




Elasticsearch 作为一款强大的分布式搜索和分析引擎,被广泛应用于日志分析、实时监控和全文搜索等场景。

然而,尽管它的文档非常详尽,但对于运维人员或开发者来说,缺乏一个全面的设置清单常常让人头疼。
Elasticsearch 的设置繁多且分散,涉及节点、索引、集群等多个层面,有些甚至可能是未文档化的隐藏配置。
为了解决这一问题,一位开发者通过分析 Elasticsearch 源码,利用 “代码即数据” 的理念,提取了完整的设置列表。
本文将带你深入了解这一成果,并展示如何利用这份设置清单优化你的 Elasticsearch 集群。
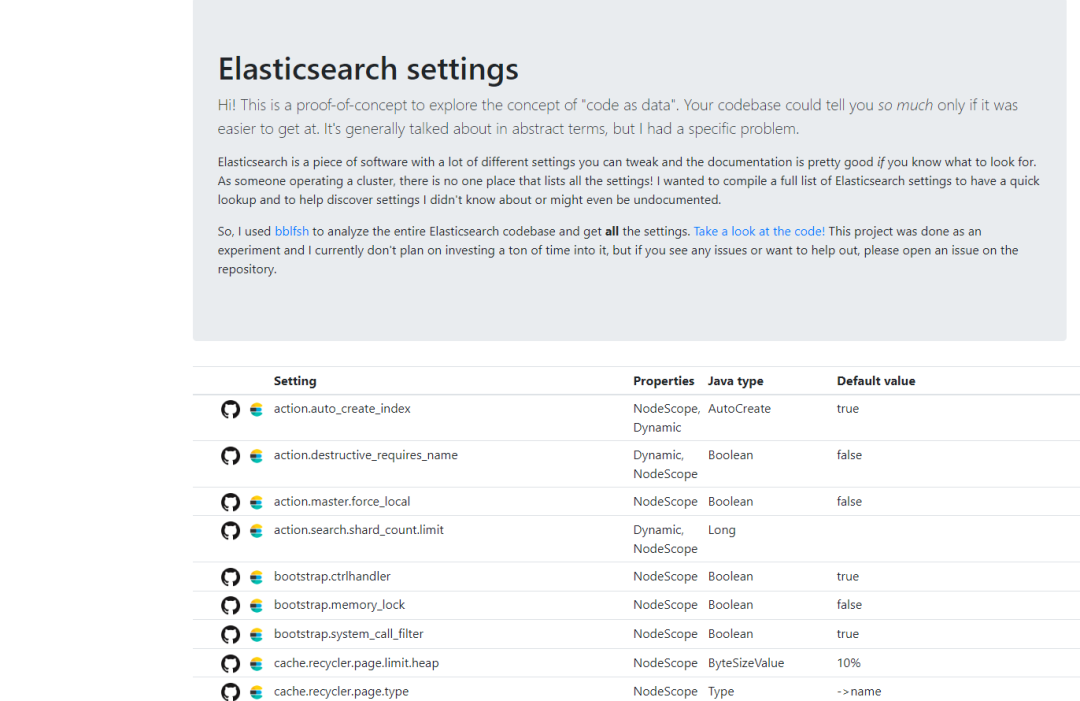
1、背景:为什么需要完整的 Elasticsearch 设置清单?
在管理 Elasticsearch 集群时,了解所有可配置选项至关重要。
无论是调整集群的性能、优化资源分配,还是处理特定的业务需求,合理的配置都能显著提升系统效率。
然而,官方文档虽然详细,却往往需要你明确知道要查找的设置名称,而缺乏一个统一的参考列表。这不仅增加了学习成本,还可能让你错过一些关键或鲜为人知的配置。
比如,你想优化 Elasticsearch 集群的磁盘使用率,但不知道具体有哪些设置可以调整。官方文档里,cluster.routing.allocation. disk.watermark.high(默认 90%)这个设置控制高水位线,超过后会触发分片重新分配。
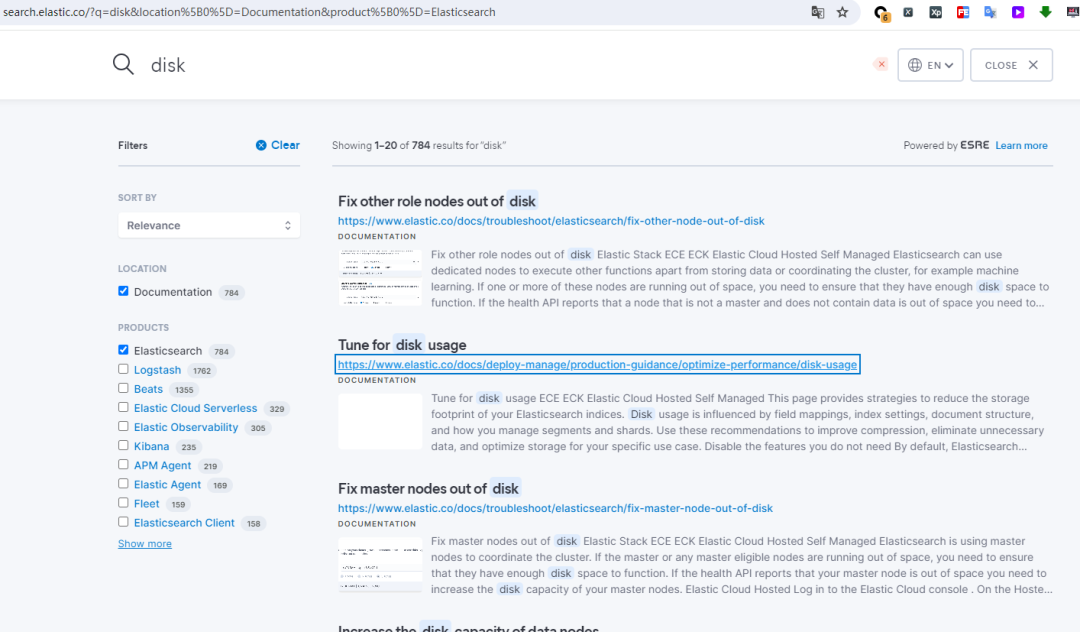
官方文档直接搜 disk 的话,可能要找好一会
但如果你不知道这个设置的名字,很难直接在文档中找到它。结果可能得花不少时间翻阅,或者完全错过这个关键配置,导致磁盘满载时集群性能下降。
这份清单直接列出所有设置,包括这种鲜为人知的选项,让你一目了然,省时又省力!
通过使用 bblfsh(一个源代码解析工具),开发者成功从 Elasticsearch 源码中提取了所有设置,形成了一份详尽的清单。
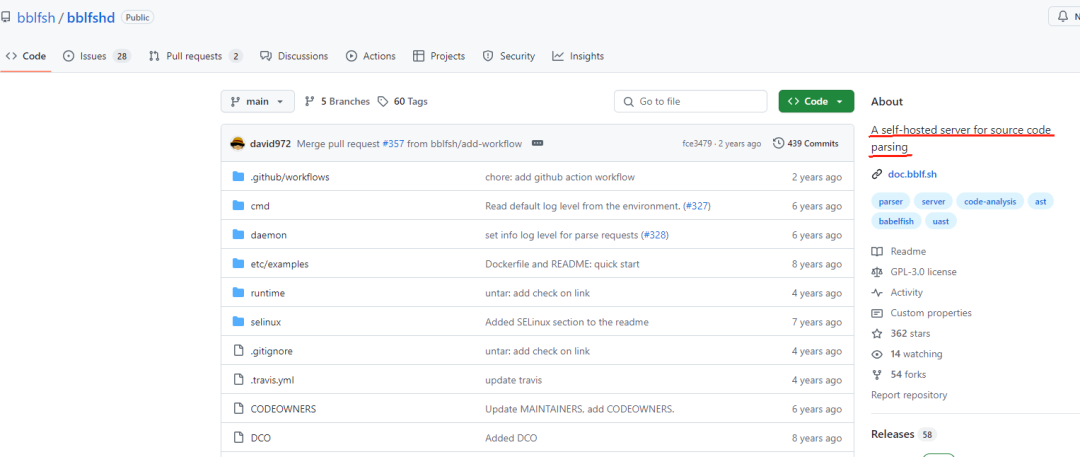
这份清单不仅包含常见的配置项,还包括一些可能未在官方文档中明确列出的设置,为运维人员和开发者提供了一个快速查找和发现新设置的宝贵资源。
2、项目亮点:代码即数据的实践
这个项目的核心理念是 “代码即数据”,即通过解析源代码来提取有价值的信息。
Elasticsearch 的设置通常以代码中的常量、枚举或配置文件的形式存在,开发者利用 bblfsh 分析了整个代码库,提取了所有与设置相关的定义。
这不仅展示了源代码分析的强大潜力,还为其他类似项目提供了一个可复制的思路。
这份清单涵盖了数百个设置项,涉及节点范围(NodeScope)、索引范围(IndexScope)、动态配置(Dynamic)等多个类别。
每个设置项都包含以下关键信息:
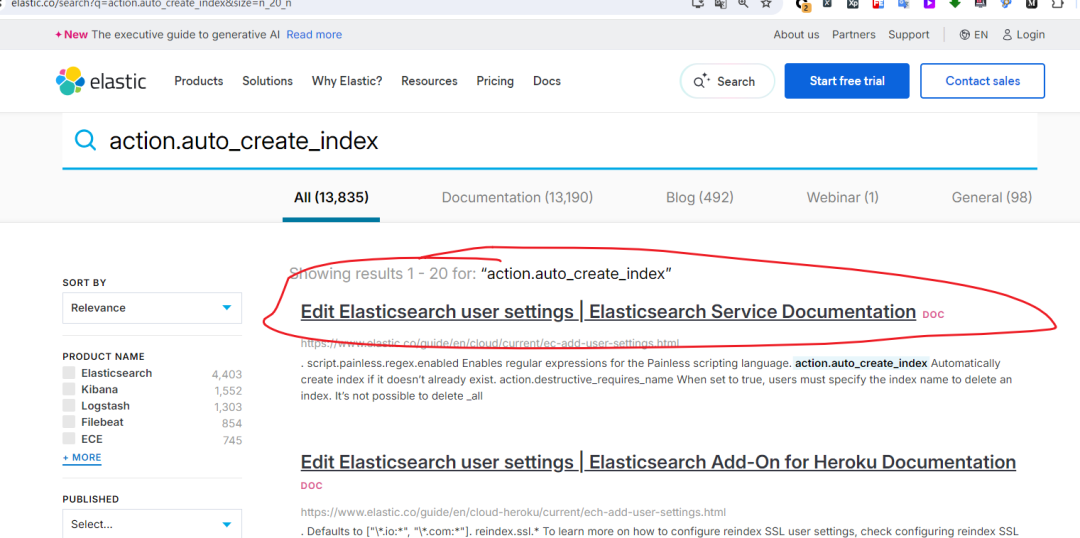
设置名称:如 action.auto_create_index
、cluster.routing.allocation.enable
等。属性:如是否动态可调(Dynamic)、作用范围(NodeScope 或 IndexScope)。 Java 类型:如 Boolean、Integer、TimeValue 等。 默认值:如 true
、30s
、10%
等。
以下是一些典型设置的示例:
action.auto_create_index
:控制是否自动创建索引,默认值为true
。
cluster.routing.allocation.disk.watermark.high
:磁盘使用率高水位线,默认值为90%
,用于触发分片重新分配。index.max_result_window
:控制搜索结果的最大窗口大小,默认值为10000
。
3、清单的实际用途
这份设置清单对 Elasticsearch 用户有以下几个方面的实际价值:
快速查找配置:无需逐一翻阅文档,只需在这份清单中搜索即可找到所需设置及其默认值。
发现隐藏设置:一些未文档化的设置可能隐藏在代码中,这份清单让你有机会发现它们并评估其用途。
优化集群性能:通过调整如
cluster.routing.allocation
或indices.breaker
相关的设置,可以更好地管理资源分配和性能。调试与故障排查:了解所有设置的默认值和作用范围,有助于快速定位配置问题。
例如,如果你希望优化集群的磁盘使用率,可以关注以下设置:
cluster.routing.allocation.disk.watermark.low
:默认85%
,控制低水位线。cluster.routing.allocation.disk.watermark.high
:默认90%
,控制高水位线。cluster.routing.allocation.disk.watermark.flood_stage
:默认95%
,触发只读模式。
通过调整这些值,你可以更灵活地管理磁盘空间,避免因磁盘满载导致的集群故障。
4、清单中的一些关键设置解析
以下是一些重要的设置类别及其作用:
4.1 集群分配与平衡:
cluster.routing.allocation.enable
:控制分片分配的行为,默认值为all
,可设置为primaries
或none
。
cluster.routing.allocation.balance.shard
:分片平衡权重,默认值为0.45f
,影响分片在节点间的分布。
index.max_result_window
:限制单次搜索返回的文档数,防止内存溢出。
index.translog.flush_threshold_size
:控制事务日志的刷新阈值,默认512MB
,影响数据写入性能。
4.3 网络与通信:
http.port
:HTTP 服务端口范围,默认9200-9300
。
transport.tcp.port
:节点间通信端口范围,默认9300-9400
。
4性能优化:
indices.memory.index_buffer_size
:索引缓冲区大小,默认10%
,影响写入性能。
indices.breaker.fielddata.limit
:字段数据缓存限制,默认60%
,防止内存过度使用。
5、如何使用这份清单?
这份清单已经被整理成结构化的格式,包含设置名称、属性、Java 类型和默认值。
你可以通过以下方式利用它:
本地保存:将清单保存为 CSV 或 Markdown 文件,方便随时查阅。
集成到工具:将清单导入配置管理工具或脚本,用于自动化配置或监控。
6、项目局限与未来方向
虽然这个项目提供了一份宝贵的设置清单,但作为概念验证,它仍有一些局限:
维护性:Elasticsearch 版本更新可能引入新的设置或更改现有设置,清单需要定期更新。
完整性:虽然通过源码提取了大量设置,仍可能遗漏某些动态生成的配置。
文档化:部分设置的描述和用途可能需要结合官方文档进一步解释。
未来,可以考虑以下改进方向:
开发一个自动化工具,定期从 Elasticsearch 源码更新设置清单。
提供一个交互式 Web 界面,方便用户搜索和过滤设置。
结合官方文档,为每个设置添加详细说明和使用场景。
7、结语
这份 Elasticsearch 设置清单是 “代码即数据” 理念的一次成功实践,为运维人员和开发者提供了一个全面的配置参考。无论是优化集群性能、排查问题,还是探索隐藏设置,这份清单都能让你事半功倍。

如果你对这个项目感兴趣,不妨访问 https://nickcanzoneri.com/elasticsearch-settings/ 或在 GitHub 上提交反馈,共同完善这一工具!
希望这篇文章能让你对 Elasticsearch 的设置有更全面的了解。
如果你还有其他问题或想深入探讨某个设置,欢迎随时留言!
参考资料:
Elasticsearch 官方文档
bblfsh 源代码分析工具 
更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
