




一、开门见山:一场查询,指标“爆表”!
有一天,运维同事惊呼:“ES 节点又宕了!”你一脸疑惑地看着监控图,JVM Heap 蹭蹭往上飙、系统 Load 一下子接近 500、IO 指标爆表,整台机器几乎喘不过气来。
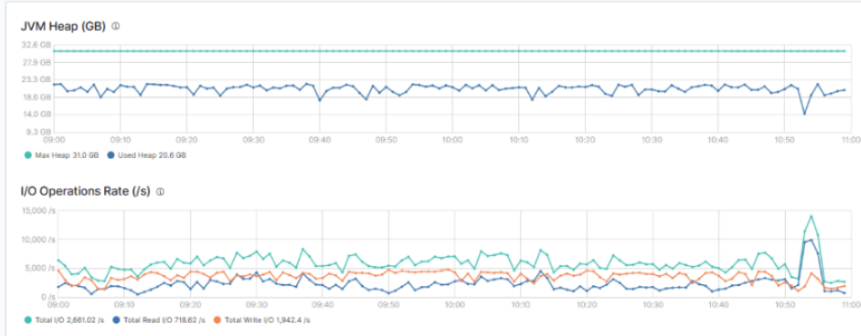
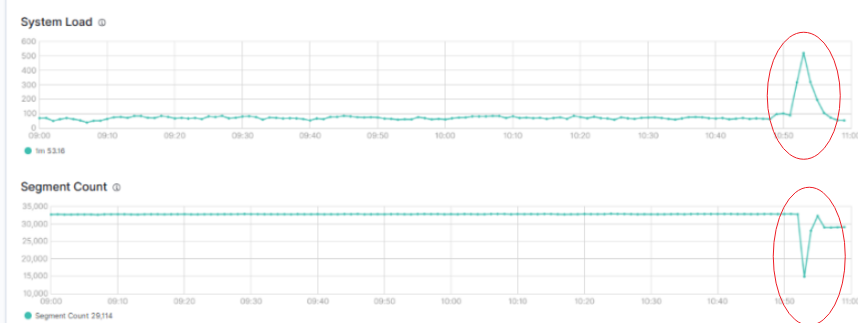
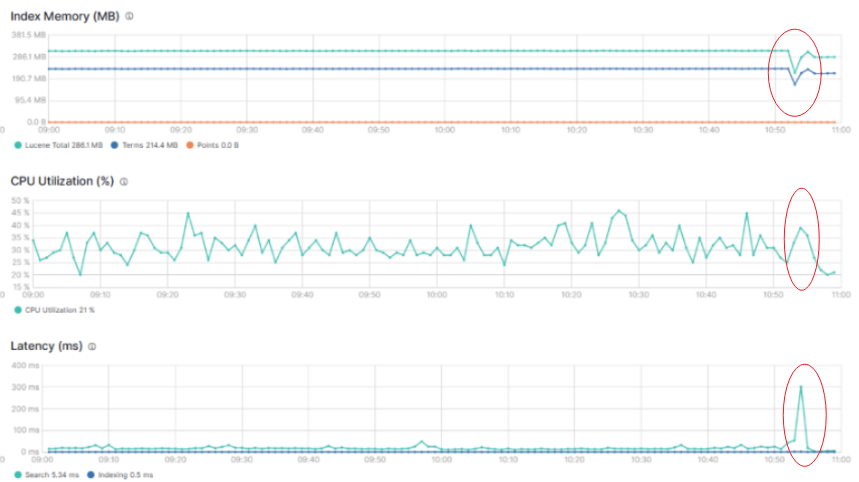
背后真相是什么?
只是一个用户,打开 Kibana,点了一下“过去 30 天”,没加任何查询条件。就这一击,干趴了一整台数据节点。
看似无辜,其实“杀伤力爆表”!
这不是科幻小说,而是现实中 Elasticsearch 集群常见的“查询炸弹”。
二、为什么不要轻易把 Kibana 查询权限随便开放?
1. 用户行为不可控
Kibana 是个强大的分析工具,但用户不是每个都懂数据结构,更不会懂查询代价。
他们会怎么操作?
点个“match_all”,查全部; 拉个时间选择器,直接选“过去 30 天”; 不加过滤,啥都查。
然后,就看到节点 CPU 打满,JVM 一通 GC,系统直接上天了……
2. Kibana 查询没有“刹车机制”

默认设置下:
查询分片会并发执行,每个节点瞬间拉起多个线程; 查询范围越大、字段越多,聚合开销越高; 没有强制限制时间范围、聚合字段或数据量。
你不限制,系统也不管,用户点下去,ES 就“自己扛”。
3. 安全风险
开放 Kibana 等于给用户一张“后门钥匙”:
看见索引名、字段名、数据结构(Mappings); 能构造自定义 DSL 查询,甚至绕过系统逻辑; 哪怕无意,用户也可能点出敏感数据或发起非法扫描。
三、你应该怎么做?记住这三个层面的“安全绳索”
✅ 第一层:限制权限,不是谁都能查
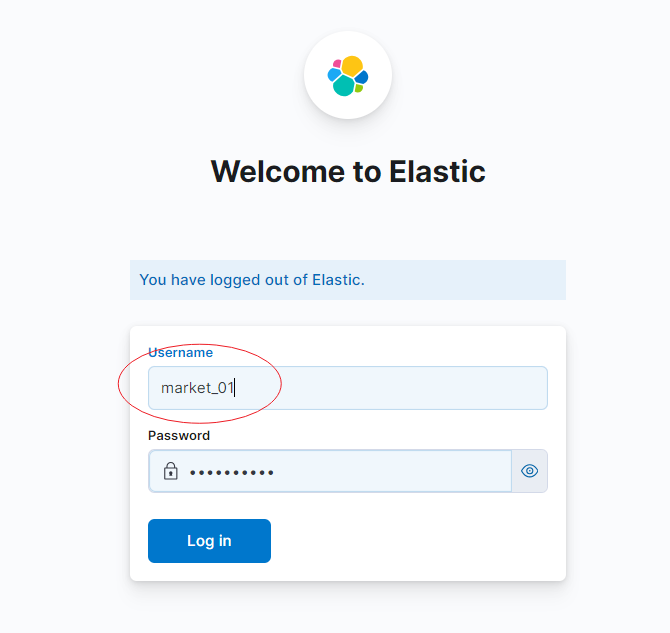
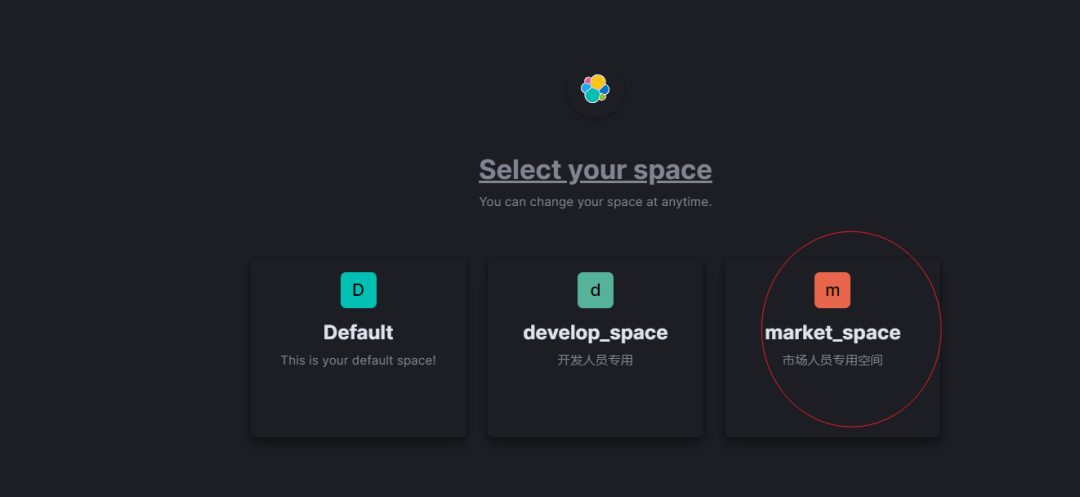
给 Kibana 设置权限分组; 只开放给有经验的运营、分析同事; Step1:设置 Spaces,控制不同空间不同权限。 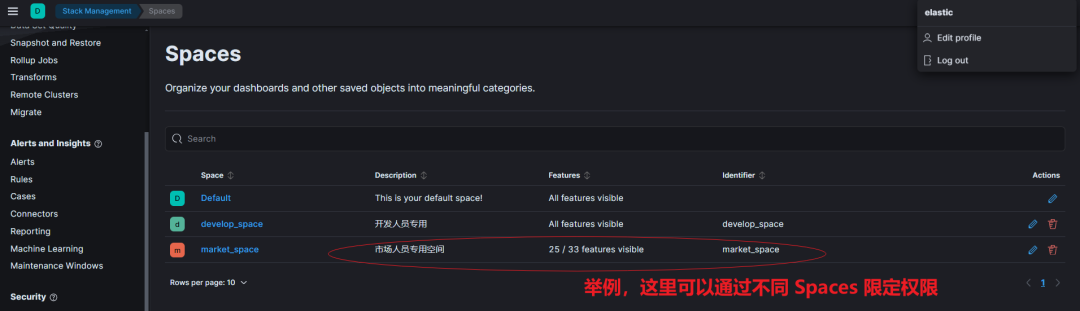
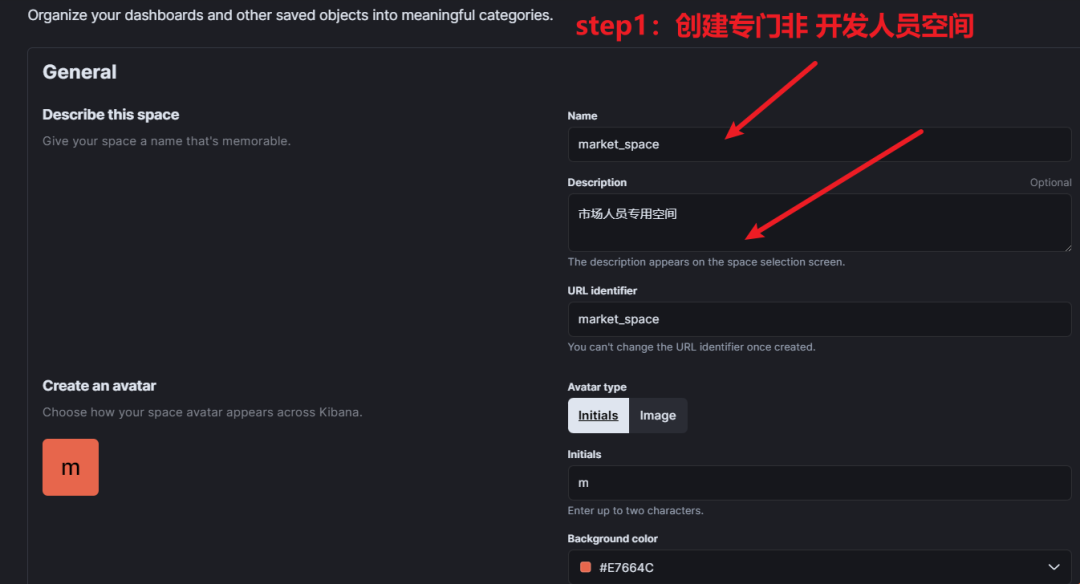
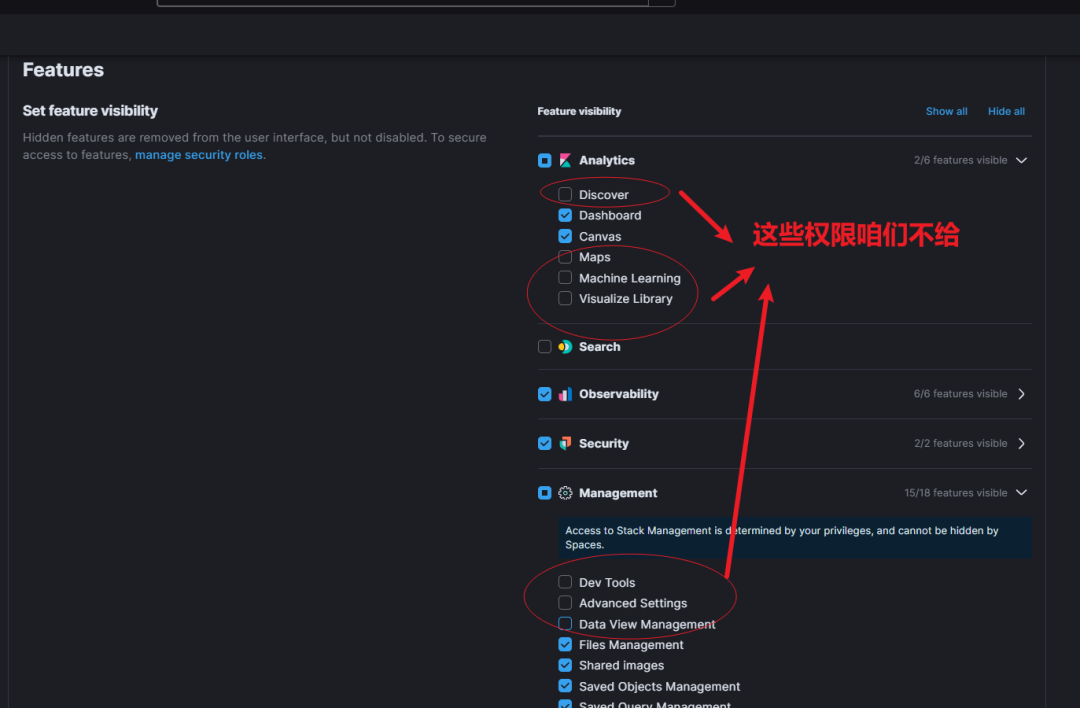
Step2:设置 role 角色。 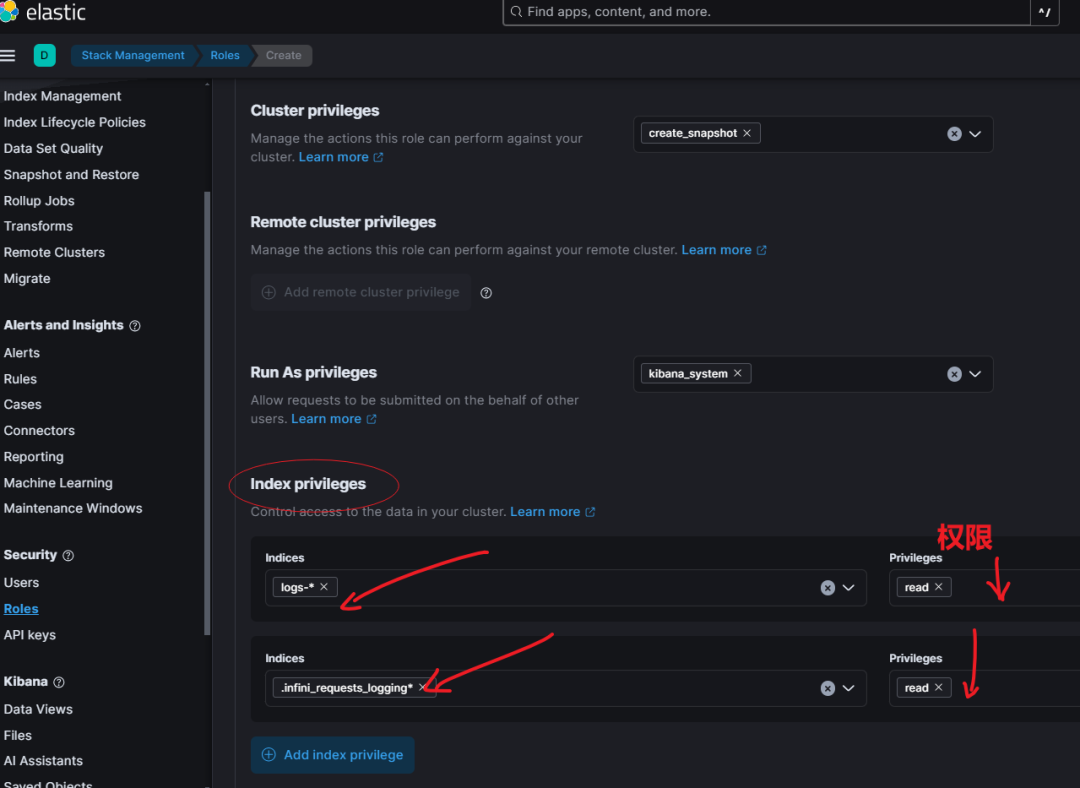
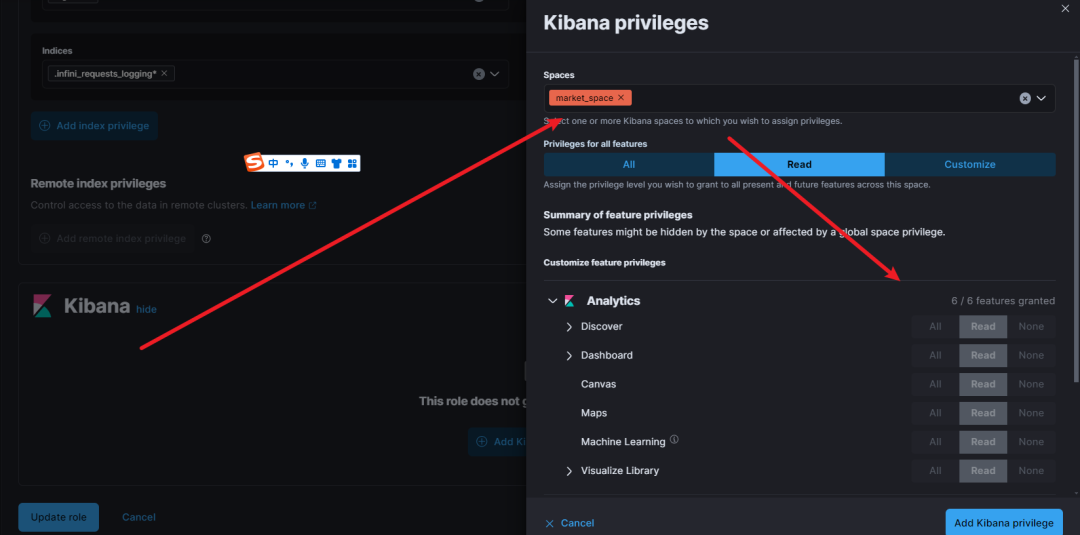
Step3:设置在上述空间下、上述角色下的用户。 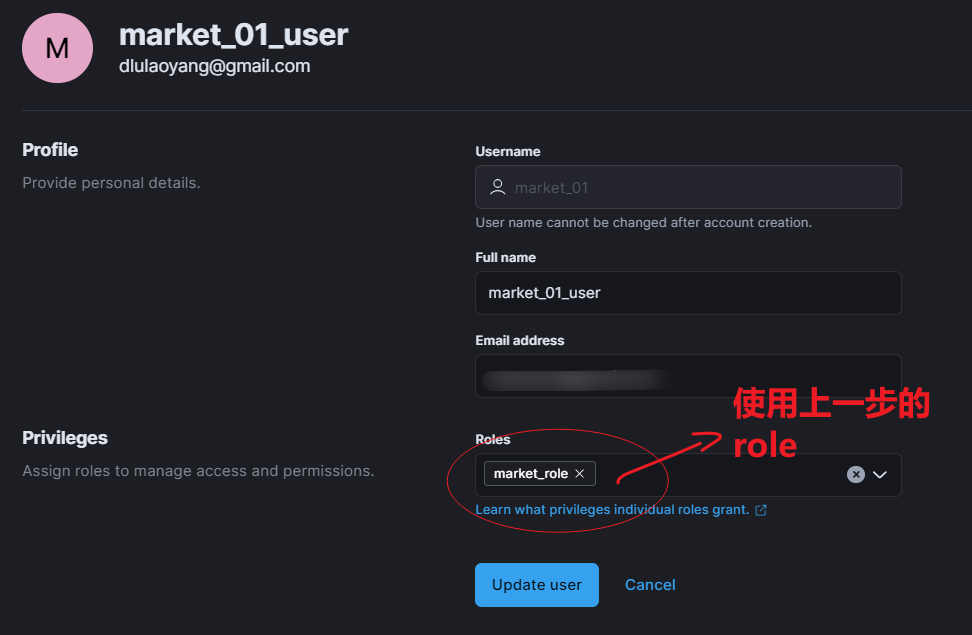
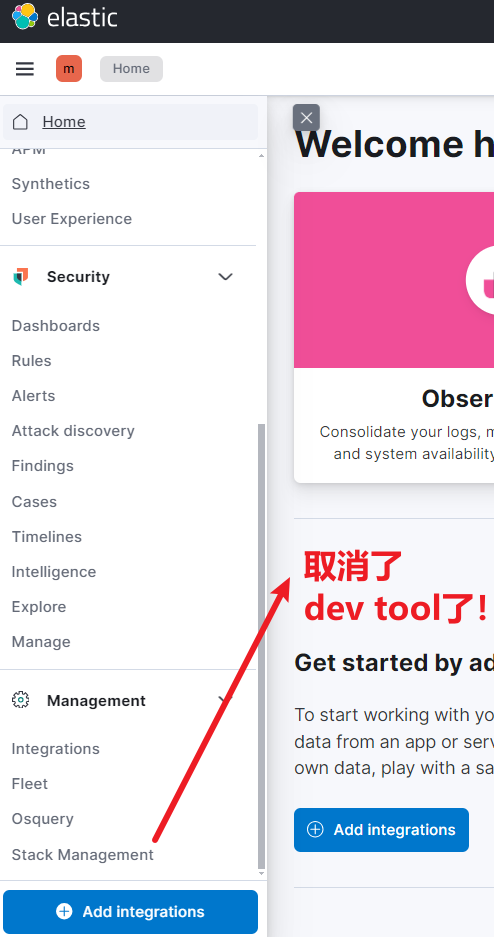
普通用户?对不起,Kibana 查询按钮请收回。
✅ 第二层:前端封装查询逻辑
用户通过业务系统查询; 查询条件由前端构造(加默认时间范围、过滤字段); 后端统一生成 DSL 请求,发给 Elasticsearch。
你得代替用户思考和兜底,不要让他们“自由发挥”。
✅ 第三层:查询模板 + 控制并发
提供预设查询模板(比如只能查近7天、只能聚合单字段); 设置 max_concurrent_shard_requests
来限制并发查询;配合 search.max_buckets
、threadpool.search.size
等配置,从系统层面设上限。
ES 的强大在于灵活,但灵活意味着危险。你要给它系上“安全带”。
四、一套组合拳,护住你的 Elasticsearch
4.1 查询并发限制
参数:max_concurrent_shard_requests
适用场景:防止单次查询打爆所有分片
实操参考:
POST .kibana_8.15.0/_search?max_concurrent_shard_requests=2
{
"query": {
"match_all": {}
}
}
建议值:2~3(默认值为自动设置)
4.2 聚合上限控制
配置:search.max_buckets
适用场景:限制聚合 bucket 数量,避免查询内存爆炸
实操参考:
PUT _cluster/settings
{
"transient": {
"search.max_buckets": 20000
}
}

官方地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-settings.html#search-settings-max-buckets
4.3 Scroll 查询限制
配置:search.max_open_scroll_context
适用场景:限制并发 scroll 查询上下文数量,避免资源泄漏。避免集群出错:Trying to create too many scroll contexts
PUT /_cluster/settings
{
"persistent": {
"search.max_open_scroll_context": 1000
}
}
官方地址:
https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html
4.4 查询模板限制
适用场景:强制查询带时间范围,避免无限全量查。
实操参考:
# 创建一个 search template
POST _scripts/time_range_template
{
"script": {
"lang": "mustache",
"source": {
"query": {
"range": {
"timestamp": {
"gte": "{{start_time}}",
"lte": "{{end_time}}"
}
}
}
}
}
}
# 使用模板查询
POST logs/_search/template
{
"id": "time_range_template",
"params": {
"start_time": "now-30d/d",
"end_time": "now/d"
}
}
4.5 前端管控:不允许直接写 DSL
建议:仅提供封装接口(如 API),由后端注入参数如时间范围。实操参考咱们本文第 3 部分。

使用 Kibana Spaces 分级,不开放 Dev Tools 和 Discover 权限。
前端调用 API 时统一注入分页、过滤条件、最大桶数限制等。
4.6 线程池队列保护
配置:threadpool.search.queue_size
适用场景:限制 search 请求等待队列长度,避免系统过载
# elasticsearch.yml 中设置(节点级配置)
threadpool.search.queue_size: 500
4.7 请求资源熔断
配置:indices.breaker.request.limit
适用场景:控制单次请求使用内存的比例,防止节点被打爆
实操参考:
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.request.limit": "50%"
}
}
以下是实战优化建议清单:
max_concurrent_shard_requests: 2~3 | |
search.max_buckets≤ 10000 | |
search.max_open_scroll_context限制上下文数量 | |
threadpool.search.queue_size | |
indices.breaker.request.limit: 60% |
五、总结:技术可以防火,但设计才防灾
Elasticsearch 是个强大的引擎,不该拿来当“BI工具”直接暴露给终端用户。
把查询交给业务系统,由你控制格式、限制时间、封装字段,才是正解。
Kibana,不该是所有人都能自由操作的“全开窗口”。
轻易授权 Kibana,相当于让人“开着拖拉机冲进了数据仓库”——
不宕机,才是奇迹。
铭毅天下建议:
👉 Elasticsearch 要安全稳定运行,靠的不只是技术优化,更要从入口设计、权限管理、用户行为引导入手,全方位控住风险。
👉 想高可用,先控用户。别让 Kibana,成为下一次“事故的起点”。
如需转载,添加 VX:elastic6, 请注明出处:铭毅天下技术博客
更多优化实践,欢迎留言交流 👇

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
