




我们非常高兴地宣布,Elasticsearch Serverless 现已全面上线。我们重新架构了 Elasticsearch 作为一个完全托管的服务[1],它可以根据您的数据、使用情况和性能需求自动扩展。它具有 Elasticsearch 的强大功能和灵活性,同时没有运营负担。
自从今年春季技术预览[2]以来,我们引入了新的功能,帮助开发者更快地构建和管理应用程序。无论您是在实现语义搜索、关键词搜索,甚至是图片搜索,Elasticsearch Serverless 都简化了这个过程,让您可以专注于创新,而不是基础设施。
Elasticsearch Serverless 旨在消除管理资源的复杂性,使得运行搜索、RAG 和 AI 驱动的应用程序变得更加容易,同时保持 Elasticsearch 所知名的速度、相关性和多功能性。
在这篇文章中,我们将分享 Elasticsearch Serverless 如何通过其现代架构和对开发者友好的功能简化构建搜索应用程序的过程。
Elasticsearch 是搜索体验的支柱
Elasticsearch 长期以来一直是开发者、数据科学家和全栈工程师追求高性能、可扩展搜索和向量数据库能力的信赖引擎。其强大的相关性功能和灵活性使其成为无数搜索驱动应用程序的支柱。
Elasticsearch 在查询速度和向量量化方面的创新使其成为领先的向量数据库,支持语义搜索和混合搜索等可扩展的 AI 驱动用例。
今天,Elasticsearch 通过结合以下特点继续设定搜索的金标准:
• 高速度和相关性:用于文本搜索。
• 灵活的查询能力:定制搜索工作流。
• 无缝处理混合查询:结合向量和词汇搜索。
• 以 Lucene 为根基的开源核心:不断优化,推动搜索技术的界限。
随着搜索用例的发展——包括混合搜索、AI 和推理以及动态工作负载——团队有更多的选择来扩展和管理基础设施,以满足其独特的需求。这些不断变化的需求为我们重新思考如何设计扩展提供了令人兴奋的机会。
以无服务器的速度和简便性实现 Elasticsearch
Elasticsearch Serverless 基于 Elasticsearch 的优势,解决了现代工作负载的需求,这些工作负载通常具有大型数据集、AI 搜索和不可预测的流量。Elasticsearch Serverless 通过重新设计的架构[3]来应对这些挑战。
从根本上说,Elasticsearch Serverless 基于解耦计算和存储模型。这是一种架构变更,消除了重复数据传输的低效,并利用对象存储的可靠性。从这里开始,分离关键组件能够独立扩展索引和搜索工作负载,解决在高需求场景中平衡性能和成本效益的长期挑战。
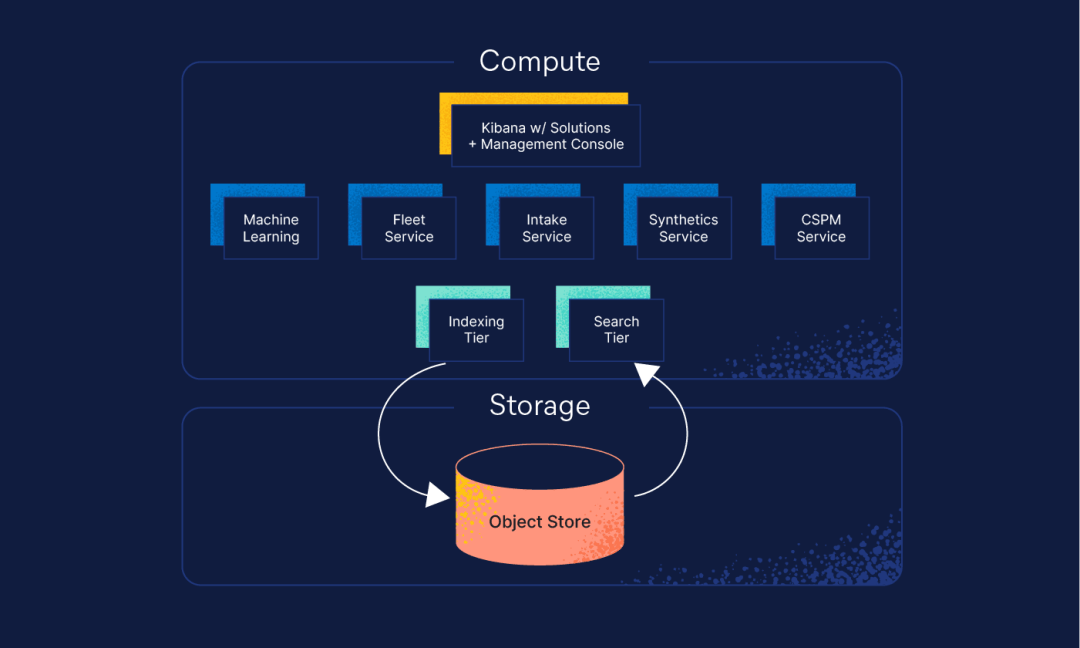
解耦的计算和存储
Elasticsearch Serverless 使用对象存储来实现可靠的数据存储和成本效益的扩展。通过消除多副本的需求,减少了索引成本和数据重复。这种方法确保存储只用于必要的内容,消除浪费,同时最大化效率。
为了保持 Elasticsearch 的速度,段级查询并行化优化了从对象存储(如 S3)检索数据的速度,同时高级缓存策略确保快速访问常用数据。
动态自动扩展而无妥协
解耦架构还通过分离搜索和摄取工作负载,实现了更智能的资源管理,使其能够根据特定需求独立扩展。这种分离确保:
• 并发更新和搜索不再争夺资源。CPU 周期、内存和 I/O 独立分配,即使在高摄取操作期间也能确保一致性能。
• 摄取密集型用例受益于独立计算。即使在索引大量数据时,也能确保快速可靠的搜索性能。
• 向量搜索工作流繁荣发展。解耦允许计算密集型索引(如嵌入生成)而不影响查询速度。
摄取、搜索和机器学习的资源动态且独立地扩展,以适应多样的工作负载。无需为高峰负载过度配置,也不用担心需求高峰期间的停机。
了解更多关于我们的动态和基于负载的摄取[4]和搜索[5]自动扩展。
高性能查询执行
Elasticsearch Serverless 通过构建在 Elasticsearch 作为向量数据库的优势上,增强了查询执行。查询性能和向量量化方面的创新确保了现代用例的快速高效搜索体验。亮点包括:
• 通过段级查询并行化加快数据检索,使多个并发请求能够从对象存储中获取数据,大幅减少延迟,即使数据未本地缓存也能确保快速访问。
• 更智能的缓存,通过智能查询结果重用和 Lucene 中优化的数据结构,仅缓存使用到的部分索引。
• 定制的 Lucene 索引结构,最大限度地提高各种数据格式的性能,确保每种数据类型以最有效的方式存储和检索。
• 高级向量量化,显著减少高维数据的存储占用和检索延迟,使 AI 和向量搜索更具可扩展性和成本效益。
这种新架构保留了 Elasticsearch 的灵活性——支持分面、过滤、聚合和多样的数据类型——同时简化操作并加速现代搜索需求的性能。对于寻求适应不断变化需求的无操作解决方案的团队,Elasticsearch Serverless 提供了所有 Elasticsearch 的强大功能和灵活性,而无需运营负担。
无论您是希望集成混合搜索的开发者,处理高基数数据集的数据科学家,还是优化 AI 模型相关性的全栈工程师,Elasticsearch Serverless 都能让您专注于提供出色的搜索体验。
获取最新的搜索和 AI 功能
Elasticsearch Serverless 不仅仅是一个托管服务,它是一个旨在加速开发和优化搜索体验的平台。它是您可以访问最新搜索和生成式 AI 功能的地方:
• Elastic AI Assistant:快速访问文档、指南和资源,简化原型设计和实施。
• ELSER 嵌入模型:启用语义或混合搜索功能,提供新的数据查询方式。
• 语义文本字段类型:轻松生成文本字段的向量。
• 更好的二进制量化(BBQ):优化向量存储和内存使用[6],而不影响准确性或性能。
• Elastic 重新排序和互惠排序融合(RRF):通过简化重新排序[7]和混合评分功能,提高结果相关性。
• Playground 和开发者控制台:使用统一界面和 API 工作流,实验新功能,包括生成 AI 集成。
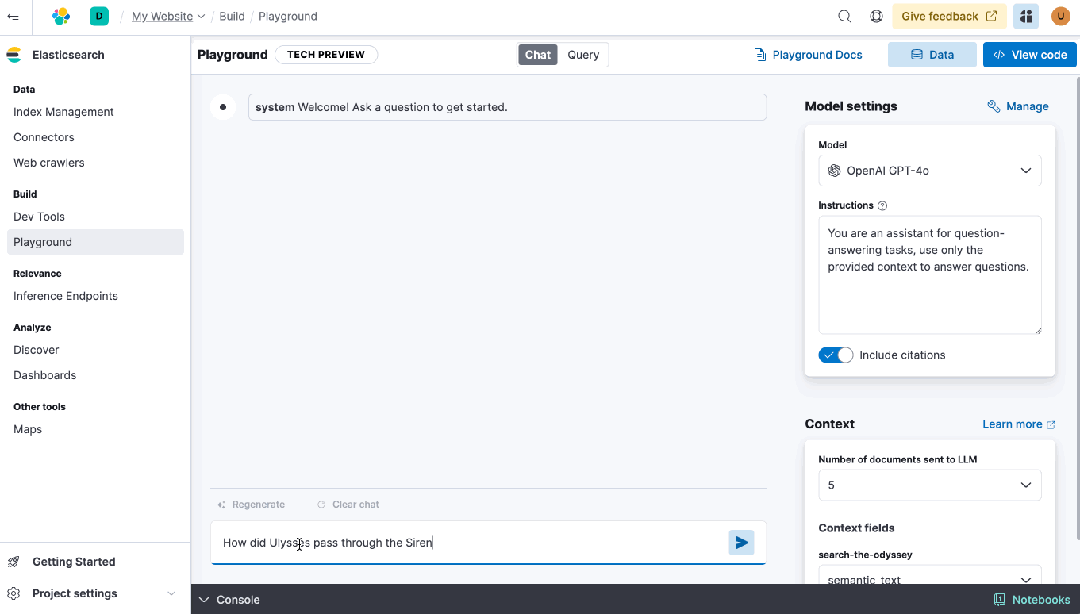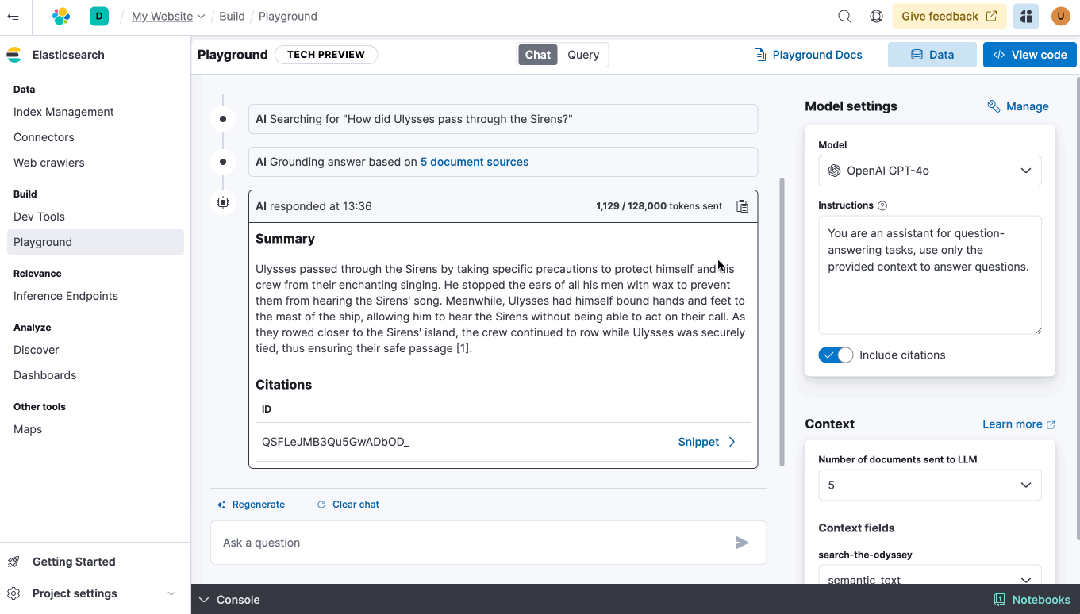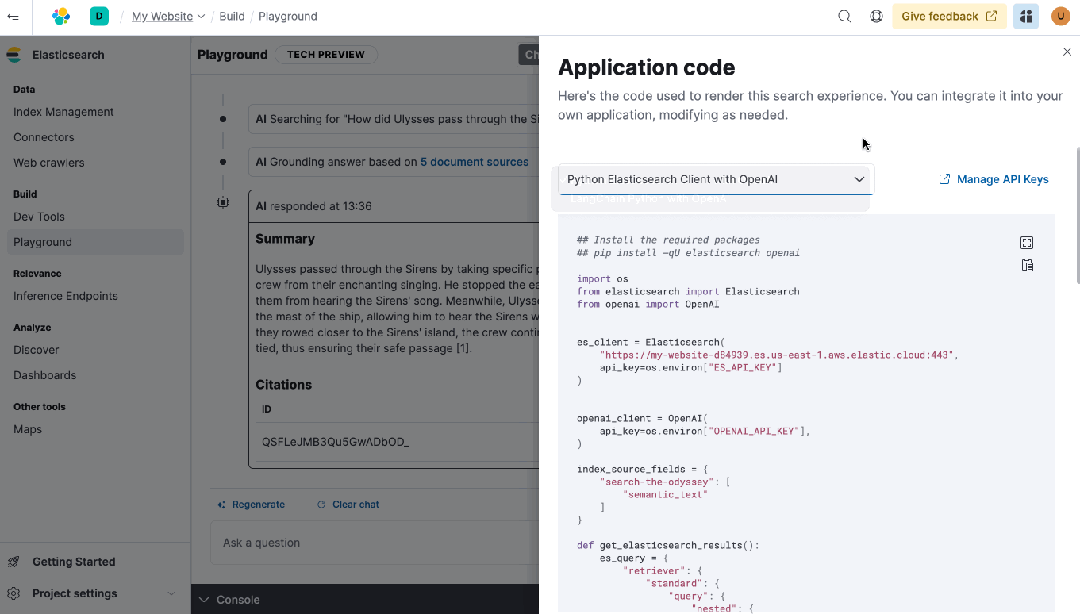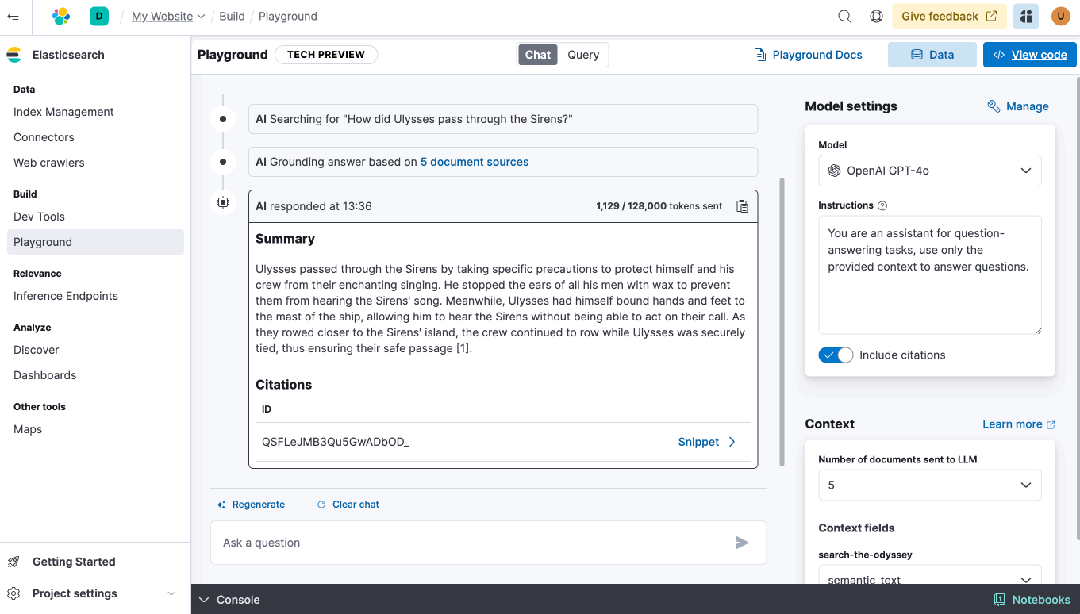
• ES|QL,Elastic 的直观命令语言,完全兼容 Elasticsearch Serverless。
• 使用和性能透明度:通过 Cloud 控制台管理搜索速度和成本,提供详细的性能见解。
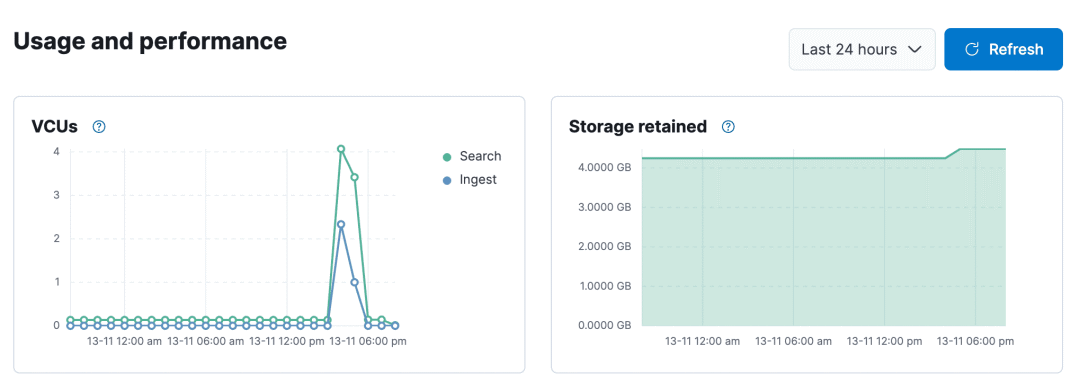
开始使用 Elasticsearch Serverless
准备好开始构建了吗?Elasticsearch Serverless 现已上线,您可以通过我们的免费试用立即体验。
开发者喜欢 Elasticsearch 的速度、相关性和灵活性。使用 Elasticsearch Serverless,您会爱上它的简便性。
探索 Elasticsearch Serverless[8] 并体验重新设计的搜索。了解无服务器定价[9]。
引用链接
[1]
架构了 Elasticsearch 作为一个完全托管的服务: http://www.elastic.co/blog/elastic-cloud-serverless[2]
技术预览: https://www.elastic.co/blog/elasticsearch-serverless-preview[3]
重新设计的架构: https://www.elastic.co/blog/elastic-serverless-architecture[4]
摄取: https://www.elastic.co/search-labs/blog/elasticsearch-ingest-autoscaling[5]
搜索: https://www.elastic.co/search-labs/blog/elasticsearch-serverless-tier-autoscaling[6]
优化向量存储和内存使用: https://www.elastic.co/search-labs/blog/better-binary-quantization-lucene-elasticsearch[7]
简化重新排序: https://www.elastic.co/search-labs/blog/elastic-semantic-reranker-part-1[8]
Elasticsearch Serverless: https://www.elastic.co/elasticsearch/serverless[9]
无服务器定价: https://www.elastic.co/pricing/serverless-search
