36.694:
[/u01/grid/11.2.0.3/product/bin/oraagent.bin(11611)]CRS-5011:Check of resource "+ASM" failed: details at "(:CLSN00006:)" in "/u01/grid/11.2.0.3/product/log/dbrac2/agent/ohasd/oraagent_grid/oraagent_grid.log"
2024-11-20 16:06:36.768:
[crsd(77204)]CRS-2765:Resource 'ora.dbrac.db' has failed on server 'dbrac4'.
2024-11-20 16:06:36.772:
[crsd(77204)]CRS-2765:Resource 'ora.asm' has failed on server 'dbrac4'.
2024-11-20 16:06:36.972:
[/u01/grid/11.2.0.3/product/bin/oraagent.bin(77425)]CRS-5011:Check of resource "dbrac" failed: details at "(:CLSN00007:)" in "/u01/grid/11.2.0.3/product/log/dbrac2/agent/crsd/oraagent_oracle/oraagent_oracle.log"
2024-11-20 16:06:37.063:
三、操作处理
- 发现新路径存在问题,后面再排查可能需要时间,考虑到目前集群仅有一个节点在撑,先试一下重启大法(reboot)对节点轮翻重启,然后集群各节点逐渐加入集群恢复正常。
分析小结:
- 从日志来分析应该是新分的存储路径的问题,导致集群ASM异常。 网上发现同种案例:Redhat6主机系统Oracle11g数据库异常重启问题,说是系统多路径BUG,日志输出与网页相吻合。
- 回溯操作当时有记录路径状态发现,新路径ASM-ARCH2本来应该是size=500G,但其它节点均识别为size=10G,由此想到之前给集群分配过一次10G的测试磁盘但已摘除。从目前现象分析像是新分的500G磁盘路径,系统按旧的10G信息识别到了,但UUID为新的,但磁盘信息为旧的(如下),没有重启的节点是因为1年前因硬件问题重启过一次,残留信息已清理。此次经历真是有惊有点小险啊,差点全军(全节点宕机)覆灭。
-- 重启前
ASM-ARCH2 (560002ac0000000000000007a00020406) dm-24 3PARdata,VV
size=10G features='0' hwhandler='1 alua' wp=rw
`-+- policy='round-robin 0' prio=0 status=active
|- 1:0:0:17 sdbv 68:144 active undef unknown
|- 3:0:0:17 sdbx 68:176 active undef unknown
|- 1:0:1:17 sdbw 68:160 active undef unknown
`- 3:0:1:17 sdby 68:192 active undef unknown
-- 重启后 :
ASM-ARCH2 (560002ac0000000000000007a00020406) dm-24 3PARdata,VV
size=500G features='0' hwhandler='1 alua' wp=rw
`-+- policy='round-robin 0' prio=50 status=active
|- 1:0:0:17 sdbr 68:80 active ready running
|- 3:0:0:17 sdbt 68:112 active ready running
|- 1:0:1:17 sdbs 68:96 active ready running
`- 3:0:1:17 sdbu 68:128 active ready running
- 后续再次测试整理:HBA&multipath 操作及问题汇总
欢迎赞赏支持或留言指正

「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
