




在 Elasticsearch 中,dense_vector
是一种专门用来存储和处理稠密向量(dense vectors)的字段类型。
它特别适合需要进行 k 近邻搜索(kNN) 的场景,比如推荐系统、图像搜索或自然语言处理中的语义相似性计算。

本文将带你从零开始了解 dense_vector
,包括它的定义、使用方式、索引选项以及一些实用技巧。
让我们一步步拆解这块内容,用通俗的语言把复杂的概念讲明白!
1、什么是 dense_vector?
简单来说,dense_vector
是一个字段类型,用来存储一组数字向量(比如 [0.5, 10, 6]
),这些向量通常是机器学习模型生成的特征表示。它不像普通的字段类型(比如 keyword
或 text
)那样支持聚合或排序,
而是专为 向量相似性搜索 设计。
在实际应用中,你可以用它来做 kNN 搜索,也就是找到与某个查询向量最相似的 k 个向量。
这种搜索在推荐系统或语义匹配中非常常见。
2、如何定义和使用 dense_vector?
2.1 基本定义
在 Elasticsearch 中,添加一个 dense_vector
字段很简单。你需要指定它的维度(dims
),也就是向量中数字的个数。比如下面这个例子:
PUT my-index
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 3// 向量有 3 个维度
},
"my_text": {
"type": "keyword"// 普通的文本字段
}
}
}
}
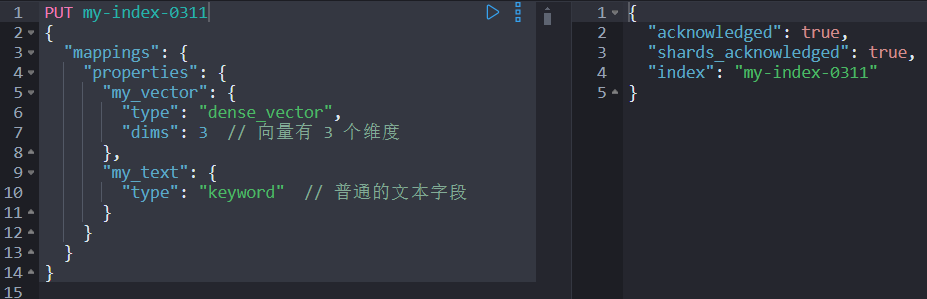
这里我们定义了一个索引 my-index
,
其中 my_vector
是dense_vector
类型,维度是 3。dims
是必须指定的,最大不能超过 4096(注意:8.10 版本之前最大值 2048,8.10版本之后最大值 4096)。
2.2 添加数据
定义好字段后,就可以往里面塞数据了。
每个文档的 my_vector
字段只能存一个向量,不能存多个。比如:
PUT my-index/_doc/1
{
"my_text": "text1",
"my_vector": [0.5, 10, 6]
}
PUT my-index/_doc/2
{
"my_text": "text2",
"my_vector": [-0.5, 10, 10]
}
注意,向量中的数字默认是浮点数(float
),而且长度必须和 dims
一致。
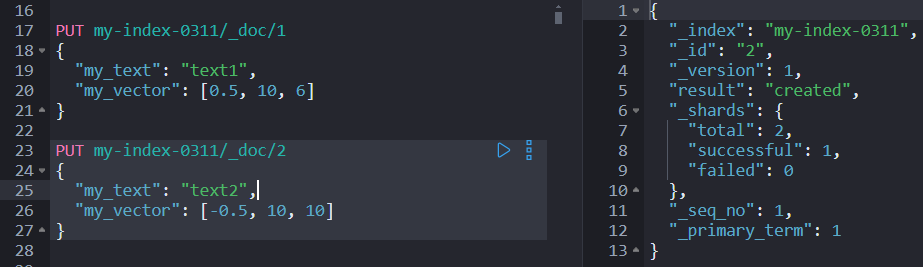
这里我们用了 3 个数字,正好匹配定义的维度。
3、kNN 搜索:让向量派上用场
dense_vector
的核心用途是 kNN 搜索,也就是找到与查询向量最相似的 k 个文档。
Elasticsearch 支持两种方式来实现:
暴力搜索(Brute-Force kNN)
用script_score
查询扫描所有文档,逐一计算相似度。这种方法简单,但数据量大时会很慢。索引加速(Approximate kNN)
通过给向量建立索引(默认启用),可以用专门的数据结构(比如 HNSW)加速搜索。索引后的向量可以通过knn
选项在搜索 API 中快速检索。
3.1 设置相似度
为了做 kNN 搜索,你需要告诉 Elasticsearch 如何衡量两个向量的相似度。
可以用 similarity
参数指定,默认是 cosine
(余弦相似度)。
比如:
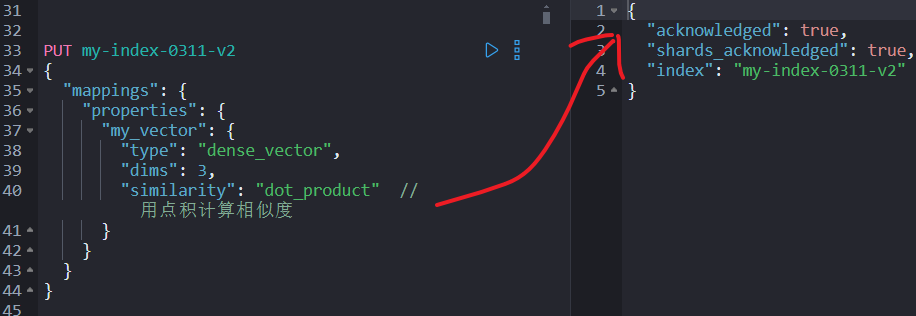
PUT my-index-2
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 3,
"similarity": "dot_product" // 用点积计算相似度
}
}
}
}
支持的相似度选项包括:
l2_norm
:欧几里得距离dot_product
:点积cosine
:余弦相似度max_inner_product
:最大内积
每种方法适用于不同的场景,具体选哪个取决于你的数据和需求。
3.2 相似度选项的区别与适用场景
如前所述,Elasticsearch 的 dense_vector
字段支持四种相似度计算方式:l2_norm
(欧几里得距离)、dot_product
(点积)、cosine
(余弦相似度)和 max_inner_product
(最大内积)。
每种方法在向量比较时有不同的数学基础和适用场景,选择哪种主要取决于你的数据特性(如是否归一化)和应用需求(如是否重视向量长度)。
下面通过一段话和一个表格来直观说明它们的区别与用途。
简单来说:
l2_norm
适合需要精确衡量空间距离的场景,比如地理位置匹配;
dot_product
适用于已归一化向量的高效余弦计算,或字节向量的高性能需求;
cosine
是语义相似性计算的首选,比如文本或图像特征匹配(所以,这个咱们用的多);
max_inner_product
则在向量长度有意义时表现更好,比如某些推荐系统。
相似度选项对比表
l2_norm | |||||
dot_product | floatbyte无要求 | ||||
cosine | |||||
max_inner_product |
希望这能帮你快速选出合适的相似度方法!如果有具体案例,欢迎讨论。
3.3 关闭索引
如果不需要快速 kNN 搜索,可以关闭索引功能,节省资源:
PUT my-index-2
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 3,
"index": false // 关闭索引
}
}
}
}
关闭索引后,只能用暴力搜索方式查询。建议咱们慎用!!
4、量化:内存和速度的平衡
索引向量虽然能加速搜索,但会占用不少内存。
Elasticsearch 提供了 量化(Quantization) 来压缩向量,减少内存占用。
支持三种量化策略:
int8
每个维度用 1 字节整数表示,内存减少 75%(4 倍压缩),精度略有损失。int4
每个维度用半个字节(4 位),内存减少 87%(8 倍压缩),精度损失更大。要求维度是偶数。bbq(实验功能)
每个维度压缩到 1 位,内存减少 96%(32 倍压缩),精度损失最大,要求维度大于 64。可以用过采样和重排序来弥补。
设置量化很简单,比如用 int8_hnsw
:
PUT my-byte-quantized-index
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"index_options": {
"type": "int8_hnsw"// int8 量化 + HNSW 算法
}
}
}
}
}
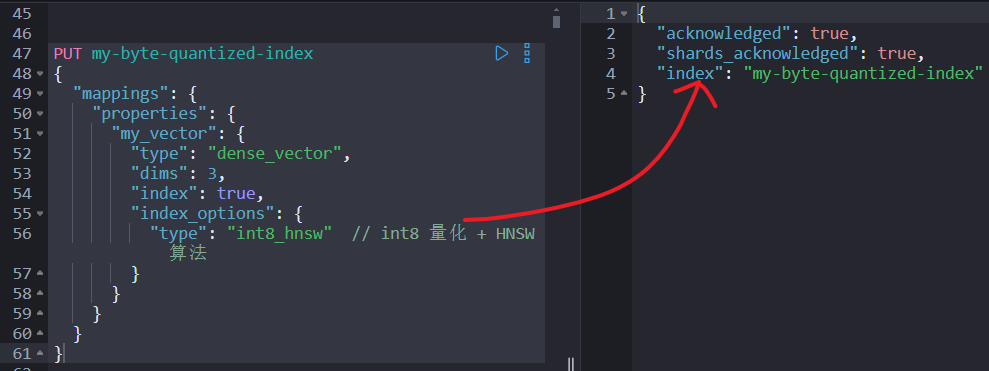
量化后的向量会牺牲一些准确性,但可以通过调整查询时的参数(比如过采样)来提高结果质量。
5、位向量(bit vectors):超高维场景的利器
除了浮点数,dense_vector
还支持 byte
和 bit
类型。
其中 bit
类型特别适合超高维向量,每个维度只用 1 位存储,极大节省空间。
5.1 定义位向量
PUT my-bit-vectors
{
"mappings": {
"properties": {
"my_vector": {
"type": "dense_vector",
"dims": 40, // 维度必须是 8 的倍数
"element_type": "bit"
}
}
}
}
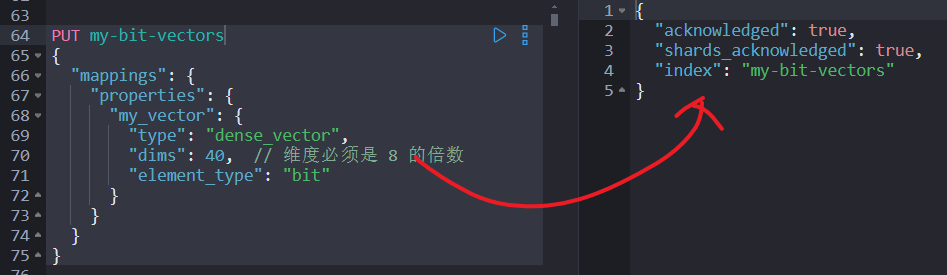
5.2 添加数据
可以用字节数组或十六进制字符串表示位向量:
POST my-bit-vectors/_bulk?refresh
{"index": {"_id": "1"}}
{"my_vector": [127, -127, 0, 1, 42]}
{"index": {"_id": "2"}}
{"my_vector": "8100012a7f"}
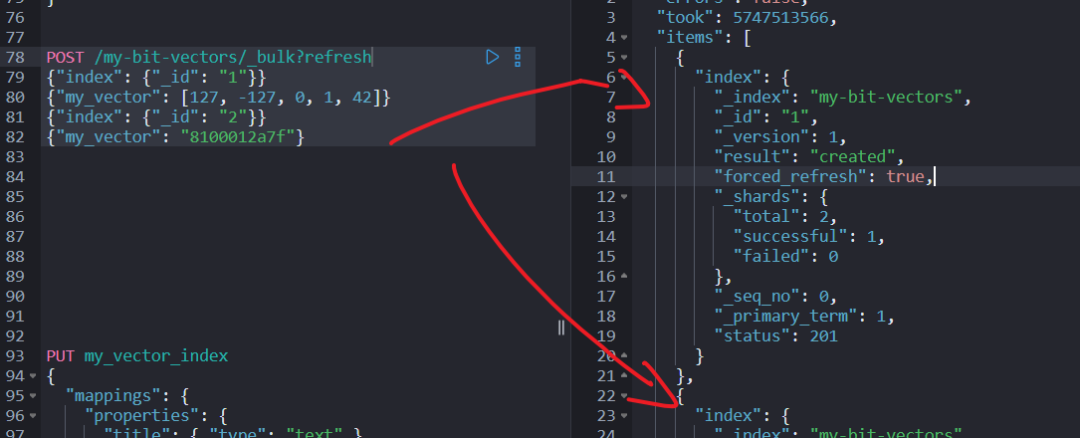
5.3 搜索位向量
用 knn
查询搜索相似向量:
POST my-bit-vectors/_search?filter_path=hits.hits
{
"query": {
"knn": {
"query_vector": [127, -127, 0, 1, 42],
"field": "my_vector"
}
}
}
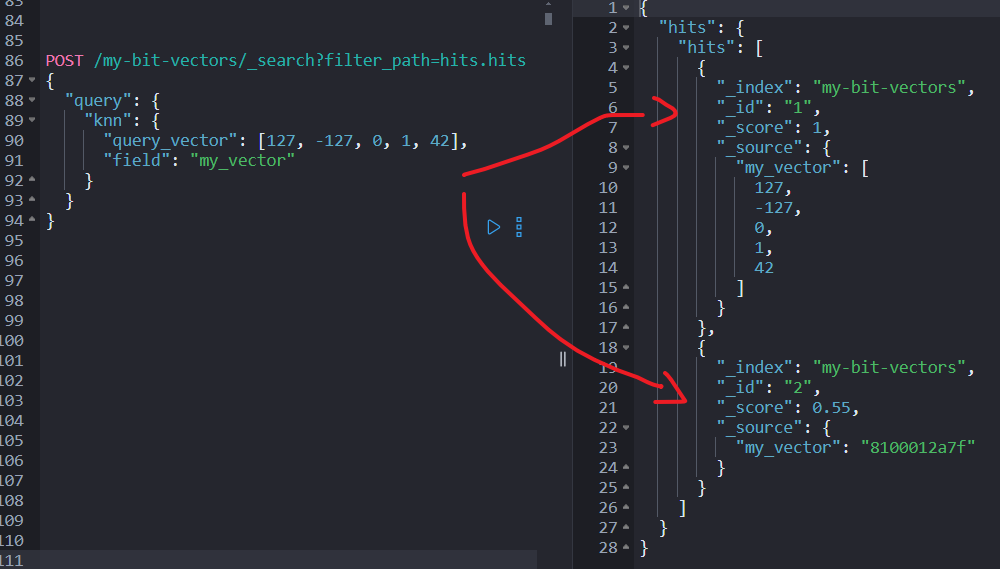
位向量的相似度用汉明距离(Hamming Distance)计算,分数越高表示越相似。
6、参数详解
dense_vector
支持以下几个关键参数:
element_type
:向量元素类型,默认float
,可选byte
或bit
。dims
:维度数,最大 4096。index
:是否启用索引,默认true
。similarity
:相似度计算方式,默认cosine
。index_options
:索引算法配置,比如:type
:算法类型(hnsw
,int8_hnsw
,flat
等)。m
:HNSW 算法中每个节点的邻居数,默认 16。ef_construction
:构建时的候选数,默认 100。
这些参数可以灵活调整,平衡准确性和性能。
7、更新字段类型
Elasticsearch 支持通过 Update Mapping API
更新 index_options
的 type
,比如从 flat
切换到 int4_hnsw
:
PUT my-index-000001/_mapping
{
"properties": {
"text_embedding": {
"type": "dense_vector",
"dims": 384,
"index_options": {
"type": "int4_hnsw"
}
}
}
}
注意,更新不会影响已索引的数据,新数据才会用新类型。想让所有数据生效,可以重新索引或强制合并。
8、总结
dense_vector
是 Elasticsearch 中处理向量数据的强大工具。
它支持灵活的定义、多种相似度计算方式,还能通过量化和索引优化性能。
不管是简单的暴力搜索,还是复杂的近似 kNN 搜索,甚至超高维的位向量场景,dense_vector
都能胜任。
希望这篇博客能帮你快速上手 dense_vector
!
如果有疑问,欢迎留言讨论。
9、参考链接
Elasticsearch 官方文档:Dense Vector Field Type https://www.elastic.co/guide/en/elasticsearch/reference/current/dense-vector.html k-Nearest Neighbor (kNN) Search https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html
基于 Qwen2.5-14B + Elasticsearch RAG 的大数据知识库智能问答系统 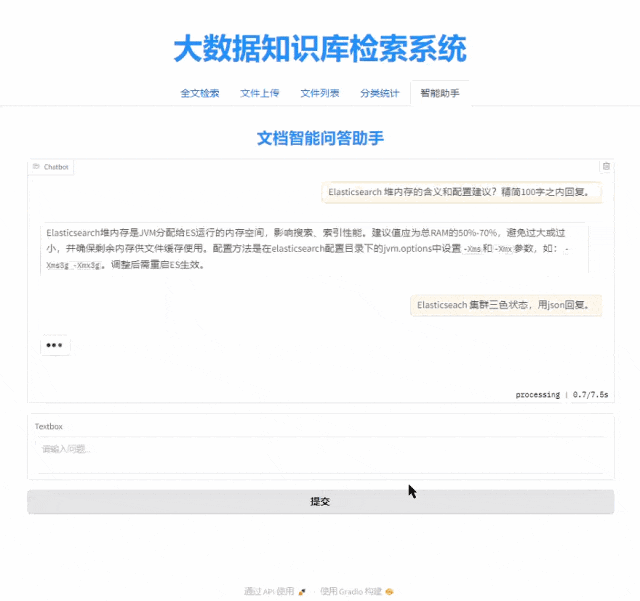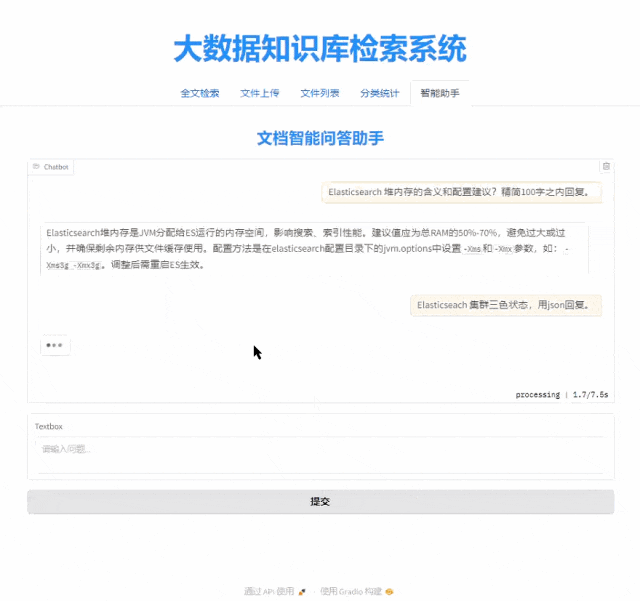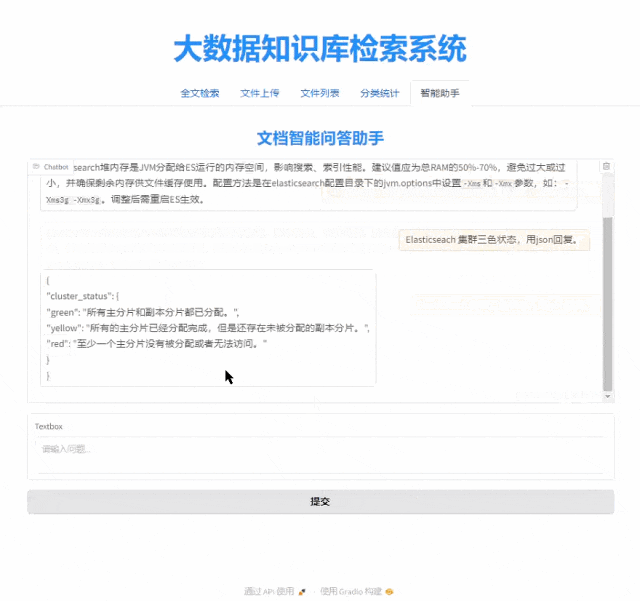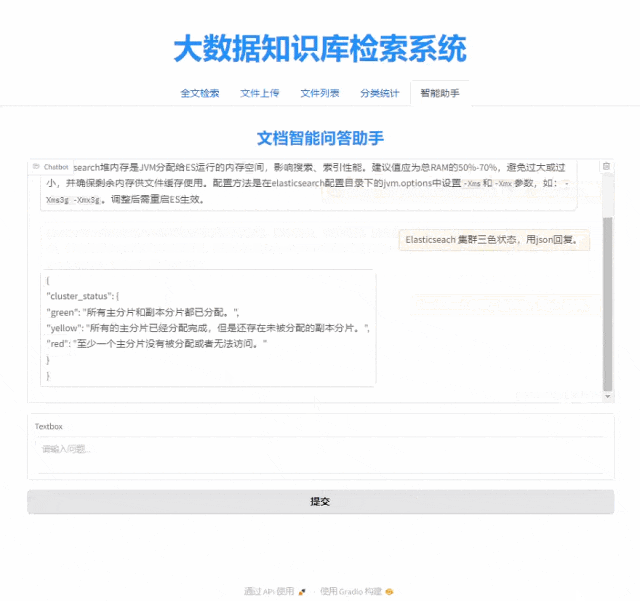
Elasticsearch 8.X “图搜图”实战 
Elasticsearch 8.X 向量检索和普通检索能否实现组合检索?如何实现? Elasticsearch:普通检索和向量检索的异同? 干货 | Elasticsearch 向量搜索的工程化实战 
更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
