





点击蓝字关注我们
在开发数据库解决方案架构时,仔细考虑未来功能的各个方面及相应的业务需求非常重要,以避免不必要的复杂性和费用,同时确保满足所有业务要求。这在设计具有高可用性的数据库系统时尤为重要。在信息技术领域,高可用性通常通过提供关键组件的冗余来实现,以实现架构能够在不产生过多成本的情况下提供必要的弹性,这些组件希望只有在极少数情况下才会被使用。
什么是高可用性?
高可用性(HA)指的是系统在组件故障时保持运行和可访问的能力。在数据库的上下文中,这意味着要有策略来维持在计划维护和意外停机期间的数据访问。
两个指标通常用于定义数据库解决方案的可用性水平:
恢复时间目标(RTO)确定数据库系统可以离线的时间。这是将数据库恢复到运行状态所需的时间。
恢复点目标(RPO)确定相对于故障时刻,恢复的数据库快照可以回溯到多远的时间点。这是在恢复过程中允许丢失的故障前的事务变更量。RPO 为零意味着在应用程序认为已提交的事务中,绝对不能有任何丢失。
每向零靠近一步,无论是RTO还是RPO,都会增加解决方案架构的成本和复杂性,因此需要权衡这些目标与期望的业务结果。
PostgreSQL提供了内置机制来支持高可用性,这些机制构成了下文描述的替代方案的基础。
术语
集群
传统上,谈论PostgreSQL时,集群指的是由单个PostgreSQL进程管理的一个或多个数据库的集合。有时也称为PostgreSQL一个“实例”。
在高可用性的上下文中,集群表示一组冗余的PostgreSQL实例,以及任何相关组件(如故障转移管理器进程),这些组件共同构成了一个高可用性数据库解决方案。
为避免混淆,在本文中,我们将使用“集群”一词表示后一种含义,而使用“实例”来表示前一种概念。
节点
集群的一个节点是运行HA解决方案的一个或多个软件组件的单个服务器(物理或虚拟)。通常,一个节点会托管一个PostgreSQL实例,但并非总是如此:例如,一个解决方案可能包含一个专用节点来运行Barman备份软件。
位置
集群的节点可以部署在一个或多个地理位置:云提供商的可用区(AZs)或区域,或实际的数据中心(DCs)。地理分布的数据库集群提供了对区域基础设施故障和灾难的弹性,尽管它们的设置和维护稍微复杂一些。选择一个与你的总体灾难准备策略相匹配的设计。
见证者(仲裁者)
在具有偶数个数据库节点的集群中,见证者(也称为仲裁者)是必要的,以帮助在需要提升副本时实现法定人数。大多数故障转移集群解决方案需要多数节点来做出提升决定。如果集群中有偶数个节点,且一半节点失效,则无法在没有额外见证者的情况下达成多数。
在PostgreSQL中实现高可用性
时间点恢复
如果支持所需的 RTO 和 RPO 目标,从备份中进行数据库的时间点恢复(PITR)可以被视为数据库高可用性工具的一部分。这种方法需要从其备份副本中恢复失败的数据库,并重放一系列归档的 WAL 文件到所需的时间点,这使得恢复时间完全取决于数据库的大小和需要处理的 WAL 文件数量。恢复点由 WAL 文件归档的频率决定。如果数据库更改不频繁且应用程序可以容忍一些停机时间,PITR 可能是一个可接受的高可用性选项。
复制
PostgreSQL提供了两种内置的复制方法:物理复制和逻辑复制。EDB Postgres Distributed(PGD)通过允许多向(主-主)复制并添加企业级功能,扩展了原生PostgreSQL逻辑复制实现,使其适用于高可用性应用程序。
PostgreSQL的复制默认是异步的,这意味着在主节点故障之前,无法保证副本已接收或重放了主节点的所有事务。但是,你可以配置不同级别的同步复制,在这种情况下,只有在所有或至少部分副本确认已接收相应数据后,事务才被视为完成。同步复制提供了更低的RPO,通常接近于零,但代价是降低了数据库事务吞吐量。
每种复制选项都有其优缺点,使其适用于不同的用例。
1.物理复制
工作原理:
物理复制涉及将主服务器的整个事务日志(WAL)记录的更改复制到副本服务器。由于PostgreSQL实例中的所有数据库共享相同的WAL文件,因此此复制方法会移动所有数据库的数据。
物理复制可以通过两种方法实现,这两种方法在支持的RPO上有所不同。
日志传送:主服务器定期将WAL文件存档到共享位置,副本在该位置检索这些文件并重放其中的事务。
流复制:副本始终连接到主服务器,主服务器通过这些连接在相应事务提交后立即发送WAL记录。
优点:
简单设置:配置物理复制所需的步骤较少。
复制数据库架构:不仅复制数据更改,还复制表结构和其他数据库对象的修改。
高性能:在某些情况下,它可能比逻辑复制更快、更高效。
低开销:主服务器上需要的处理最少。
缺点:
灵活性有限:不允许在复制过程中过滤或转换数据。
版本兼容性:要求主服务器和副本服务器上的PostgreSQL主版本相同。
备用服务器:主要用于高可用性和灾难恢复。允许在副本上执行只读查询。
2.逻辑复制
工作原理:
逻辑复制涉及捕获特定表或数据库的逻辑更改(插入、更新、删除),并将其作为一系列数据更改指令发送到副本服务器。
优点:
灵活性:允许在复制期间过滤、转换和将数据路由到多个副本。
版本兼容性:可以在不同的PostgreSQL主版本之间复制数据。
读写副本:允许在副本服务器上进行读写操作。
缺点:
更高的开销:主服务器上需要更多的处理。
潜在的数据冲突:副本上的更新可能导致数据分歧或冲突更改。
不复制架构更改:表结构更改不会被复制,必须手动维护。架构偏差可能会破坏复制。
不适合HA:使用原生的PostgreSQL逻辑复制实现稳健的高可用性架构并不实用。
EDB Postgres Distributed
工作原理:
EDB Postgres Distributed(PGD)改进了内置的逻辑复制,允许多向复制、添加DDL复制、数据冲突解决、改进的一致性控制和其他功能。
优点:
架构更改:DDL命令被复制,确保所有副本上的表结构一致。
冲突避免和解决:允许在所有副本上安全地并发更新。
数据一致性:在选定的副本集上提供更好的数据一致性的灵活性。
使用场景:
1.物理复制:
高可用性设置
灾难恢复
负载均衡的只读副本
2.逻辑复制:
数据仓库和分析
跨多个区域的数据分发
测试和开发环境
与其他系统的数据集成
EDB Postgres Distributed结合了上述两种方法的优点,提供了物理复制的稳健性和可靠性,同时提供了逻辑复制的灵活性。
每种选项都允许您实现特定的RTO和RPO目标;下图显示了它们在这些领域的相对能力。
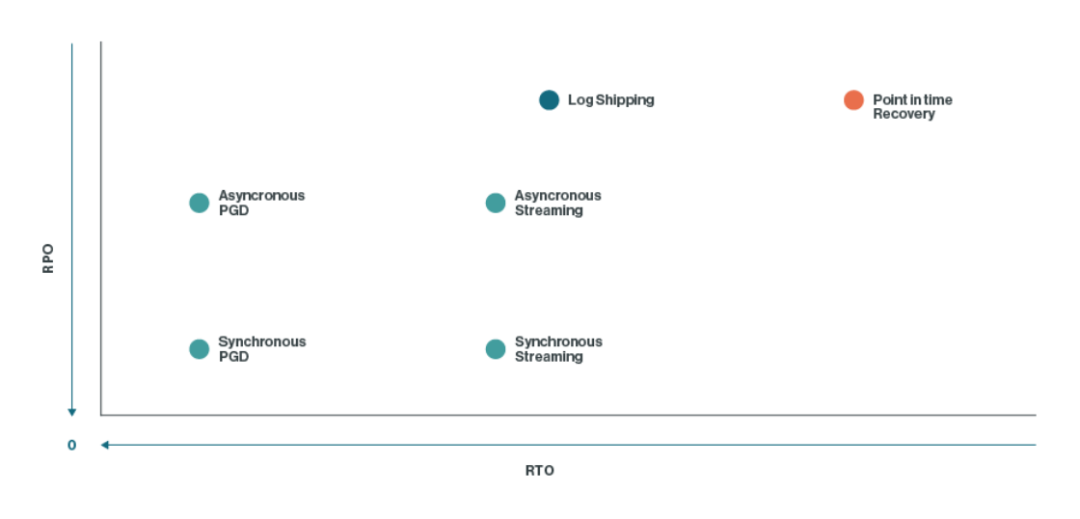
故障转移集群
对于关键应用程序,故障转移集群提供了实现高可用性的全面解决方案。可以使用EDB Failover Manager(EFM)、Patroni或repmgr等工具与物理复制一起,在主服务器故障时自动管理备用服务器的提升。这些工具简化了集群管理,并减少了故障转移过程中的复杂性。
EDB Postgres Distributed将故障转移管理作为其基本功能的一部分实现,无需设置额外工具即可自动化故障转移。
负载均衡
负载均衡帮助在多个服务器之间分发数据库请求。这不仅提高了性能,还确保了在一个服务器关闭时,其他服务器可以处理负载。可以配置HAProxy等工具来高效管理连接,特别是与故障转移管理解决方案配合使用时。
备份和恢复
定期备份是高可用性的重要方面。PostgreSQL支持各种备份方法,包括物理和逻辑备份,以及文件系统或存储设备级别的快照。将这些与时间点恢复(PITR)功能结合使用,可以在故障和应用程序或用户错误的情况下将数据库恢复到特定状态。Barman和pgBackRest等工具有助于管理恢复对象(数据库和WAL文件),并简化备份和恢复任务。
连接池化
PgBouncer和Pgpool-II等这样的连接池有助于在高负载期间通过重用现有数据库连接来维持数据库性能,并在故障转移后将应用程序连接重定向到新的主服务器。这可以防止数据库被新的连接请求淹没,并提高弹性。
实现高可用性的最佳实践
监控和警报:定期监控数据库性能,并设置警报以应对任何问题。像Postgres Enterprise Manager、Prometheus或Grafana等工具可以帮助跟踪重要指标,提供有关数据库健康状况的洞察,并在出现不利条件下主动发出通知。
测试故障转移过程:定期测试故障转移过程,确保其按预期工作。模拟故障转移场景可以帮助识别高可用性策略中的薄弱环节。
文档:保留高可用性配置和标准流程的清晰文档。这可以简化故障排除,并在故障需要手动干预时提高响应时间。
示例架构模式
由于可用于实现PostgreSQL高可用性解决方案的不同软件组件数量众多,以及业务需求和其他外部因素的多样性,本文无法详尽描述所有可能的架构选项。在此只是提供了一些示例解决方案,希望能在对您自己的研究和规划中有所帮助。
每种架构模式都可以使用PostgreSQL物理复制或EDB Postgres Distributed实现;选择底层技术受某些软件产品中某些功能的可用性影响,但也受非技术标准(如成本考虑和复杂性容忍度)影响。
我们根据其基本布局(包括部署位置的数量和集群节点的数量)来描述这些架构模式。
一对三
此架构仅包含一个位置,部署了三个集群节点,如下图所示。
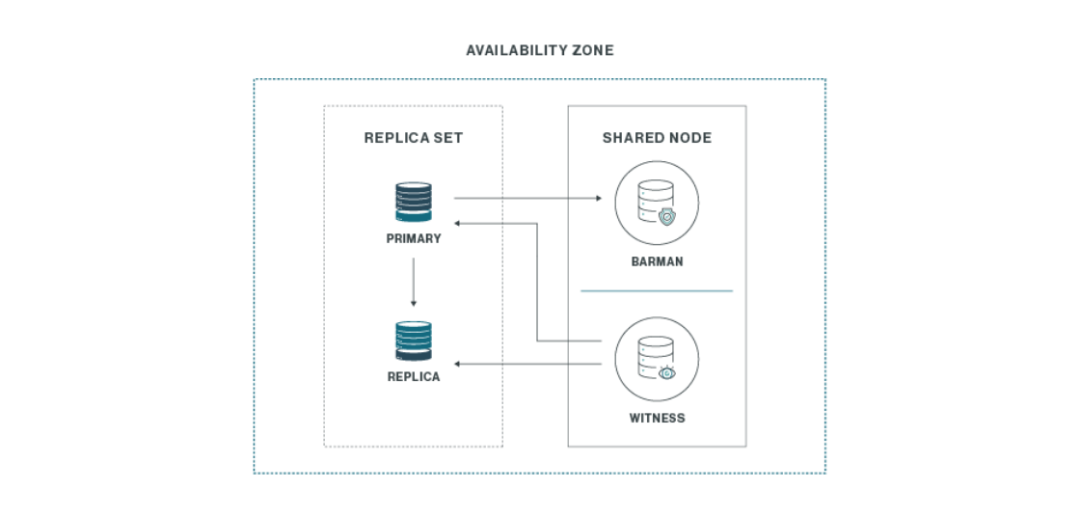
在这个特定示例中,集群只有两个数据库节点:主节点及其物理流副本。第三个节点由两个组件共享:
故障转移管理软件,在主节点故障时充当见证者或仲裁者,自动提升副本。
Barman备份和恢复软件。
这是最经济的高可用性架构,仅包含两个可能需要付费许可证的组件(两个数据库服务器),占用空间最小。它在其位置内保护系统免受单个数据节点故障。
然而,此架构不能保护您免受完全位置故障,特别是如果备份副本未存储在不同位置。
一对三加一
此模式通过为灾难恢复目的添加另一个位置,扩展了上述架构,如下所示。
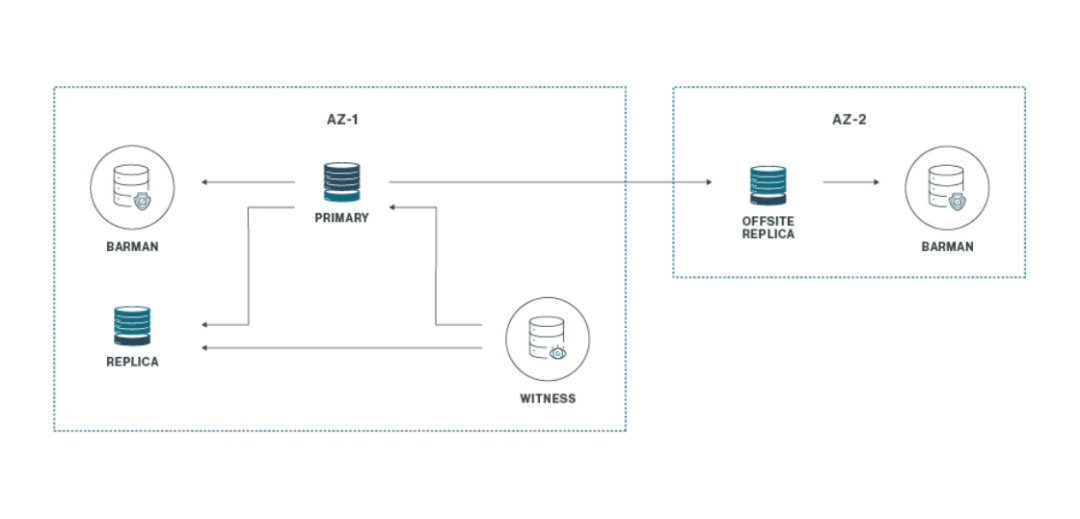
在此配置中,集群可以承受其主位置的丢失,尽管由于缺乏法定人数,无法自动提升离线副本。需要手动干预来提升副本,并可能将幸存位置扩展为完整的一对三配置。
两对三加一
此EDB Postgres Distributed部署示例提供了最终的高可用性和灾难恢复能力。它不仅为主位置的单个节点故障提供了弹性,还允许在整个主位置丢失时进行完全自动、几乎即时的灾难恢复。
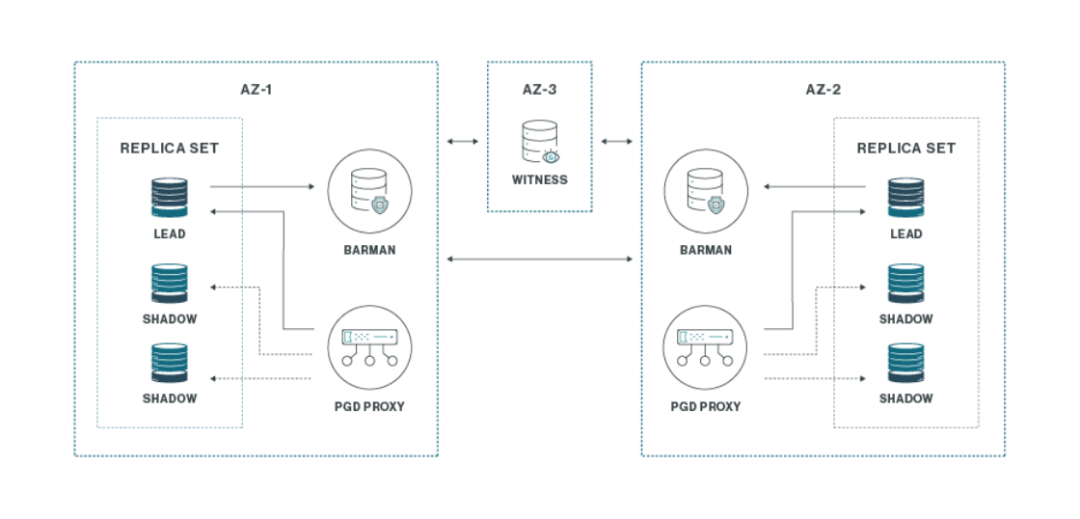
有关 EDB Postgres Distributed 三种示例架构详细配置,可以在本公众号往期文章里查看。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
