





1. 问题背景
腾讯云MongoDB团队通过观测线上分片集群运行情况发现,4.0版本当表的路由chunks达到20W(约4-5T数据),增量路由获取就会有200ms左右的抖动;随着路由chunks的继续增加,抖动会越加明显,达到100W路由chunks(约10-15T数据)后,抖动增加到秒级。
原生MongoDB内核从3.4到最新的6.0版本,路由刷新模块核心代码都有较大的机制改动来解决路由刷新抖动问题,但是没有彻底解决。
此外,路由更新过程消耗内存远远高于实际的路由chunks所需要内存,容易OOM。
通过本文可以学习到如下知识:
分片集群路由核心实现原理。
刷路由过程为何业务大量超时?
MongoDB分片集群路由性能1000倍/10000倍级优化核心算法实现。
MongoDB团队如何彻底解决balance、扩容、缩容、split等引起集群抖动。
腾讯云MongoDB团队路由刷新模块优化收益:
● 不管集群数据量多大、chunks有多少,扩缩容、split等过程业务访问不再抖动。
● 物理资源充足情况下,可实现24小时无抖动balance数据搬迁。
● 不管集群多大,路由替换模块耗时从秒级减少到1ms以内。
● 提升大业务快速迭代效率,不再担心表太大引起的抖动。
腾讯云路由优化后效果:
数据量 | Chunk数 | 原生版本时延 | 优化后时延 | 性能提升结果 | |
3.6 | 80T | 450W | 4500ms | 2ms | 提升2200倍 |
4.0 | 1.2T | 25W | 300ms | 2ms | 提升150倍 |
4.2 | 25T | 150W | 1200ms | 2ms | 提升600倍 |
5.0(测试数据) | 30T | 200W | 750ms | 2ms | 提升450倍 |
5.0(测试数据) | 100T | 600W | 2400ms | 2ms | 提升1200倍 |
腾讯云路由优化后,不管集群规模多大,整个增量路由获取都维持2ms左右。
MongoDB官方也认可了腾讯的贡献,该优化4.2及以上版本中增加了该优化功能。
2. 问题影响
mongos和mongod在split chunk、moveChunk、扩容、缩容、普通读写请求、路由转发等都和路由fresh相关联,几乎影响MongoDB整个分片集群的核心功能逻辑。
全量获取路由和增量获取路由过程,所有请求都需要阻塞等待,因此如果刷路由过程耗时过长,所有客户端请求都会超时。随着数据量增大,chunks也相应增加,获取路由过程耗时更长,从而引起分片集群的一系列问题,主要问题如下:
● 集群抖动
全量获取路由和增量获取路由过程,所有请求都需要阻塞等待,因此mongos和mongod都存在严重抖动,chunks越多,抖动越明显。
例如:4.2版本,25T数据,150W路由chunk全量获取会有16秒抖动,增量chunk获取会有1.5秒抖动。
● 分片集群数据永远无法均衡,数据倾斜严重
以线上某150W chunk集群为例,由于balance过程业务抖动明显,因此关闭了balance和split功能,只在业务低峰期凌晨1:00~6:00启用,数据迁移速度永远低于写入速度,最终造成数据倾斜越来越不均衡,如下图所示:
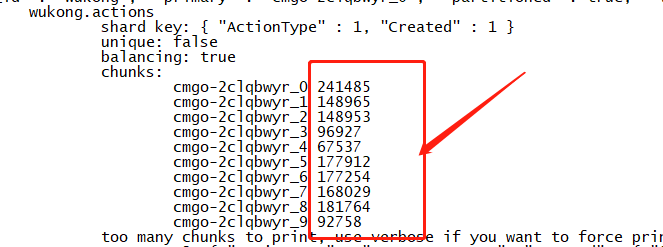
● 增加了业务改造成本,不利于业务快速迭代开发
随着数据量的增加集群抖动,为了避免路由问题引起的严重业务抖动,很多用户严格限制一个分片集群中某个表的数据量,进行传统的分库分表操作,通过这种方式避免业务抖动,这限制了MongoDB分布式水平扩容的功能,增加了业务改造难度,不利于业务快速迭代开发。
3. 路由抖动问题真实线上案例
案例1:线上4.0版本抖动现象(25W chunk,增量路由300ms抖动)
● 集群规模详情
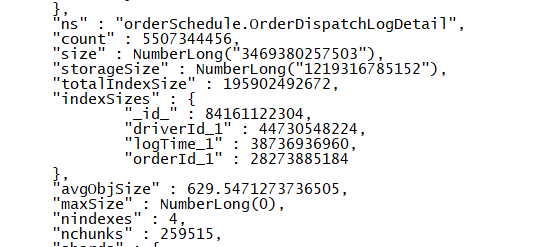
数据量:50亿行,1.2T数据
chunk数:25万
获取增量路由抖动程度:mongos约200ms抖动,mongod约300ms抖动
● mongos获取增量路由抖动日志

● Thu Oct 6 11:28:42.556 I SH_REFR [ConfigServerCatalogCacheLoader-85148] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|686||62d157722a3a66acadc3b7a4 to version 102961|701||62d157722a3a66acadc3b7a4 took 190 ms
● Thu Oct 6 11:28:44.914 I SH_REFR [ConfigServerCatalogCacheLoader-85148] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|701||62d157722a3a66acadc3b7a4 to version 102961|704||62d157722a3a66acadc3b7a4 took 173 ms
● Thu Oct 6 11:29:41.923 I SH_REFR [ConfigServerCatalogCacheLoader-85149] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|704||62d157722a3a66acadc3b7a4 to version 102961|707||62d157722a3a66acadc3b7a4 took 174 ms
● Thu Oct 6 11:32:02.121 I SH_REFR [ConfigServerCatalogCacheLoader-85151] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|707||62d157722a3a66acadc3b7a4 to version 102961|723||62d157722a3a66acadc3b7a4 took 198 ms
● mongod获取增量路由抖动日志

Thu Oct 6 11:24:11.358 I SH_REFR [ConfigServerCatalogCacheLoader-191078] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|603||62d157722a3a66acadc3b7a4 to version 102961|628||62d157722a3a66acadc3b7a4 took 262 ms
Thu Oct 6 11:24:21.306 I SH_REFR [ConfigServerCatalogCacheLoader-191078] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|628||62d157722a3a66acadc3b7a4 to version 102961|631||62d157722a3a66acadc3b7a4 took 255 ms
Thu Oct 6 11:24:45.905 I SH_REFR [ConfigServerCatalogCacheLoader-191078] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|631||62d157722a3a66acadc3b7a4 to version 102961|634||62d157722a3a66acadc3b7a4 took 265 ms
Thu Oct 6 11:25:20.979 I SH_REFR [ConfigServerCatalogCacheLoader-191078] Refresh for collection orderSchedule.OrderDispatchLogDetail from version 102961|634||62d157722a3a66acadc3b7a4 to version 102961|644||62d157722a3a66acadc3b7a4 took 252 ms
● mongos获取全量路由(25W chunk,约3.6秒抖动)
对应日志如下:
1. Thu Oct 6 14:00:26.986 I SH_REFR [ConfigServerCatalogCacheLoader-1] Refresh for database orderSchedule took 28 ms and found { _id: "orderSchedule", primary: "xxxxxxhotjy7ep_2", partitioned: true, version: { uuid: UUID("95759fb6-545f-4c3c-a514-dd1391e38099"), lastMod: 1 } }
2. Thu Oct 6 14:00:32.605 I SH_REFR [ConfigServerCatalogCacheLoader-1] Refresh for collection orderSchedule.OrderDispatchLogDetail to version 102961|1281||62d157722a3a66acadc3b7a4 took 3579 ms
● mongos获取全量路由(150W chunk,约3.6秒抖动)
测试方法:新建一个mongos,启动后访问一条orderSchedule.OrderDispatchLogDetail数据,对应日志如下:
从上面的现象可以看出,4.0版本25W chunk,50亿数据,获取一个增量chunk,约300ms左右抖动。
mongos重启后,访问数据获取全量路由,25W chunk全量路由获取时间3.5秒;mongod重启、或者主从切换预计获取全量路由时间更长。
案例2:线上4.2版本抖动现象(150w chunk, 全量15秒级,增量1秒级抖动)
● 集群规模详情
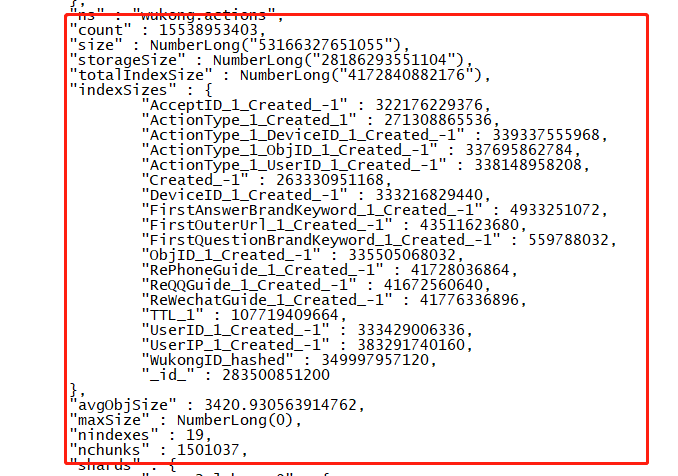
数据量:155亿行,25T数据
chunk数:150万
获取增量路由抖动程度:mongos约800ms抖动,mongod约1200ms抖动
● mongos获取增量路由抖动日志

● 2022-10-05T04:18:41.359+0800 I SH_REFR [ConfigServerCatalogCacheLoader-136639] Refresh for collection wukong.actions from version 102910|1||626ba80f5fa7cb632d7bf264 to version 102910|4||626ba80f5fa7cb632d7bf264 took 740 ms
● 2022-10-05T04:18:50.800+0800 I SH_REFR [ConfigServerCatalogCacheLoader-136639] Refresh for collection wukong.actions from version 102910|4||626ba80f5fa7cb632d7bf264 to version 102910|7||626ba80f5fa7cb632d7bf264 took 740 ms
● 2022-10-05T04:19:18.546+0800 I SH_REFR [ConfigServerCatalogCacheLoader-136639] Refresh for collection wukong.actions from version 102910|7||626ba80f5fa7cb632d7bf264 to version 102911|1||626ba80f5fa7cb632d7bf264 took 748 ms
● 2022-10-05T04:20:01.105+0800 I SH_REFR [ConfigServerCatalogCacheLoader-136640] Refresh for collection wukong.actions from version 102911|1||626ba80f5fa7cb632d7bf264 to version 102912|1||626ba80f5fa7cb632d7bf264 took 781 ms
● mongod获取增量路由抖动日志

● 2022-10-06T10:54:49.219+0800 I SH_REFR [ConfigServerCatalogCacheLoader-141236] Refresh for collection wukong.actions from version 103200|584||626ba80f5fa7cb632d7bf264 to version 103200|593||626ba80f5fa7cb632d7bf264 took 1001 ms
● 2022-10-06T10:57:42.071+0800 I SH_REFR [ConfigServerCatalogCacheLoader-141237] Refresh for collection wukong.actions from version 103200|593||626ba80f5fa7cb632d7bf264 to version 103200|608||626ba80f5fa7cb632d7bf264 took 1200 ms
● 2022-10-06T11:00:36.781+0800 I SH_REFR [ConfigServerCatalogCacheLoader-141240] Refresh for collection wukong.actions from version 103200|608||626ba80f5fa7cb632d7bf264 to version 103200|623||626ba80f5fa7cb632d7bf264 took 1146 ms
● 2022-10-06T11:03:34.142+0800 I SH_REFR [ConfigServerCatalogCacheLoader-141241] Refresh for collection wukong.actions from version 103200|623||626ba80f5fa7cb632d7bf264 to version 103200|632||626ba80f5fa7cb632d7bf264 took 1129 ms
● mongos获取全量路由(150W chunk,约17秒抖动)
测试方法:重新手工创建一个新的mongos,重启后手动访问该mongos。
● 2022-10-06T14:28:35.887+0800 I QUERY [conn93] slow query:{ find: "actions", filter: {}, limit: 1.0, singleBatch: true, lsid: { id: UUID("18ab404c-d56b-4dae-8182-aabfacd6dedb") }, $clusterTime: { clusterTime: Timestamp(1665037697, 14), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, $db: "wukong" }, 16780238 microSeconds
● 2022-10-06T14:28:35.887+0800 I COMMAND [conn93] command wukong.actions appName: "MongoDB Shell" command: find { find: "actions", filter: {}, limit: 1.0, singleBatch: true, lsid: { id: UUID("18ab404c-d56b-4dae-8182-aabfacd6dedb") }, $clusterTime: { clusterTime: Timestamp(1665037697, 14), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, $db: "wukong" } nShards:10 cursorExhausted:1 numYields:0 nreturned:1 reslen:2675 protocol:op_msg 16780ms
从上面的现象可以看出,4.2版本150W chunk,150亿数据,获取增量路由约1100ms左右抖动。
mongos重启后,访问数据获取全量路由,150W chunk全量路由获取时间17秒;mongod重启、或者主从切换预计获取全量路由时间更长。
案例3:线上3.6版本抖动现象(450W chunk,增量路由4000ms抖动,全量35秒抖动)
● 集群规模详情
数据量:1200亿行,80T数据
chunk数:450万
获取增量路由抖动程度:mongos约4秒抖动,mongod约4.5秒抖动。
获取450W chunk全量路由:抖动时间约35秒。
参考之前分享的案例:千亿级高并发MongoDB集群在某头部金融机构中的应用及性能优化实践(上)
● mongos/mongod获取增量路由抖动日志
参考已分享中行案例。
案例4:5.0版本测试抖动现象(200W chunk,全量17秒,增量700ms抖动)
测试集群构造200W个chunk,以最简单的id做片建,id按照0-100000000随机取值,然后手动进行chunk预分片,生成200W个chunk。
● 5.0版本mongos获取全量路由(200W chunk,17秒抖动)
1. //全量路由获取耗时
2. mestamp":{"t":0,"i":0}},"1":{"$oid":"000000000000000000000000"}},"newVersion":{"chunkVersion":{"0":{"$timestamp":{"t":49182,"i":1}},"1":{"$oid":"626a663821072b82d9059209"},"2":{"$timestamp":{"t":1651140151,"i":6}}},"forcedRefreshSequenceNum":7,"epochDisambiguatingSequenceNum":6},"timeInStore":{"chunkVersion":"None","forcedRefreshSequenceNum":0,"epochDisambiguatingSequenceNum":0},"durationMillis":16985}}
● 5.0版本mongos获取增量路由(单个增量路由获取耗时900ms)
● //增量路由获取耗时
● {"t":{"$date":"2022-10-06T17:46:25.479+08:00"},"s":"I", "c":"SH_REFR", "id":4619901, "ctx":"CatalogCache-2","msg":"Refreshed cached collection","attr":{"namespace":"test.test2","lookupSinceVersion":{"0":{"$timestamp":{"t":49182,"i":1}},"1":{"$oid":"626a663821072b82d9059209"},"2":{"$timestamp":{"t":1651140151,"i":6}}},"newVersion":{"chunkVersion":{"0":{"$timestamp":{"t":49182,"i":1}},"1":{"$oid":"626a663821072b82d9059209"},"2":{"$timestamp":{"t":1651140151,"i":6}}},"forcedRefreshSequenceNum":21,"epochDisambiguatingSequenceNum":18},"timeInStore":{"chunkVersion"::{"0":{"$timestamp":{"t":49182,"i":1}},"1":{"$oid":"626a663821072b82d9059209"},"2":{"$timestamp":{"t":1651140151,"i":6}},"forcedRefreshSequenceNum":20,"epochDisambiguatingSequenceNum":17},"durationMillis":896}}
说明:5.0测试集群采用最简单的id做片建,id取值范围0-100000000,路由数据非常简单,实际线上真实环境片建更加复杂,因此路由获取过程耗时实际上同等规模会更高。
4. MongoDB内核路由刷新核心实现流程
4.1. mongos全量路由刷新核心实现流程
● mongos获取全量路由触发条件
当cache中没有路由信息的情况下,客户端第一次通过mongos访问DB的时候,会触发mongos进行全量路由刷新。例如以下情况:
1、 mongos重启。
2、 db.adminCommand({"flushRouterConfig":1})清理metadata中的路由信息。
● mongos获取全量路由信息流程
主要流程步骤如下:
步骤1:mongos接受到客户端请求,按照二分查找方式,从路由元数据中获取请求对应的目标分片信息,确保请求转发到对应正确的分片。如果内存中有对应路由元数据则直接转发到对应分片,如果内存中没有路由信息,则从config server获取全量的路由信息。
步骤2:发送请求给config server,从config server获取请求对应表的所有chunk信息。
步骤3:批量获取config server返回的chunk路由信息,同时对所有chunk信息排序然后加载到内存中。
步骤4:从新按照二分查找方式,从获取的全量路由信息中获取客户端请求对应的目的分片信息,转发请求到匹配的目的分片。
步骤5:接收目的分片应答信息,转发分片获取到的数据到客户端。
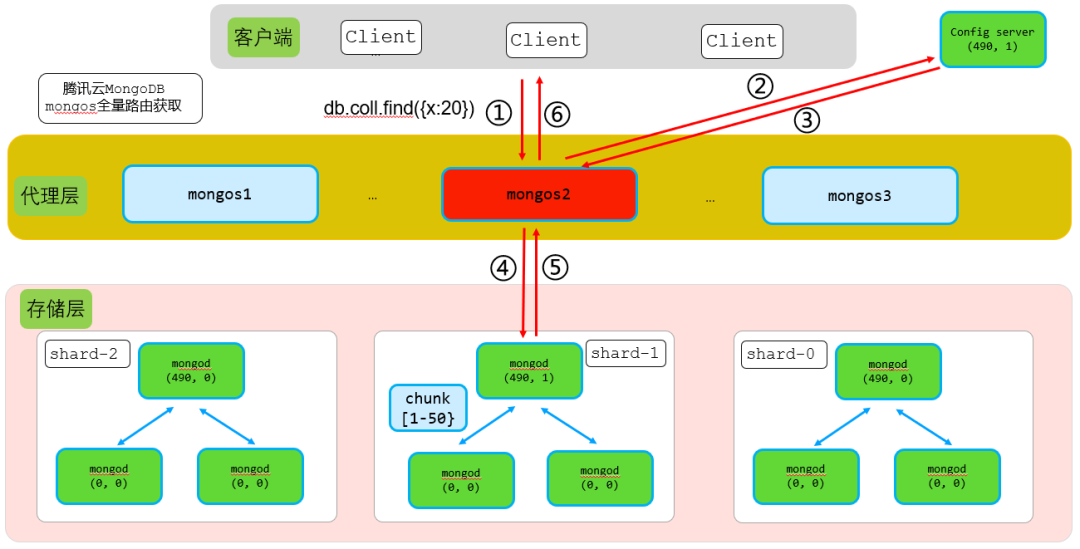
4.2. mongos增量路由刷新核心实现流程
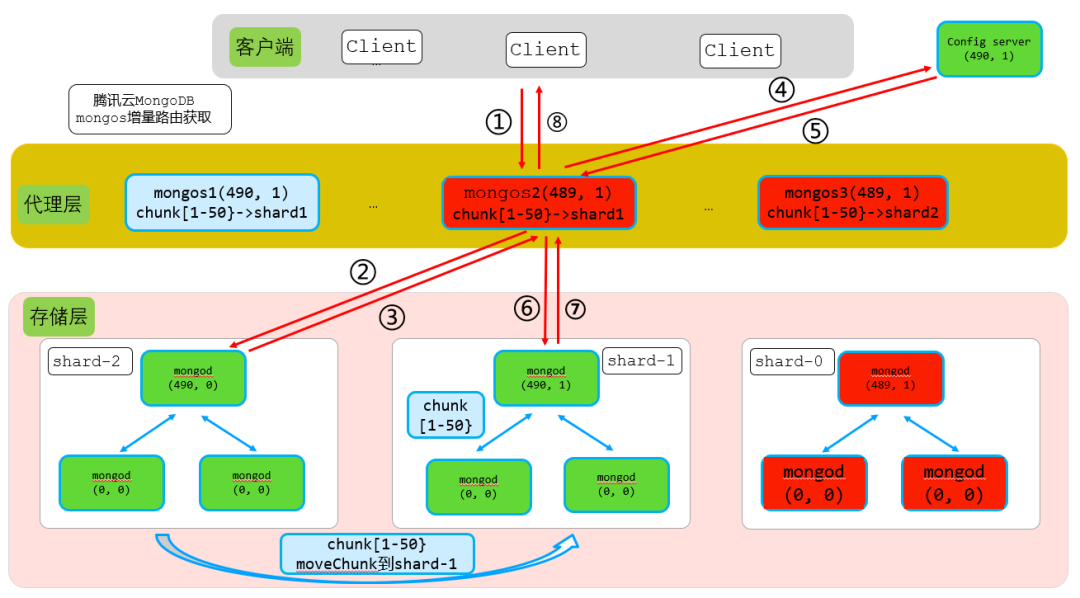
结合上图,假设客户端通过mongos2写入{x:20}这条数据,其执行步骤如下:
● 步骤1:客户端请求写入到mongos2
请求内容db.xx.insert({x:20})转发到mongos2。
● 步骤2:mongos2转发请求到对应分片,同时携带mongos2本地shardVersion
mongos2获取到请求后,查询本地路由,确定{x:2}这条数据对应chunk[1-50]在shard2,于是转发请求到shard2,同时携带上mongos本地的shardVersion(489,1)。
因此步骤2转发内容:db.xx.insert({x:20})+ shardVersion(489,1)。
● 步骤3:shard2主节点收到请求后,进行shardVersion版本检查
shard2主节点收到写入请求后,进行shardVersion版本检查。shard2主节点shardVersion大版本号为490,而收到的insert请求大版本号为489,这里即可判断从mongos2版本号较低,从而返回StaleConfig error信息给mongos2。
● 步骤4 + 步骤5:mongos2收到StaleConfig error信息,从config server获取最新的路由信息
mongos2收到shard2主节点返回的StaleConfig error信息,即可判断出本地的路由信息较旧,不是最新的路由信息,因此从config server获取最新的路由信息。
● 步骤6:mongos2获取到最新路由信息后,从新转发请求到正确的shard
mongos2获取到最新config server路由信息后,重新判断{x:20}这条数据对应chunk路由,确定该chunk[1-50}在shard1,因此从新转发请求到shard1主节点。同时携带最新的shardVersion(490,1),最终请求中包含最新路由信息。
因此步骤6转发内容:db.xx.insert({x:20})+ shardVersion(490,1)。
● 步骤7:shar1收到insert写入请求后路由检查判断
shard1主节点收到{x:20}这条数据写请求后,进行shardVerion主版本号检查,由于本次mongos2转发的请求主版本号和shard1主节点版本号相等,因此路由检查通过,直接写入数据,并返回写入结果。
● 步骤8:转发写入结果给客户端
mongos2直接转发shard1写入结果返回给客户端。
4.3. mongod主节点全量路由刷新核心实现流程
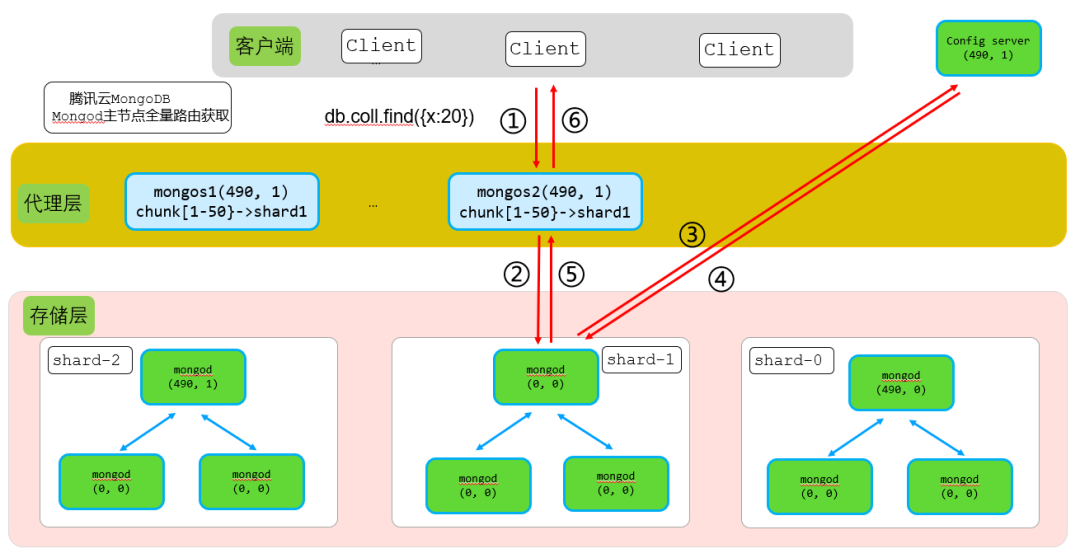
结合上图,当分片1主节点重启,或者从节点主从切换到没有路由元数据的节点后,内存中的路由元数据丢失,这时候mongos转发客户端请求到该节点就需要全量路由刷新。
假设客户端通过mongos2写入{x:20}这条数据,mongod全量路由刷新流程执行步骤如下:
● 步骤1:客户端请求写入到mongos2
请求内容db.xx.insert({x:20})转发到mongos2。
● 步骤2:mongos2转发请求到对应分片,同时携带mongos2本地shardVersion
mongos2获取到请求后,查询本地路由,确定{x:2}这条数据对应chunk[1-50]在shard2,于是转发请求到shard2,同时携带上mongos本地的shardVersion(490,1)。
因此步骤2转发内容:db.xx.insert({x:20})+ shardVersion(490,1)。
● 步骤3+步骤4:shard2主节点收到请求后,进行shardVersion版本检查
shard2主节点收到写入请求后,进行shardVersion版本检查。shard2主节点shardVersion大版本号为0,也就是没有路由信息,而收到的insert请求大版本号为490,这里即可判断从mongos2版本号比本地版本高,从而从config server获取全量路由。
分片2主节点从config server拿到所有全量路由信息后,持久化到本地cache.chunks.db.collection表中,同时缓存路由元数据到cache中。
● 步骤5:转发获取到的数据给mongos,同时携带最新的路由版本
mongod拿到全量路由后,再次检查mongod最新版本号shardVersion(490,1)和mongos携带的版本号shardVersion(490,1),两则一致。然后,访问DB获取请求对应数据,然后转发给mongos,同时携带最新的shardVersion(490,1)。
因此步骤5转发内容:db.xx.insert({x:20})结果信息+ shardVersion(490,1)。
● 步骤6:mongos接收mongod应答的数据再次进行版本检查,版本一致直接应答客户端请求结果
mongos收到insert{x:20}请求结果,进行shardVerion主版本号检查,版本一致,直接转发结果给客户端。
4.4. mongod主节点增量路由刷新核心实现流程
主节点增量路由刷新及版本检查过程和主节点全量刷新流程几乎一样,只是步骤三和步骤四只是从config server获取增量变化的路由信息。
4.5. mongod从节点全量路由刷新核心实现流程
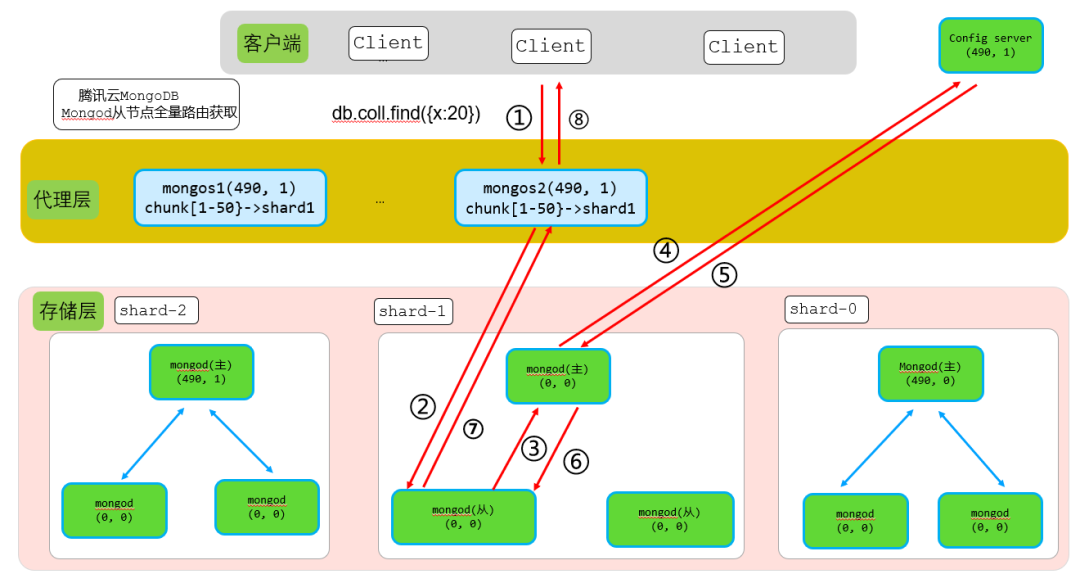
如果客户端请求做了读写分离配置,则mongos会携带请求及mongos本地版本号转发到分片从节点。
5.0版本mongos如果检查客户端请求没有携带{readConcern: { level: "local" }}配置,则默认在代理层添加该配置,因此从节点默认会进行路由版本检查。
如果从节点刚重启则内存中不会有路由版本信息,这时候从节点就需要从config server获取最新的全量路由信息。从节点获取全量路由信息过程由从节点触发,从节点在步骤3发送_flushRoutingTableCacheUpdates命令给主节点,主节点收到该请求后从config server获取最新的路由信息(注意:如果主节点这时候本地已获取过路由信息,则步骤4只需要获取增量路由即可)。
相比主节点获取全量路由逻辑,从节点获取最新全量路由增加步骤3和步骤6两个过程,分别如下:
步骤3:发送_flushRoutingTableCacheUpdates命令给主节点,通知主节点获取最新路由信息。
步骤6:从节点通过主从同步获取到最新路由信息,首先持久化到本地,然后加载到内存中。
4.6. mongod从节点增量路由刷新核心实现流程
从节点增量路由刷新及版本检查过程和从节点全量刷新流程几乎一样,只是加载增量的持久化数据到内存中。
5. mongodb内核路由核心代码实现及其性能瓶颈
本文的内核代码核心实现基于5.0分析,实际上在5.0以下版本这部分功能实现原理大同小异,只是代码做了重新迭代,代码实现架构有些优化,代码修改比较大。
5.1. mongos全量路由获取代码核心实现及其性能瓶颈
5.1.1. mongos全量路由获取核心代码实现
分片路由代码量巨大,这里只分析影响性能的核心流程,获取全量路由代码核心实现流程如下:
步骤1:加锁+异步线程池方式从config server获取的全量路由chunk存入一个临时vector
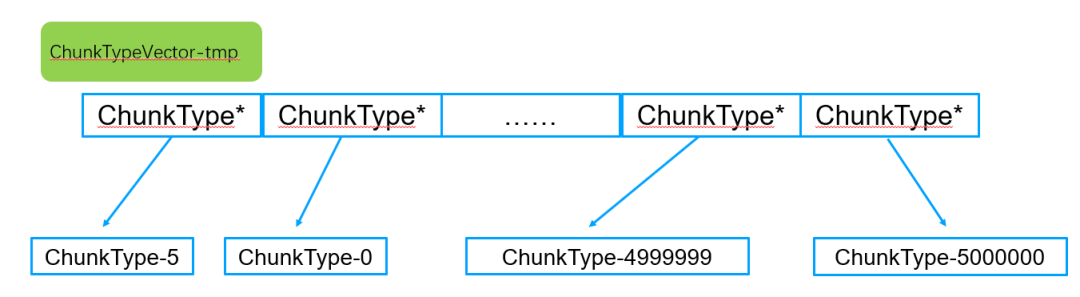
异步线程获取到一批数据后,申请内存存入临时vector。注意这时候vector中的chunk是按照lastmode排序的,也就是vector中的chunk的min和max是乱序的。
步骤2:对临时vector中的所有ChunkInfo按照maxKey进行排序
由于从config server获取到的chunk是按照lastmode排序的,不是按照maxKey排序,因此这里需要对指针vector排序方法按照makKey从大到小排序。
步骤3:反转临时vector,实现vector按照maxKey从小到大顺序。
vector反转std::reverse,然转后的临时vector是按照maxKey从小到大排序的。
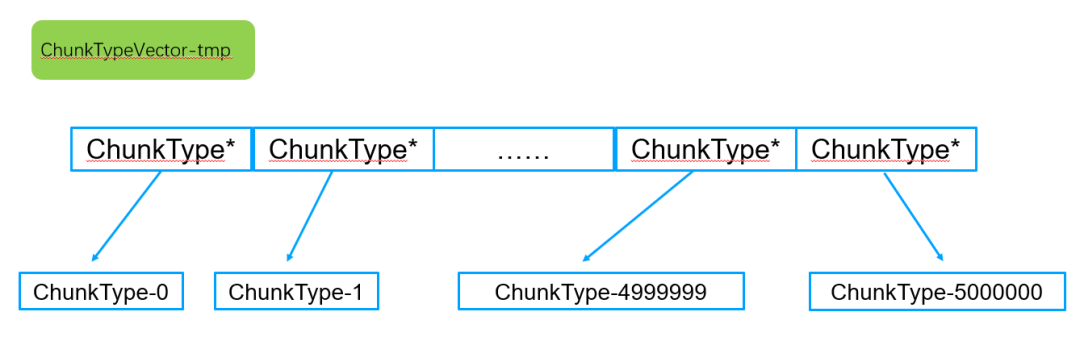
步骤4:遍历排序好的临时vector,拷贝数据到新的ChunkVectorvector中
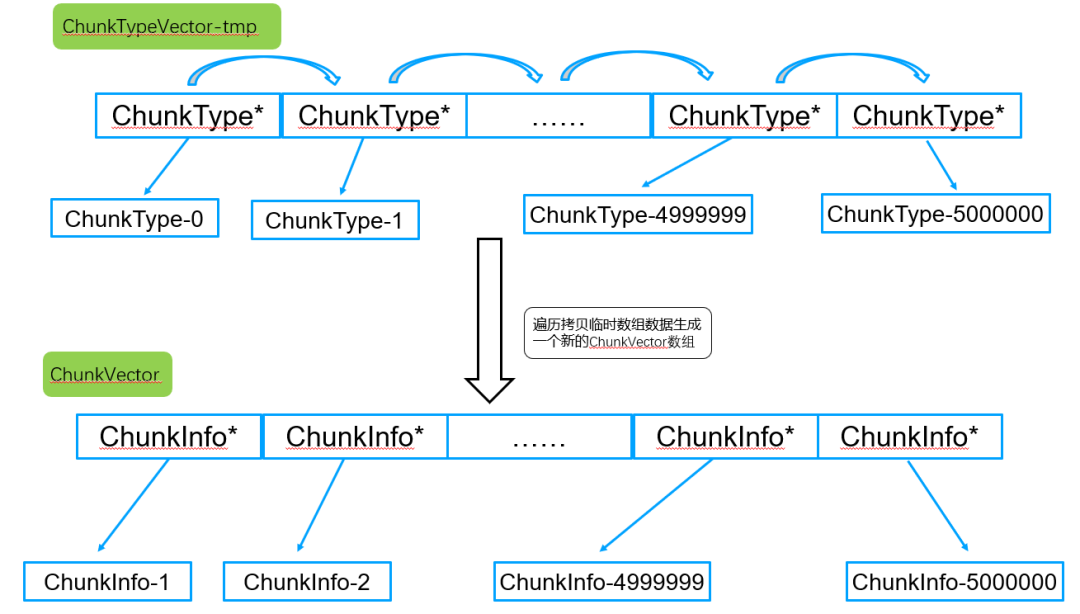
步骤5:遍历ChunkVectorvector,生成每个分片的shardVersion。
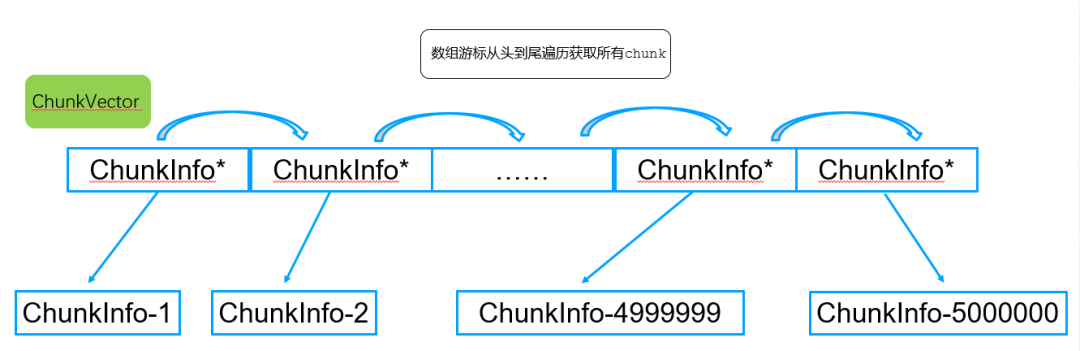
为了获取每个分片的shardVersion,因此需要遍历vector中所有ChunkInfo,通过遍历vector最终获取到每个路由chunk信息。
拿到每个chunk信息后,计算获取每个shard分片的最新路由版本号,所有分片的路由版本号存入hash-map表中,如下图所示:
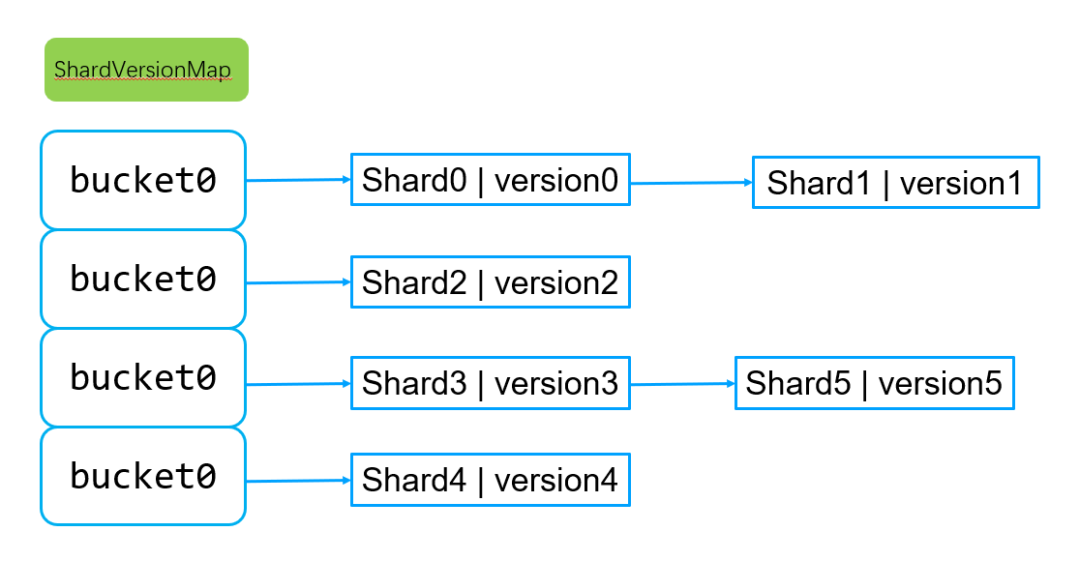
分片shard及其shardVersion分布对应hash表的key和value,由于一个集群shard分片总数一般做多也就百来个,shard不需要排序,因此采用hash存储最佳,查找速度也最快。
遍历过程除了生成每个分片的shardVersion,还会生成collectionVersion为所有分片shardVersion中最大的,如下图所示:
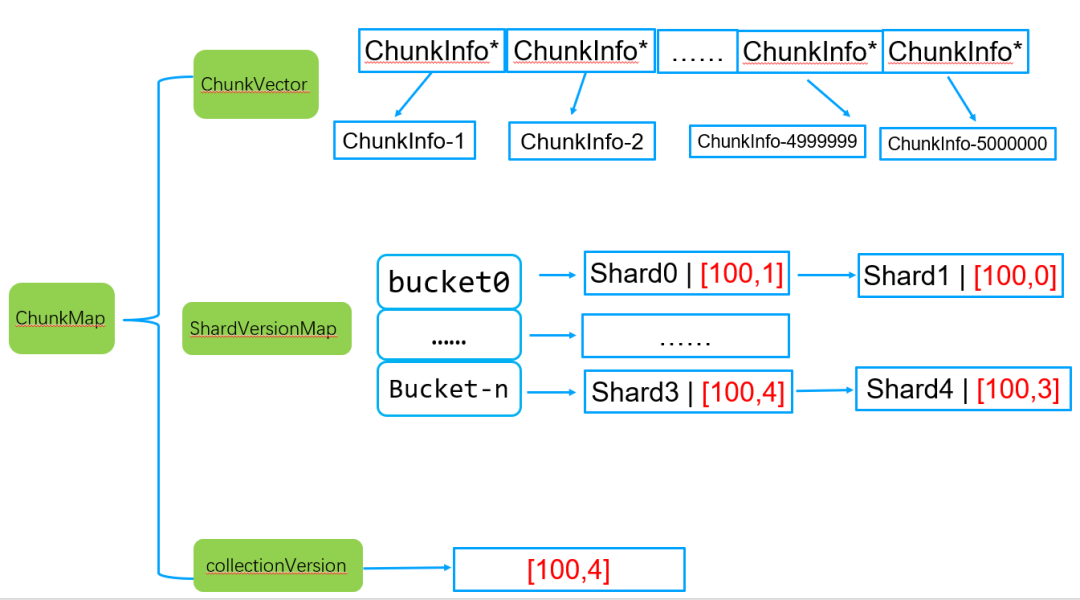
步骤6:根据全量路由+分片shardVersion+collectionVersion生成一个chunkMap路由元数据信息,同时交由MetadataManager统一管理
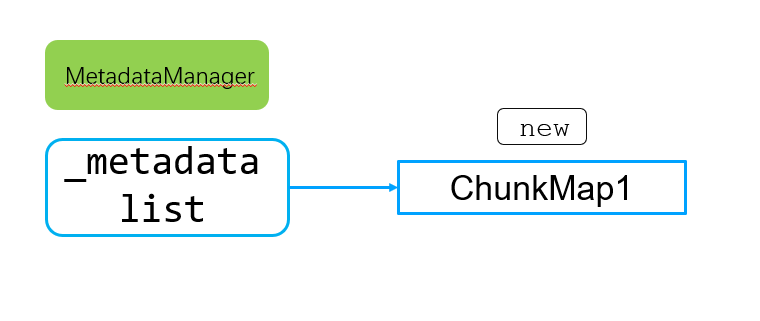
chunkMap最终交由MetadataManager统一管理,存储到_metadata链表中,同时交由LRU进行过期管理。
说明:这里涉及到非常复杂的线程运行时、元数据转换等逻辑,由于这些逻辑不影响性能,这里不详述。
5.1.2. mongos全量路由获取瓶颈点
mongos重启获取全量路由过程主要耗时点如下:
1. 从config server批量拉数据,100T数据规模的chunk数约500W,拉数据过程需要耗时。
2. 500万数据存入临时vector,并且按照maxKey进行排序+vector反转需要耗时
3. 遍历500万chunk的临时vector,拷贝500万数据生成新的chunkVector需要耗时。
4. 遍历500万chunk的chunkVectorvector生成shardVersion需要耗时。
从上面的分析可以看出,除了从config server批量拉数据流程外,整个流程需要多次数据拷贝和遍历。
5.2. mongos增量路由获取代码核心实现及其性能瓶颈
5.2.1. mongos增量路由核心代码实现
假设某一时刻mongos1触发某个chunk从一个分片move到了另一个分片,则这个chunk的大版本号会增加,这时候变化的chunk只有一个。通过mongos2访问这个chunk数据的时候就会触发mongos2对该chunk的增量拉取过程,mongos2增量拉取路由的核心流程如下:
步骤1:从config server获取这个变化的chunk。
根据本地的collectionVersion,获取config server中lastmode大于collectionVersion的所有元数据,假设这里增量只有一个chunk。
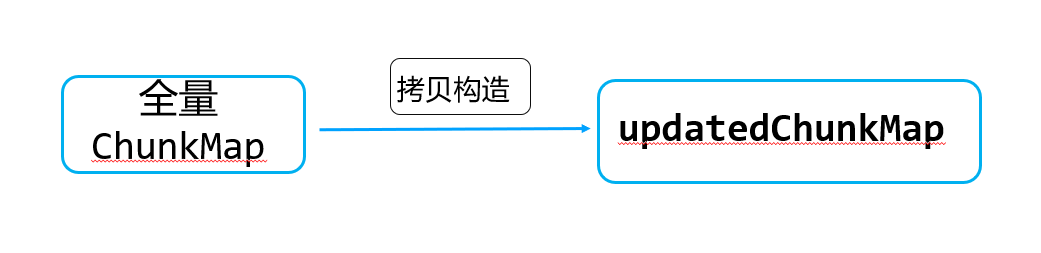
步骤2:获取cache中全量的chunkMap,拷贝一份完全一样的临时updatedChunkMap
chunkMap中的ChunkVector包含500万个路由chunk,这里实际默认构造函数会申请500万新的chunkInfo,并进行内容拷贝。
此外,还会进行collectionVersion和ShardVersionMap的拷贝。
步骤3:遍历updatedChunkMap中的ChunkVector动态vector成员,添加增量数据到vector中的合适位置
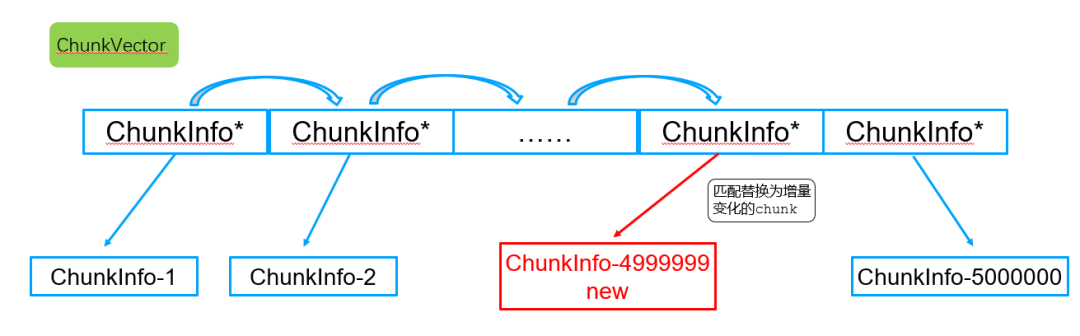
在遍历updatedChunkMap中的ChunkVector前为了避免vector空间不够引起的数据移动拷贝迁移,因此会对vector提前reserve空间,保证其可以容纳增量数据。
根据已有的全量数据和新的增量数据,最终生成一个完整的新的ChunkVector。
此外,该过程还会比较增量chunk和collectionVersion,如果chunk路由版本比collectionVersion版本高,则更新collectionVersion版本。
到这里,根据历史全量路由数据+新的增量数据,ChunkVector和collectionVersion(即ShardVersionMap)到这里就构建好了。
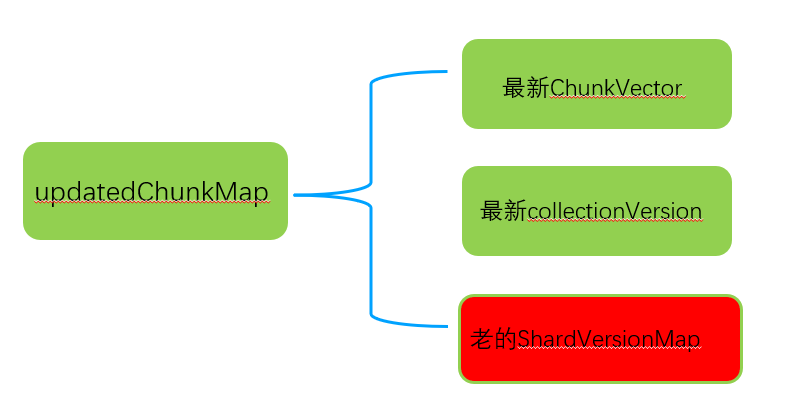
步骤4:再次遍历updatedChunkMap中的ChunkVector成员,重新生成最新的ShardVersionMap
重新遍历updatedChunkMap.ChunkVector中的所有chunkInfo数据,生成该表最新的shardVersion hash表,存储到updatedChunkMap.ShardVersionMap成员中。如下图所示:
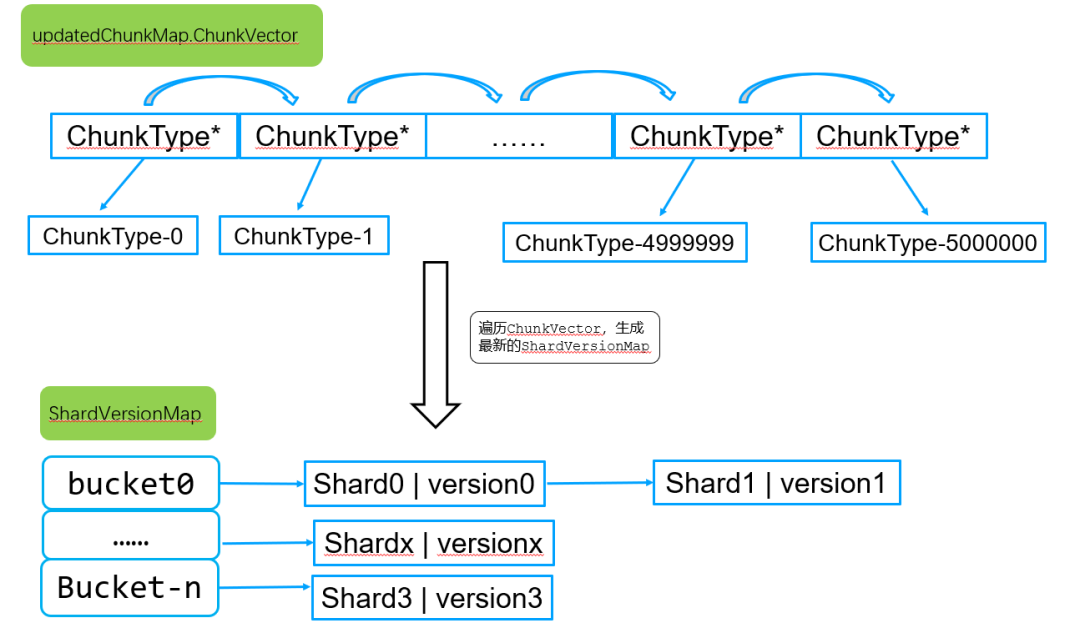
到这里,一个完整的updatedChunkMap形成了,如下图所示:
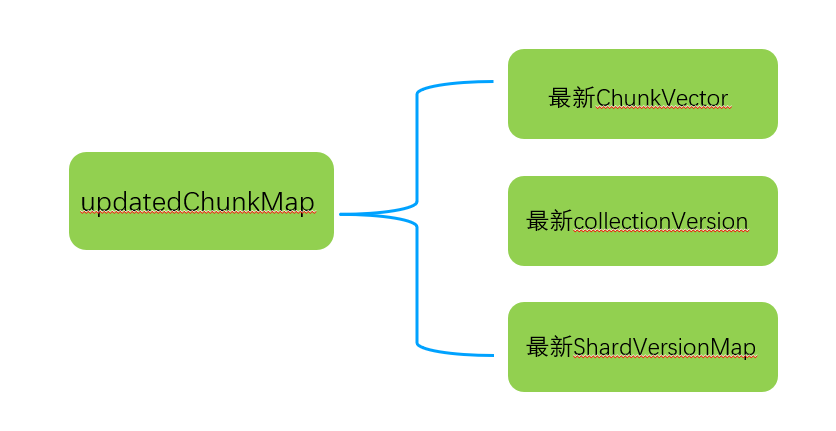
步骤5:根据全量路由+分片shardVersion+collectionVersion生成一个新的chunkMap路由元数据信息,同时交由MetadataManager统一管理。
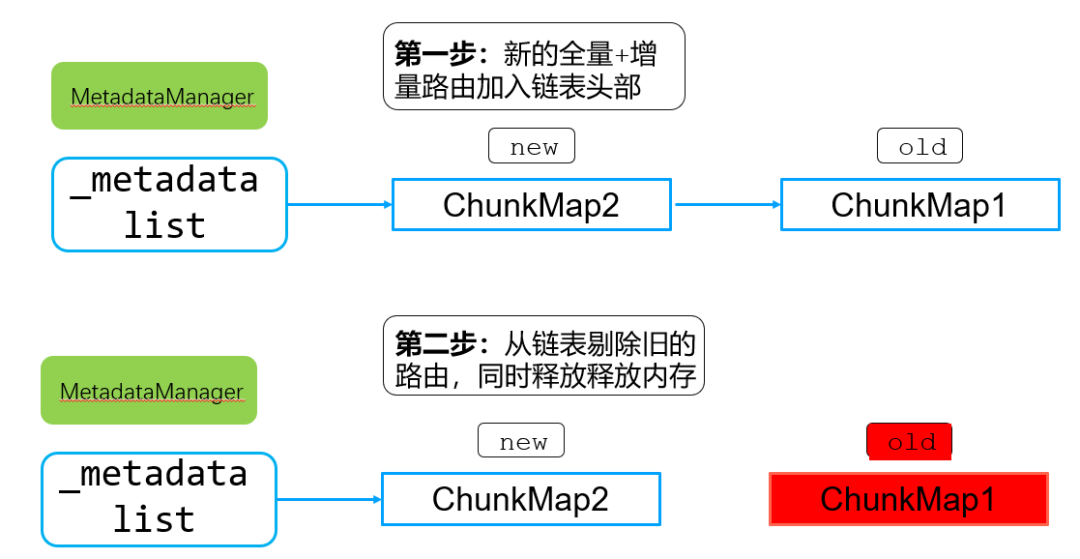
新的updatedChunkMap加入到_metadata这个链表头部,同时删除链表尾部旧的chunkMap,当旧的chunkMap引用计数为0后,自动释放所有chunkInfo占有的内存。
5.2.2. mongos增量路由瓶颈点
从上一节增量路由核心实现流程可以看出,即使是单个增量chunk获取,这里也存在1次全量chunkMap拷贝,2次ChunkVector遍历,1次历史chunkMap回收。
● 瓶颈点1:chunkMap拷贝
mongodb路由采用read copy update机制,需要copy全量chunkMap到新的updatedChunkMap中。由于chunkMap.ChunkVector中存在500万路由chunk,这个拷贝过程持续时间比较耗时。
● 瓶颈点2:根据chunkMap+增量chunk生成新的chunkMap时候,需要遍历
获取到增量chunk后,需要遍历原有的所有ChunkVector中的路由信息,对updatedChunkMap进行更新操作,500万ChunkVector遍历过程比较耗时。
● 瓶颈点3:metadata链表中管理的历史ChunkVector回收,需要遍历+内存释放
metadata链表中会管理历史的全量路由信息,当新的chunkMap生成后,旧版本的chunkMap需要释放,其中的ChunkVector释放,实际上是遍历vector一个节点一个节点释放,因此释放历史版本chunkMap统一非常耗时。
5.3. 分片mongod全量及增量路由获取代码核心实现及其性能瓶颈
5.3.1. 分片mongod全量路由获取核心实现及瓶颈点
mongod(不管是主节点还是从节点) chunkMap生成过程和mongos过程类似,只是多了持久化的过程,该过程无性能瓶颈,因此这里不详述。
5.3.2. 分片mongod增量路由获取核心实现及瓶颈点
mongod(不管是主节点还是从节点) chunkMap生成过程和mongos过程类似,只是多了持久化的过程,该过程无性能瓶颈,因此这里不详述。
5. MongoDB内核增量刷新优化方法(二维vector排序及搜索)
原生版本从3.4到最新6.0在路由刷新这里使用了map->bsonmap->vector等持续迭代,每次迭代性能都有一定提升,但是提升后增量路由获取还是秒级的,因此需要一种更好的办法来解决增量路由刷新引起的抖动问题。
增量路由变化,即使是一个chunk发生变化,增量路由刷新都需要对全量ChunkVector中的chunkInfo指针遍历;同时生成shardVersion的时候还需要重新遍历整个ChunkVector,整个过程非常耗时,任何操作都需要对全量ChunkVector进行操作。
由于增量chunk都比较少,我们是否可以做到只对少部分chunk做变更,避免对全量ChunkVector中的所有chunk做遍历呢?可以通过二维vector排序及搜索来彻底解决该问题,如下:
5.2.1. 全量路由存储结构-二维vector排序生成
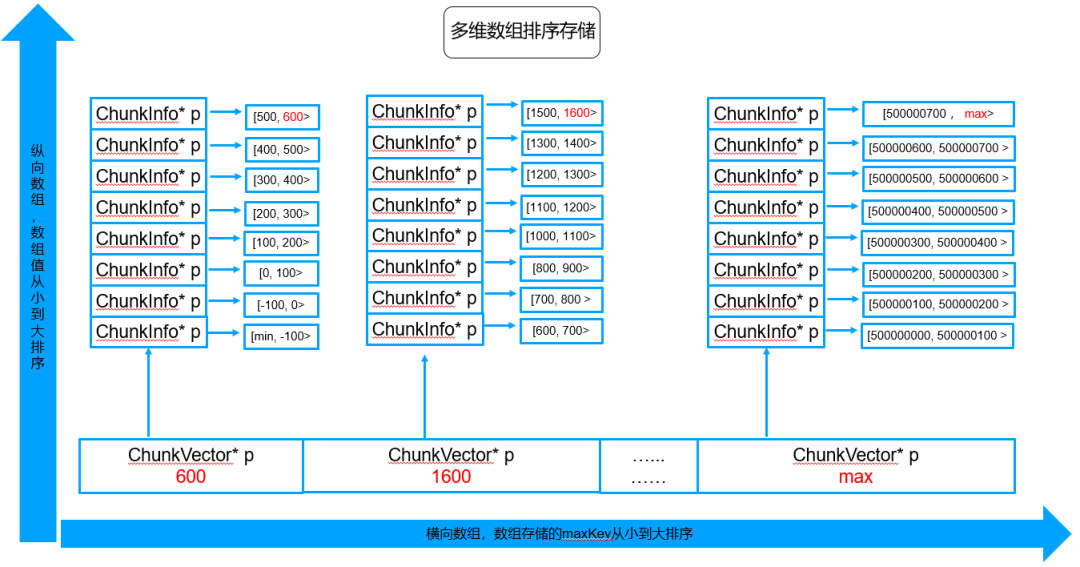
这里假设以最简单的用户id做片建,id是一个<min, max>区间的整数,总共500W个chunk,每个chunk占用一个ChunkInfo指针节点。线上真实集群片建、路由更加复杂,但是实际上原理是一样的。
说明:途中的chunkInfo只给出来路由的范围区间信息,实际上chunkInfo还会记录该路由所在shard、路由版本信息等,图中没有体现。按照maxKey获取到对应chunkInfo,即可获取到shard、路由版本等信息。
首先,定义几个概念:
● 横向vector
horizontalVector:横向vector,主要存储每个纵向vector中最大得maxKey,vector按照maxKey从小到大排序。横向vector定义:std::map< std::pair<std::string, ChunkVector *> >。
说明:为了方便画图理解,横向的map使用vector替代。
● 纵向vector
verticalVector:纵向vector,主要对全量路由进行分区存储排序,vector中的chunkInfo按照maxKey从小到大排序。纵向vector定义:std::vector<std::shared_ptr<ChunkInfo>>
● 横向搜索游标
horizontalCursor:横向搜索游标,主要通过二分查询来快速定位需要查询的纵向vector成员位置。
● 纵向搜索游标
verticalCursor:纵向搜索游标,主要通过二分查找来快速定位指定纵向vector中的某个chunkInfo。
此外,全量路由存储结构更新时候会实时进行_shardVersions、_collectionVersion计算更新,保证和config server中的具体shard版本信息、集合版本信息完全一致,避免再次通过全量遍历计算生成。
5.2.2.二维vector查询-精确查询+范围查询
● 精准查询类
例如查询db.xxx.find({id:805})的数据,这时候就需要查找id=805这个查询对应路由信息,通过这个路由即可拿到该数据对应的shard信息,这样就直到应该转发到那个shard。精确查找过程如下图所示:
第一步:横向查询,确定对应纵向vector游标
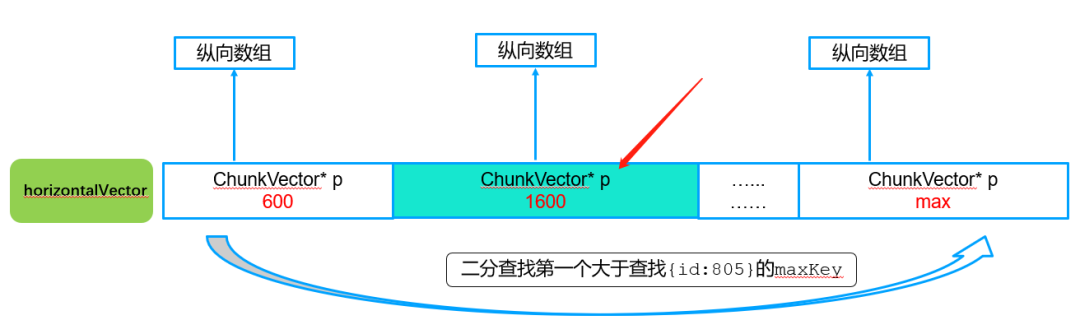
横向查找算法:按照二分查找方式找到第一个大于805的vector游标节点,这里也就是1600这个pair。
第二步:纵向查询,确定对应纵向vector游标
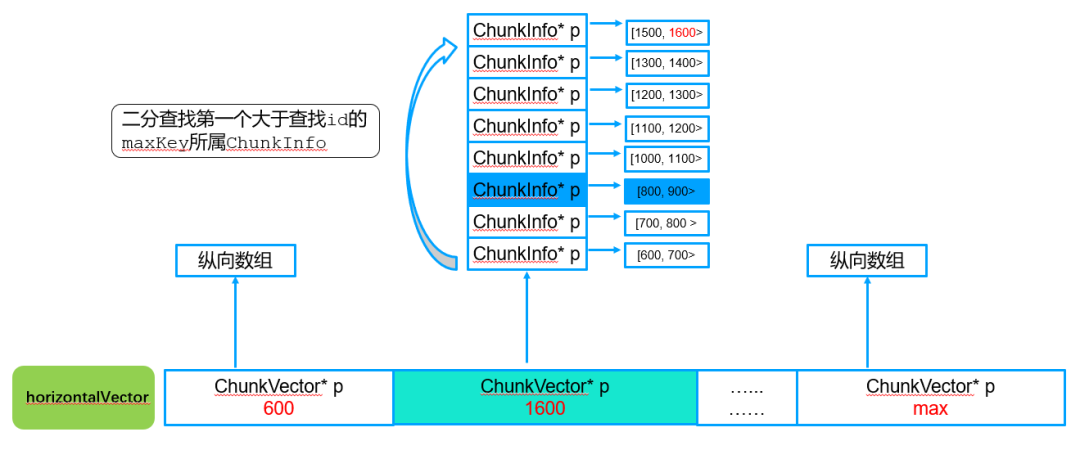
纵向查找算法:按照二分查找算法找到第一个大于805所属的chunkInfo。
● 二维vector查询-范围查询
例如查询db.xxx.find({id:{$gte:505, $lte:805})的数据,这个vector横跨在两个纵向vector中,其查找过程如下:
第一步:横向查询,确定对应横向vector游标边界
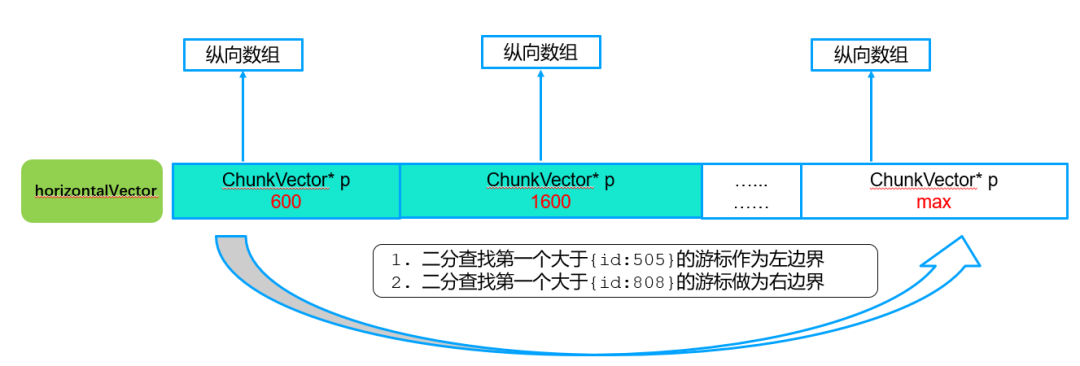
查找算法:确定范围查询的游标左边界和右边界,按照二分查找确定。
第二步:纵向查询,确定对应纵向vector游标边界
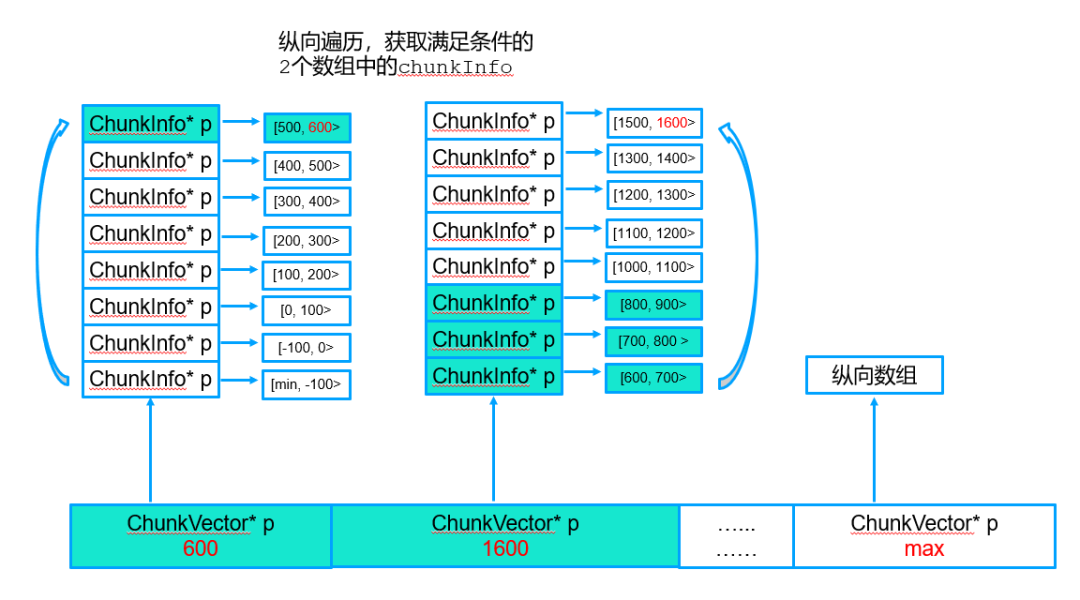
查找算法:纵向遍历,获取满足条件的2个vector中的chunkInfo。
5.2.3. 增量路由快速构建ChunkMap (只遍历一次增量数据所在的纵向vector,避免2次全量遍历)
原生的实现需要对全量路由进行一次拷贝,拷贝完后进行增量更新。新的二维vector增量更新只需要找到对应的纵向vector进行拷贝,然后进行增量更新。
假设增量刷新获取到2个增量路由,分别为chunk[800-850>和chunk[850-900>,增量路由快速构建ChunkMap主要步骤:
第一步:拷贝横向指针vector,纵向指针vector共享
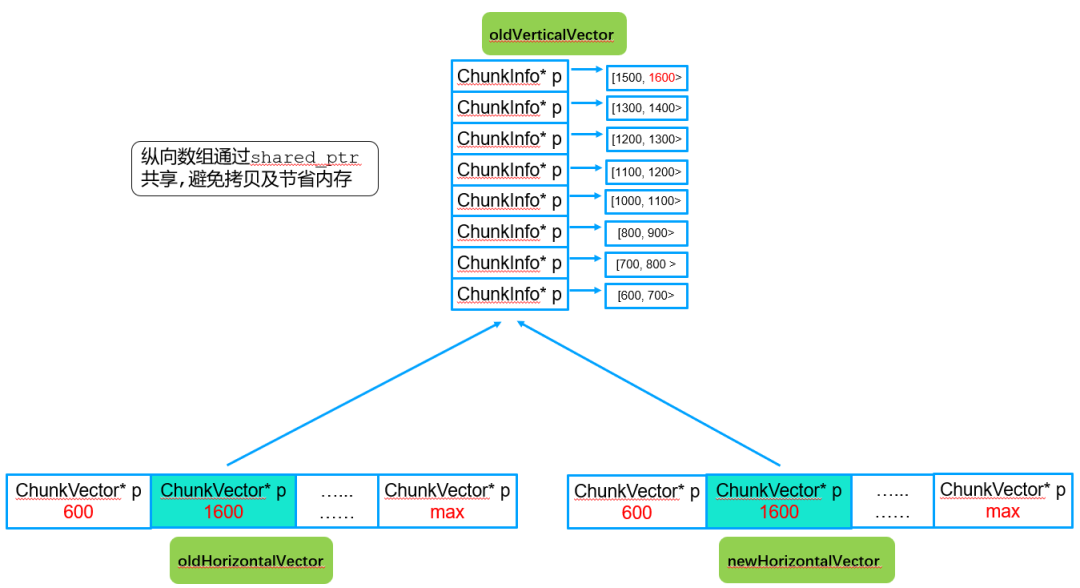
为了提升性能和节省内存,这里采用指针方式实现纵向数组共享,只占用一份内存资源,同时可以避免数组遍历和拷贝。
步骤2:根据原始oldVerticalVector及增量变化chunk生成最新合并后的newVerticalVector
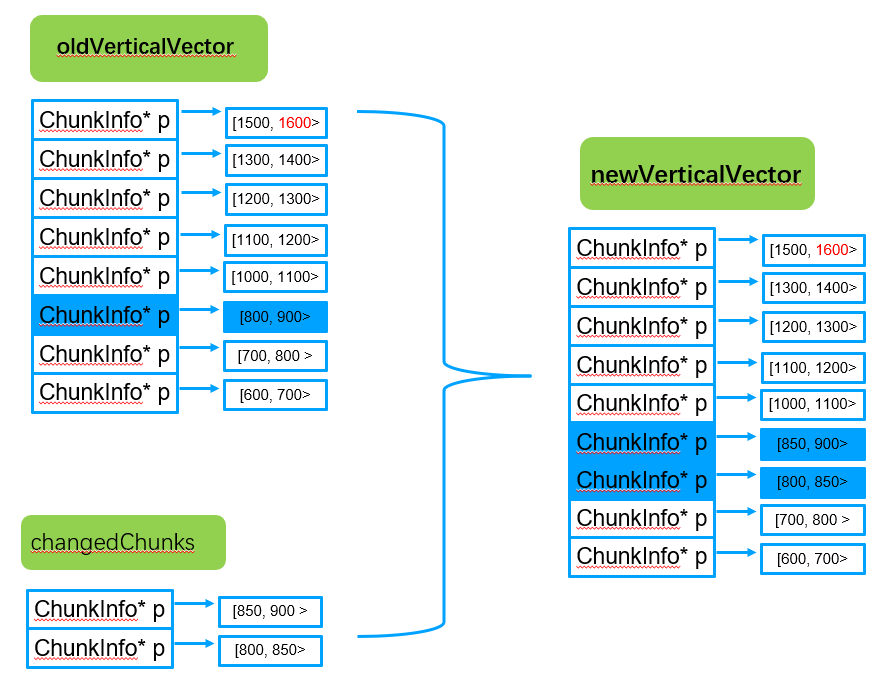
为了避免vector的插入移动拷贝,newVerticalVector采用提前vector分片成员空间,以排序入桶的方式实现,达到性能的最大化。
此外,这个_shardVersions、_collectionVersion在该步骤生成新的纵向数组的时候会实时进行_shardVersions、_collectionVersion更新赋值,保证其值与config server中的实时一致,同时避免了原生版本中的全量遍历。
步骤3:横向vector中对应的成员指针指向新的newVerticalVector
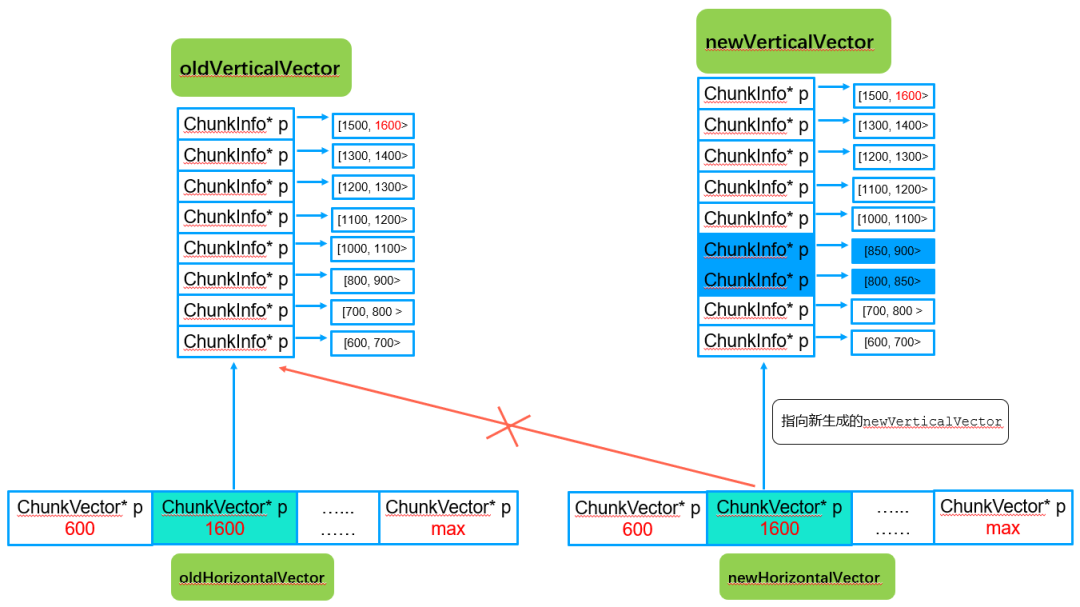
通过该步骤后,newHorizontalVector对应的横向数组中的指定指针指向新的newVerticalVector。
注意:除了变化的纵向vector,其他纵向vector都是共享的,只存储一份。
步骤4. RoutingTableHistory的_chunkMap指向新的newchunkMap
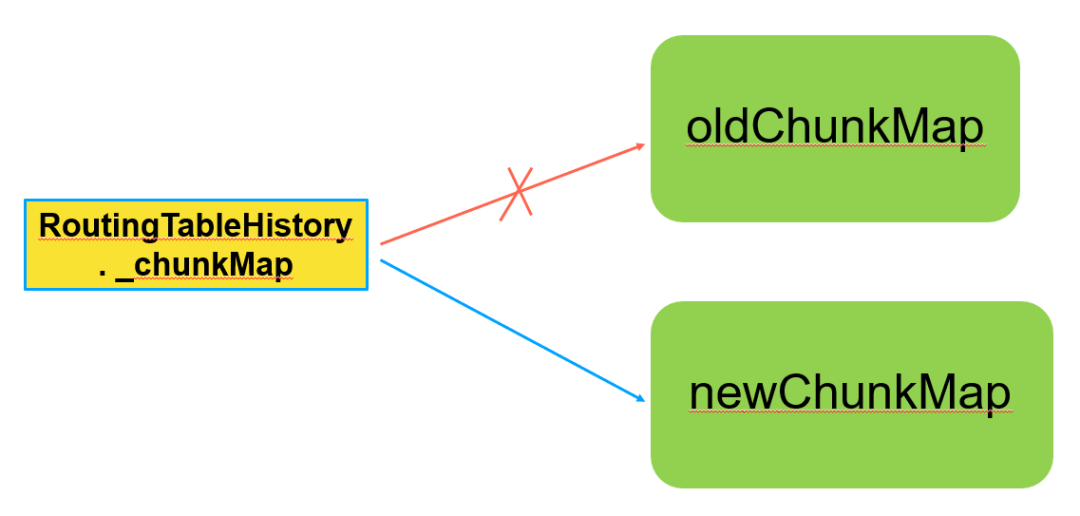
● oldchunkMap:
所有oldHorizontalVector+所有oldVerticalVector结构组成的全量数据结构。
● newchunkMap:
所有newHorizontalVector+无变化的纵向vector+oldVerticalVector结构组成的全量数据结构。
步骤5. 释放oldHorizontalVector横向vector中的共享指针,智能指针引用计数回收,所有纵向vector由newHorizontalVector接管
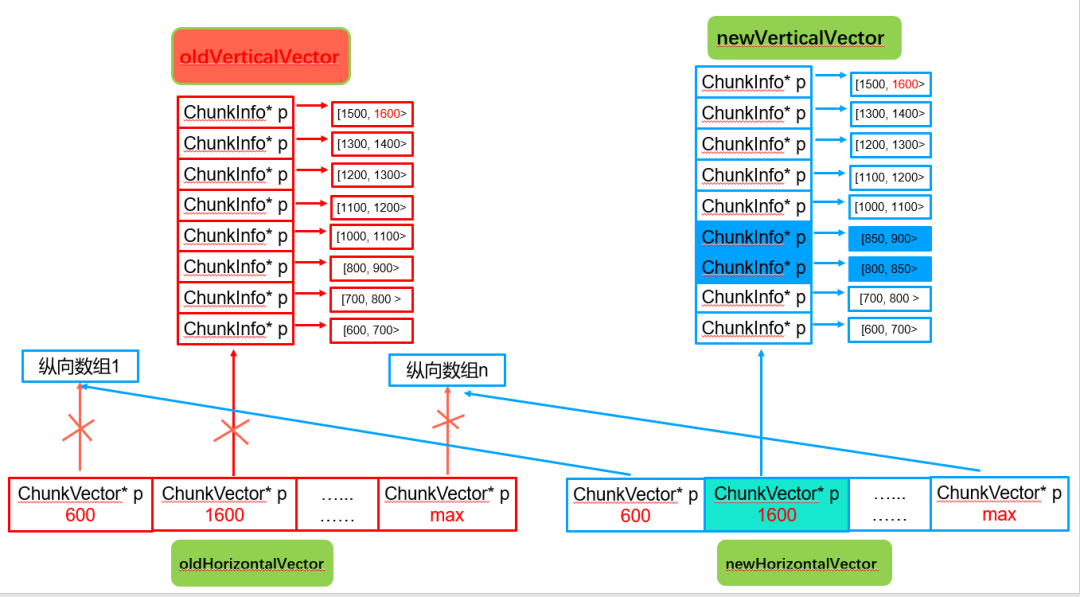
从这一节可以看出,由于增量路由都是变化的路由,变动比较小,因此遍历和回收也只会进行纵向vector中一个或者几个vector的拷贝,从而避免了全量chunk的数据拷贝和遍历。
此外,历史路由回收也由之前的全量旧版本路由指针回收变为增量变化的横向vector回收,整体回收量也由之前的全量500W路由指针回收变为横向数组指针数组的回收,性能也就大大提升了。
5.2.4. 纵向vector拆分及自平衡,纵向vector深度配置支持
随着增量刷新的不断进行,可能存在纵向vector中的chunk数差距很大的情况,例如下面的现象:
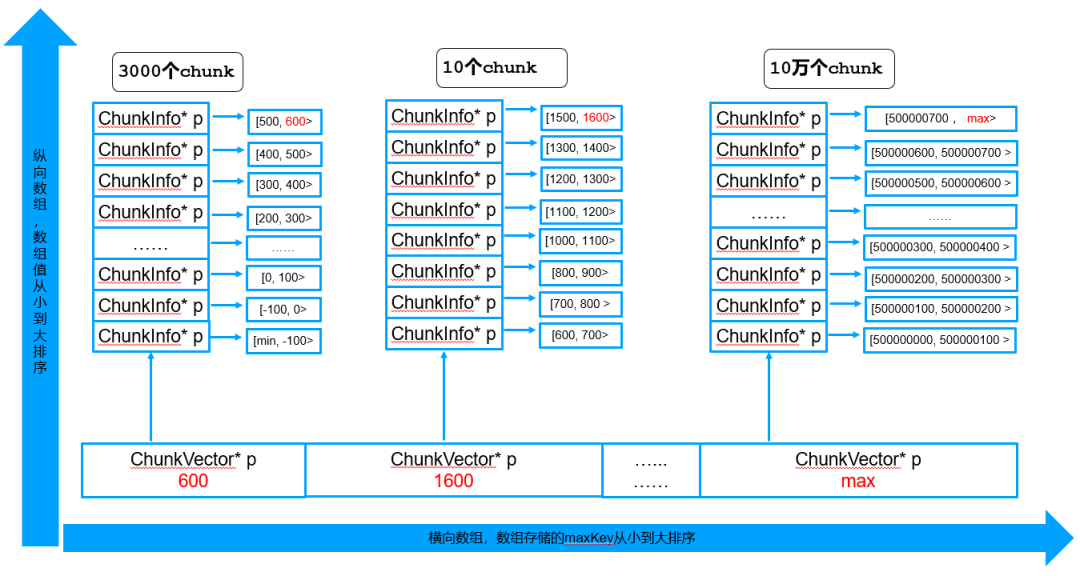
为了确保纵向vector的深度(即纵向vector中chunkInfo数,或者纵向vector大小)的平衡,避免部分纵向vector深度过高引起的大量数据遍历及拷贝,因此考虑如下优化:
● 增加纵向深度参数配置
启动参数增加CatalogCacheRefreshVectorVerticalDepth配置,默认深度500。
● 全量路由刷新时候纵向深度为默认值/2
全量路由刷新为了避免触发纵向vector自平衡引起的chunk移动,因此只使用配置深度的一半。
● 增量路由突破纵向深度大小后,进行自平衡(一个500 chunk的纵向vector->2个250 chunk的纵向vector)
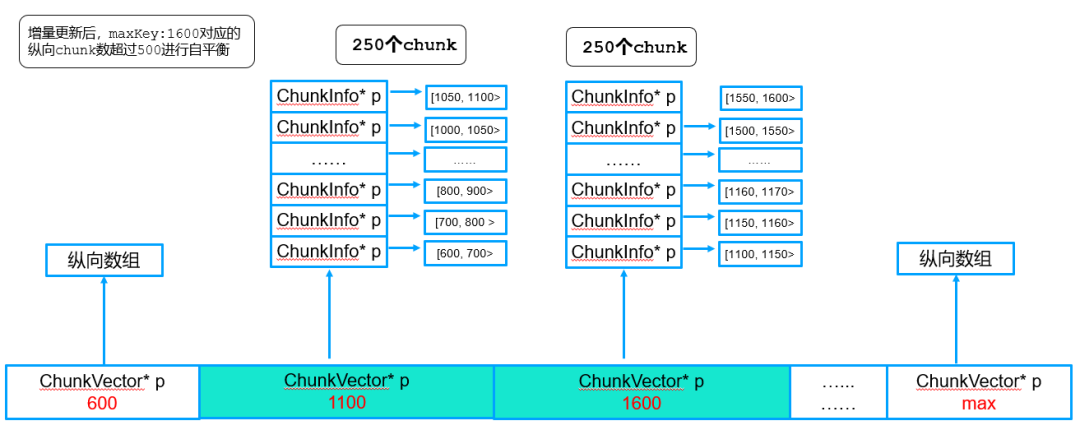
5.2.5. 纵向vector合并(mergeChunk)
纵向vector合并包括单维度合并和多维度合并,具体实现如下:
● 单维度chunkMerge
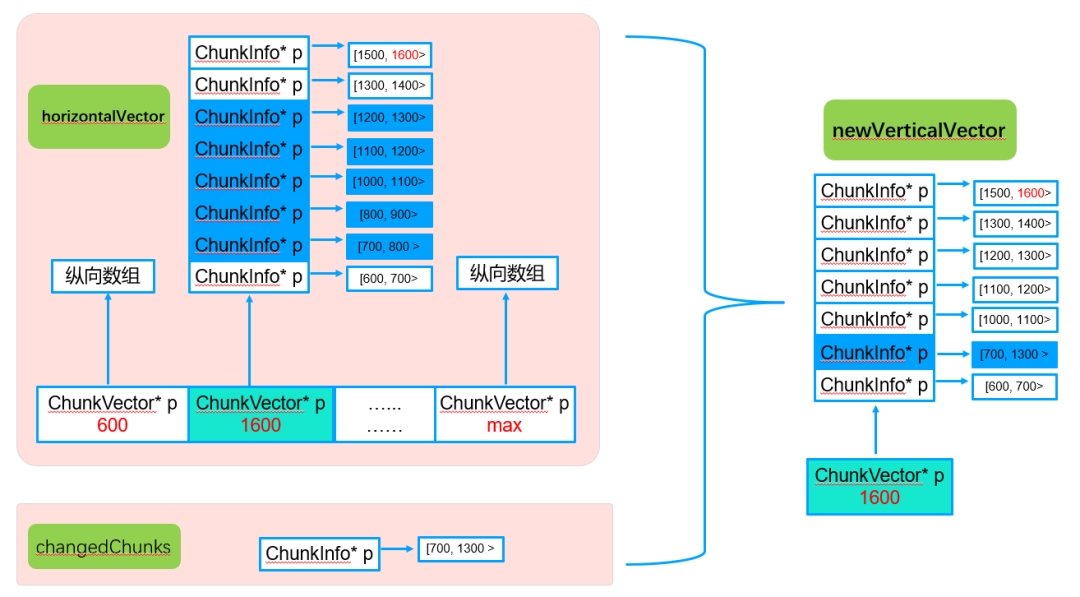
● 多维度chunkMerge
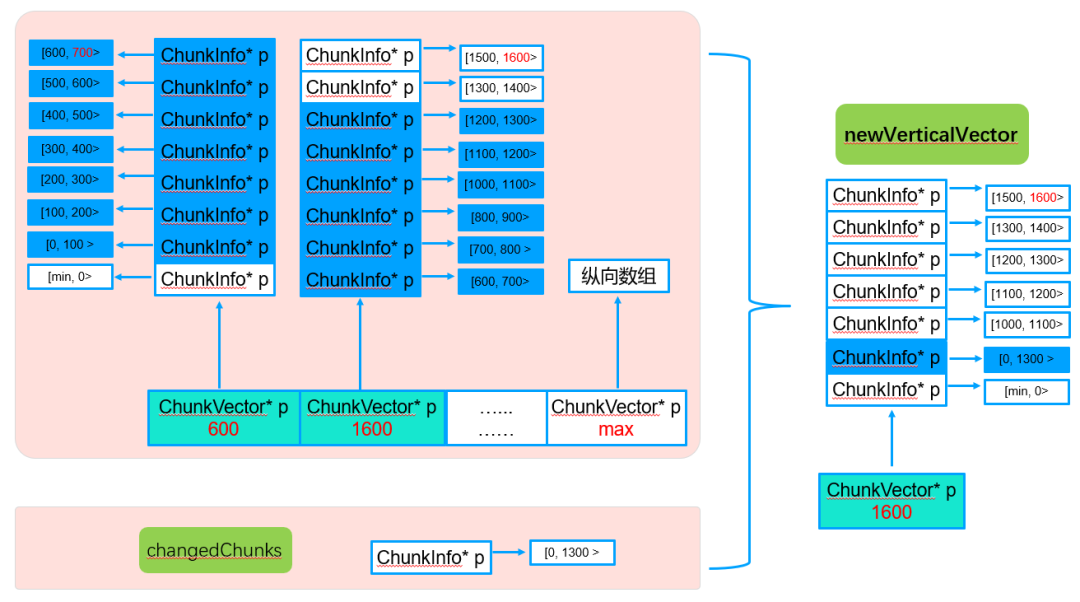
5.2.6. 路由有效性检查
当纵向vector更新或者发生结构变化,需要对增量引起的纵向vector进行有效性检查,主要包括以下几个检查项:
● 相邻chunk边界连续性检查
检查方式:前一个chunk的max和后一个chunk的min相等。
● epoch检查
检查方式:增量变化的chunk的epoch必须和表所在epoch相等。
● 版本号检查
检查方式:增量变化的chunk的version版本必须大于等于已有的最大chunk版本号。
● MinKey、MaxKey检查
检查方式:chunkMap表中最小的Chunk版本号必须为MinKey,最大chunk版本号必须为MaxKey。
6. 增量路由优化收益及性能数据对比
增量路由刷新可实现性能数百上千倍性能提升,彻底解决分片集群chunks较多时引起的抖动。
● 腾讯云路由优化后效果:
内核版本 | 数据量 | Chunk数 | 原生版本时延 | 优化后时延 | 性能提升结果 |
3.6 | 80T | 450W | 4500ms | 2ms | 提升2200倍 |
4.0 | 1.2T | 25W | 300ms | 2ms | 提升150倍 |
4.2 | 25T | 150W | 1200ms | 2ms | 提升600倍 |
5.0(测试数据) | 30T | 200W | 750ms | 2ms | 提升450倍 |
5.0(测试数据) | 100T | 600W | 2400ms | 2ms | 提升1200倍 |
腾讯云MongoDB团队路由优化后,不管集群规模多大,增量路由获取都维持2ms左右,这两毫秒实际上主要消耗在从config server获取增量路由的流程中,实际优化的ChunkMap替换过程小于2ms,单独对比ChunkMap优化过程,实际性能提升倍数远比表中的高。
● 优化前后日志对比(600W chunk)
1. 优化前访问日志:
2. 优化后慢日志
关于腾讯云MongoDB
腾讯云MongoDB当前服务于游戏、电商、社交、教育、新闻资讯、金融、物联网、软件服务等多个行业;MongoDB团队(简称CMongo)致力于对开源MongoDb内核进行深度研究及持续性优化;为用户提供高性能、低成本、高可用性的安全数据库存储服务。后续持续分享MongoDb在腾讯内部及外部的典型应用场景、踩坑案例、性能优化、内核模块化分析。
往期推荐
《腾讯云与MongoDB战略合作升级,瞄准AI时代的数据管理服务》
《客户口碑|亲邻科技 x TDSQL-C 分析引擎,更快更稳更省》
《人大、腾讯数据库联合攻坚交答卷:7项顶会论文突破,成果落地TDSQL产线》
