




一、引出问题
在 Elasticsearch 中,我们经常使用 _count 和 _stats API来获取索引的统计信息。
但是,当使用 _count 和 _stats 这两个API时,返回的结果可能会有显著差异,尤其是在处理含有nested字段的文档时。
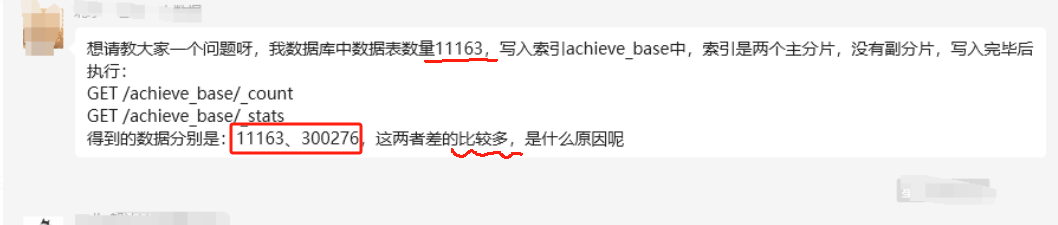
例如,执行以下查询时,返回的结果分别为:
GET achieve_base/_count 返回 11163
GET achieve_base/_stats 返回 300276
——来自死磕 Elasticsearch 星球微信群
可以看到,_stats 返回的文档数量远大于_count的结果,产生了较大的差异。

那么,究竟是什么原因导致了这种差异呢?
二、分析问题
Count API与 Stats API 的区别:
根据 Elasticsearch 官方文档,_count和_stats API分别具有不同的功能和统计粒度:
1. _count API
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-count.html
用于查询索引中匹配给定查询的文档数量。
默认情况下,_count 统计的是文档数,而不区分文档的类型。
它对文档的计数是按照文档本身进行的,不会区分是否包含 nested字段。
GET <target>/_count
2. _stats API
用于获取有关一个或多个索引的统计信息,包括存储大小、文档数量、字段的存储统计等。
它统计的是 Lucene
级别的文档数,包括索引中的所有原始文档和嵌套字段所产生的文档数量。
通过 level
参数可以控制统计的粒度,primaries
返回的是主分片的统计,total
则是主分片和副本分片的统计。
默认返回的是索引级别的统计信息。
GET <target>/_stats
需要注意的是,_stats API 默认统计的是所有 Lucene
文档 ,包括由nested
字段生成的多个Lucene
文档。
三、nested字段对统计结果的影响
当使用nested
字段时,每个nested
数组的元素会被视为一个独立的文档来存储。
这意味着一个文档中包含多个nested元素时,Elasticsearch会为每个nested
元素生成一个Lucene
文档,这些文档会被计入到_stats
API的统计中。
例如,在以下示例中,文档包含了一个nested_field
,其中包含多个嵌套文档:
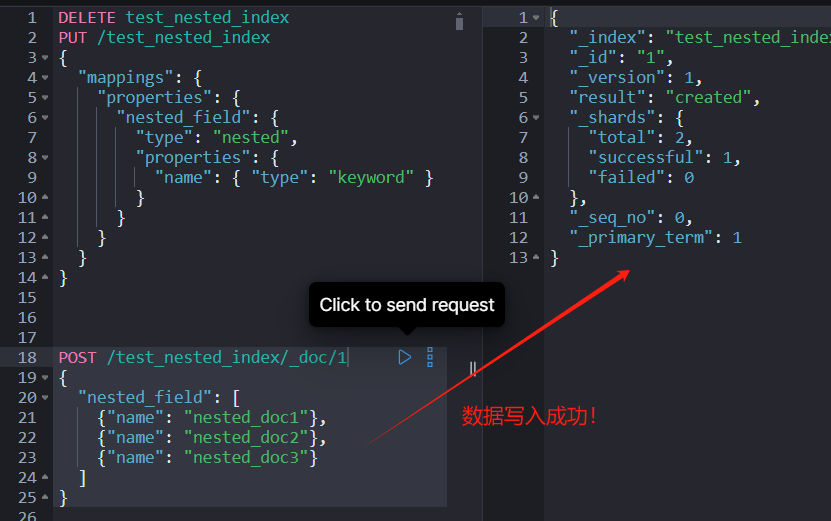
DELETE test_nested_index
PUT test_nested_index
{
"mappings": {
"properties": {
"nested_field": {
"type": "nested",
"properties": {
"name": { "type": "keyword" }
}
}
}
}
}
POST test_nested_index/_doc/1
{
"nested_field": [
{"name": "nested_doc1"},
{"name": "nested_doc2"},
{"name": "nested_doc3"}
]
}
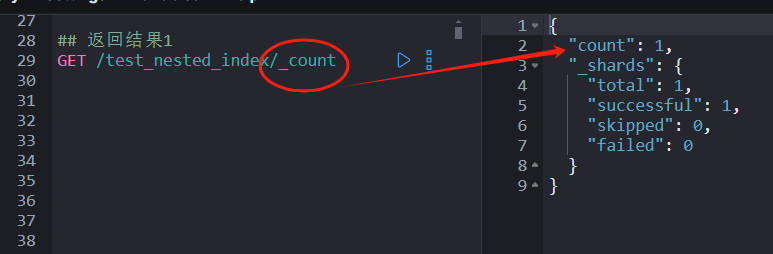
## 返回结果1
GET test_nested_index/_count
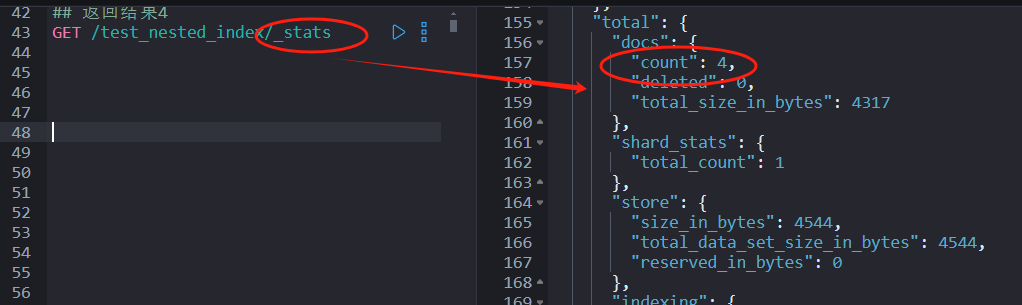
## 返回结果4
GET test_nested_index/_stats
GET test_nested_index/_search
执行GET test_nested_index/_count 返回文档数:1,如下图所示。
而执行 GET test_nested_index/_stats 返回文档数:4。
这个差异就是因为nested字段的每个元素都被存储为独立的Lucene文档(示意图如下图所示)。
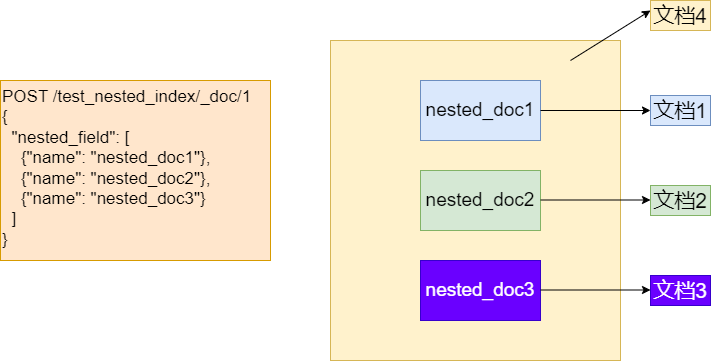
非严谨的示意图
继续写入更多数据后:
POST test_nested_index/_bulk
{"index":{"_id":"1"}}
{"nested_field":[{"name":"a1"},{"name":"a2"},{"name":"a3"},{"name":"a4"},{"name":"a5"},{"name":"a6"},{"name":"a7"},{"name":"a8"},{"name":"a9"},{"name":"a10"},{"name":"a11"},{"name":"a12"},{"name":"a13"},{"name":"a14"},{"name":"a15"},{"name":"a16"},{"name":"a17"},{"name":"a18"},{"name":"a19"},{"name":"a20"},{"name":"a21"},{"name":"a22"},{"name":"a23"},{"name":"a24"},{"name":"a25"},{"name":"a26"},{"name":"a27"}]}
{"index":{"_id":"2"}}
{"nested_field":[{"name":"b1"},{"name":"b2"},{"name":"b3"},{"name":"b4"},{"name":"b5"},{"name":"b6"},{"name":"b7"},{"name":"b8"},{"name":"b9"},{"name":"b10"},{"name":"b11"},{"name":"b12"},{"name":"b13"},{"name":"b14"},{"name":"b15"},{"name":"b16"},{"name":"b17"},{"name":"b18"},{"name":"b19"},{"name":"b20"},{"name":"b21"},{"name":"b22"},{"name":"b23"},{"name":"b24"},{"name":"b25"},{"name":"b26"},{"name":"b27"}]}
## 返回结果2
GET /test_nested_index/_count
## 返回结果56
GET /test_nested_index/_stats
GET /test_nested_index/_search
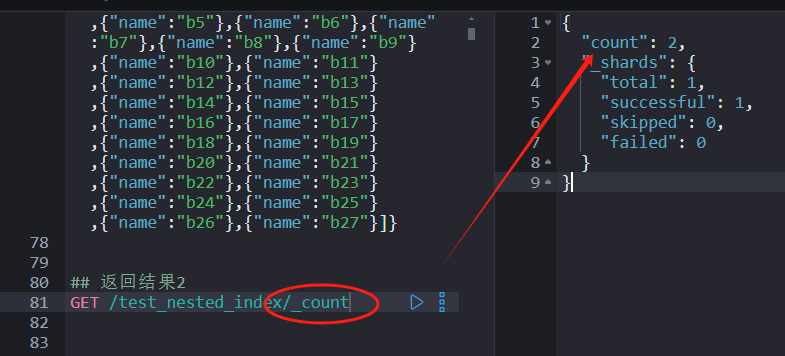
下图执行结果为:27*2+2=56。
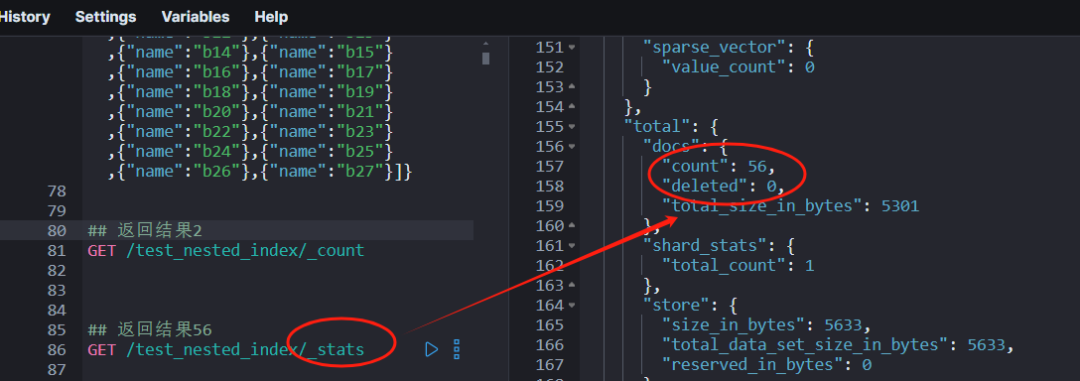
四、解决问题
1. 刷新索引
有时候,数据还没有完全刷新到磁盘或者Lucene索引中,可能会导致_count和_stats之间的差异。
可以通过执行refresh操作来刷新索引,确保统计数据是最新的。
POST /achieve_base/_refresh
然后重新执行GET /achieve_base/_count和GET /achieve_base/_stats,以确认刷新后的数据是否一致。
2. 重新理解nested字段的影响
如前所述,如果文档中使用了nested字段,我们需要理解_stats API返回的是Lucene级别的文档数量,这其中包括了nested字段生成的所有文档。
因此,_count返回的是原始文档的数量,而_stats则返回了原始文档及其nested元素所产生的Lucene文档数量。
3. 数据结构优化
如果nested字段的使用导致了文档数量的显著增加,可以考虑优化数据模型,例如使用flattened
类型,或者将嵌套数据存储为独立的文档,而不是在同一个文档中嵌套。
Elasticsearch 字段膨胀不要怕,Flattened 类型解千愁!
五、结论
在Elasticsearch中,_count 和 _stats 两个 API 的统计方式不同,导致它们返回的结果会存在差异。
_count统计的是原始文档数量,而_stats统计的是Lucene文档数量,包括由nested字段生成的文档。
理解这些区别,有助于我们更好地使用Elasticsearch,尤其是在处理复杂数据结构时。
Elasticsearch 大数据存储与检索系统化实战直播课
《一本书讲透 Elasticsearch》被清华、北大等多所知名高校图书馆收录
公司有系统 Elasticsearch 查询传入 10 万个字符的 Query,导致集群爆掉,怎么办?
干货 | Elasticsearch Nested 数组大小求解,一网打尽!
Elasticsearch 8.X 如何依据 Nested 嵌套类型的某个字段进行排序?
干货 | 拆解一个 Elasticsearch Nested 类型复杂查询问题
Elasticsearch Nested 选型,先看这一篇!

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
