




本文将通过一个 Python 实现,详细讲解如何加载斯坦福公开预训练的 GloVe 词向量并将其索引到 Easysearch,以实现高效的语义搜索。
我们将逐步分析数据源、Easysearch 连接、索引逻辑以及关键注意事项,确保整个流程逻辑清晰、层次分明。

1、引言
GloVe(Global Vectors for Word Representation)是一种词向量模型,能够将单词映射到密集向量空间,捕捉语义关系,非常适合语义搜索或文本相似性任务。

Easysearch支持密集向量字段和k近邻(k-NN)搜索,是存储和查询这些向量的强大工具。
本文将展示如何使用Python将两者结合,重点讲解数据源、连接设置和索引逻辑。
2、前提条件
在开始之前,请确保准备好以下内容:
Easysearch集群:一个运行中的实例(例如 https://127.0.0.1:9200/
)并具备访问凭据。
GloVe文件:预训练的GloVe 向量文件(例如 glove.6B.50d.txt
)。Python依赖:安装必要的Python库: pip install Easysearch urllib3 numpy索引映射:Easysearch中已创建的索引( knn-test
),并配置了支持50维向量的密集向量字段(my_vec
)。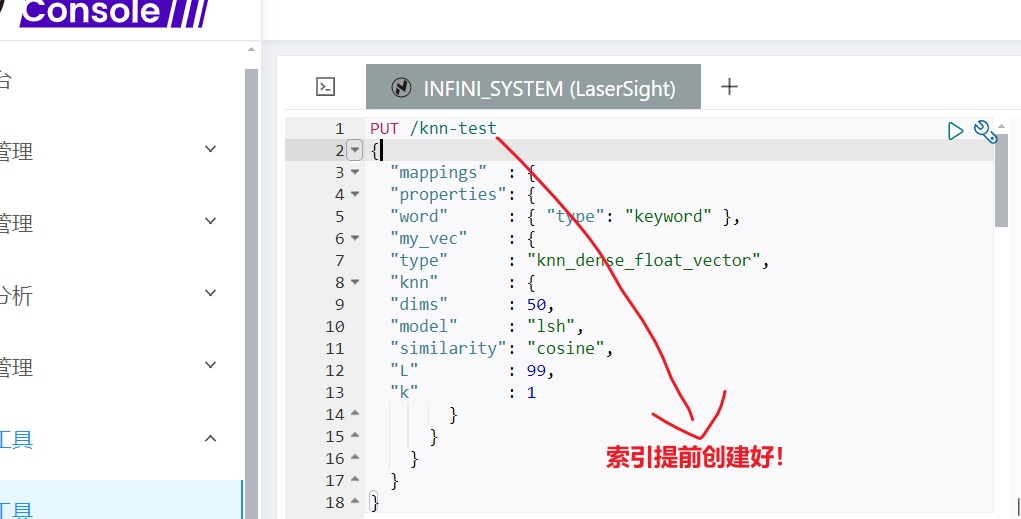
极限控制台创建索引
3、数据源:GloVe 向量
3.1 什么是 GloVe?
GloVe 是由斯坦福NLP团队开发的词向量模型,通过在大规模文本语料库(如Wikipedia或Common Crawl)上训练生成。每个单词被表示为一个密集向量(例如50维、100维或300维),这些向量能够捕捉单词的语义信息。
本项目使用glove.6B.50d.txt
文件,包含40万个单词,每个单词对应一个50维向量。
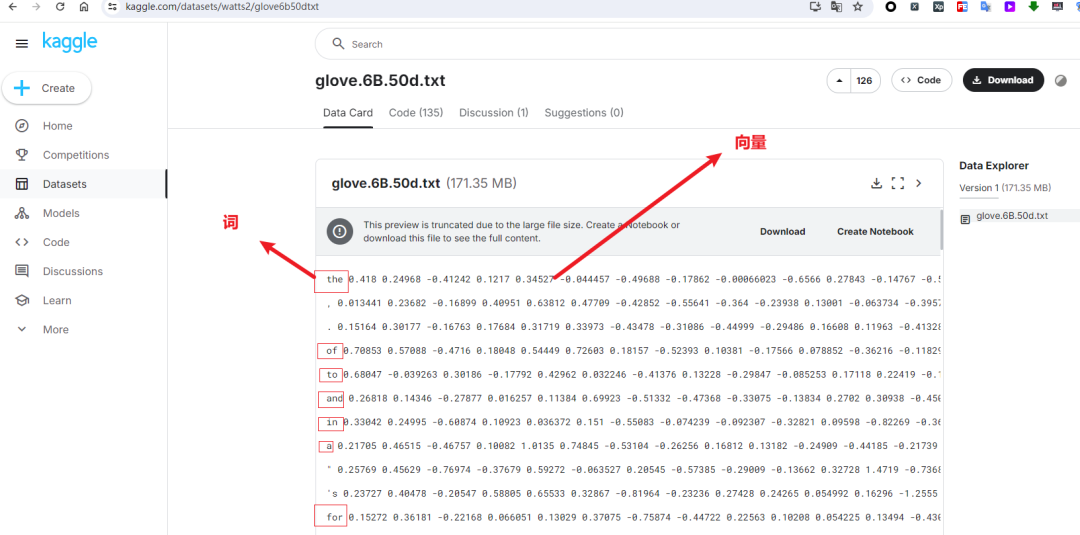
3.2 文件结构
GloVe 文件是一个纯文本文件,每行表示一个单词及其嵌入向量:
word1 0.123 0.456 -0.789 ... (50个浮点数)
word2 0.234 -0.567 0.890 ... (50个浮点数)
第一列:单词(例如“the”、“dog”)。 其余列:50个浮点数,表示该单词的向量。
3.3 加载GloVe模型
load_glove_model
函数将GloVe文件加载到Python字典中:
def load_glove_model(file_path):
print("加载GloVe模型")
glove_model = {}
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
split_line = line.strip().split()
word = split_line[0]
embedding = np.array(split_line[1:], dtype=np.float64)
glove_model[word] = embedding
print(f"已加载{len(glove_model)}个单词!")
return glove_model
处理流程: 使用UTF-8编码打开文件,以支持特殊字符。 将每行拆分为单词和其向量。 将向量转换为NumPy数组,便于计算。 将单词和向量存储到字典 glove_model
中。输出:一个字典,将单词映射到50维NumPy数组(例如, glove_model["dog"]
返回一个50维向量)。注意事项: 文件较大( glove.6B.50d.txt
约167MB),加载可能需要几秒钟。
UTF-8编码确保兼容非ASCII单词。 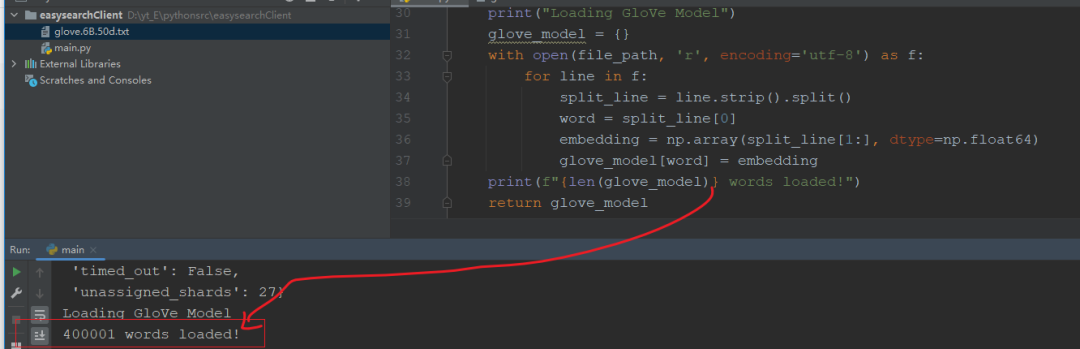
40万个单词加载
4、Easysearch 设置
4.1 连接配置
脚本使用Easysearch
Python客户端连接到Easysearch集群:
url = "https://127.0.0.1:9200/"
user_passwd = ('admin', 'dffXXXXXXXXXXXXc57')
es = Easysearch(
[url],
http_auth=user_passwd,
verify_certs=False,
)
URL:指向Easysearch实例。 认证:使用HTTP基本认证,提供用户名和密码。 SSL验证:为简化流程,禁用SSL验证( verify_certs=False
),但生产环境中应使用合法证书以确保安全。警告处理:通过 urllib3.disable_warnings
和warnings.filterwarnings
禁用SSL相关警告(生产环境不建议)。
4.2 集群健康检查(仅测试demo用,本示例可以删除)
在索引之前,脚本会检查集群状态:
health = es.cluster.health()
pprint(health)
此调用返回集群状态(green
、yellow
或red
)、节点数量和分片分配等信息,确保集群可用于索引。
4.3 索引映射
目标索引(knn-test
)需预先配置支持密集向量的映射。典型的映射如下:
{
"mappings": {
"properties": {
"word": { "type": "keyword" },
"my_vec": { "type": "dense_vector", "dims": 50 }
}
}
}
word
:以keyword
类型存储单词,用于精确匹配。
my_vec
:一个50维的dense_vector
字段,用于存储GloVe向量。
5、索引逻辑
index_glove_to_es
函数将 GloVe 嵌入分批索引到 Easysearch:
def index_glove_to_es(glove_model, index_name="knn-test", batch_size=1000):
print(f"正在将GloVe向量索引到{index_name}")
actions = []
count = 0
for word, vector in glove_model.items():
if len(vector) != 50:
print(f"由于向量维度错误,跳过单词'{word}':{len(vector)}")
continue
action = {
"_index": index_name,
"_source": {
"word": word,
"my_vec": vector.tolist()
}
}
actions.append(action)
count += 1
if len(actions) >= batch_size:
from Easysearch.helpers import bulk
success, failed = bulk(es, actions, raise_on_error=False)
print(f"索引{success}个文档,{failed}个失败")
actions = []
if count % 10000 == 0:
print(f"已处理{count}个单词")
if actions:
from Easysearch.helpers import bulk
success, failed = bulk(es, actions, raise_on_error=False)
print(f"索引{success}个文档,{failed}个失败")
print(f"共处理{count}个单词")
return count
5.1 核心组件
分批处理:
文档以每批1000个( batch_size=1000
)的方式索引,平衡内存使用和性能。使用 Easysearch.helpers
的bulk
API实现高效索引。每批完成后清空 actions
列表,释放内存。
文档结构:
word
:GloVe模型中的单词。my_vec
:50维向量,转换为Python列表(Easysearch不支持直接使用NumPy数组)。每个文档包含: _index
字段指定目标索引(knn-test
)。错误处理:
检查向量维度是否为50( len(vector) == 50
),跳过无效向量并记录警告。bulk
API设置raise_on_error=False
,防止失败中断流程,失败的文档会被记录。进度跟踪:
每处理10,000个单词记录一次进度。 每批及最后报告成功和失败的文档数量。
5.2 执行流程
主程序块协调整个流程:
if __name__ == "__main__":
glove_file = "glove.6B.50d.txt"
index_name = "knn-test"
glove_model = load_glove_model(glove_file)
index_glove_to_es(glove_model, index_name)
指定GloVe文件路径和目标索引。 将GloVe模型加载到内存。 将所有向量索引到Easysearch。
6、性能考虑
内存使用:加载40万个词向量需要约170MB内存。分批索引可避免内存峰值。 索引速度:每批1000个文档适用于大多数系统,可根据集群容量和网络延迟调整。 集群负载:索引40万个文档可能需要几分钟,具体取决于集群的节点数和资源。 错误处理:跳过无效向量确保流程鲁棒性,但可记录这些问题以便进一步分析。 
7、潜在改进
并行索引:使用 concurrent.futures
并行处理批次,提升索引速度。动态映射:如果索引不存在,程序化创建正确的映射。 数据验证:检查GloVe文件中是否存在重复单词或格式错误。 安全性:生产环境中启用SSL验证,并使用环境变量存储凭据。 监控:集成Easysearch的 _cat/indices
API,实时监控索引增长。
8、结论
本流程展示了如何加载GloVe向量并将其索引到 Easysearch,用于语义搜索应用。
通过分批处理、错误处理和 Easysearch Python 客户端(本质是 Elasticsearch 客户端,由于 Elasticsearch 7.10.2 以后变更了许可模式,所以本文使用的 7.13.1 的客户端),我们实现了一个可扩展且鲁棒的解决方案。
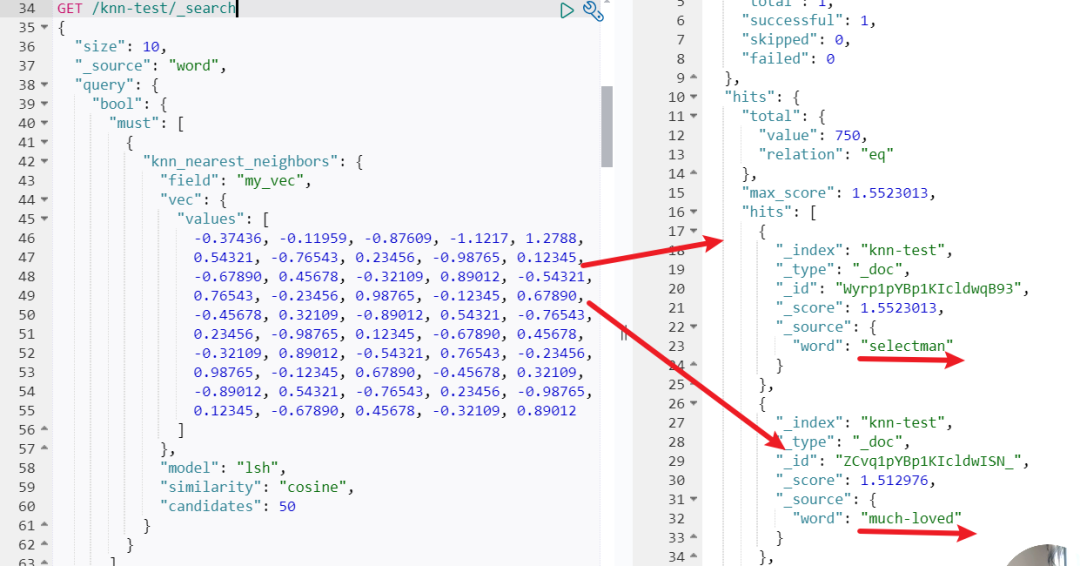
GloVe数据源提供了丰富的语义表示,而 Easysearch 的k-NN搜索功能支持高效的相似性查询。通过小调整,此设置可扩展到其他嵌入模型或更大规模的数据集。
完整代码请参考如下链接:
https://articles.zsxq.com/id_4p2rr0g6bm3j.html
更多优化实践,欢迎留言交流 👇
参考
[1] https://www.cnblogs.com/infinilabs/p/18313184
[2] https://docs.infinilabs.com/easysearch/main/docs/references/search/knn_api/
[3] https://stackoverflow.com/questions/37793118/load-pretrained-glove-vectors-in-python

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
