




点击上方 蓝字 关注数据微光👆 免费获取Doris+AI知识库

在大数据分析领域,Apache Doris 和 Elasticsearch (ES) 经常被用于实时分析和检索任务,但两者的设计理念和技术侧重点存在显著差异。
本文将从核心架构、查询语言、实时性、应用场景、性能表现、以及企业实践六个方面进行详细对比。
1. 核心设计哲学:MPP 架构 vs 搜索引擎架构
Apache Doris 采用典型的 MPP(Massively Parallel Processing)分布式架构,定位于高并发、低延迟的实时在线分析(OLAP)场景。它由 Frontend 和 Backend 组件构成,通过多节点并行计算和列式存储来高效处理海量数据。这种设计使 Doris 能在亚秒级返回查询结果,适合复杂聚合和大数据量下的分析查询。
Elasticsearch 则源自全文搜索引擎架构,采用 分片+倒排索引 的设计,更侧重于快速文本检索和过滤。ES 将数据作为文档存储,每个字段建立倒排索引,擅长关键字搜索和日志查询,但在复杂分析和大规模聚合计算时性能相对较弱。
为直观比较,两者核心架构理念差异如下:
| 架构理念 | Apache Doris(MPP 分析型数据库) | Elasticsearch(分布式搜索引擎) |
|---|---|---|
| 设计初衷 | ||
| 数据存储 | 列式存储 | 文档存储 |
| 扩展与弹性 | ||
| 典型特性 |
分析: Doris 的 MPP 架构使其在大数据聚合分析上具备天生优势。列式存储和向量化执行充分利用 IO 和 CPU,提高了处理效率。同时 Doris 支持预聚合和物化视图,加上易扩展的架构,使其在大规模数据分析场景下性能远超 ES。相比之下,Elasticsearch 的搜索引擎架构更擅长即时搜索和简单指标统计,对于复杂 SQL 分析、跨表关联等需求力不从心。另外,Doris 在 schema 演进上也更灵活,支持在线增加或修改列和索引,几乎实时生效;而 ES 的索引 schema 固化后难以更改,业务需求变化常需重新建索引,运维成本高。总体而言,在核心设计上 Doris 更侧重分析能力和易用性,而 ES 专注检索能力。当面临企业级的复杂分析需求时,Doris 的架构哲学提供了更高的性能上限和灵活性。
2. 查询语言:SQL vs DSL 的易用性与表达力
Doris 和 ES 在查询接口上截然不同:Doris 原生支持标准 SQL,而 Elasticsearch 使用 JSON DSL(Domain Specific Language) 查询。Doris 兼容 MySQL 协议,支持丰富的 SQL92 查询特性,包括 SELECT 投影、WHERE 过滤、GROUP BY 聚合、ORDER BY 排序、多表 JOIN、子查询、窗口函数、UDF/UDAF 以及创建视图和物化视图等。这种完整的 SQL 支持意味着数据分析师和工程师无需学习新语言,即可利用熟悉的 SQL 直接对 Doris 进行复杂查询和数据处理。
相反,Elasticsearch 提供的是专有的 JSON 格式查询 DSL,语法与 SQL 完全不同,往往需要嵌套多层结构来表示过滤和聚合逻辑。对于不熟悉 DSL 的用户来说,编写和调试此类查询学习曲线陡峭,而且和传统 BI/数据库工具集成困难。
下表对比了 Doris 的 SQL 查询与 ES DSL 查询在易用性和能力上的差异:
| 查询语言 | Apache Doris(SQL 接口) | Elasticsearch(JSON DSL) |
|---|---|---|
| 语法风格 | 标准 SQL | 专有 DSL |
| 表达能力 | ||
| 学习成本 | ||
| 生态集成 | MySQL 协议兼容 | 生态封闭 |
分析: 对于日常使用和开发效率而言,Doris 的 SQL 接口优势明显。用户可以用熟悉的 SQL 编写查询,不需额外学习,这极大降低了使用门槛。
例如,在 Doris 上要对日志数据按日期、URL、应用ID等多维度聚合,只需一条SQL语句包含相应的 GROUP BY
子句即可完成;而在 Elasticsearch 中,实现相同功能需要嵌套多个聚合层次的 DSL,结构复杂冗长。这种差异导致在 ES 上开发调试效率较低:据实践经验,当排查问题时,需要构造大量复杂的 Curl DSL 请求给没有ES经验的用户,沟通和定位非常困难。引入 Doris 后,只要熟悉 SQL 基本语法,问题定位和查询编写就变得简单快捷。
另外在功能上,Doris 完全支持多表关联和子查询,这对于构建数据仓库模型(星型模型关联维表等)以及复杂指标计算至关重要。而 ES 天生不支持表关联,往往需要预先把数据冗余到一个索引里,或者通过应用层二次处理,既不灵活也影响性能。
综合来看,Doris 在查询语法的易用性和表达能力上全面胜出:它既保留了 SQL 强大的表达力,又大幅降低了分析师和开发人员的使用难度,方便与现有的数据分析生态衔接。
3. 实时数据处理机制:写入架构与数据更新
在实时数据摄取与查询方面,Doris 和 ES 采取了不同的机制,各有侧重。
Elasticsearch 强调近实时搜索,特点是逐条文档写入、频繁刷新索引:数据通过 REST API (如 Bulk 批量接口) 写入 ES,经过分词、建立倒排索引后存储,每隔固定短周期(默认1秒)刷新使新数据可被搜索。这样的机制保证了单条日志在秒级内可被检索,但也带来了写入开销高和一致性上的折衷。每条数据写入时,ES 都要在主分片和副本上各自执行一次完整的索引过程,涉及文本解析和倒排索引生成,CPU 开销大。官方测试显示 ES 单核写入吞吐仅约 2 MB/s;在写入高峰时,CPU 常成为瓶颈甚至拒绝写入请求,影响数据实时性。
相比之下,Apache Doris 的实时数据导入采用高吞吐的批量写入架构。Doris 将数据按小批流式导入(可以通过 Stream Load 接口 push,或通过 Routine Load 从消息队列 pull),在 Backend 以列存格式高效批量写入,一次完成多副本的数据分发和存储。由于省去了逐字段倒排索引的重压计算,Doris 单节点的写入带宽远高于 ES。例如基于官方 ES Rally 基准测试,Doris 的数据写入速度约是 ES 的 5 倍。更重要的是,Doris 支持直接从消息队列拉取数据(如 Kafka),无需像 ES 那样借助 Logstash/Beats 等外部工具来喂数,简化了实时管道的架构。
在数据更新和存储实时化方面,两者也有差异:
索引/存储机制: Doris 采用列式存储并配合多副本一次写入,整体存储空间占用低,压缩比可达 5:1 ~ 10:1。ES 因为存储了正排、倒排索引和 column store (doc values) 等冗余结构,同一份数据存储膨胀,压缩比仅 ~1.5:1。这意味着相同日志数据 Doris 只需大约 20% 的存储空间即可保存。低存储占用也提升了 IO 效率,使 Doris 可更快地扫描最新数据做分析。 数据更新与聚合: Doris 支持多种数据模型,其中 Unique Key 模型可用于以主键更新数据,内部通过“写时合并 (MoW)”或“读时合并 (MoR)”机制高效处理UPSERT操作,即使含有去重更新,其写入性能损耗也在10%以内。相较之下,ES 对文档级更新(如更改或删除一条记录)基本相当于重索引,开销极大,在模拟主键去重场景下性能损失高达3倍以上。另外 Doris 的 Aggregate Key 模型支持在数据导入时自动对指定维度汇总聚合,保证聚合结果强一致更新,并允许明细和聚合数据在同一库中共存查询。ES 虽有 rollup 等聚合索引功能,但属于异步最终一致,且生成的汇总数据通常独立于原始索引,无法同时查询,灵活性和一致性较弱。 实时查询可见性: ES 新写入的数据在一次 refresh 后即可被搜索到,延迟通常在秒级以内,适合即时检索单条日志。Doris 虽然不像ES那样每秒刷新索引,但通过持续的小批量导入(如 Routine Load 每隔数秒提交),也能做到秒级甚至亚分钟级数据可见。在实际日志分析场景中,这样的延迟能够满足绝大多数实时分析需求。同时 Doris 在 Backend 内存中维护新数据并定期刷新到列存盘上,因此查询可以及时读取最新的导入批次数据,保证分析的实时性。
分析: 综合来看,Doris 的实时性机制更注重高吞吐和最终一致的快速分析,而 ES 注重毫秒级写入和近实时检索。
当日志数据量和并发写入很大时,ES 的逐条索引方式将耗费大量CPU并产生索引膨胀,不仅写入速度慢且集群容易过载。Doris 则通过批量写入和列式压缩,大幅提高了单节点吞吐并降低存储成本。实际测试表明,Doris 写入性能约为 ES 的5倍,查询性能约为 ES 的2.3倍,而存储消耗仅为 ES 的1/5。这意味着在相同硬件资源下,Doris 能以更低延迟摄取更多数据、保存更长周期的明细,并及时提供聚合分析结果。
同时 Doris 丰富的数据模型和 Schema 动态演进能力,使实时数据处理更灵活——无论是流式导入、实时去重更新,还是随业务调整添加新字段/索引,在 Doris 上都能平滑完成。相反,ES 在遇到 schema 变更或数据更新需求时,往往需要重建索引或额外的后处理逻辑,实时性和易用性打折扣。
因此,对于高频数据写入且需要持续快速分析的场景,Doris 提供了更高的吞吐和弹性,确保了实时数据的高效利用。
4. 典型应用场景比较:日志分析、BI 报表等
由于上述架构和功能差异,Apache Doris 和 Elasticsearch 各自在不同应用场景中表现出优劣势。下面对比两者在日志分析和商业智能(BI)报表场景下的适用性:
| 应用场景 | Apache Doris | Elasticsearch |
|---|---|---|
| 日志集中分析 | ||
| BI 报表/数据仓库 |
分析: 在日志分析领域,Doris 和 ES 可以说是各有侧重又相辅相成。Elasticsearch 因其强大的全文检索能力,依然是即时搜索具体日志的利器;运维人员习惯使用 Kibana 查询最近几小时的错误日志或进行全文模糊搜索,这是 Doris 所不擅长的。但随着日志数据规模增长和分析需求提高,仅靠 ES 会遇到性能和成本瓶颈。Doris 的引入正好弥补了这些不足——通过更低成本的存储和更快速的复杂查询,它可以承担海量日志的长期保存和多维分析任务,将 ES 解放出来专注于实时检索热数据。很多企业的实践是将 Doris 与 ES 联用:热数据和全文检索用 ES,冷数据和统计分析用 Doris,实现冷热分层和功能互补。至于 BI 报表和数据仓库场景,Doris 无疑比 ES 更加契合。Doris 提供了数据仓库所需的几乎全部功能(分区、桶分布、ETL加载、SQL分析等),能够直接承载企业级数仓和报表系统。在需要跨表汇总、复杂计算的典型BI场景中,Doris 体现出高度的易用性和出色性能,这是搜索引擎出身的 ES 难以企及的。因此,企业往往会选用 Doris 或其它 OLAP 数据库来构建报表分析体系,而不是尝试在 ES 上开发此类应用。
5. 性能基准测试对比
大量实测数据进一步印证了 Doris 在分析性能上的优势。官方使用 Elasticsearch 的基准测试工具 ES Rally 对两者进行了同硬件下的对比,结果显示 Apache Doris 在写入、查询、存储三个维度均大幅优于 Elasticsearch。如下图所示:
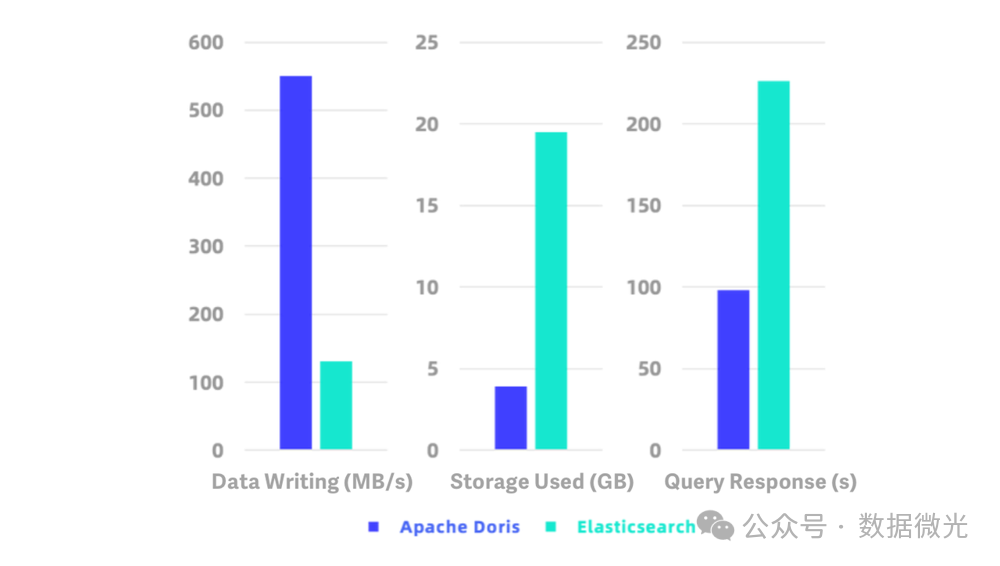 Apache Doris 与 Elasticsearch 性能对比:包括数据写入吞吐、存储占用以及查询响应时间
Apache Doris 与 Elasticsearch 性能对比:包括数据写入吞吐、存储占用以及查询响应时间
从上图可以看出,Doris 的数据写入速度达到 550 MB/s(每秒可导入数百万条记录),约为 ES 的 5 倍。这意味着如果需要在单位时间内摄取海量数据(如服务器日志、用户行为流等),Doris 可以用更少的节点完成任务。存储方面,Doris 对相同数据仅占用 ES 大约 1/5 的空间(因为Doris压缩比可达10:1,而ES只有约1.5:1),这不仅节省存储成本,也提高了系统在大数据量下的可扩展性。查询性能上,Doris 对复杂分析查询的响应时间约为 ES 的 1/2.3。例如,在某实际测试中,对 4000 万条日志记录执行多维度聚合统计,Elasticsearch 大约需要 6–7 秒 返回结果,而 Doris 1 秒以内即可完成。可见在面对大数据集的重度查询时,Doris 能显著胜出,实现亚秒级的交互查询体验。
除平均指标外,高并发下的性能稳定性也是 Doris 的优势所在。由于 MPP 架构可以将查询拆解成并行任务,Doris 即使在多用户并发执行复杂查询时,仍能保持较低的延迟和高吞吐。而 ES 在并发增加、查询变重时容易受制于单节点内存和CPU限制,出现延时飙升甚至查询失败(特别是遇到需要大量排序、聚合的请求时,可能因为 JVM 内存不足而 OOM)。因此,无论从吞吐、延迟还是资源利用来看,基准测试都体现了 Doris 更适合作为分析型引擎部署在数据密集型场景中。
6. 企业实践案例
越来越多的企业在实际生产中验证了 Doris 相比 ES 的效能提升和成本优势。下面列举几个具有代表性的案例:
360 企业安全浏览器(奇安信)[1]:原架构采用 Elasticsearch 保存和分析日志,随着数据量增长,遇到索引变更困难、聚合查询慢等问题。引入 Apache Doris 统一日志检索与报表分析后,**聚合分析效率提升了数量级、存储成本降低约 60%**,成功实现了日志平台的升级。在具体查询上,Doris 将原先 ES 上需要复杂 DSL 实现的多层聚合转化为简单 SQL,大幅提升了开发和运维效率。
腾讯音乐娱乐集团 (TME)[2]:面对海量音乐内容库检索和分析需求,TME 最初使用 Elasticsearch 集群支撑内容搜索和数据分析。后来通过引入 Doris 替代 ES,实现了搜索和分析一体化的新架构。迁移后效果显著:**存储成本降低了 80%**,每日全量数据由 ES 需 697GB 降至 Doris 的 195GB(压缩节省 72%);同时 Doris 提升了约 4 倍写入性能 满足高并发导入。这个案例表明 Doris 在提供类似搜索功能的同时还能处理复杂分析,并大幅削减硬件成本。
某大型银行(如中信银行)[3]:该行构建基于 Doris 的日志存储与分析平台,上线后相比原有 Elasticsearch 架构消除了数据冗余、提高了存储效率,并提供了更强大高效的日志检索与分析服务。通过 Doris 的统一数仓架构,日志的实时写入和复杂查询性能都有明显优化,实现了对安全日志的精细化分析和快速报表展现。
某支付科技公司[3]:此前采用多套组件组合的安全分析系统,存在数据多份存储、体系复杂的问题。引入 Doris 统一架构后,系统在数据写入吞吐、复杂查询速度、存储效率等方面均有显著提升:具体包括写入速度提升 4 倍,复杂查询性能提升 3 倍,存储空间节省 **50%**。同时因为使用标准 SQL,大大简化了运维和使用成本。
上述案例充分证明,在需要同时处理大量数据写入和复杂查询的企业级应用中,Apache Doris 展现出超越 Elasticsearch 的综合表现:不但查询更快、支撑的分析场景更丰富,而且极大降低了资源和运维开销。这也是为何越来越多公司选择在日志分析、用户行为分析、报表系统等领域部署 Doris 来替代或补充原有的 ES 集群。当然,Elasticsearch 也依然在众多企业中扮演重要角色,尤其是在全文检索、实时监控方面。例如经典的 ELK(Stack) 日志方案曾被无数互联网公司采用,用于检索服务器日志、业务指标和异常信息。只是随着业务发展,很多公司开始引入像 Doris 这样的新一代实时数仓,形成“搜索+分析”分工协作的新架构,以获得更高的性价比。
总结:
Apache Doris 和 Elasticsearch 分别从数据仓库和搜索引擎两端出发,正在逐步覆盖实时数据处理领域的广阔版图。
通过上述多方面对比可以看出,Doris 在大规模复杂分析、SQL 易用性、高吞吐与存储效率等方面具备明显优势,特别适合建设统一的实时分析平台;而 ES 在全文检索、实时细粒度查询方面仍有不可替代的价值,适合作为搜索型应用和监控系统的支柱。
对于企业来说,二者并非绝对对立的选择:根据具体业务需求,可以采用 Doris 提供数据分析能力、ES 提供检索能力的组合方案,发挥各自所长。在数据规模和实时要求不断提高的未来,Doris 凭借其MPP架构和持续演进,有望承担更多传统数仓和部分搜索的职能,成为企业实时分析的利器;而 Elasticsearch 则会向智能搜索方向深化,服务于搜索和AI融合的新型应用。
可以预见,两者都会在各自擅长的轨道上不断创新,为企业的海量数据价值挖掘提供更强大的技术引擎。最终,选择哪种技术或如何搭配使用,取决于应用场景的侧重:需要更强分析和低成本时倾向 Doris,需要更强搜索和实时查询时依赖 ES,合理整合将让我们获得“1+1>2”的效果。
今后,我们期待看到更多关于 Doris 和 ES 协同创新的实践,为实时大数据处理打造更高效的解决之道。
参考文献:
从 Elasticsearch 到 Apache Doris 统一日志检索与报表分析,360 企业安全浏览器的数据架构升级实践 - SelectDB https://www.selectdb.com/blog/166 从 Elasticsearch 到 Apache Doris,腾讯音乐成本直降 80% - SelectDB https://www.selectdb.com/blog/1037 SelectDB 技术对比 https://www.selectdb.com/solutions/doris-vs-elasticsearch
往期推荐

数据微光 专注分享 Apache Doris 的最佳实践、问题解决技巧、学习资源和实用案例,致力于为开发者和技术爱好者提供高质量内容支持和持续学习动力。
📚 特别福利 | 数据微光知识库内含Apache Doris丰富的 学习资料、实战课程、白皮书、行业报告、技术指南,帮助快速掌握数据库核心技能!
📘 领取方式: 关注 “数据微光” 公众号 扫描下方二维码,备注【Doris】即可免费获取! 💻 让我们携手点亮技术微光,共同探索 Doris 的无限可能!


Apache Doris
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极易易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发发点查询场景,也能支持高吞吐的复杂分析场景。
如果您对 Apache Doris 感兴趣,可以通过以下入口访问官方网站、社区论坛、GitHub 和 dev 邮件组:
📒 官方文档: https://doris.apache.org 💬 社区论坛: https://ask.selectdb.com 📂 GitHub: https://github.com/apache/doris 📧 dev 邮件组: dev@doris.apache.org
可以加 作者微信 (hhj_0530) 直接进 Doris 官方社区群。
PowerData
PowerData 是由一群数据从业人员,因为热爱凝聚在一起,以开源精神为基础,组成的数据开源社区。
社区群内会定期组织模拟面试、线上分享、行业研讨、线下 Meetup、城市聚会、求职内推等活动。同时,在社区群内您可以进行技术讨论、问题请教,结识更多志同道合的数据朋友。
社区整理了一份每日一题汇总及社区分享 PPT,内容涵盖大数据组件、编程语言、数据结构与算法、企业真实面试题等各个领域,帮助您提升自我,成功上岸。
可以加 作者微信 (hhj_0530) 直接进 PowerData 官方社区群。


点击上方蓝字关注我们
