





点击蓝字关注我们
什么是熔断机制
熔断机制(Circuit Breaker)是 ES 用来保护自身资源、避免因为资源枯竭(主要是内存)而造成集群不可用的一种安全策略。简单来说,当 ES 判断一次操作可能会占用过多的内存资源时,它会提前抛出异常(通常是 CircuitBreakingException),拒绝继续执行该操作,从而避免更加严重的问题(比如进程被 OOM killer 杀死)。
在 ES 中,熔断器通常基于内存使用量进行判断,当预估消耗的内存超过某个阈值时,熔断就会触发;这些阈值可以通过多个维度配置和监控。
为什么需要熔断机制
资源保护:ES 依赖 JVM 运行,一旦触发了 JVM 的 OOM(OutOfMemoryError),很可能导致 ES 进程崩溃甚至数据丢失。为了尽可能避免这种情况,ES 在执行操作(如聚合查询、字段数据加载)时会对内存使用做预估,防止单个请求导致内存的过度占用。
稳定性保障:熔断可以在请求的早期就拒绝继续执行,从而保证 ES 集群不至于因极端请求而陷入不可恢复的状态。
可控的服务质量:通过合理地设置熔断阈值,可以让运维人员对 ES 使用的内存情况有一个可预期的上限,避免发生异常内存飙升。
ES 中的主要熔断类型
从早期版本到目前版本,ES 中最常见的熔断器包括以下几种:
Field Data Circuit Breaker(字段数据熔断器)
Request Circuit Breaker(请求熔断器)
In-flight Requests Breaker(传输层熔断器)
Parent Circuit Breaker(父熔断器)
ES 7.x 之后默认会采用“基于真实内存使用”(Real Memory Usage)的统计方式来触发熔断,提升了熔断判断的准确性。
3.1 Field Data Circuit Breaker
3.1.1 原理
Field Data 是一种存储在 JVM 堆内的结构,用来支持基于字段值(如聚合、排序等)的操作。当对某些字段进行聚合或者排序操作时,ES 需要将这些字段数据加载到内存(Field Data)中,如果数据量非常大,就有可能导致内存使用量暴增。
Field Data Circuit Breaker 会在需要分配字段数据内存时,进行预估判断。一旦发现超过了可用阈值,ES 会抛出 CircuitBreakingException 并中止该操作。
3.1.2 相关配置
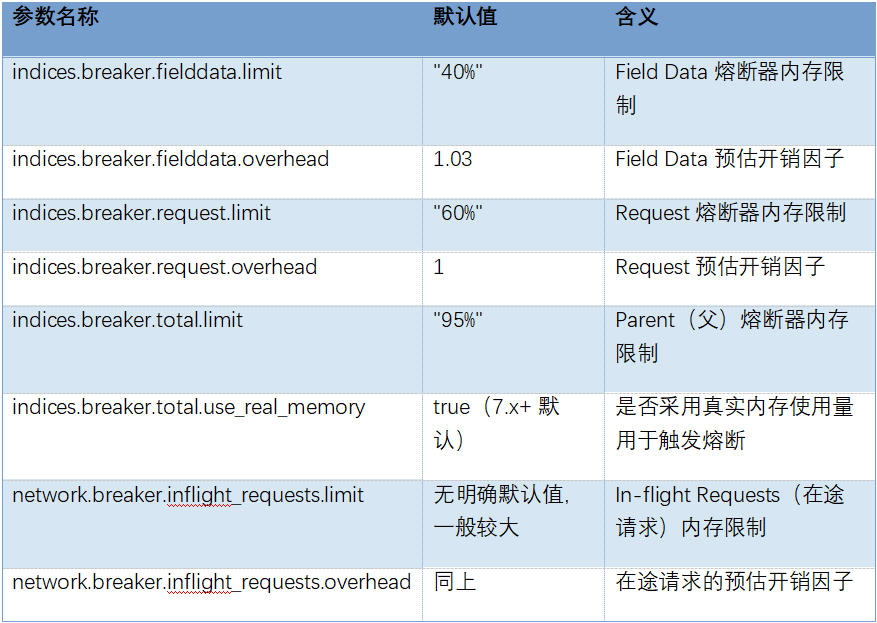
indices.breaker.fielddata.limit:Field Data 的内存使用上限,默认值为 JVM 堆内存的 40%(如 “40%”)。
indices.breaker.fielddata.overhead:预估开销因子(倍数),默认值为 1.03。即在进行内存分配时,会将实际估算值乘以该因子,防止低估。
示例:
PUT _cluster/settings{"persistent": {"indices.breaker.fielddata.limit": "40%","indices.breaker.fielddata.overhead": 1.03}}
3.2 Request Circuit Breaker
3.2.1 原理
Request Circuit Breaker 会对请求过程中的临时数据结构进行评估。例如执行一些复杂的聚合或脚本操作时,需要构建大量临时数据结构来完成查询和计算。
当预估的内存消耗超过设定值时,ES 会提前抛出 CircuitBreakingException。
3.2.2 相关配置
indices.breaker.request.limit:针对请求临时数据的内存上限,默认值一般为 JVM 堆内存的 60%(如 “60%”)。
indices.breaker.request.overhead:预估开销因子,默认值为 1。
示例:
PUT _cluster/settings{"persistent": {"indices.breaker.request.limit": "60%","indices.breaker.request.overhead": 1}}
3.3 In-flight Requests Breaker
3.3.1 原理
In-flight Requests Breaker 针对 ES 节点之间的网络通信过程进行熔断。当节点之间传输大批量数据或有大量在途请求时,也可能导致内存开销累积。
它限制当前还未完成的网络请求所占用的内存,一般很少需要单独修改。
3.3.2 相关配置
network.breaker.inflight_requests.limit:在途请求最大内存占用限制。
network.breaker.inflight_requests.overhead:在途请求内存预估值的乘数。
3.4 Parent Circuit Breaker(父熔断器)
3.4.1 原理
Parent Circuit Breaker 是一个全局熔断器,会对其他子熔断器的内存使用做总量控制。当整体内存使用率接近设置的阈值时,就会触发熔断。
3.4.2 相关配置
indices.breaker.total.limit:父熔断器内存使用限制,默认值为 95%(“95%”)。
注意:如果是ES6.X版本,该参数的默认值为70%
indices.breaker.total.use_real_memory:是否使用真实内存使用量判断,默认为 true(ES 7.x+)。
示例:
PUT _cluster/settings{"persistent": {"indices.breaker.total.limit": "95%","indices.breaker.total.use_real_memory": "true"}}
熔断相关常见参数汇总
如何配置熔断器
通过 _cluster/settings 接口进行配置,示例:
PUT _cluster/settings{"persistent": {"indices.breaker.fielddata.limit": "50%","indices.breaker.request.limit": "70%"}}
如何监控和排查熔断
6.1 使用 _cluster/stats 查看
GET _cluster/stats
可查看 breakers 中的统计信息,如 limit_size_in_bytes、estimated_size_in_bytes、tripped 次数等。
6.2 查看节点日志
熔断异常通常会在 elasticsearch.log 里以 CircuitBreakingException 的形式出现。如果发现大量熔断日志,需要排查是否有不合理的聚合或查询导致内存过高。
常见问题与实践建议
1) 熔断过于频繁?
优化查询、简化聚合、调整映射结构;或适度提升熔断阈值,但需防止 OOM。
2) 提高 JVM 堆内存能否解决问题?
能缓解但非根本之道,大堆会增加 GC 压力。
3) 升级到 ES 7.x 后熔断更多?
因 7.x 默认使用真实内存统计,更贴近实际使用量。
4) 使用 Doc Values 替代 Field Data:
对需要聚合、排序的字段使用 keyword + doc_values,减少 Field Data 占用。
5) 监控和报警:
通过外部监控(Grafana、Elastic Stack)观察 JVM 堆使用量与熔断次数,及时排查问题。
总结
熔断机制是保障 ES 集群稳定性的重要“安全阀”。
包括 Field Data、Request、In-flight Requests、Parent 等多类熔断器,覆盖不同内存分配场景。
通过合理设置 limit、overhead、use_real_memory 等参数,可以避免 OOM 等严重故障。
建议搭配查询/映射优化、日常监控与报警,实现性能和稳定性的平衡。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
