




1、向量检索背景
在信息检索和推荐系统中,如何高效地找到与给定输入语义相似的文档或词语?
传统的关键词匹配往往无法捕捉深层语义,而向量检索(Vector Search)通过将文本、图像等数据转化为高维向量,利用向量间的相似性度量(如余弦相似度)来实现更精准的语义匹配。
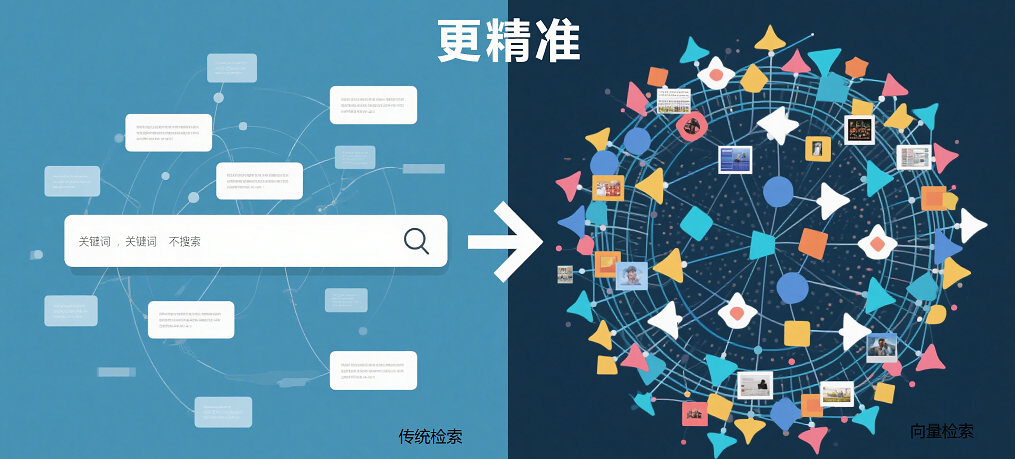
Easysearch 作为一款强大的搜索平台,支持 k-Nearest Neighbors (kNN) 向量检索功能,适用于词向量、图像特征等场景。
本文将围绕 Easysearch 的向量检索功能,探讨如何利用 kNN 检索 API 实现高效的向量查询,解决语义相似性检索问题。
2、Easysearch 的 kNN 检索 API
向量检索的核心是将数据表示为向量,并通过相似性度量找到最相似的向量。
Easysearch 的 kNN 检索 API 提供了两种主要方式:
1.近似搜索(Approximate Search):
通过索引结构(如 LSH,局部敏感哈希)加速查询,适合大规模数据集。需要配置索引参数(如维度、模型类型、相似性度量等)。
2.精确搜索(Exact Search):
计算查询向量与所有索引向量的精确相似度,适合小规模数据集,但计算开销较高。
https://docs.infinilabs.com/easysearch/main/docs/references/search/knn_api/3、Eaysearch 实现向量检索步骤
实现向量检索需要解决以下关键问题:
索引配置:如何定义映射(Mapping)和设置(Setting)以支持向量存储和查询?
数据导入:如何将高维向量数据(如词向量)导入 Easysearch?
查询实现:如何通过 kNN API 检索与目标向量最相似的向量?
性能优化:如何在近似搜索和精确搜索间权衡性能与精度?
接下来,我们将通过实战案例,基于斯坦福大学的 GloVe 词向量(见上一篇文章),演示 Easysearch 向量检索的完整流程,实战解决问题。
3.1. 环境准备
要使用 Easysearch 的 kNN 检索功能,早期版本需确保已安装 knn 插件。具体安装步骤可参考官方文档的“插件安装”部分。 特别说明的是:1.11.1(含)之后的新版本已经不需要额外安装!

3.2. 创建索引
在索引向量之前,需定义 Mapping,指定向量字段的类型、维度、模型和相似性度量。
以下是一个创建索引的请求示例,使用 LSH 模型和余弦相似度:
PUT knn-test
{
"mappings": {
"properties": {
"word": { "type": "keyword" },
"my_vec": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 50,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}
参数说明:
word:存储词语的字段,类型为 keyword。 my_vec:存储 50 维向量的字段,类型为 knn_dense_float_vector。 dims:向量维度(50 维,与 GloVe 数据一致)。 model:使用 LSH 模型加速近似搜索。 similarity:余弦相似度,适合词向量语义比较。 L 和 k:LSH 模型参数,分别控制哈希表数量和哈希函数数量,影响召回率和精度。 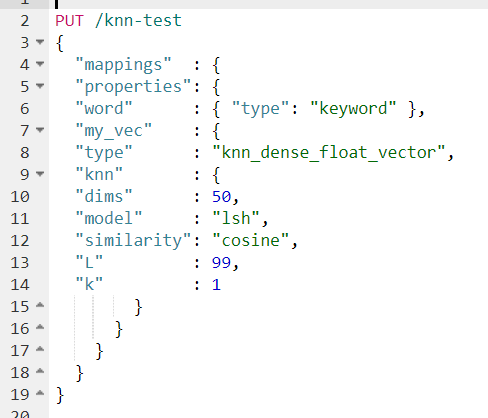
3.3. 导入测试数据
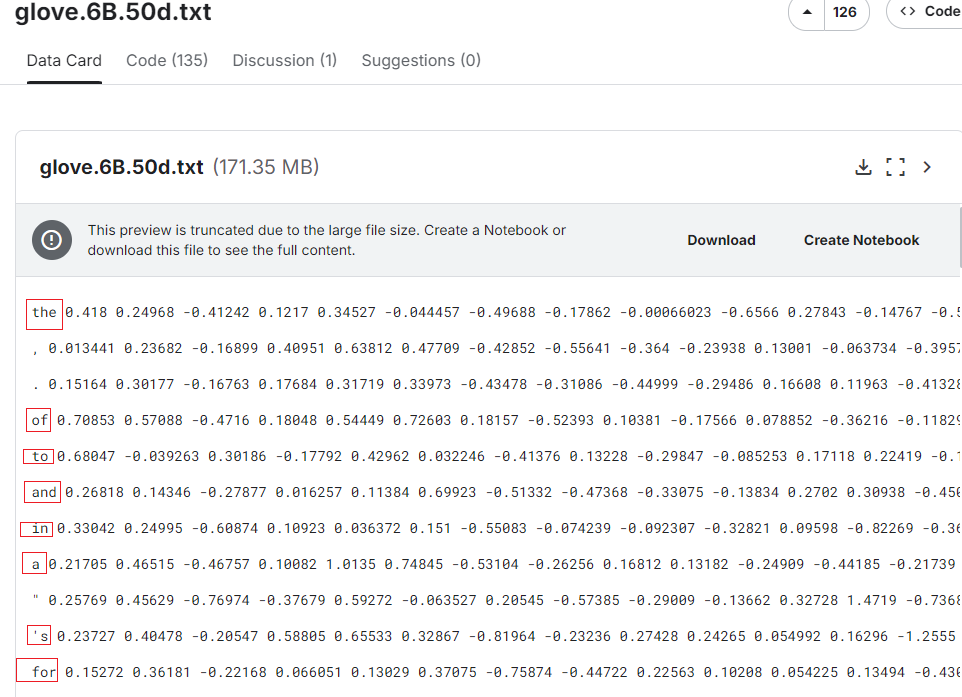
我们使用斯坦福大学预训练的 GloVe 词向量(glove.6B.50d.txt),每个词对应一个 50 维向量。下载并解压文件后,将数据导入 Easysearch,词语存储在 word 字段,向量存储在 my_vec 字段。导入方式可通过批量 API 或脚本实现,确保每个文档包含 word 和 my_vec 字段。
完整导入代码:https://t.zsxq.com/82Ra6
3.4. 向量检索
以词语 “bread” 为例,展示向量检索的两个步骤:
3.4.1 查询 “bread” 的向量
首先通过 match 查询获取 “bread” 的向量:
GET knn-test/_search
{
"query": {
"match": {
"word": "bread"
}
}
}
响应中包含 “bread” 的 50 维向量,例如:
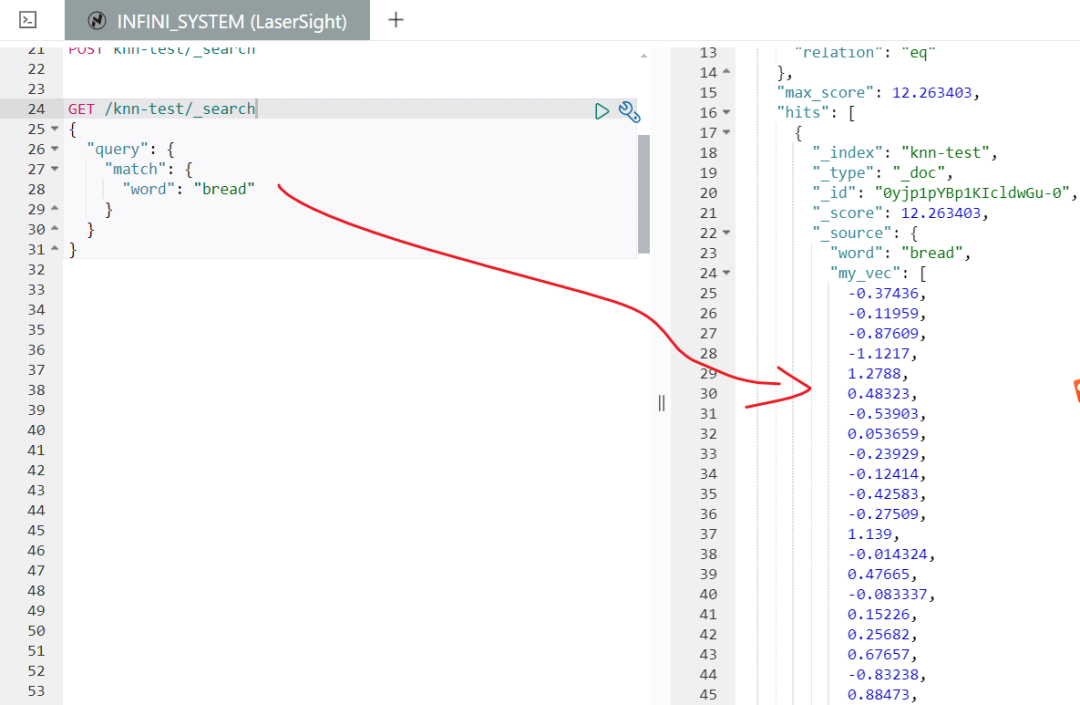
{
"my_vec": [-0.37436, -0.11959, -0.87609, -1.1217, 1.2788, ...]
}
3.4.2 使用向量查询相似词
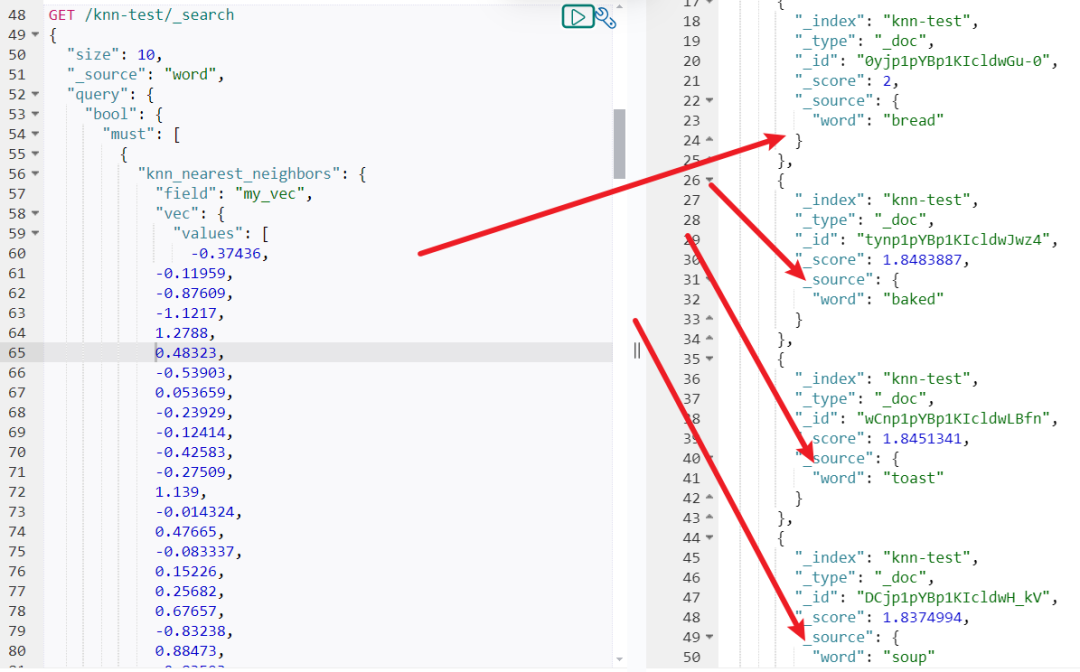
利用获取的向量,通过 kNN 查询检索语义相似的词语:
GET knn-test/_search
{
"size": 10,
"_source": "word",
"query": {
"bool": {
"must": [
{
"knn_nearest_neighbors": {
"field": "my_vec",
"vec": {
"values": [
-0.37436, -0.11959, -0.87609, -1.1217, 1.2788,
0.54321, -0.76543, 0.23456, -0.98765, 0.12345,
-0.67890, 0.45678, -0.32109, 0.89012, -0.54321,
0.76543, -0.23456, 0.98765, -0.12345, 0.67890,
-0.45678, 0.32109, -0.89012, 0.54321, -0.76543,
0.23456, -0.98765, 0.12345, -0.67890, 0.45678,
-0.32109, 0.89012, -0.54321, 0.76543, -0.23456,
0.98765, -0.12345, 0.67890, -0.45678, 0.32109,
-0.89012, 0.54321, -0.76543, 0.23456, -0.98765,
0.12345, -0.67890, 0.45678, -0.32109, 0.89012
]
},
"model": "lsh",
"similarity": "cosine",
"candidates": 50
}
}
]
}
}
}
参数说明:
size:返回前 10 个最相似的词。 _source:仅返回 word 字段。 vec:查询向量,即 “bread” 的向量。 candidates:候选集大小,影响召回率。 响应示例
"_index": "knn-test","_type": "_doc","_id": "0yjp1pYBp1KIcldwGu-0","_score": 2,"_source": {"word": "bread"}},{"_index": "knn-test","_type": "_doc","_id": "tynp1pYBp1KIcldwJwz4","_score": 1.8483887,"_source": {"word": "baked"}},{"_index": "knn-test","_type": "_doc","_id": "wCnp1pYBp1KIcldwLBfn","_score": 1.8451341,"_source": {"word": "toast"}},{"_index": "knn-test","_type": "_doc","_id": "DCjp1pYBp1KIcldwH_kV","_score": 1.8374994,"_source": {"word": "soup"}},{"_index": "knn-test","_type": "_doc","_id": "3ijp1pYBp1KIcldwHvdc","_score": 1.8201615,"_source": {"word": "cake"}},
结果显示与 “bread” 语义相近或常一起出现的词,如 “baked”、“toast”、“butter” 和 “soup”,符合预期。
3.5. 精确搜索(可选)
对于小规模数据集,可使用精确搜索,计算查询向量与所有向量的精确相似度。以下是创建精确映射和查询的示例:
3.5.1 创建精确映射
PUT my-index{"mappings": {"properties": {"my_vec": {"type": "knn_dense_float_vector","knn": {"dims": 50}}}}}
3.5.2 精确查询
GET /my-index/_search{"query": {"knn_nearest_neighbors": {"field": "my_vec","vec": {"values": [-0.37436,-0.11959]},"model": "exact","similarity": "cosine"}}}
注意:精确搜索无需配置模型参数,但运行时间为 O(n²),适合文档数量较少的场景。
4、小结
通过 Easysearch 的 kNN 检索 API,我们实现了高效的向量检索,解决了语义相似性匹配问题。
核心步骤
1.配置索引 Mapping,指定向量类型、维度和模型。 2.导入高维向量数据(如 GloVe 词向量)。 3.使用 kNN 查询检索相似向量,支持近似搜索和精确搜索。 4.根据数据规模和性能需求,选择合适的搜索方式。
优势
近似搜索(LSH)在大规模数据集上效率高,适合生产环境。 精确搜索结果准确,适合小规模实验场景。 Easysearch 的 kNN API 配置灵活,支持多种相似性度量。
注意事项
近似搜索需权衡召回率和精度,调整 L 和 k 参数。 精确搜索计算开销大,谨慎用于大规模数据集。
通过本文的实战案例,读者可以快速上手 Easysearch 向量检索,应用于词嵌入、推荐系统等场景。未来可进一步探索模型优化和参数调优,以提升检索性能。
如需转载,添加 VX:elastic6, 请注明出处:铭毅天下技术博客
更多优化实践,欢迎留言交流 👇

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
