




写在文章开头
之前的文章简单介绍了ES
中的核心概念,而本文将基于Linux
系统简单介绍ES
的安装和使用演示,希望对你有帮助。
Hi,我是 sharkChili ,是个不断在硬核技术上作死的技术人,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
详解ES环境搭建
ES下载安装
首先我们需要下载ES
压缩包,以本文为例,笔者使用的是7.12.0
版本的ES
对应下载指令如下,读者可按需修改完成下载:
curl -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.12.0-linux-x86_64.tar.gz
通过curl指令完成下载后,通过tar
指令进行解压:
tar -zxvf elasticsearch-7.12.0-linux-x86_64.tar.gz
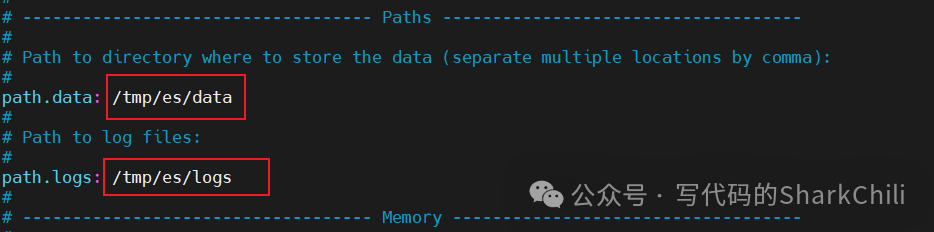
此时我们就可以开始ES的基本配置了,以笔者为例,为了更好的检测ES运行情况信息,笔者通过vim
指令修改了ES
数据存储和日志的目录,对应文件和路径如下,可以看到配置文件位于ES
根目录下的config
文件夹下:
vim config/elasticsearch.yml
对应的修改内容和配置如下所示:
完成配置后我们就可以进入bin
目录,执行./elasticsearch
将es启动。
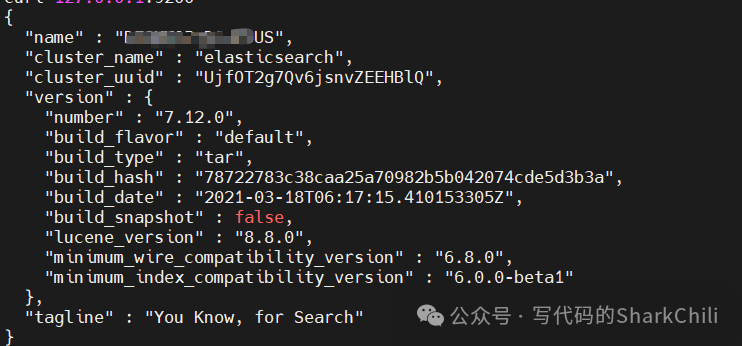
查看控制台没有报错后,我们可以通过curl
指令查看es
是否正常运行:
curl 127.0.0.1:9200
如下图,在curl
之后如果输出es
的基本信息则说明本次es配置部署成功:
kibana下载安装
kibana是操作es的图形界面工具,用起来非常方便,接下来我们就开始介绍一下kibana
的安装步骤,我们首先到达kibana官网,找到和我们ES
一致的Linux
版本进行下载,以笔者为例选择的就是7.12.0
版本,对应下载地址如下:
Kibana 7.12.0:https://www.elastic.co/cn/downloads/past-releases/kibana-7-12-0
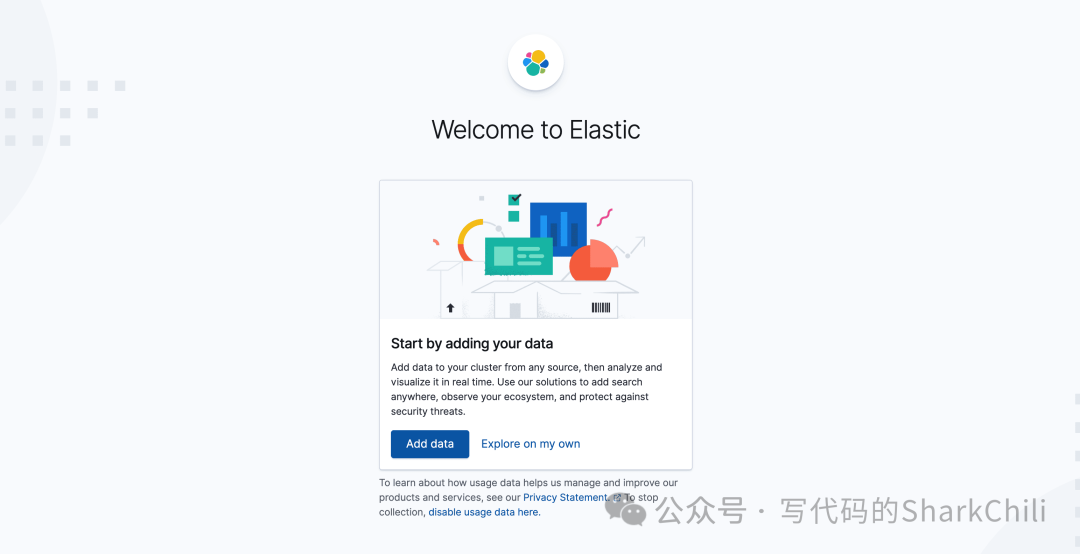
完成后我们进入kibana
根目录的bin
目录执行./kibana
将其启动。完成后我们通过浏览器访问5601端口如果出现如果进入kibana
初始化界面则说明安装成功:
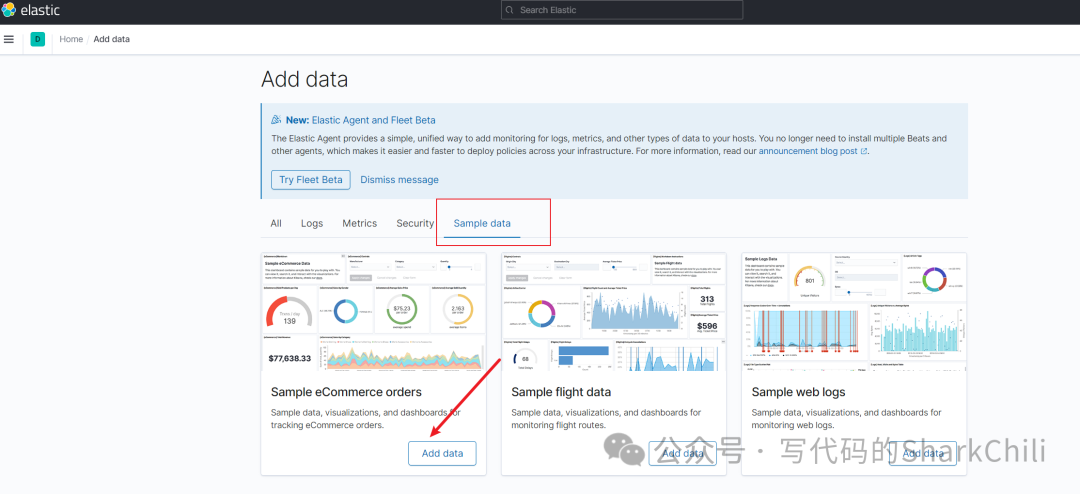
基于上述界面我们可以按需点击add data
选择simple data
等面板数据导入,这里笔者就不多
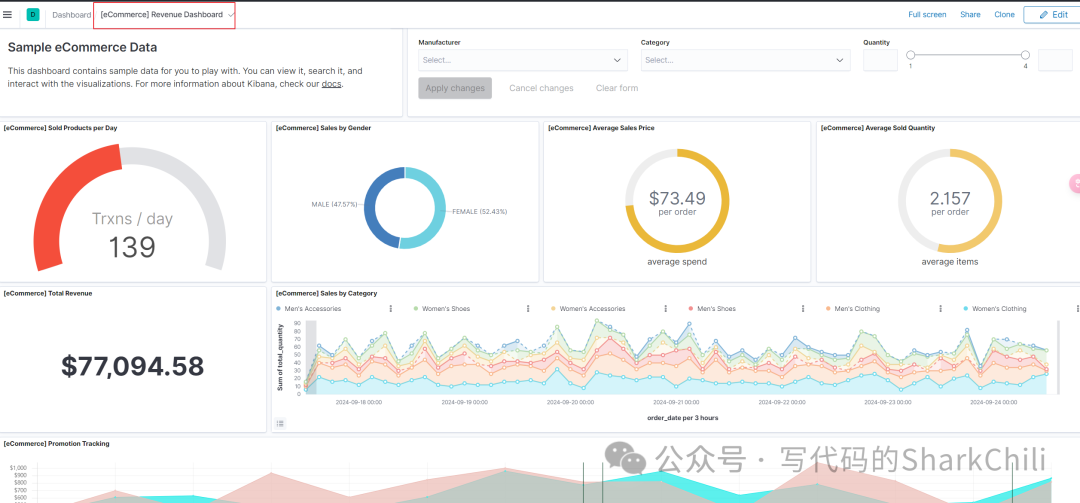
完成之后我们就可以在面板看到各种导入数据的概览信息:
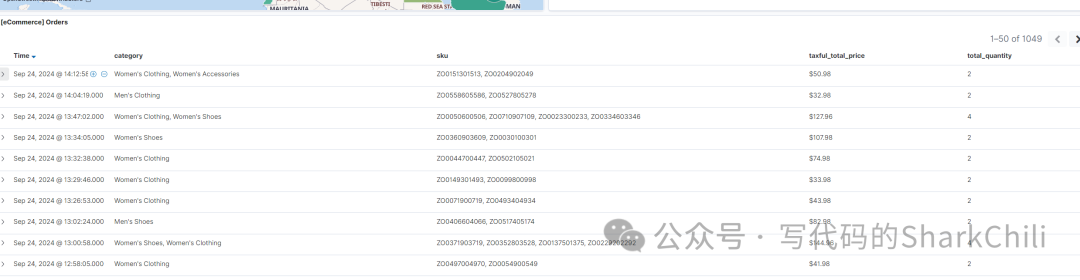
向下翻阅查看就可以看到导入数据的具体详情信息:
详解ElasticSearch和Kibana基础搜索姿势
基础插入和查询
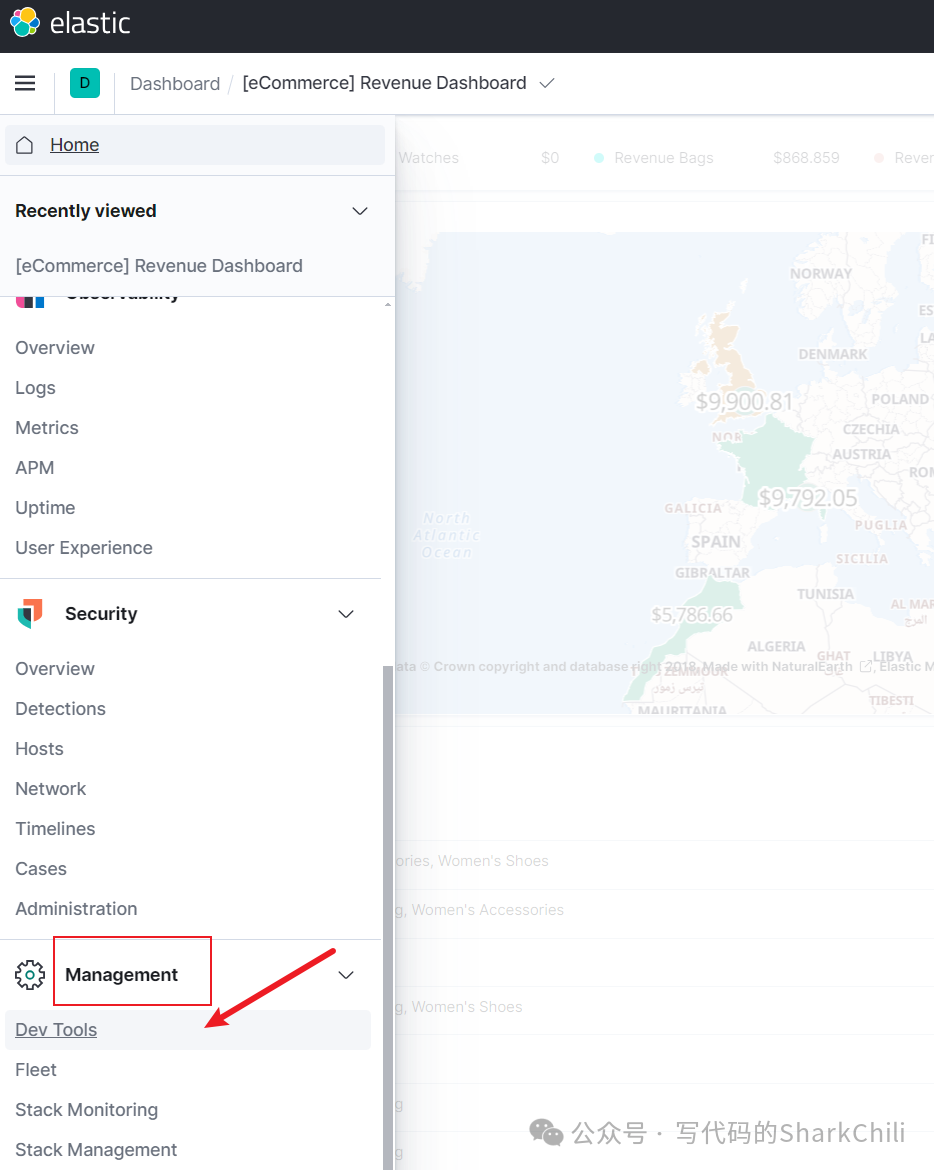
接下来就是正式的介绍Kibana对于ES的操作步骤了,在此之前我们先找到dev tools
界面:
若我们希望通过kibana
插入一条数据,我们就可以通过put
指令完成,如下所示,我们指定索引名为customer
,type
为_doc并指定id
为1的文档设置数据text
为hello kibana
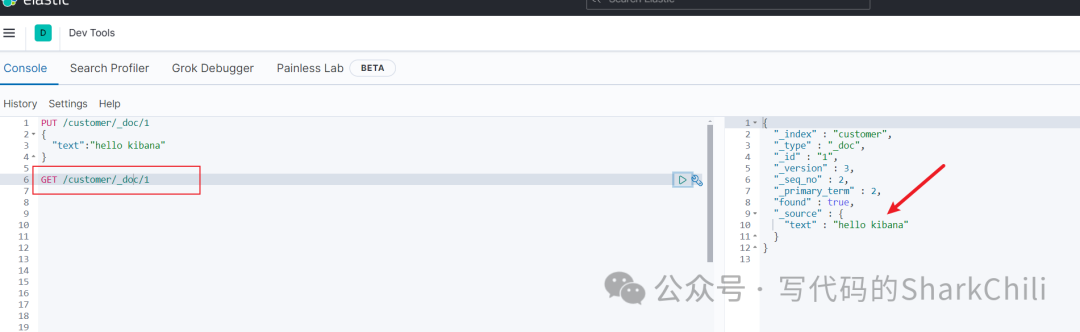
PUT /customer/_doc/1
{
"text":"hello kibana"
}
完成后我们可以直接通过GET
指令获取对应的指令为GET customer/_doc/1
,最终查询结果如下:
查询所有
通过上一个例子我们了解了基于kibana的基础读写ES操作,接下来我们就来演示一下几种比较常见的查询姿势,还记得我们上文导入的simple data
嘛?这里我就基于导入的数据演示一下查询所有数据的操作。
对应指令如下,可以看到我们指定导入数据的index为kibana_sample_data_ecommerce
,并键入_search
指令:
GET /kibana_sample_data_ecommerce/_search
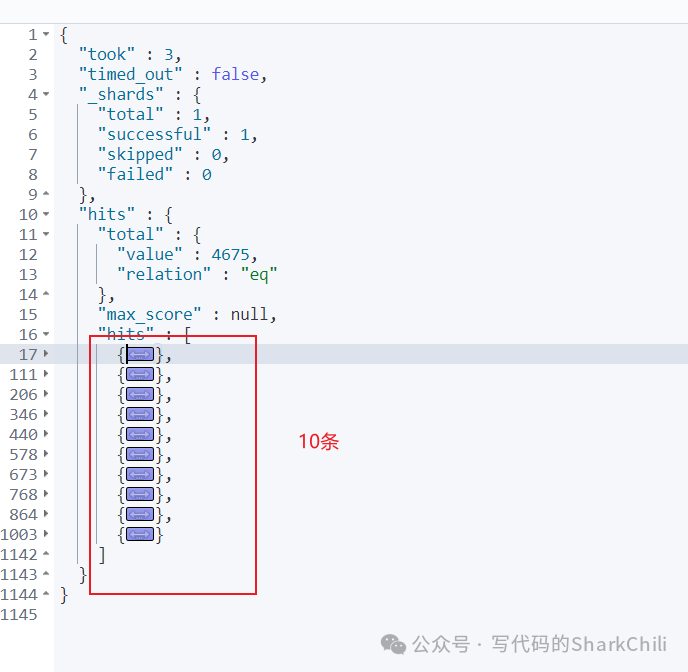
最终我们就可以看到下面这样的输出,这里笔者简单介绍一下几个比较重要的字段:
took
:查询耗费时间,单位为毫秒。timed_out
:搜索请求是否超时,这里显示false即没有超时。_shards
:查询的分片数,并列出成功、失败、跳过的条目数。max_score
:最匹配的一份文档的分数值。hits.sort
:具体文档列表信息hits._score
:具体文档的相关性得分,例如下图第一条目的文档就是1分。

分页查询
如果我们希望分页查询,则可以通过from
指定起始页,通过size
指定每页的大小,对应的查询示例如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_all": {} },
"sort": [
{ "email": "asc" }
],
"from": 1,
"size": 10
}
输出结果:
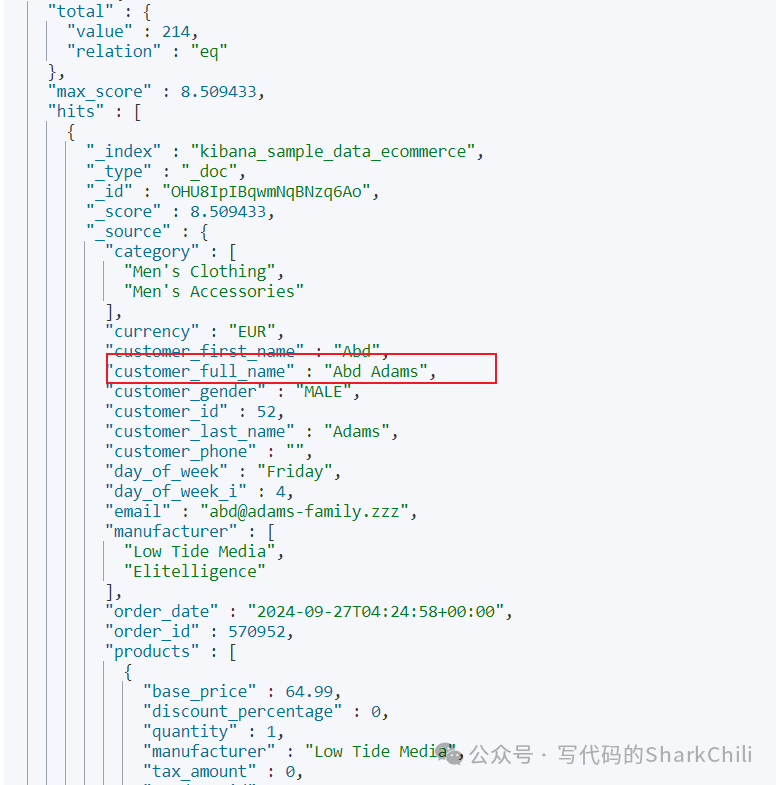
指定条件字段
我们希望查询customer_full_name
中包含Abd
或者Adams
中的数据,对此我们就可以通过match
指明查询的字段和字段值即可:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match": { "customer_full_name": "Abd Adams" } }
}
输出结果:
段落匹配
上一个例子是针对每一个词项进行匹配,如果我们希望查到customer_full_name
中带有Abd Adams
的数据,我们就可以通过段落匹配即可实现,对应的指令如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": { "match_phrase": { "customer_full_name": "Abd Adams" } }
}
输出结果:
多条件查询
es
支持多条件查询,例如我们希望查询customer_full_name
带有Abd
、Adams
但是customer_first_name
不包含Abd
的数据,那么我们就可以指定:
must
中指明customer_full_name
为Abd
、Adams
。must_not
中指明customer_first_name
为Abd
。
对应的指令示例如下:
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"bool": {
"must": [
{ "match": { "customer_full_name": "Abd Adams" } }
],
"must_not": [
{ "match": { "customer_first_name": "Abd" } }
]
}
}
}
输出结果:
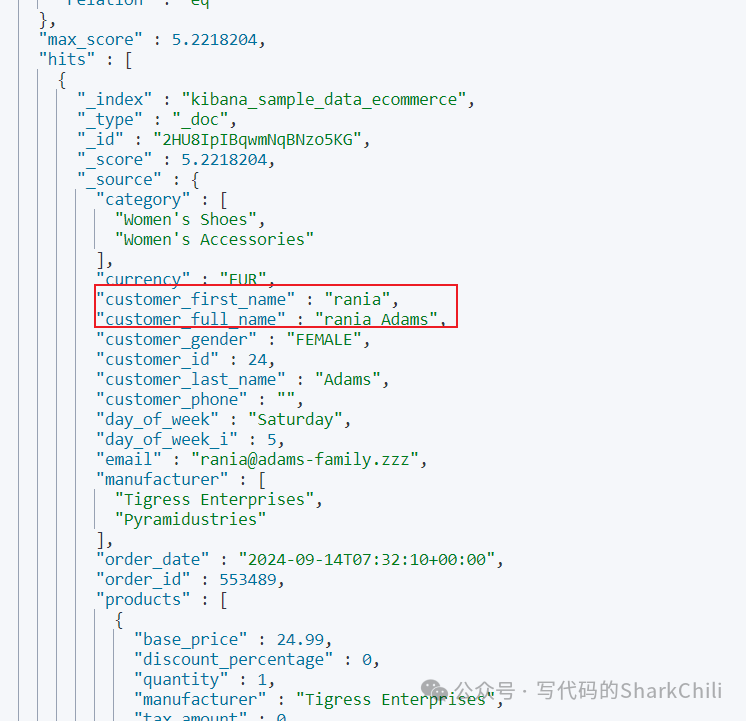
复合条件查询
我们希望查询符合如下3个条件的数据:
customer_full_name
为Abd
、Adams
。currency
为EUR
。customer_id
范围在50~55
。
对此我们的编写的检索语句为:
指定查询为 bool
多条件查询。must
通过match_phrase
关键字限定customer_full_name
为Abd Adams
。filter
过滤出值为EUR
的currency
。通过 customer_id
限定customer_id
范围为50~55
。
对应的我们给出查询语句,读者可结合表述进行理解,这里笔者需要补充一点,如果查询时单单使用filter
进行过滤的话,查询结果是是不会计算max_score
等匹配相关的结果,所以如果读者希望查询时得到每份文档的匹配分数还是建议使用must
:
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"customer_full_name": "Abd Adams"
}
}
],
"filter": [
{
"term": {
"currency": "EUR"
}
},
{
"range": {
"customer_id": {
"gte": 50,
"lte": 55
}
}
}
]
}
}
}
简单聚合查询
es同样是支持聚合操作,例如我们希望看到每个customer_full_name
对应的文档数,我们就可以通过group_by_state
查询指定term(词项)
为customer_full_name
,被聚合的字段无需对分词统计,所以使用customer_full_name.keyword
对整个字段统计:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword"
}
}
}
}
输出结果:
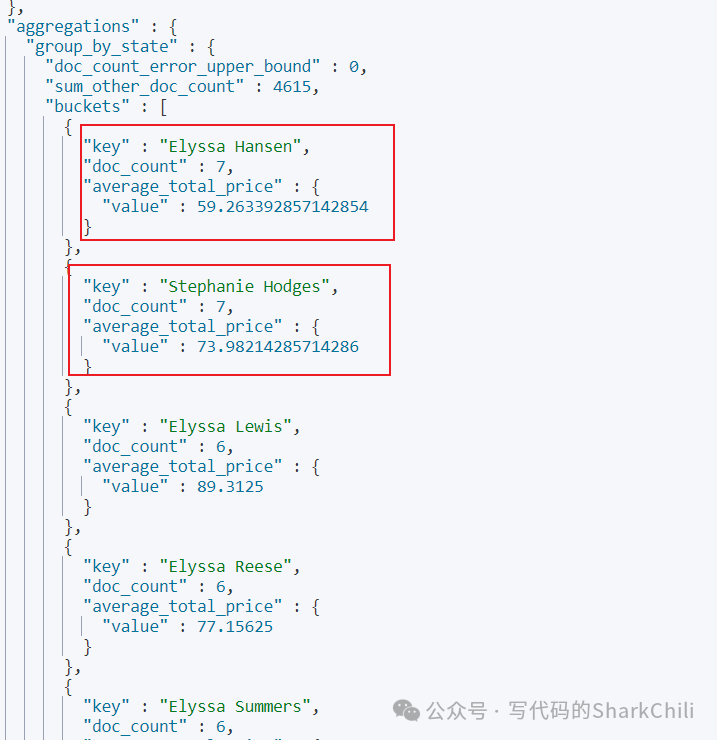
嵌套聚合
基于上述基础,我们希望查询出这每个人taxful_total_price
的平均值,我们可以通过es的嵌套聚合实现,语句如下,基于上述语法基础再声明一个aggs
指明avg
的字段为taxful_total_price
即可:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword"
},
"aggs": {
"average_total_price": {
"avg": {
"field": "taxful_total_price"
}
}
}
}
}
}
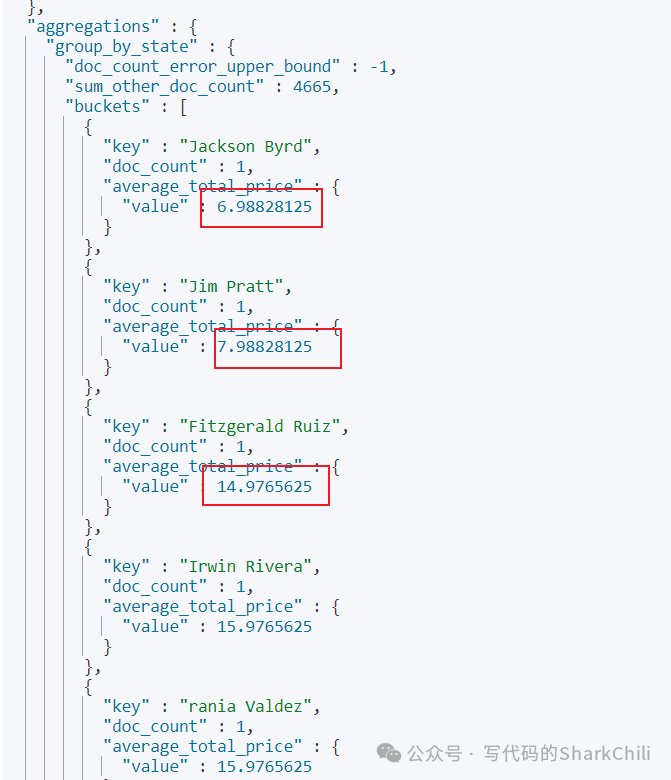
聚合结果排序查询
还是以上面的排序为例,如果我们希望通过taxful_total_price的结果进行升序排序的话,我们可以通过order指明使用的排序结果,以笔者本次示例来说,也就是通过average_total_price的结果进行排序,所以对应的语法如下:
GET /kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "customer_full_name.keyword",
"order": {
"average_total_price": "asc"
}
},
"aggs": {
"average_total_price": {
"avg": {
"field": "taxful_total_price"
}
}
}
}
}
}
从结果来看,输出的数据确实是按照聚合排序数据显示:
小结
自此笔者将所有es的基础操作都演示完成,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,mini-redis的作者,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
同时也非常欢迎你star我的开源项目mini-redis:https://github.com/shark-ctrl/mini-redis
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。
参考
ES详解 - 安装:ElasticSearch和Kibana安装:https://www.pdai.tech/md/db/nosql-es/elasticsearch-x-install.html
ES详解 - 入门:查询和聚合的基础使用:https://www.pdai.tech/md/db/nosql-es/elasticsearch-x-usage.html
ElasticSearch——Kibana 的Windows安装和Dev Tools的使用 :https://blog.csdn.net/wpc2018/article/details/121118269#:~:text=Kibana 是一款
