




1、简介
应用程序和系统日志可以帮助我们了解集群内部的运行情况,日志对于我们调试问题和监视集群情况也是非常有用的。而且大部分的应用都会有日志记录,对于传统的应用大部分都会写入到本地的日志文件之中。对于容器化应用程序来说则更简单,只需要将日志信息写入到 stdout 和 stderr 即可,容器默认情况下就会把这些日志输出到宿主机上的一个 JSON 文件之中,同样我们也可以通过 docker logs
或者 kubectl logs
来查看到对应的日志信息。
但是,通常来说容器引擎或运行时提供的功能不足以记录完整的日志信息,比如,如果容器崩溃了、Pod 被驱逐了或者节点挂掉了,我们仍然也希望访问应用程序的日志。所以,日志应该独立于节点、Pod 或容器的生命周期,这种设计方式被称为 cluster-level-logging
,即完全独立于 Kubernetes 系统,需要自己提供单独的日志后端存储、分析和查询工具。
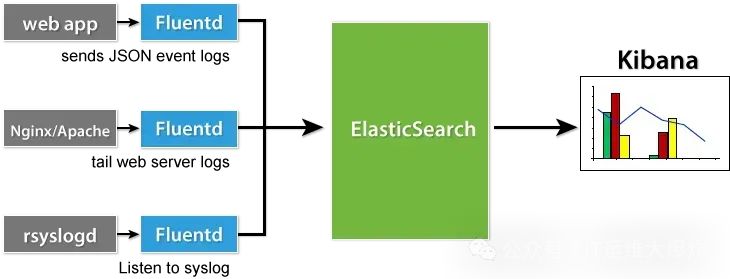
EFK 堆栈(Elasticsearch, Fluentd, Kibana)是一套强大且灵活的日志管理系统,广泛应用于现代分布式系统中。它结合了 Elasticsearch 的高效存储和搜索能力,Fluentd 的灵活日志收集和处理功能,以及 Kibana 的实时数据可视化,帮助企业更好地管理和分析日志数据。
2、EFK 堆栈的架构
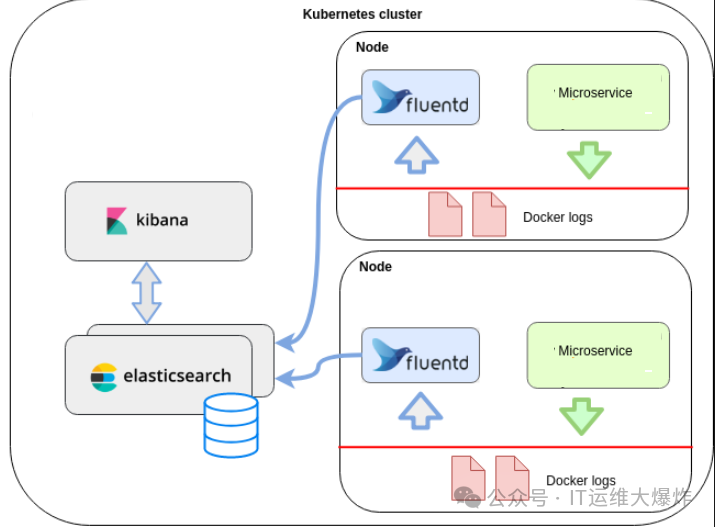
EFK 的架构可以简单地描述为:日志数据从各种来源被收集(由 Fluentd 处理),然后被传输到 Elasticsearch 进行存储和索引,最后通过 Kibana 对数据进行可视化展示。整个流程如下:
日志收集(Fluentd):
Fluentd 从多个来源收集日志数据,包括应用日志、系统日志、容器日志等。
数据可以通过各种输入插件(如
tail
、syslog
、http
等)进入 Fluentd。Fluentd 支持数据的过滤、变换、聚合和路由,可以对日志数据进行复杂的处理。
数据存储和索引(Elasticsearch):
Fluentd 处理后的数据被发送到 Elasticsearch,Elasticsearch 将数据存储为索引,并对其进行全文搜索和分析。
Elasticsearch 具备强大的分布式存储能力,支持水平扩展,能够处理大规模的日志数据。
数据可视化(Kibana):
Kibana 连接到 Elasticsearch,可以通过图形界面浏览、搜索、过滤日志数据。
用户可以使用 Kibana 创建自定义仪表板,实时监控系统状态和日志趋势。
3、各组件的详细介绍
Elasticsearch
Elasticsearch 是一个基于 Lucene 的搜索和分析引擎,能够快速存储、搜索和分析海量数据。它是 EFK 堆栈中的核心存储引擎。
索引:Elasticsearch 使用索引来组织数据,每个索引包含多个文档,每个文档是一个 JSON 格式的数据对象。
集群与节点:Elasticsearch 运行在一个分布式集群中,集群由多个节点组成,每个节点都可以存储数据和处理搜索请求。
分片与副本:Elasticsearch 的索引可以分为多个分片,每个分片可以有多个副本,以实现高可用性和负载均衡。
Fluentd
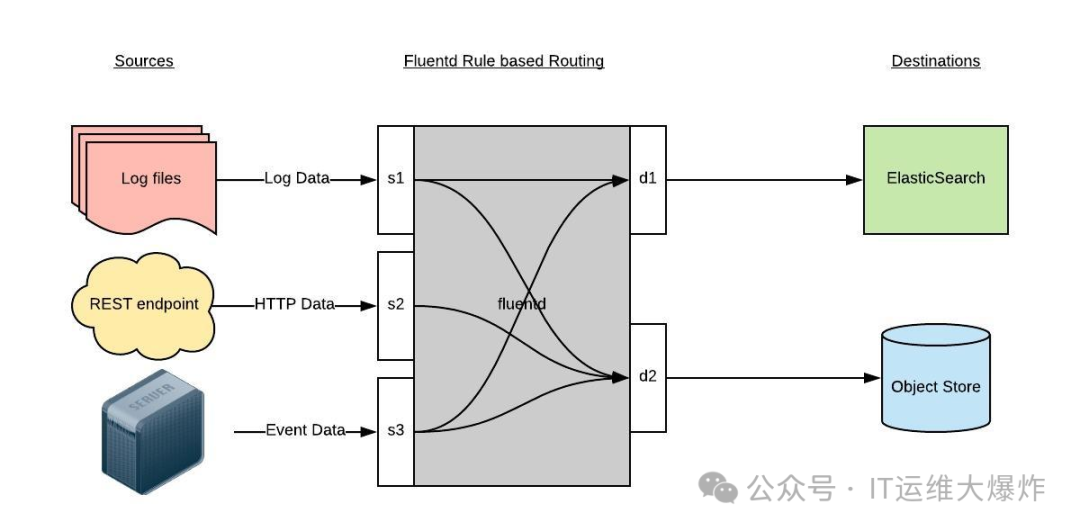
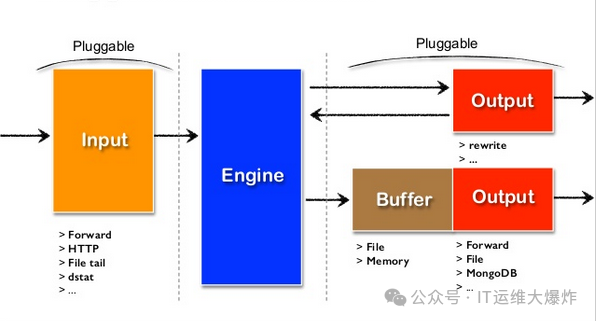
Fluentd 是一个灵活的数据收集器,能够统一处理不同来源的日志数据,并将其发送到目标系统。
输入插件:Fluentd 通过输入插件采集数据,例如
tail
插件用于监听日志文件,http
插件用于接收 HTTP 请求日志。过滤器:Fluentd 允许在数据传输前对日志进行过滤和变换,例如添加标签、格式化数据、筛选特定日志等。
缓冲与输出插件:Fluentd 支持缓冲机制,确保数据在传输过程中不丢失,并通过输出插件将数据发送到目标系统,如 Elasticsearch、S3、Kafka 等。
Kibana
Kibana 是一个与 Elasticsearch 无缝集成的数据可视化工具,用户可以通过 Kibana 轻松创建和管理仪表板。
Discover:Kibana 提供了一个强大的搜索界面,允许用户根据各种条件查询日志数据。
Visualize:用户可以使用 Kibana 创建各种图表(如条形图、折线图、饼图等),展示日志数据的分析结果。
Dashboard:Kibana 支持将多个图表组合成一个仪表板,提供对系统状态的整体视图。
Alerting:Kibana 还支持告警功能,用户可以根据特定条件设置告警规则,当条件满足时,Kibana 会触发告警通知。
4、EFK 堆栈的优势
云原生:EFK 堆栈与云原生环境高度契合,特别是在 Kubernetes 等容器编排平台中,能够轻松实现日志的收集、处理和分析。
日志 JSON 化:Fluentd 提供强大的解析和格式化功能,将各种格式的日志文件转换为标准的 JSON 格式,便于 Elasticsearch 的存储和索引。

可插拔架构设计:EFK 采用高度可插拔的架构,用户可以根据具体需求灵活添加或替换插件和组件,以适应多样化的日志处理场景。
极小的资源占用:EFK 堆栈设计轻量,特别是 Fluentd 在资源有限的环境中占用极少的系统资源,适用于嵌入式系统和物联网设备。

极强的可靠性:EFK 提供了完善的缓冲、重试和数据复制机制,在分布式环境下保证了日志数据的高可用性和持久性。
5、EFK 堆栈的应用场景
日志集中化管理:在分布式系统中收集、存储和分析来自不同节点的日志。
实时监控:通过 Kibana 仪表板实时监控系统性能和业务运行状态。
故障排查:通过搜索和分析日志,快速定位并解决系统故障。
安全分析:结合 Elasticsearch 的搜索功能,分析安全日志,检测潜在的安全威胁。
6、日志收集方式
直接在应用程序中将日志信息推送到采集后端(这种是从代码层面实现的,直接略过)
应用程序内部集成日志传输逻辑,将日志直接推送到日志存储或处理系统(如 Elasticsearch、Kafka 等)。
这种方法适合特定场景,能提供更低的延迟和更高的灵活性,但需要开发者在应用中实现相关功能。
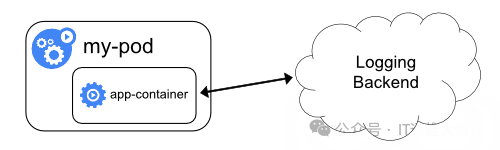
Pod 中包含一个 sidecar 容器来收集应用日志
每个应用 Pod 中部署一个独立的 sidecar 容器,专门负责收集和处理主应用容器的日志。
这种方法允许应用日志与 Pod 生命周期同步,并且可以对每个应用单独进行日志收集和处理。
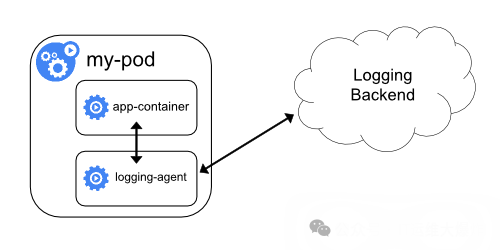
节点上运行一个 agent 来收集日志
在每个节点上部署日志收集 agent(如 Fluentd、Filebeat 等),该 agent 负责从节点上的所有容器中收集日志,并将其发送到日志存储或分析系统。
这种方法的优点是集中化管理日志,易于扩展和维护。
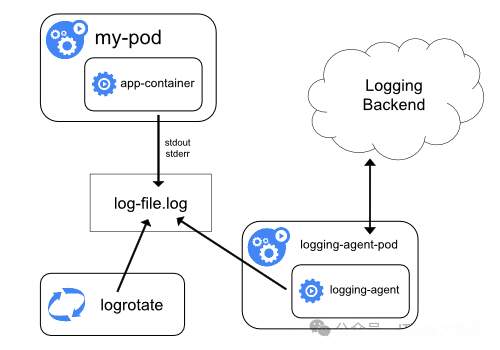
7、基本日志
直接将数据输出到标准输出流
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
[
bin/sh,
-c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done',
]
[root@mast01 fluentd]# kubectl apply -f 1.yaml
pod/counter created
[root@mast01 fluentd]# kubectl get pod
NAME READY STATUS RESTARTS AGE
counter 1/1 Running 0 3s
查看日志信息
[root@mast01 fluentd]# kubectl logs counter
0: Tue Aug 27 03:44:42 UTC 2024
1: Tue Aug 27 03:44:43 UTC 2024
2: Tue Aug 27 03:44:44 UTC 2024
3: Tue Aug 27 03:44:45 UTC 2024
4: Tue Aug 27 03:44:46 UTC 2024
5: Tue Aug 27 03:44:47 UTC 2024
6: Tue Aug 27 03:44:48 UTC 2024
7: Tue Aug 27 03:44:49 UTC 2024
8: Tue Aug 27 03:44:50 UTC 2024
9: Tue Aug 27 03:44:51 UTC 2024
10: Tue Aug 27 03:44:52 UTC 2024
11: Tue Aug 27 03:44:53 UTC 2024
12: Tue Aug 27 03:44:54 UTC 2024
13: Tue Aug 27 03:44:55 UTC 2024
14: Tue Aug 27 03:44:56 UTC 2024
15: Tue Aug 27 03:44:57 UTC 2024
......
在 Pod 中将日志记录在了容器的两个本地文件之中
[root@mast01 fluentd]# vim one-files-counter-pod-streaming-sidecar.yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> var/log/1.log;
echo "$(date) INFO $i" >> var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: var/log
volumes:
- name: varlog
emptyDir: {}
[root@mast01 fluentd]# kubectl exec -it counter -- cat var/log/1.log
0: Tue Aug 27 03:59:19 UTC 2024
1: Tue Aug 27 03:59:20 UTC 2024
2: Tue Aug 27 03:59:21 UTC 2024
3: Tue Aug 27 03:59:22 UTC 2024
4: Tue Aug 27 03:59:23 UTC 2024
5: Tue Aug 27 03:59:24 UTC 2024
6: Tue Aug 27 03:59:25 UTC 2024
7: Tue Aug 27 03:59:26 UTC 2024
[root@mast01 fluentd]# kubectl exec -it counter -- cat var/log/2.log
Tue Aug 27 03:59:19 UTC 2024 INFO 0
Tue Aug 27 03:59:20 UTC 2024 INFO 1
Tue Aug 27 03:59:21 UTC 2024 INFO 2
Tue Aug 27 03:59:22 UTC 2024 INFO 3
Tue Aug 27 03:59:23 UTC 2024 INFO 4
Tue Aug 27 03:59:24 UTC 2024 INFO 5
Tue Aug 27 03:59:25 UTC 2024 INFO 6
Tue Aug 27 03:59:26 UTC 2024 INFO 7
利用另外一个 sidecar 容器去获取到另外容器中的日志文件,然后将日志重定向到自己的 stdout 流中
[root@mast01 fluentd]# vim two-files-counter-pod-streaming-sidecar.yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> var/log/1.log;
echo "$(date) INFO $i" >> var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f var/log/1.log']
volumeMounts:
- name: varlog
mountPath: var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f var/log/2.log']
volumeMounts:
- name: varlog
mountPath: var/log
volumes:
- name: varlog
emptyDir: {}
[root@mast01 fluentd]# kubectl apply -f two-files-counter-pod-streaming-sidecar.yaml
pod "counter" created
[root@mast01 fluentd]# kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
[root@mast01 fluentd]# kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
<!--注意:这样前面节点上的日志采集 agent 就可以自动获取这些日志信息,而不需要其他配置。这种方法虽然可以解决上面的问题,但是也有一个明显的缺陷,就是日志不仅会在原容器文件中保留下来,还会通过 stdout 输出后占用磁盘空间,这样无形中就增加了一倍磁盘空间。-->
创建存储目录(这里使用的是nfs)
[root@mast01 ~]# yum install -y nfs-utils
[root@mast01 ~]# mkdir -p nfs/data/elasticsearch
[root@mast01 ~]# chmod 777 nfs/data/elasticsearch
[root@mast01 ~]# vim etc/exports
/nfs/data/elasticsearch/ 192.168.58.0/24(rw,no_root_squash)
[root@mast01 ~]# systemctl start nfs
[root@mast01 ~]# systemctl enable nfs
Created symlink from etc/systemd/system/multi-user.target.wants/nfs-server.service to usr/lib/systemd/system/nfs-server.service.
[root@mast01 ~]# exportfs -arv
exporting 192.168.58.0/24:/nfs/data/elasticsearch
创建pv
[root@mast01 elk]# mkdir nfs/data/elasticsearch/pv1
[root@mast01 elk]# mkdir nfs/data/elasticsearch/pv2
[root@mast01 elk]# mkdir nfs/data/elasticsearch/pv3
[root@mast01 elk]# kubectl apply -f es-config.yaml
configmap/es-config created
[root@mast01 elk]# vim pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-pv1
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: nfs/data/elasticsearch/pv1
server: 192.168.58.116
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-pv2
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: nfs/data/elasticsearch/pv2
server: 192.168.58.116
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-pv3
spec:
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: nfs/data/elasticsearch/pv3
server: 192.168.58.116
创建es-config
[root@mast01 elk]# vim es-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: es-config
namespace: logging
data:
elasticsearch.yml: |
cluster.name: "huqi-elasticsearch"
node.name: "${POD_NAME}"
network.host: 0.0.0.0
discovery.seed_hosts: "es-svc-headless"
cluster.initial_master_nodes: "elasticsearch-0,elasticsearch-1,elasticsearch-2"
创建es-svc-headless
[root@mast01 elk]# vim es-svc-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: es-svc-headless
namespace: logging
labels:
k8s-app: elasticsearch
spec:
selector:
k8s-app: elasticsearch
clusterIP: None
ports:
- name: in
port: 9300
protocol: TCP
创建es-statefulset
[root@mast01 elk]# vim es-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: logging
labels:
k8s-app: elasticsearch
spec:
replicas: 3
serviceName: es-svc-headless
selector:
matchLabels:
k8s-app: elasticsearch
template:
metadata:
labels:
k8s-app: elasticsearch
spec:
initContainers:
- command:
- sbin/sysctl
- -w
- vm.max_map_count=262144
image: registry.cn-shanghai.aliyuncs.com/study-03/alpine:3.6
imagePullPolicy: IfNotPresent
name: elasticsearch-logging-init
resources: {}
securityContext:
privileged: true
- name: fix-permissions
image: registry.cn-shanghai.aliyuncs.com/study-03/alpine:3.6
command: ["sh", "-c", "chown -R 1000:1000 usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: es-data-volume
mountPath: usr/share/elasticsearch/data
containers:
- name: elasticsearch
image: registry.cn-shanghai.aliyuncs.com/study-03/elasticsearch:7.4.2
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
resources:
limits:
cpu: '1'
memory: 2Gi
requests:
cpu: '1'
memory: 2Gi
ports:
- containerPort: 9200
name: db
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: es-config-volume
mountPath: usr/share/elasticsearch/config/elasticsearch.yml
subPath: elasticsearch.yml
- name: es-data-volume
mountPath: usr/share/elasticsearch/data
volumes:
- name: es-config-volume
configMap:
name: es-config
items:
- key: elasticsearch.yml
path: elasticsearch.yml
volumeClaimTemplates:
- metadata:
name: es-data-volume
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs"
resources:
requests:
storage: 5Gi
创建 es-svc
[root@mast01 elk]# vim es-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: es-svc
namespace: logging
labels:
k8s-app: elasticsearch
spec:
selector:
k8s-app: elasticsearch
ports:
- name: out
port: 9200
protocol: TCP
部署es
[root@mast01 elk]# kubectl create namespace logging
#部署服务
[root@mast01 elk]# kubectl create -f es-config.yaml
[root@mast01 elk]# kubectl create -f es-svc-headless.yaml
[root@mast01 elk]# kubectl create -f es-sts.yaml
[root@mast01 elk]# kubectl create -f es-svc.yaml
#等待片刻,查看一下es的pod部署到了k8s-slave1节点,状态变为running
[root@mast01 elk]# kubectl -n logging get po -o wide
NAME READY STATUS RESTARTS AGE IP
elasticsearch-0 1/1 Running 0 15m 10.244.0.126
elasticsearch-1 1/1 Running 0 15m 10.244.0.127
elasticsearch-2 1/1 Running 0 15m 10.244.0.128
#然后通过curl命令访问一下服务,验证es是否部署成功
[root@mast01 elk]# kubectl -n logging get svc
es-svc ClusterIP 10.104.226.175 <none> 9200/TCP 2s
es-svc-headless ClusterIP None <none> 9300/TCP 32m
[root@mast01 elk]# curl 10.102.66.227:9200
{
"name" : "elasticsearch-2",
"cluster_name" : "huqi-elasticsearch",
"cluster_uuid" : "ZiE8JOtvTIqBH3aP1njp1Q",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
部署kibana
[root@mast01 elk]# vim kibana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
selector:
matchLabels:
app: "kibana"
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: registry.cn-shanghai.aliyuncs.com/study-03/kibana:7.4.2
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_HOSTS
value: http://es-svc:9200
- name: SERVER_NAME
value: kibana-logging
- name: SERVER_REWRITEBASEPATH
value: "false"
ports:
- containerPort: 5601
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
ports:
- port: 5601
protocol: TCP
targetPort: 5601
nodePort: 32001 # 指定NodePort范围在30000-32767之间,如不指定,K8s会自动分配
type: NodePort
selector:
app: kibana
[root@mast01 elk]# kubectl create -f kibana.yaml
deployment.apps/kibana created
service/kibana created
configmap配置
fluentd为日志采集服务,kubernetes集群的每个业务节点都有日志产生,因此需要使用daemonset的模式进行部署。
为进一步控制资源,会为daemonset指定一个选择标签,fluentd=true来做进一步过滤,只有带有此标签的节点才会部署fluentd。
日志采集,需要采集哪些目录下的日志,采集后发送到es端,因此需要配置的内容比较多,我们选择使用configmap的方式把配置文件整个挂载出来
[root@mast01 elk]# vim fluentd-es-config-main.yaml
apiVersion: v1
data:
fluent.conf: |-
# This is the root config file, which only includes components of the actual configuration
#
# Do not collect fluentd's own logs to avoid infinite loops.
<match fluent.**>
@type null
</match>
@include fluentd/etc/config.d/*.conf
kind: ConfigMap
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
name: fluentd-es-config-main
namespace: logging
configmap配置文件注意点
数据源source的配置,k8s会默认把容器的标准和错误输出日志重定向到宿主机中。
默认集成了 kubernetes_metadata_filter 插件,来解析日志格式,得到k8s相关的元数据,raw.kubernetes。
match输出到es端的flush配置。
[root@mast01 elk]# vim fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path var/log/containers/*.log
pos_file var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head false
</source>
# Detect exceptions in the log output and forward them as one log entry.
# https://github.com/GoogleCloudPlatform/fluent-plugin-detect-exceptions
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
hosts elasticsearch-0.es-svc-headless:9200,elasticsearch-1.es-svc-headless:9200,elasticsearch-2.es-svc-headless:9200
#port 9200
logstash_format true
#index_name kubernetes-%Y.%m.%d
request_timeout 30s
<buffer>
@type file
path var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
daemonset配置文件注意点
需要配置rbac规则,因为需要访问k8s api去根据日志查询元数据。
需要将/var/log/containers/目录挂载到容器中。
需要将fluentd的configmap中的配置文件挂载到容器内。
想要部署fluentd的节点,需要添加fluentd=true的标签。
[root@mast01 elk]# vim fluentd.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
addonmanager.kubernetes.io/mode: Reconcile
k8s-app: fluentd-es
name: fluentd-es
namespace: logging
spec:
selector:
matchLabels:
k8s-app: fluentd-es
template:
metadata:
labels:
k8s-app: fluentd-es
spec:
containers:
- env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
image: registry.cn-shanghai.aliyuncs.com/study-03/fluentd:2.5.2
imagePullPolicy: IfNotPresent
name: fluentd-es
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- mountPath: var/log
name: varlog
- mountPath: var/lib/docker/containers
name: varlibdockercontainers
readOnly: true
- mountPath: fluentd/etc/config.d
name: config-volume
- mountPath: fluentd/etc/fluent.conf
name: config-volume-main
subPath: fluent.conf
nodeSelector:
fluentd: "true"
securityContext: {}
serviceAccount: fluentd-es
serviceAccountName: fluentd-es
volumes:
- hostPath:
path: var/log
type: ""
name: varlog
- hostPath:
path: var/lib/docker/containers
type: ""
name: varlibdockercontainers
- configMap:
defaultMode: 420
name: fluentd-config
name: config-volume
- configMap:
defaultMode: 420
items:
- key: fluent.conf
path: fluent.conf
name: fluentd-es-config-main
name: config-volume-main
部署Fluentd
## 给slave1打上标签,进行部署fluentd日志采集服务
[root@mast01 elk]# kubectl label node work01 fluentd=true
node/work01 labeled
[root@mast01 elk]# kubectl label node work02 fluentd=true
node/work02 labeled
# 创建服务
$ kubectl create -f fluentd-es-config-main.yaml
configmap/fluentd-es-config-main created
$ kubectl create -f fluentd-configmap.yaml
configmap/fluentd-config created
$ kubectl create -f fluentd.yaml
serviceaccount/fluentd-es created
clusterrole.rbac.authorization.k8s.io/fluentd-es created
clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created
daemonset.extensions/fluentd-es created
## 然后查看一下pod是否已经在k8s-slave1
[root@mast01 elk]# kubectl -n logging get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
elasticsearch-0 1/1 Running 0 5h3m 10.244.205.194 work01 <none> <none>
elasticsearch-1 1/1 Running 0 127m 10.244.75.71 work02 <none> <none>
elasticsearch-2 1/1 Running 0 126m 10.244.205.195 work01 <none> <none>
fluentd-es-94lcv 1/1 Running 0 96m 10.244.75.74 work02 <none> <none>
fluentd-es-l8w64 1/1 Running 0 96m 10.244.205.196 work01 <none> <none>
kibana-6dfbd68bd8-tt8z2 1/1 Running 0 112m 10.244.75.73 work02 <none> <none>
10、创建测试容器
#在slave节点中启动服务,同时往标准输出中打印测试日志,到kibana中查看是否可以收集
[root@mast01 elk]# vim test-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
nodeSelector:
fluentd: "true"
containers:
- name: count
image: alpine:3.6
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
[root@mast01 elk]# kubectl get po
NAME READY STATUS RESTARTS AGE
counter 1/1 Running 0 6s
11、配置kibana
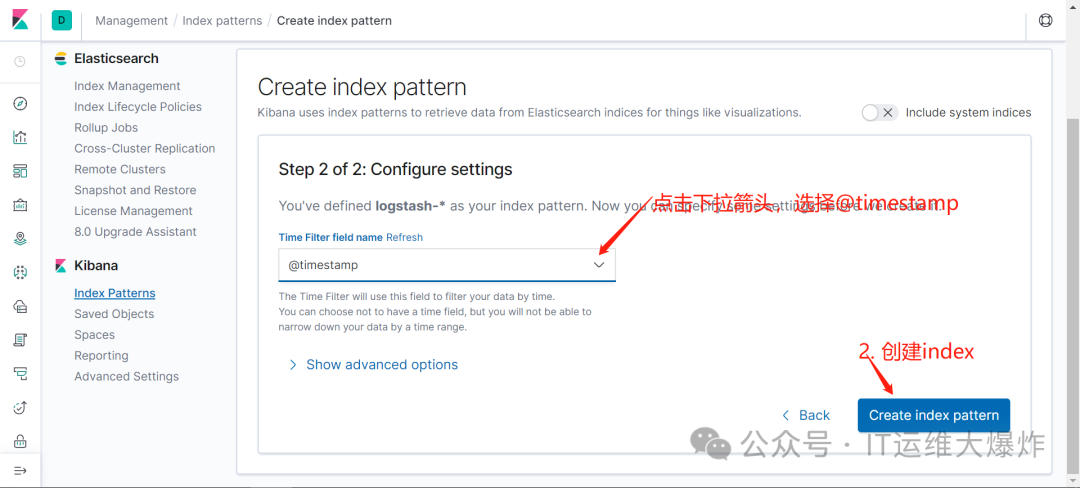
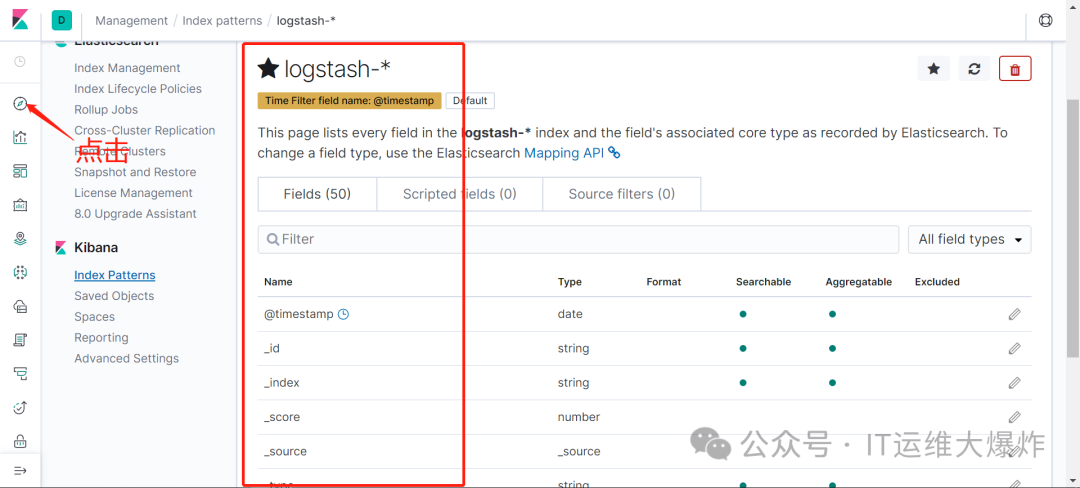
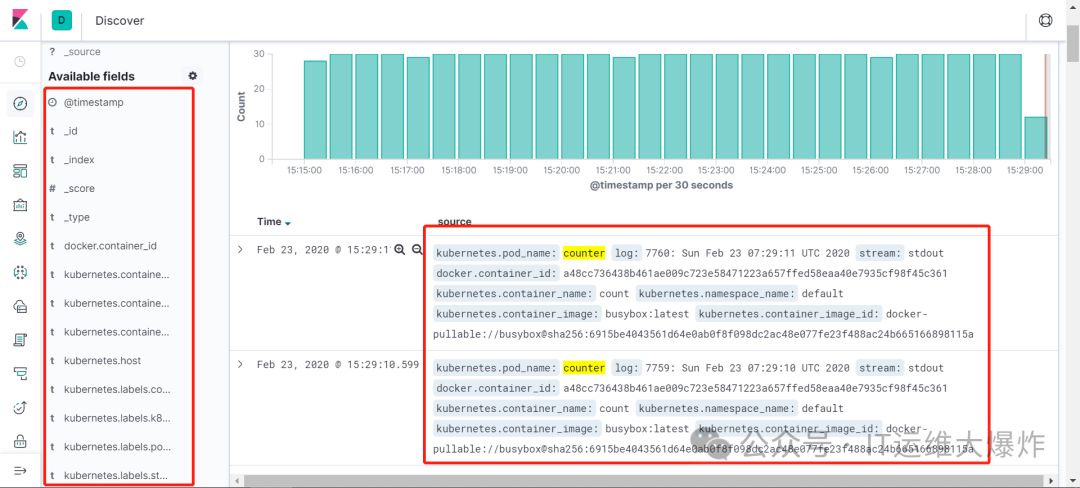
欢迎大家扫码关注:

本公众号只写原创,不接广告、不接广告、不接广告。下期小伙伴想学习什么技术,可以私信发我吆。

