





一些用户已经注意到Elasticsearch 8.6、8.7 和 8.8 在很多不同类型数据写入时速度都获得了可观的提升,从简单的Keywords到复杂的KNN向量,再到一些负载比较重的写入处理管道都是这样。写入速度涉及到很多方面:运行写入处理管道、反转内存中的数据、刷新段、合并段,所有这些通常都需要花费不可忽略的时间。幸运的是,我们在所有这些领域都进行了改进,这为端到端的写入速度带来了很不错的提升。例如,在我们的基准测试里面,8.8比8.6写入速度提升了13%,这个基准测试模拟了真实的日志写入场景,其中包含了多种数据集、写入处理管道等等。请参见下图,您可以看到在这段时间内,实施了这些优化措施后写入速率从 ~22.5k docs/s 提升到了 ~25.5k docs/s。
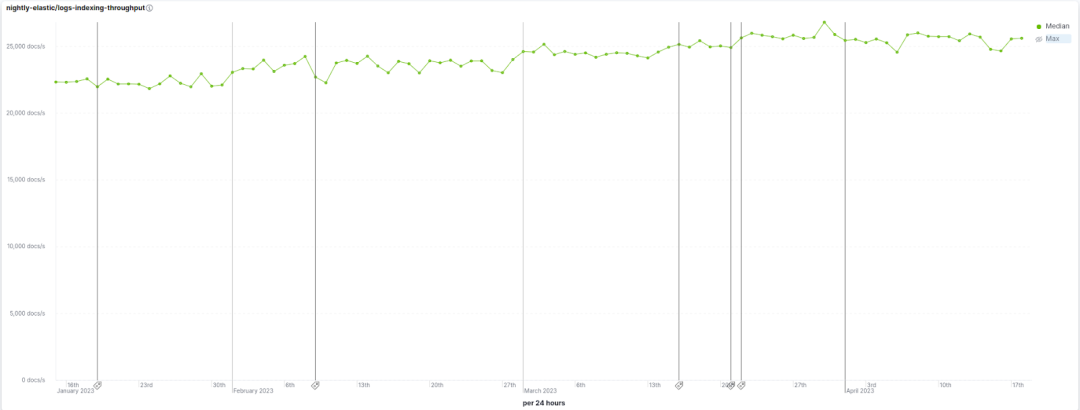
这篇博客深入探讨了在 8.6、8.7 和 8.8中实现写入速度提升的一些关键优化。
更快地合并 kNN 向量
Elasticsearch实现kNN搜索的底层结构是Lucene的Hierarchical Navigable Small World (HNSW) 图。该图甚至可以在数百万个向量上提供异常快速的kNN搜索。然而,构建图本身却是一项昂贵的任务。构建图需要在现有图中进行多次搜索、建立连接并更新当前的邻居集。在 Elasticsearch 8.8之前,合并段时会创建一个全新的HNSW图索引。意味着,来自每个段的每个向量都被单独添加到一个完全空的图形中。随着段变大,它们的数量增加,合并会变得非常昂贵。
在Elasticsearch 8.8中,Lucene对合并HNSW图进行了重大改进。Lucene智能地复用现有最大的HNSW图。因此,Lucene不再像以前那样从一个空图开始,而是利用之前完成的所有工作来构建现有最大的段。合并较大的段时,这个改进带来的提升是巨大的。在我们自己的基准测试中,我们发现段合并时间减少了40%以上,刷新吞吐量提高了两倍以上。这显著减少了集群在索引庞大的向量数据集时所承受的负载。
写入处理管道的优化
写入处理管道使用处理器在文档被索引之前执行数据转换工作 ——例如,设置或删除字段、解析日期或 json字符串等,以及使用ip地址或其他数据来查找地理位置。使用写入处理管道,可以从日志文件发送文本行,直接让Elasticsearch将文本转换为结构化文档。我们绝大部分开箱即用数据整合组件使用写入处理管道来帮助您快速地解析和强化各种数据源的数据。
我们通过在多个管道间传递单个文档实例来消除了大部分开销. 我们优化了一些最常用的处理器: 设置和追加使用mustache模板的处理器现在有更快的模板模型创建 和mustache模板执行速度
现在的日期处理器缓存它们关联的日期解析器
geoip处理器不再依赖反射
在8.6.0 我们优化了painless脚本,改进了脚本处理器和条件检查
此外,写入处理的总体指标和统计数据比以前更准确:
管道执行后数据序列化的时间被正确计算了
针对多个管道执行的文档只被统计一次
最后,底层热代码的优化减少了所有处理文档的开销,比如更快的集合求交集, 更快的元数据验证,和更快的自我引用检查.
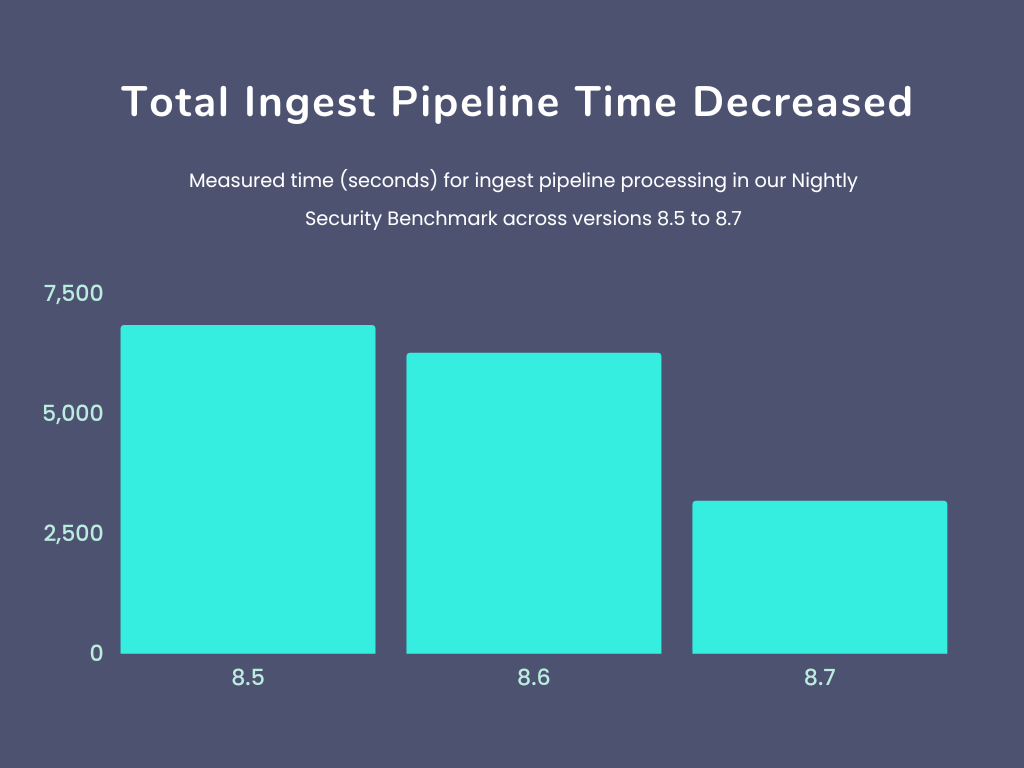
在升级到 8.7或更新版本后,我们希望这些速度提升能够在一些复杂数据处理的时候体现出来。
Keyword和数字字段的优化
我们有很多数据集,其中大部分都是简单的数字和Keyword字段,它们会自动受益于针对这些字段类型的改进。两项改进有助于索引这些字段类型:
Elasticsearch在可能的情况下,都改用了Lucene 9.5中新的IntField、LongField、FloatField 和 DoubleField,以及Lucene 9.6中新的KeywordField。这些字段类型允许用户在单个Lucene字段上同时启用indexing和doc values——在这以前您需要提供两个字段:一个启用indexing,另一个启用doc values。事实证明,这一旨在使Lucene更加人性化的改进也有助于提高索引速度,这超出了我们的预期!请参阅注释 AH 和 AJ,网址为http://people.apache.org/~mikemccand/lucenebench/sparseResults.html#index_throughput 查看这些更改对Lucene每晚基准测试的影响。
简单Keywords现在直接索引,而不是通过TokenStream抽象。TokenStreams通常是分析器的输出,用来导出terms、positions、offsets和payloads 这些为文本字段构建倒排索引所需的所有信息。为了保持一致性,简单Keywords也可以通过TokenStream返回单个token来进行索引。现在Keyword值直接被索引,无需通过TokenStream抽象。请参阅下面网页中注释AH http://people.apache.org/~mikemccand/lucenebench/sparseResults.html#index_through看看这个变化对Lucene每晚基准测试的影响。
优化索引排序
索引排序是一个强大的功能,可以通过提前终止查询或将可能匹配查询条件的文档聚集在一起等手段来加速查询。此外,索引排序是时序数据流基础的一部分。所以我们花了一些时间来解决索引排序中一些索引时遇到的瓶颈。这使得在HTTP日志数据集的基准测试中写入速度提高了12%,因为这个测试数据集会按@timestamp降序排列。
针对时序数据优化的新合并策略
一直以来,Elasticsearch都依靠Lucene默认的合并策略:TieredMergePolicy。这是一个非常明智的合并策略,它试图将段组织成指数数量的层,默认情况下每个层有10个段。它擅长做低成本的合并、回收删除的文档等工作。那为什么要使用不同的合并策略呢?
时序数据的特殊之处在于它通常以近似@timestamp的顺序写入,因此通过后续刷新操作形成的段时间戳范围通常是不会重叠的。对于在@timestamp字段上进行范围查询,这是一个有趣的属性,因为许多段要么根本不与查询范围重叠,要么完全包含在查询范围内,这是处理范围查询非常高效的两种情况。不幸的是,段时间戳范围不重叠的特性会被TieredMergePolicy破坏,因为它更乐意将不相邻的段合并在一起。
所以有@timestamp日期类型字段的分片现在使用Lucene的LogByteSizeMergePolicy,它是TieredMergePolicy的前身. 两者之间的一个关键区别是LogByteSizeMergePolicy只会合并相邻的段,所以在假设数据以 @timestamp 顺序写入的情况下,这可以使得合并后段的@timestamp属性继续保持不会重叠。这个变化使得在EQL 基准测试中一些查询速度加快了多达3倍,这些查询需要按“@timestamp”顺序遍历事件的序列!
但这个属性也有一个缺点,因为LogByteSizeMergePolicy在计算相等大小段的合并方面不如 TieredMergePolicy灵活,这是通过合并限制写入放大的最佳方法。为了减轻这种不利影响,合并因子已从TieredMergePolicy的10提高到 32。虽然增加合并因子通常会使搜索速度变慢,但由于在相同的合并因子下, LogByteSizeMergePolicy比TieredMergePolicy会更积极地合并数据,并且保留段的@timestamp 范围不重叠极大地帮助了时间戳字段的范围查询,通常对于时序数据最常用的就是根据时间戳进行过滤。
这就是对 8.6、8.7 和 8.8写入性能提升的分析。我们会在后续多个小版本中带来更多的加速优化,敬请期待!
