




今天接着上周的内容继续学习ES,因为上次在谷歌云上安装ES和kibana以后,不能同时启动,所以这次就只能在本地重新安装一。ES和kibana安装过程很简单,这里就略过了。今天主要是学习下ES的基本概念和基本操作,更高级的操作以后有机会在补充吧。我下载和安装的都是最新版本,也就是6.4版本。
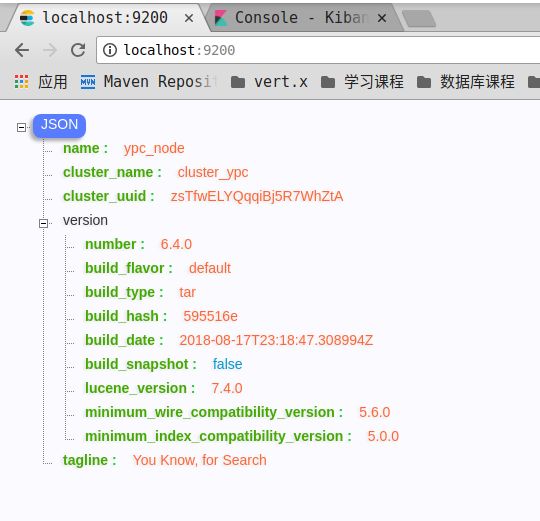
下载以后就是启动ES和kibana,我个人的学习习惯就是这样,不管什么技术先跑通再继续下一步操作。先启动ES,因为kibana是依赖ES的,当然如果没有ES,kibana自己也是可以启动的,只不过会有找不到ES实例的错误提示。启动完成后在浏览器分别输入:localhost:9200和localhost:5601就可以看到ES启动和kibana的启动信息了,见下图:
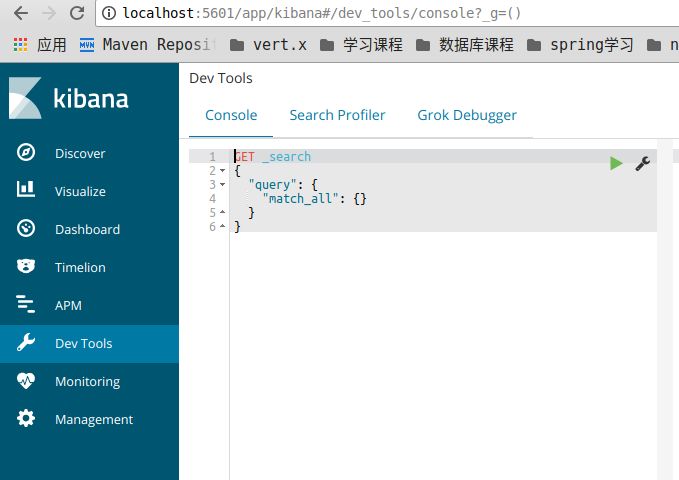
kibana的Dev Tools可以对ES进行操作的一个图形化界面,使用起来比使用命令行终端要更直观一点,也更方便一点。
在正式开始学习ES操作之前,先来熟悉一下ES的几个基本的概念。
cluster,也就是集群就是多个ES服务器节点组成的集合,这个很好理解。可以设置有多个集群,但是每个集群肯定需要一个名称,另外同一个环境集群名称是不能相同的。
node,节点指的就是单个的ES服务器,默认的情况下每一个节点都会有一个UUID,我们可以根据集群名称,把某个节点加入到指定的集群。
index,顾名思义就是索引,我们在查询的时候肯定是根据索引去查找数据的,索引的名称必须小写,另外就是索引必须唯一,也就是不能有相同名称的索引,当然创建索引的时候,如果这个索引已经存在,是无法创建的。还有就是在单一的集群环境下索引的数量是不受限制的,只要你愿意创建多少个索引都可以。
document,document是能够被索引的基本单元,也就是根据索引查询数据的时候,查询出来的就是document,它的数据格式是我们非常熟悉的json。
此外还有type,但是到6.0版本的时候已经被弃用了,所以这里也就不在介绍了。
Shards & Replicas,分片和副本,这两个的作用是非常重要的。单个索引可能存储数据过超过单个节点的硬件限制,或者可能太慢而无法单独从单个节点提供搜索请求。为了解决这个问题,ES提供了将索引细分为多个称为分片的功能。创建索引时,只需定义所需的分片数即可。每个分片本身都是一个功能齐全且独立的索引,并且分片可以托管到集群中的任何节点上。
分片之所以重要有两个原因:1、分片允许水平拆分/缩放存储的数据量;2、分片允许跨分片(可能在多个节点上)进行分布式和并行化操作,从而提高性能/吞吐量。
在可以随时发生故障的网络/云环境中使用故障转移机制是非常有用,并且也是推荐使用的。这样可以防止分片/节点以某种方式脱机或因任何原因消失。ES允许将索引分片的一个或多个副本制作成所谓的副本分片或简称副本。复制很重要有两个主要原因:1、它在分片/节点发生故障时提供高可用性。因此,副本分片永远不会在它从中复制的原始/主分片相同的节点上分配空间。也就是说,假如分片a是节点A上的索引的分片,那么分片a的副本是不允许分配到节点A上的。道理很简单,副本的目的就是提供高可用,如果你的节点A失败,那么分片a和它的副本数据都可能丢失,数据安全性是有问题的,也就不存在所谓的高可用了;2、因为搜索可以在所有副本上执行并行搜索,所以它允许扩展搜索量/吞吐量。
总的来说就是:一个索引可以拆分为多个分片,也可以复制零次(也就是没有副本)或多次。复制后,每个索引都将具有主分片(从中复制的原始分片)和副本分片(主分片的副本)。
默认情况下,ES中的每个索引都分配了5个主分片和1个副本,也就是说在你的群集中至少有两个节点,那么你的索引将包含5个主分片和5个副本分片(1个完整副本),总共是10个分片。
为了区分,我修改了cluster和node的名字,在命令行终端键入下面的命令:
./elasticsearch -Ecluster.name=cluster_ypc -Enode.name=ypc_node
然后重新在浏览器输入:localhost:9200,就会看到我们的cluter和node名称都已经修改成我自己定义的了
接下来就是对ES进行一些常用的操作了,今天主要学习的是CRUD。ES的操作很简单,它提供了很强大的REST API,接下来我先做一点简单的命令操作,前期都会通过命令行完成,等后面会使用kibana的Dev Tools进行操作:
启动ES的时候命令行显示了cluter的健康状态由红变成了黄,所以接下来先检查下cluter的健康状况,控制台键入下面的命令:
curl -X GET "localhost:9200/_cat/health?v"
注意,GET、PUT、DELETE等等这些REST API的操作必须要大写,还有就是curl可能需要自己安装。然后我们就看到控制台给出的响应信息。然后是查看节点的健康状态:
curl -X GET "localhost:9200/_cat/nodes?v"
我们看到cluster的状态信息是yellow。

简单说下几种状态值的意思,总共有三种状态值,分别是green yellow和red。yellow代表所有数据都可用,但尚未分配一些副本。green表示cluster所有状态都是好的,red表示某些数据因为某些原因无法使用。
接下来我们先查看下cluster的所有索引情况:
curl -X GET "localhost:9200/_cat/indices?v"
然后看到控制台显示内容为空,也就是目前ES的cluster下还没有索引:

那么现在我们先通过控制台创建一个索引:
curl -X PUT "localhost:9200/ypc_index"
然后在查看下所有的索引
curl -X GET "localhost:9200/_cat/indices?v"
这时候控制台显示下面的数据:

展示的数据表示索引的健康状态、索引名称、UUID以及主分片(primary shards)的数量5,以及副本(replica)的数量1。document数量是是0,也就是还没有数据。 另外索引健康状态之所以是yellow,那是因为我们只有一个节点,所以导致副本无法分配,还记得我们前面说过了副本不能在其主分片的节点上分配,所以状态就只能是yellow。
接下来我们向索引中添加一些数据,通过控制台输入下面的命令:
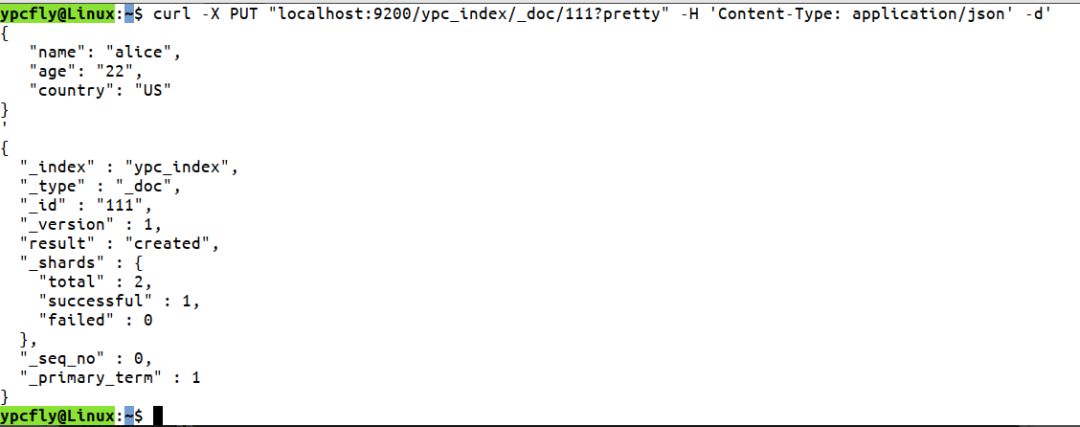
curl -X PUT "localhost:9200/ypc_index/_doc/111?pretty" -H 'Content-Type: application/json' -d'
{
"name": "alice",
"age": "22",
"country": "US"
}
'
ypc_index表示索引的名称,_doc表示数据类型,111表示索引的ID值,添加的数据类型是json,这个写法有点复杂,如果在kibana的话就不需要这么麻烦了。然后按下enter键,控制台会返回给一个相应信息,见下图:
我们根据索引的ID查询下我们索引的内容,控制台输入下面的命令:
curl -X GET "localhost:9200/ypc_index/_doc/111?pretty"
我们就看到控制台输出该索引的相关信息,_source返回的就是我们保存的json信息:
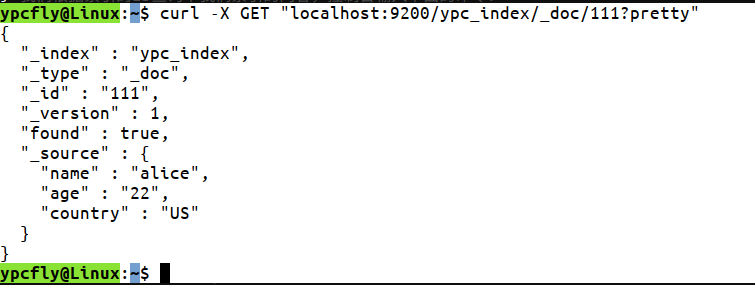
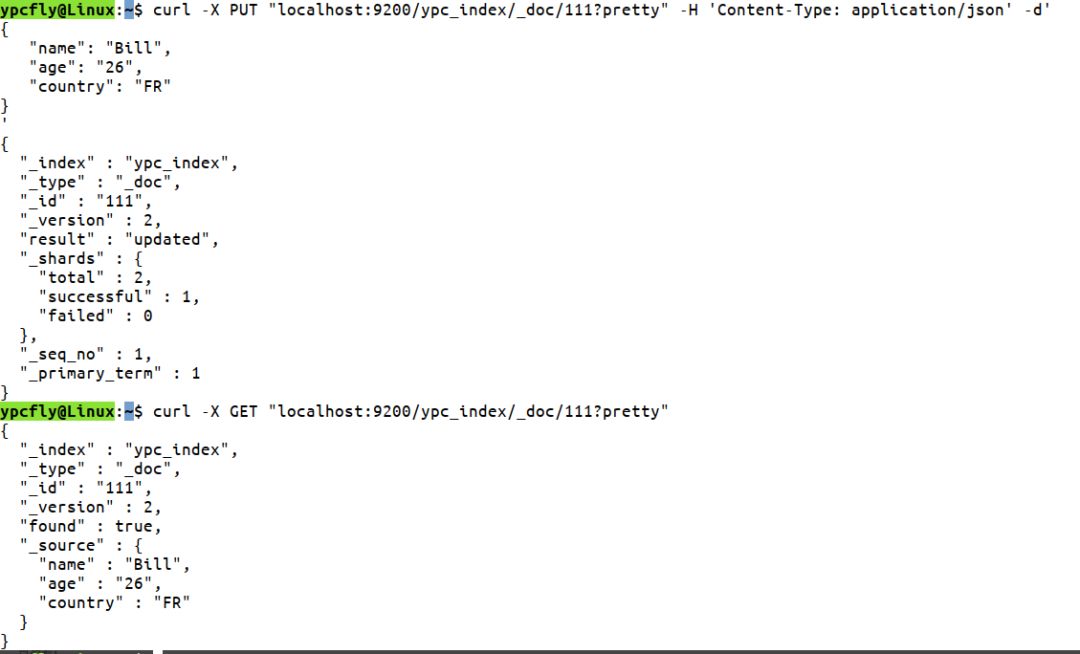
这里我们看到返回的版本号是1,result是created。接下来我们试着更新索引的内容,我们用新的内容覆盖刚才添加的信息,控制台输入:
curl -X PUT "localhost:9200/ypc_index/_doc/111?pretty" -H 'Content-Type: application/json' -d'
{
"name": "Bill",
"age": "26",
"country": "FR"
}
'
这时候我们看到控制台返回的信息中_version的值是2,并且result值显示的是update,而并不是最初的created:
最好看一下删除的操作,删除应该是最简单了,我再次新建一个索引
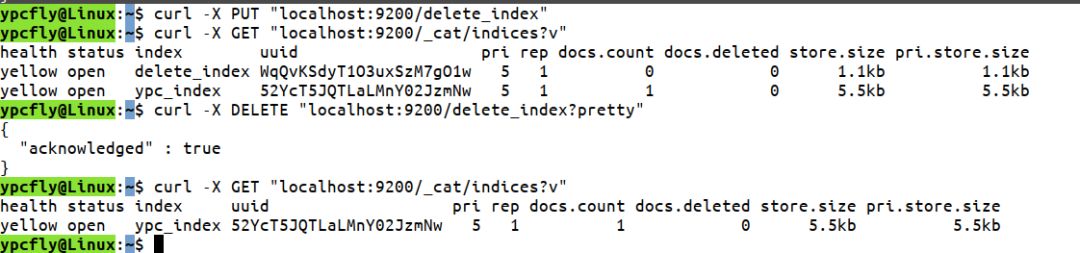
curl -X PUT "localhost:9200/delete_index"
curl -X GET "localhost:9200/_cat/indices?v"
然后在控制台输入删除索引的命令:
curl -X DELETE "localhost:9200/delete_index?pretty"
看下控制台的响应数据,acknowledged为true说明操作成功了:
最后说明一下就是很多命令里面都有个pretty这个词,它的作用是将json以一个格式化的形式展示数据。我们通过一个简单的例子看下就明白了,见下图:

两个相同的命令一个是有pretty的一个是无pretty的,有pretty的json数据展示更漂亮一点仅此而已,功能并没有什么影响。
关于ES的基本操作就先学到这里,因为ES提供的是REST API所以CRUD还是比较简单的,就是通过控制台进行操作稍微有点麻烦,以后的话就直接通过kibana来进行操作了。
由于时间的关系今天的学习就到这里了,关于更高级的知识下次继续学习。另外:今天原本的想法是ES使用谷歌云上的ES,kibana使用本地的,但是不知道为了,本地kibana就是连接不上谷歌云的ES,有时候真的不能想当然的以为某个东西很简单,还是需要实际的操作一下才行。
