




阿里云Elasticsearch提供低成本、灵活的分析和搜索服务,很大程度降低了用户的使用成本和运维成本。在此基础上,由于缺乏数据场景的支持,用户仍旧需要花很大的精力去解决数据场景的痛点问题,比如:
海量数据源如何对接
复杂的数据计算和处理逻辑
全量数据导入影响在线查询
海量数据导入越来越慢
全量/实时数据无损切换
为了帮助用户解决这些痛点问题,阿里云Elasticsearch离线平台应运而生 。
Elasticsearch离线平台化的演进

值得一提的是,在调研完用户痛点后, 我们启动了ElasticBuild。它是基于Blink的离线索引构建,对标Ha3的BuildService系统,我们仍在不断地优化性能,最终实现真正的在离线分离。
与此同时,我们还和搜索离线组件平台团队展开了深度合作,共同打造离线产品化。
Elasticsearch离线平台系统架构

上图描述了离线平台系统架构,其中部分组件的简介如下:
Elastichub:搜索场景下的离线计算产品ElasticHub
Dolphin:云上通用管控, 集成了组件库Searchflow(借鉴Beam),可对接各种服务,包括Bahamut,Maat,Elasticsearch等,串联在线和离线
Bahamut:执行引擎,是搜索离线组件平台的核心,负责离线任务的创建、调度、管理等各种功能
Blink:实时计算引擎Flink的阿里内部版本,在大规模分布式、SQL、TableAPI、Batch上做了大量的优化和重构。离线平台的所有计算任务都是Blink job,包括stream和batch
ElasticBuild:Elasticsearch的"BuildService",后面会做详细介绍
在离线平台系统架构中,离线管控是不可或缺的重要部分,下面我们来看看离线管控是如何串联起复杂的离线流程。
离线管控流程
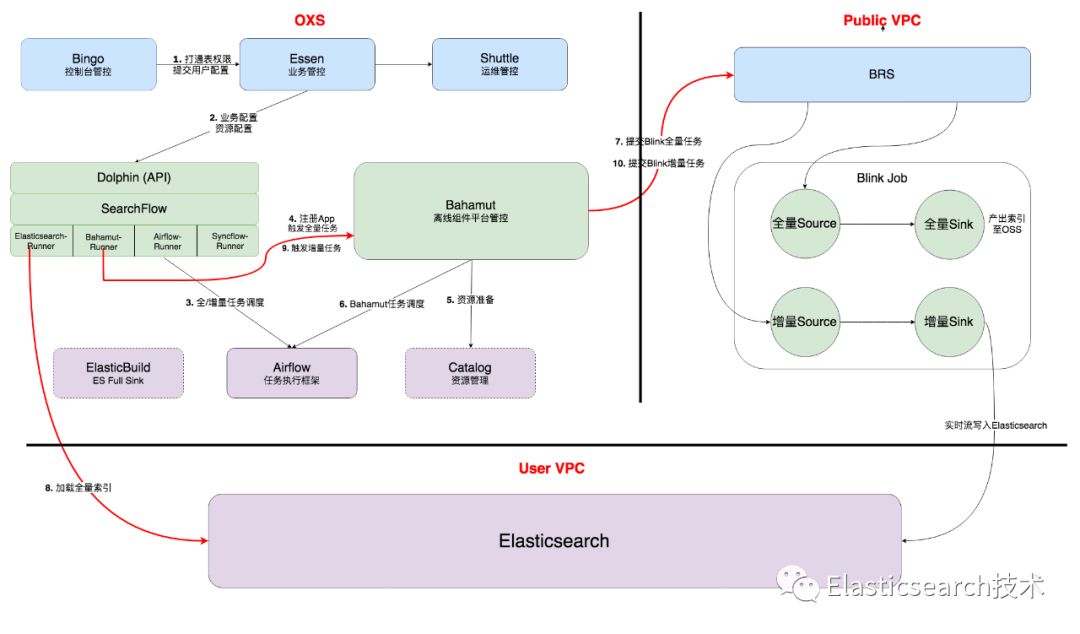
从上图中可以很清晰的看到离线管控Dolphin和Bahamut是如何配合串联起离线全量/增量切换流程的,而画虚线的ElasticBuild又在其中扮演一个的角色呢 ?
ElasticBuild简介
ElasticBuild是Elasticsearch的"BuildService"。
ElasticBuild主要解决离线全量的性能问题,做到在离线分离。它是基于实时计算引擎Blink的离线索引构建,我们针对Elasticsearch内核进行了深入优化,使得全量性能相比于在线得到了极大的提升。
下面我们来看看在数据写入场景所做的一些优化 。
Elasticsearch数据场景深入优化解密
硬件方向
HDFS Directory - Elasticsearch支持读写HDFS, Block Cache优化使其拥有良好的读写性能, 高可用和稳定性得到保障
软件方向
系统架构
规模弹性:当Shard数固定后,离线集群缺乏了弹性扩缩容能力
优化:将Shard数据进一步拆分, 达到并发构建, 随时扩缩集群规模的能力,速度随资源可扩展
Elasticsearch内核级别
Translog:Failover需要通过Translog回追数据, 增加了大量IO消耗
优化:利用Blink checkpoints机制替代Translog
索引合并 :索引合并重复的IO消耗巨大
优化:通过内存索引合并可以减少合并索引过程的重复IO读写
下面会针对两个比较重要的优化做详细介绍
/ NRT Cache实现内存索引合并 /
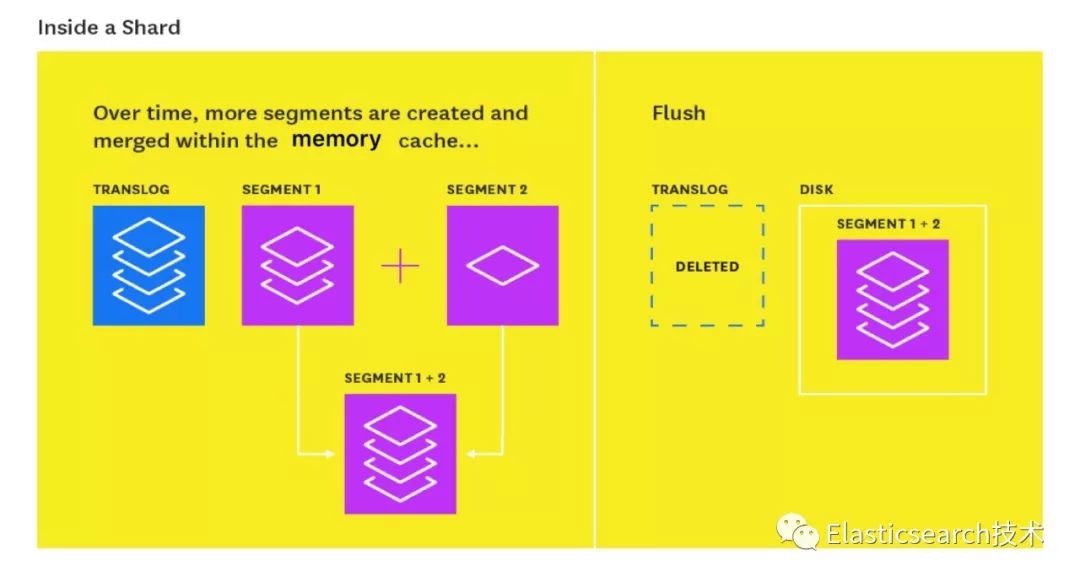
众所周知, 索引合并是Elasticsearch数据写入过程中的的重大开销。Segment写入磁盘后,又会被反复读到内存中合并,接着又写入磁盘。这个过程会有大量重复IO开销。
因此,我们将这个索引合并过程放在内存中 。
如图,多个segemnt会在内存中达到一定大小后,才会Flush到磁盘,从而避免了大量重复IO开销。
/ Blink Checkpoints取代Translog /
为了避免Translog带来的IO开销,我们移除了Translog。
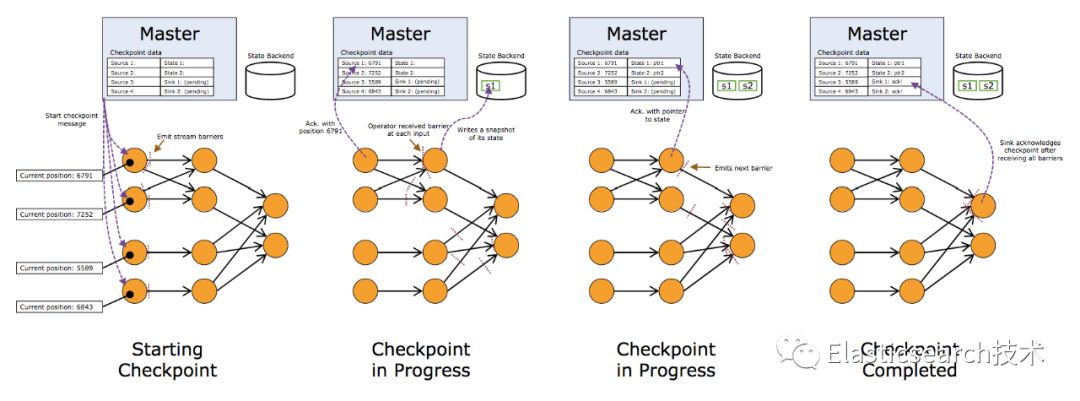
Blink Checkpoints机制简单来说就是 每隔一段时间会对数据做一次快照,快照里包含state信息以及数据消费位点, 并保存快照至HDFS,当出现Failover的时候,将还原快照,快照之后的数据会被重新消费,来保证数据的完整性。
我们基于Blink Checkpoints的Failover机制具备以下优点:
秒级Failover恢复
Exactly Once保证数据准确
去除Translog后降低了近一倍的IO开销
详细过程如下图所示:
总结与展望
阿里云Elasticsearch离线平台致力于解决搜索场景下海量数据批次/实时计算和索引构建问题, 基于实时计算引擎Blink提供高可用、高性能的数据处理能力。
END
