Elasticsearch 的跨集群复制(Cross - Cluster Replication,简称 CCR)是 Elasticsearch 6.7 版本引入的一项高级功能,它允许用户将一个 Elasticsearch 集群中的索引数据同步复制到另一个远程的 Elasticsearch 集群。该功能主要应用于数据异地备份、灾难恢复、降低访问延迟以及集中式报告等场景。
CCR 采用主动 - 被动模型(active - passive model),数据被索引到一个领导者索引(leader index),并且数据会被复制到一个或多个只读的跟随者索引(read - only follower indices)。复制过程是由跟随者索引主动发起的 pull 操作,即从领导者索引主动拉取数据。领导者索引可进行读写操作,而跟随者索引是只读的,以此确保数据的一致性和完整性。
(1) 环境准备:确保至少存在两个 Elasticsearch 集群,一个作为领导者(源数据集群),另一个作为跟随者(目标数据集群)。(2) 配置远程集群:在跟随者集群上配置领导者集群的信息,包括集群名称和种子节点(seed nodes)。(3) 创建领导者索引:在领导者集群上创建索引,并确保索引的soft_deletes属性开启,这是 CCR 复制机制的基础。(4) 建立跟随者索引:在跟随者集群上创建跟随者索引,并指定要复制的领导者索引。跟随者索引的创建可通过 Kibana 的 UI 界面或者使用 API 完成。
(1) 数据备份和灾难恢复:借助 CCR,能够在不同的数据中心之间复制数据,当一个数据中心发生故障时,可快速切换到另一个数据中心,保障服务的连续性以及数据的安全性。
(2) 数据局部性:将数据复制到更靠近用户的位置,减少延迟,提升用户体验。
(3) 集中式报告:把分散在不同地理位置的数据复制到一个中央集群,便于开展集中的数据分析和报告。
(1) CCR 功能需要 Elasticsearch 的白金版订阅。
(2) 领导者索引和跟随者索引的soft_deletes属性必须开启,这是 CCR 复制机制的基础。
(3) 跟随者索引是只读的,无法进行写操作。
(4) 需确保两个集群之间的网络互通,并且集群版本兼容。
在实际应用中,CCR 可用于多种场景。例如,一家公司在全球多个地区设有数据中心,可通过 CCR 将数据同步到各个地区的数据中心,实现数据的就近访问和灾难恢复。此外,还可将各地区的数据复制到总部的中央集群,进行统一的数据分析和报告。
通过跨集群复制,能够跨集群复制索引,以实现以下目的:跨集群复制采用主动 - 被动模型。将索引数据索引到领导者索引,并且数据会被复制到一个或多个只读 follower 索引。在将 follower 索引添加到集群之前,必须配置包含 leader 索引的远程集群。当 leader 索引收到写入操作时,follower 索引会从远程集群上的 leader 索引进行数据同步。既可以手动创建追随者索引(indices),也可以配置 Auto - Follow 模式。手动创建时,需遵循相应的创建流程和参数设置。而配置 Auto - Follow 模式,则能够自动创建 follower 索引,获取新的时间序列索引,这种自动创建方式可提高效率,减少人工干预可能带来的失误,保证数据在不同索引间的高效流转和一致性。可以在单向或双向设置中配置跨集群复制集群:(1) 在单向配置中,一个集群仅包含 leader 索引,另一个集群仅包含 follower 索引。(2) 在双向配置中,每个集群都包含 leader 和 follower indices 的 Follower 索引。在单向配置中,包含 follower indices 的集群必须运行与远程集群相同或更新版本的 Elasticsearch。
当主集群出现故障时,可将辅助集群用作热备份以实现灾难恢复。利用 data locality(数据本地化)可使数据集靠近应用程序服务器(和用户),从而减少高成本的延迟。通过集中报告可最大程度地减少查询多个地理分布式 Elasticsearch 集群时的网络流量和延迟,或者将搜索任务卸载到辅助集群。可以观看跨集群复制网络研讨会(https://www.elastic.co/cn/webinars/cross-cluster-replication?elektra=docs),以了解更多相关使用案例信息。然后,依据网络研讨会中的演示在本地计算机上设置并运行跨集群复制。在所有这些用例中,在每个集群中都必须进行相应配置。在配置跨集群复制用于灾难恢复时,安全配置不会被复制。为确保 Elasticsearch 的功能状态已备份,需定期创建快照。这样一来,就可以恢复安全配置中的本机用户、角色和令牌等安全信息。
灾难恢复能够为任务关键型应用程序提供对数据中心或区域中断情况的承受能力。这一用例是跨集群复制部署中最为常见的类型。以下是一些可用于支持灾难恢复和高可用性的架构:灾难恢复能够为任务关键型应用程序提供对数据中心或区域中断情况的承受能力。这一用例是跨集群复制部署中最为常见的类型。以下是一些可用于支持灾难恢复和高可用性的架构:在此配置下,数据会从生产数据中心复制至灾难恢复数据中心。由于 follower 索引对 leader 索引进行了复制,所以在生产数据中心无法使用时(系统仍可正常运行),灾难恢复数据中心可利用已复制的数据继续维持相关业务的运转,从而保障整个系统的连续性和稳定性,有效避免因生产数据中心故障而导致的数据丢失或业务中断问题。② 多个灾难恢复数据中心:
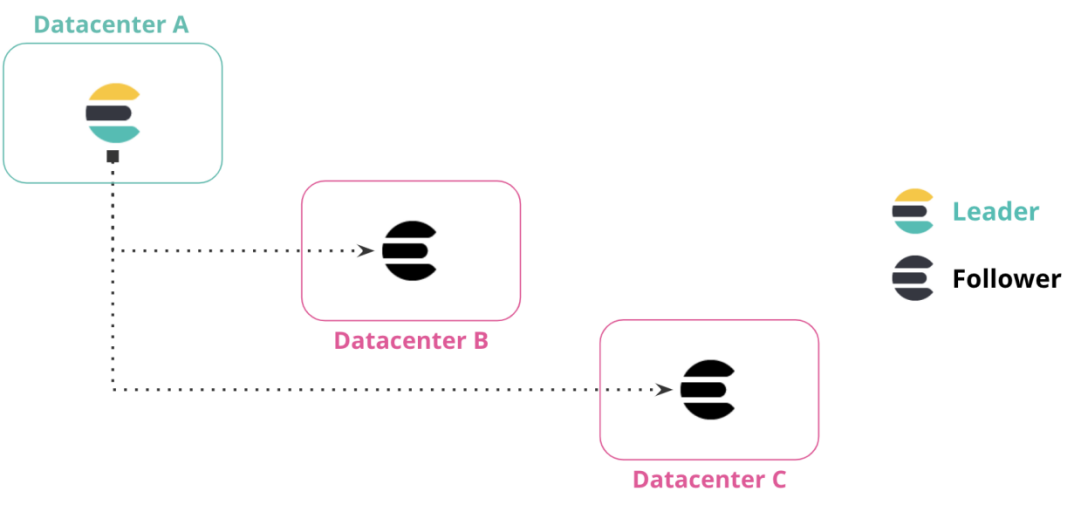
可以将数据从一个数据中心同时复制到多个数据中心。这种配置方式不仅能够提供灾难恢复功能,还能保障高可用性。它确保了在主数据中心关闭的情况下,数据由于在两个(或多个)数据中心中都有复制,不会出现数据丢失或不可用的情况。在下图所展示的示例中,数据中心 A 里的数据被分别复制到了数据中心 B 和数据中心 C。数据中心 B 和数据中心 C 都拥有来自数据中心 A 的索引的领导者只读副本,这样即使数据中心 A 出现故障,数据中心 B 和数据中心 C 依然可以凭借这些副本继续为系统提供必要的数据支持,维持系统的正常运行。③ 链式复制:
可以在多个数据中心之间进行数据的跨中心复制,从而形成复制链。具体而言,在下图呈现的场景中,数据中心 A 拥有领导者索引。数据中心 B 会从数据中心 A 复制数据,而数据中心 C 则是从数据中心 B 中的追随者索引复制数据。这些数据中心之间的这种关联方式构成了链式复制模式,这种模式能够在不同数据中心之间有序地传递和备份数据,以实现诸如数据冗余、灾难恢复和提高系统整体可用性等功能,确保在某个数据中心出现问题时,数据链上的其他数据中心依然可以维持数据的可用性和完整性。④ 双向复制:
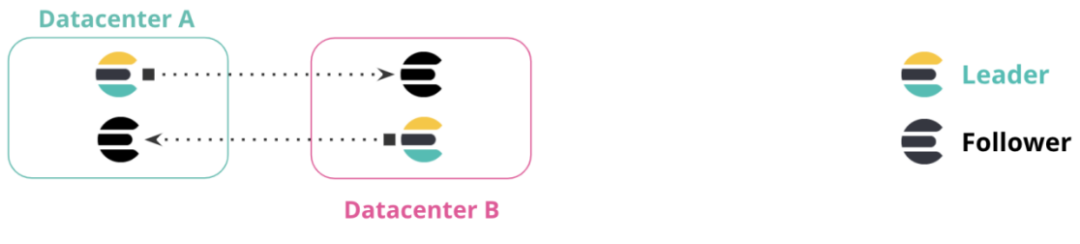
在双向复制的设置情境下,所有的集群都能够访问并查看所有数据,并且每个集群都有一个可写入的索引,无需手动实施故障转移操作。应用程序可以通过向每个数据中心的 URL 写入数据,并能够跨多个索引读取数据来获取全部信息。当某个集群或者数据中心出现不可用的情况时,系统依然可以正常运行。例如,在下图中,如果数据中心 A 不可用,系统可以继续使用数据中心 B,整个过程无需手动进行故障转移操作。 而当数据中心 A 重新联机时,集群之间的数据复制将自动恢复,从而保证数据的一致性和系统的稳定性,这种双向复制设置极大地提高了系统应对故障的能力和整体的可用性。此配置对于那些不存在更新情况、仅涉及索引的工作负载来说尤为有用,特别是当记录的值始终保持固定、不会发生变化的时候。在这样的配置模式下,由 Elasticsearch 所索引的文档是恒定不变的。与此同时,客户端会与 Elasticsearch 一同部署在每个数据中心的集群当中,并且它们不会和位于不同数据中心的集群进行通信。这样的架构安排能够在特定的业务场景中,有效简化系统的通信链路,降低因跨数据中心交互可能产生的复杂性和潜在风险,确保整个系统围绕各数据中心内的集群及客户端平稳运行,专注于处理相应的仅索引的工作负载。⑤ 数据位置:
将数据安置在更靠近用户或者应用程序服务器的位置,能够有效减少数据传输过程中的延迟以及系统的响应时间。在 Elasticsearch 数据复制的场景中,这一方法同样适用。例如,可以把产品目录或者参考数据集复制到全球 20 个甚至更多的数据中心,以此来最大程度地缩短数据与应用程序服务器之间的距离。从以下图示可以看出,数据从一个中央数据中心被复制到另外三个位于不同区域的数据中心。中央数据中心存有 leader 索引,而其他三个数据中心则包含用于在各自特定区域中复制数据的 follower 索引。这种配置方式能够让数据与访问它的应用程序之间的距离更近,从而提升系统性能,优化用户体验。⑥ 集中报告:
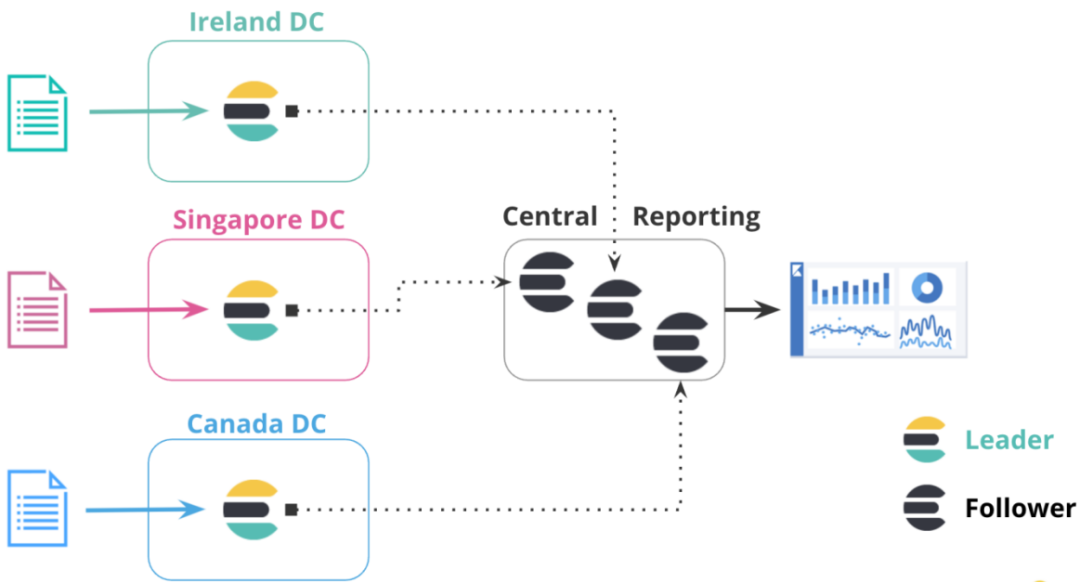
在大型网络环境中,网络效率可能会比较低下。在这种配置情况下,可以将来自多个较小集群的数据添加到集中式报告集群中。例如,一家大型全球银行可能在全球范围内拥有 100 个 Elasticsearch 集群,这些集群分布在每个银行分行所处的不同区域。通过跨集群复制,这家银行可以将所有 100 个集群中的事件复制到中央集群,进而在本地对这些事件进行分析和聚合,以用于报告。如此一来,银行无需维护镜像集群,而是可以利用跨集群复制来复制特定的索引。在下图中,来自不同区域的三个数据中心的数据被复制到集中式报表集群。这种配置使得数据能够从各个区域中心(Regional Hubs)复制到中央集群,并且可以在中央集群本地运行所有报告相关的操作,这样能有效提高报告效率,同时降低网络负担对整体业务的影响。
尽管跨集群复制是在索引级别进行设置的,但实际上 Elasticsearch 是在分片级别来具体实现复制操作的。当创建关注者(follower)索引时,该索引中的每一个分片都会从对应的 leader 索引获取数据,这也就意味着一个 follower 索引所包含的分片数量与它对应的 leader 索引的分片数量是相同的。对于 leader 索引所执行的所有操作,都会被 follower 索引同步执行,例如创建、更新或者删除文档这类操作。这些操作请求可以从 leader 分片的任意副本(无论是主分片还是副本分片)来进行处理。当 follower 分片向 leader 分片发送读取请求时,leader 分片会基于配置 follower 索引时所设定的规则,利用任何新产生的操作来进行响应。倘若当时没有新的操作可用,那么 leader 分片会等待新操作出现,直至达到配置的超时时间。一旦超时时间过去,leader 分片就会向 follower 分片回复告知没有新的操作。随后,follower 分片会更新自身的分片统计信息,并立即再次向 leader 分片发送另一个读取请求。这样的通信模型能够确保远程集群(remote cluster)和本地集群(local cluster)之间的连接得以持续维持使用,有效避免因外部因素(比如防火墙的限制等)而被强制终止。如果 follower 分片发送的读取请求出现失败的情况,此时就需要去检查失败的原因。要是故障原因被判定为是可恢复的(例如网络故障这种情况),那么 follower 分片将会进入重试循环,不断尝试再次发送请求。反之,如果故障原因是不可恢复的,那么 follower 分片将会暂停运行,直至相关问题得到恢复、满足重新运行的条件为止。总的来说,跨集群复制(CCR)是一个功能强大的工具,它能够助力企业实现跨数据中心的数据复制,通过保障数据在不同集群间的有效同步,显著提高数据的可用性,进而确保业务能够持续、不间断地运行,维持业务的连续性。倘若想要了解更多关于跨集群复制的详细信息以及最佳实践操作方法,可以参考 Elasticsearch 的官方文档以及相关的社区博客内容,从中获取更为深入、全面的知识和实用的经验技巧。
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!