





前言
简介
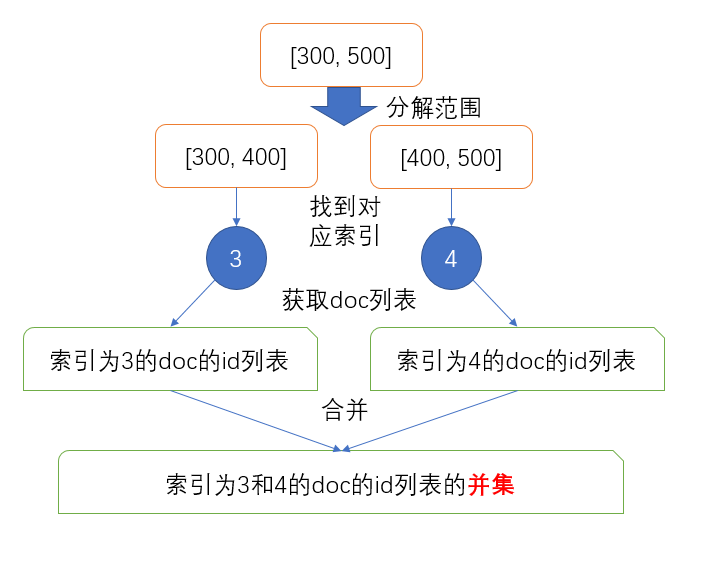
[300,500]内的文档并且事先已经把值在
[300,400]之间的文档索引到了
3、
[400,500]之间的文档索引到了
4,那么就直接通过term查询取出
3和
4对应的文档id列表并且进行
or操作就可以了,简单直接高效。
数字直接变成字符串的问题
[423,642]内的文档,
5也会被算在内,因为字典序
"5"比
"423"大,比
"642"小。
0,把
5变成
005,这样就能正确比较大小了,这也是旧版本的ES采用的解决方案。但是每次把int转化成string的时候要填充多少个0呢?太多了占空间,太少了又可能因为数字太长影响比较,比如最多只填充2个0,对于
1000以下的数字没有问题,当数字大于
1000了,个位数填充2个0就不够用了。
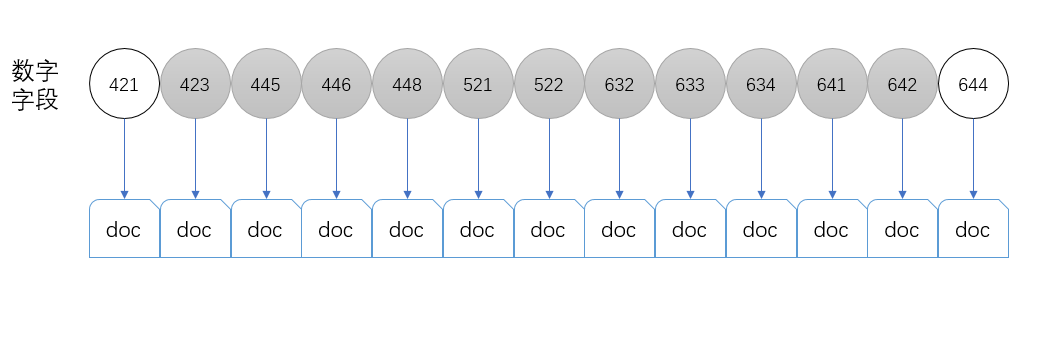
[421,423,445,446,448,521,522,632,633,634,641,642,644]一共13个term,如果我们想要查询
[423,642]之间的所有的文档,需要取出一共11个term,然后用这些term去搜索对应的文档。
ES是怎么把数字变成字符串

数字的索引是什么样子
[423,642]查询就只需要6个term,效率提高了一倍!
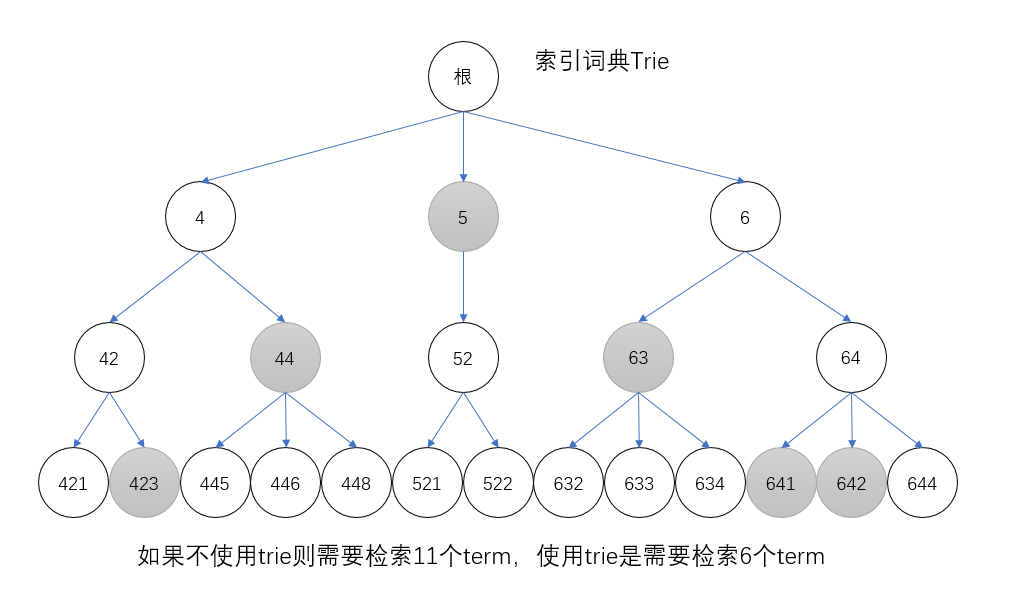
0100 0011 0001 1010,当precisionStep为4的时候,会建立4个索引——
0100 0011 0001 1010、
0100 0011 0001、
0100 0011以及
0100(最高的4位),这四个索引相当于从trie的子节点一直到根节点
423拆成
423、
42以及
4。不过分词器会同样的把
4拆分成
4,那怎么区分
423的
4和
4的
4呢?
4,ES给出的解决方案是在这两个数字前面加上一个前缀
shift表示偏移量。比如
423的
4,
shift是
2(
423的
42的
shift是
1,
423的
shift是
0);而
4的
4,
shift是
0,所以前者的
4比后者的要大。分词之后的term在每次比较之前都会先比较
shift,
shift越大,相应的term也越大,避免的重复的问题。
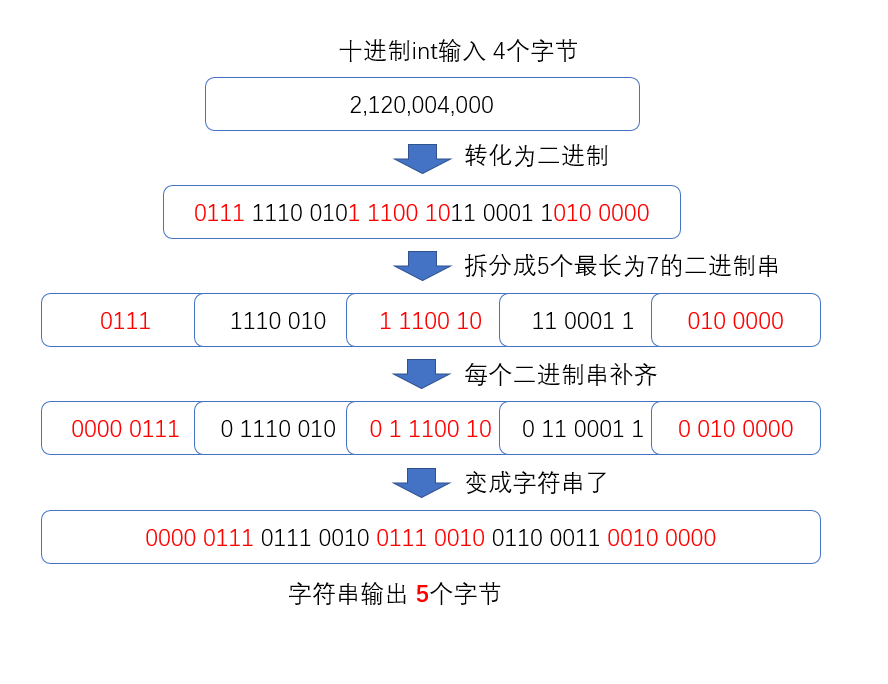
423需要建立索引,于是先把这个int数据转化成字符串,再用一个特殊的分词器根据精度把
423分成对应的三个term
423、
42和
4,并且附上对应的前缀
shift,接下来在trie中找到这几个term,把稳定的id添加到这几个term的文档id列表里面(如果不存在就创建这个term)。
查询原理
[423, 642],要找到字段大于等于423并且小于等于642的文档。
先在索引的trie里面找到这两个term以及范围内的兄弟节点,分别是trie的两个叶节点423、641和642 从叶节点向上缩小范围,对两个数字分别除以10加一和减一之后查找范围为 [43,63]
,此时的shift
是1,得到这一层级的“叶子节点”以及范围内的兄弟节点是44和63再从这一层向上,两个数字除以10,分别加一减一,得到范围 [5,5]
,shift
为2,这就是最后的节点了,term是5上面三个步骤得到最后需要的term是423、44、5、63、641和642
LegacyNumericUtils类的
splitRange方法里面。
总结
One more thing

往期推荐

点在看,让更多看见。
文章转载自佛西先森,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
