





点击蓝字关注我们
单 Red Hat OpenShift 集群的参考架构

尽管 EDB Postgres Distributed for Kubernetes (PGD4K) 支持跨多个 Red Hat OpenShift 集群的架构,但本文档仅重点介绍将具有 EDB PG4K 的 PostgreSQL 数据库的单点故障提升为 Red Hat OpenShift 集群,通常相当于云中的整个区域或本地部署中的数据中心。本文档中包含的建议可作为跨不同 Red Hat OpenShift 集群的更复杂架构的构建块。
在 Red Hat OpenShift 上运行业务关键型 PostgreSQL 数据库
EDB Postgres for Kubernetes 或 EDB PG4K 是 Red Hat OpenShift 的认证 Level 5 operator,旨在简化 PostgreSQL 数据库的Day 2 工作。它通过高可用性、灾难恢复、主/备用集群管理、自动故障转移、自我修复以及在线持续备份到对象存储或卷快照等功能增强了数据库管理。此外,它还支持时间点恢复 (PITR),确保强大的数据保护和恢复选项,并与业务连续性解决方案无缝集成,例如 Red Hat OpenShift API for Data Protection (OADP) 和 Veeam Kasten、Trilio、Portworx Backup、 IBM Fusion 等。
EnterpriseDB (EDB) 长期以来一直是 PostgreSQL 开发的领导者。现在,作为开源 CloudNativePG 运营商(PG4K 的核心)的创始发起人和维护者,EDB 正在推动 云原生数据库环境的创新。
借助红帽 OpenShift 和 EDB PG4K 的组合功能,可以在云原生环境中以微服务数据库的形式运行具有主要 RPO 和 RTO 目标的 PostgreSQL 关键业务数据库或作为满足内部组织需求或公共客户的数据库即服务 (DBaaS) 解决方案。Red Hat OpenShift 和 EDB PG4K 为云创造了前所未有的机会部署,无论是私有云、公有云、混合云还是多云。该堆栈在各种环境中的配置和管理方面提供最小差异,从而提供灵活性,实现数据可移植性,并消除云服务提供商级别的供应商锁定。
了解当前的 Red Hat OpenShift 架构
确保业务连续性需要全面了解基础设施的单点故障 (SPoF)、位置、缓解方法以及对停机时间、生产力和声誉的潜在影响。
Red Hat OpenShift 以及更广泛的 Kubernetes 旨在在单个集群中提供高可用性和自我修复功能。它可以跨多个数据中心或可用区 (AZ) 以及各种节点(虚拟机或物理机)运行,从而提供针对组件故障的弹性。图 1 和图 2 说明了云环境和本地的典型 Red Hat OpenShift 部署
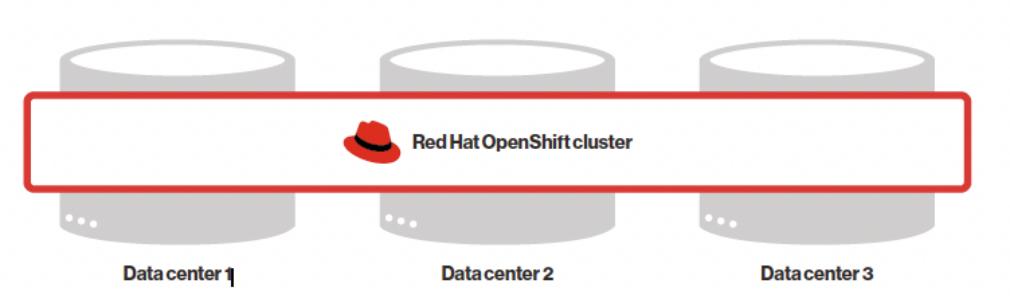
图 1.跨三个云可用区以“延伸”配置部署的 Red Hat OpenShift 集群
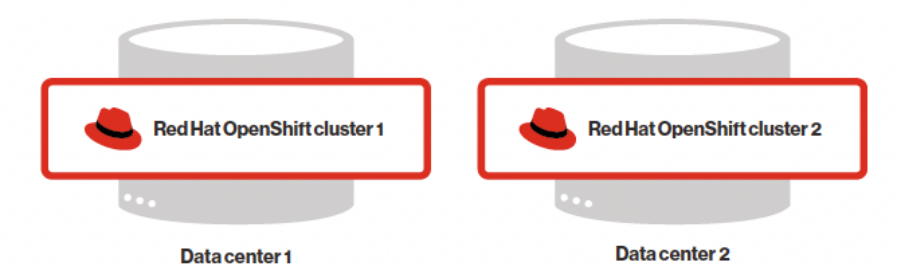
图 2.标准的 Red Hat OpenShift 本地部署,每个数据中心具有不同的集群
标准 Red Hat OpenShift 部署由三种关键类型的节点组成:
主节点(控制平面):管理集群、处理调度并运行基本服务,例如 API 服务器、调度程序和控制器管理器。
基础设施节点:托管关键基础设施组件,例如默认路由器、集成容器映像注册表以及集群指标和监控工具。
Worker 节点:运行应用程序工作负载,容器并执行Pods。
此体系结构可确保云和本地部署的高效管理和可扩展性。
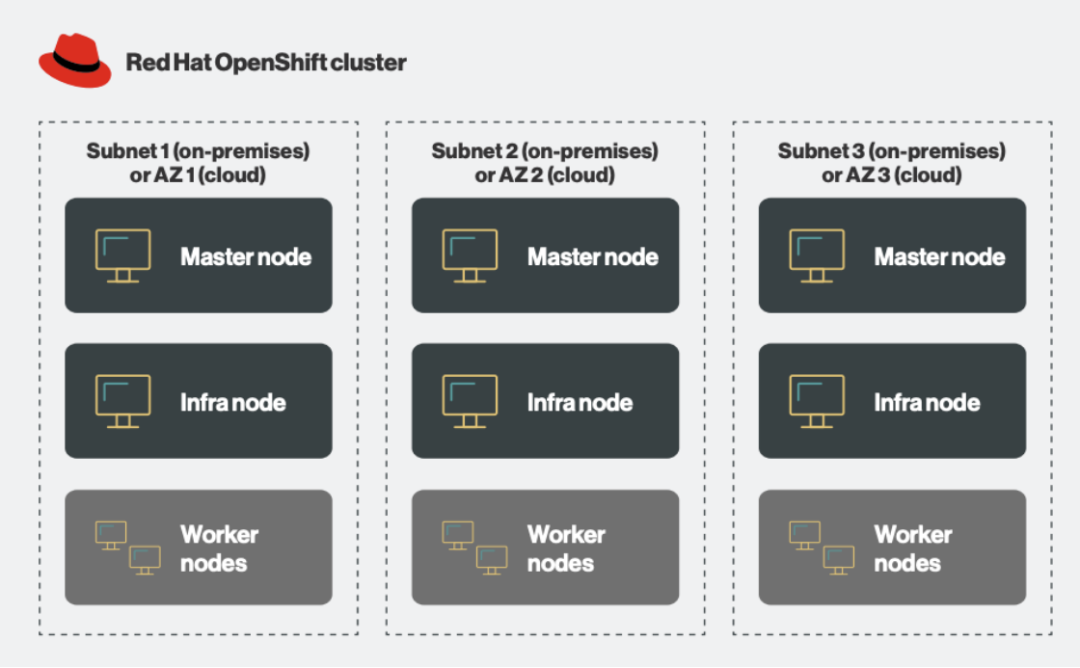
图 3.标准 Red Hat OpenShift 部署中的三种主要节点类型
在 Red Hat OpenShift 上部署 PostgreSQL 架构要考虑的事项
EDB PG4K 扩展了 Red Hat OpenShift API,以无缝管理同一 Red Hat OpenShift 集群中的 PostgreSQL 集群。它还提供了通过物理复制来缓解不同 Red Hat OpenShift 集群之间的业务连续性风险的方法 。
在 Red Hat OpenShift 上管理 PostgreSQL 数据库的关键建议:
依赖多个可用区(云)或子网(本地):利用 Red Hat OpenShift 集群中的三个可用区/子网。此配置可确保零数据丢失以实现高可用性,并在单个 Red Hat OpenShift 集群中实现非常低的恢复时间目标(RTO)。
隔离 PostgreSQL 工作负载:专门为 PostgreSQL 工作负载设置专用节点, 将它们与其他应用程序分开。使用 Red Hat OpenShift 功能(如节点标签、选择器、污点和容忍度),通过声明式配置来实施这种分离。在每个 Red Hat OpenShift 集群中为 PostgreSQL 至少预留三个节点,均匀分布在可用区/子网中。 以 3 的倍数缩放,以保持平衡和弹性。在某些情况下,可以将三个 Red Hat OpenShift Worker 节点专用于单个 PostgreSQL 集群,每个节点托管一个 PostgreSQL 实例(主实例或副本)。
信任 PostgreSQL 复制而不是存储复制:与许多在存储级别同步状态的云原生应用程序不同,PostgreSQL 通过其内置的物理复制功能独立处理状态同步,基于预写日志 (WAL) 传输。这些功能已被全球数百万用户成功用于生产十多年,包括网络上的异步和同步流复制,以及基于文件的异步日志传输,通常用作回退选项(例如,将 WAL 文件存储在对象存储中)。由于热备用功能,备用服务器或副本也可以处理只读工作负载。
这样的结果就是 PostgreSQL 工作负载与其他应用程序完全透明地物理分离,并使用 PostgreSQL 专用节点(称为“Postgres 节点”)。这些节点可以轻松添加到现有的 Red Hat OpenShift 集群中,并根据需要进行扩展。下图说明了此设置:
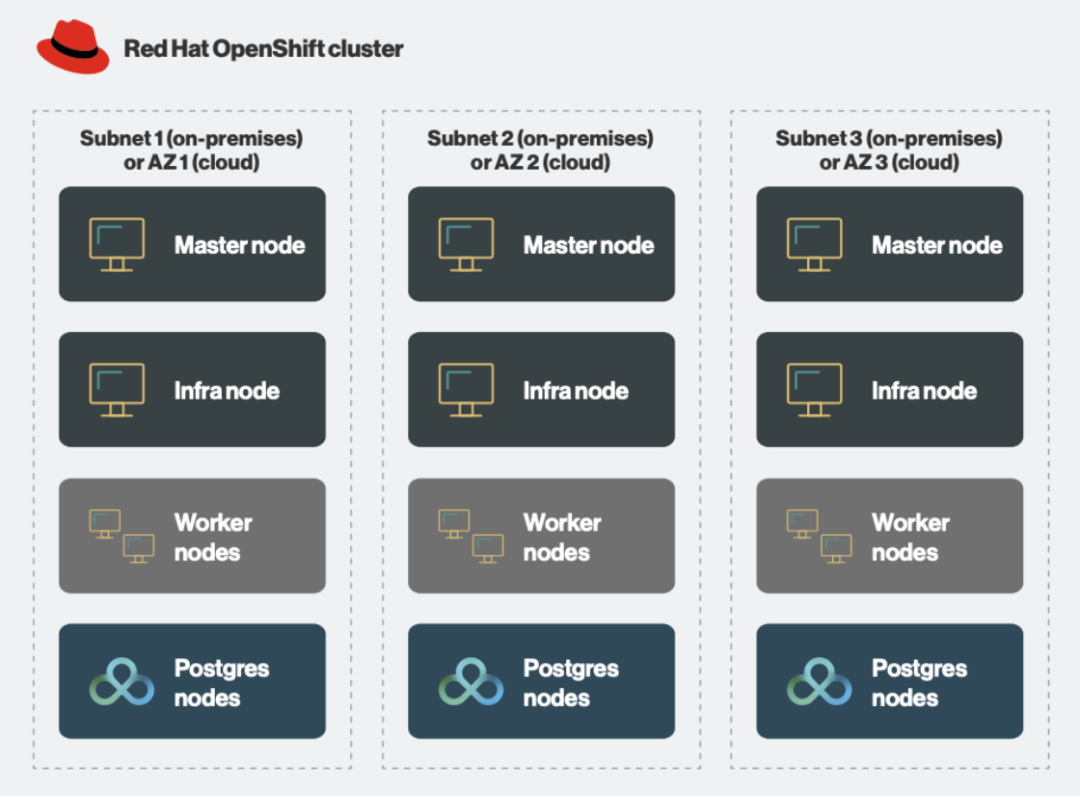
图 4.Red Hat OpenShift 上典型 EDB PG4K 部署中的四种主要节点类型
要将特定 worker 节点指定为 OpenShift 集群中的 PostgreSQL 节点,我们建议使用 node-role.kubernetes.io/postgres 标签。此标签有助于识别应处理 PostgreSQL 工作负载的节点。可以使用以下命令将标签应用于所选节点:
$ oc label node <node-name> node-role.kubernetes.io/postgres=“”
可以在这些节点上设置适当的污点(taints),以确保仅在指定的 Postgres 节点上调度 PostgreSQL 工作负载。这将防止在其上调度其他类型的工作负载,除非它们具有匹配的容忍度(tolerations)。例如,可以将以下污点添加到 PostgreSQL 节点:
$ oc adm taint nodes <node-name> node-role.kubernetes.io/postgres=:NoSchedule
通过应用此污点,节点将仅接受具有相应容忍度的 Pod,从而将其限制为 PostgreSQL 工作负载。创建它们时,请记住在 PostgreSQL 集群上设置适当的容忍度,以便它们可以在受污染的节点上调度。此方法增强了资源隔离,并确保 PostgreSQL 工作负载在最合适的环境中运行。
存储注意事项
EDB PG4K 依赖存储类,直接管理文件系统 PersistentVolumeClaim (PVC) 资源 而不是 StatefulSets,以便对数据库文件进行更精细的控制。
尽管与存储无关,但数据库工作负载需要性能和数据持久性,这只能通过在生产前进行适当的基准测试来确保。在大多数情况下,最好使用附加到 worker 节点的本地存储。
推荐的 PostgreSQL 架构
EDB PG4K 利用 PostgreSQL 原生物理复制:
在单个 Red Hat OpenShift 中管理单个主/多个备用 PostgreSQL 集群,用于 HA 目的,使用流式复制,包括同步复制;此设置提供自动故障转移、自我修复和滚动升级功能。
实施对不可变对象存储的持续备份,这对于完全恢复和 PITR 至关重要, 最大 RPO 为 5 分钟。
此外,EDB PG4K 通过跨多个Red Hat OpenShift集群实施分布式的active/passive拓朴结构及跨region对象存储(RPO ≤ 5 分钟)和/或流复制(接近零的 RPO,取决latency)。
在 Red Hat OpenShift 集群中,EDB PG4K 提供了名为 Cluster 的自定义资源定义 (CRD) 来管理高可用性 PostgreSQL 集群。此集群具有单个主和多个副本,这些副本在发生意外事件(例如,自动故障转移)或计划内作期间(例如,在 Red Hat OpenShift 节点更新后进行切换)时可以成为主服务器。
对于应用程序路由,EDB PG4K 会自动维护一组 Red Hat OpenShift 服务对象,通常为 ClusterIP 类型,用于将流量定向到主或只读副本。这些服务可以通过service模板轻松配置,包括负载均衡器,以便在需要时从 Red Hat OpenShift 外部提供对数据库的外部访问 。
EDB PG4K 支持高级调度功能,例如 Pod 亲和性和反亲和性、节点选择器和容忍度。这些功能通过确保每个 PostgreSQL 实例在不同的节点上运行,并在可能的情况下,在不同的可用区/子网中运行,来帮助管理单点故障。
下图描述了通过基于仲裁的同步复制实现高可用性的单个 PostgreSQL 集群的典型架构(可用区/子网用虚线标记 ):
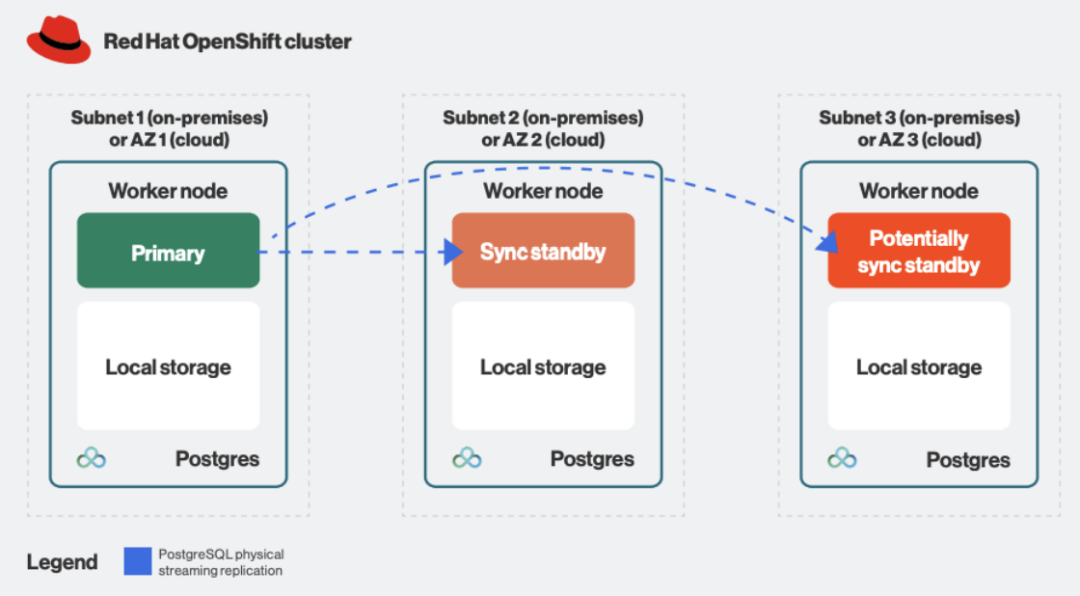
图 5.高可用 PostgreSQL 集群的典型架构
根据设计,在上述情况下,保证数据库中的每个提交事务都使用 PostgreSQL 基于原生仲裁的同步复制写入副本,从而确保 RPO 为零以实现高可用性。鉴于 Red Hat OpenShift 可以立即检测到主副本上的故障,因此故障转移时间通常只是将最高级副本提升为主状态所需的时间,通常总共在一分钟内。鉴于坚实的底层基础设施,这使得实现 99.99% 的正常运行时间成为一个现实的目标。
关于灾难恢复,EDB PG4K 允许通过基本备份和 WAL 存档设置 PostgreSQL 集群的连续备份,默认情况下,最大 RPO 为 5 分钟。
在最简单的场景中,这两个组件都可以驻留在本地对象存储中,如果使用的是云(例如 AWS S3、Azure Blob Storage、Google Cloud Storage),也可以使用 Red Hat OpenShift Data Foundation (ODF) 对象存储等专用产品。如果存储类支持它们,EDB PG4K 还允许使用卷快照执行备份和恢复。对象存储和卷快照具有不同保留策略的混合策略也是可能的。
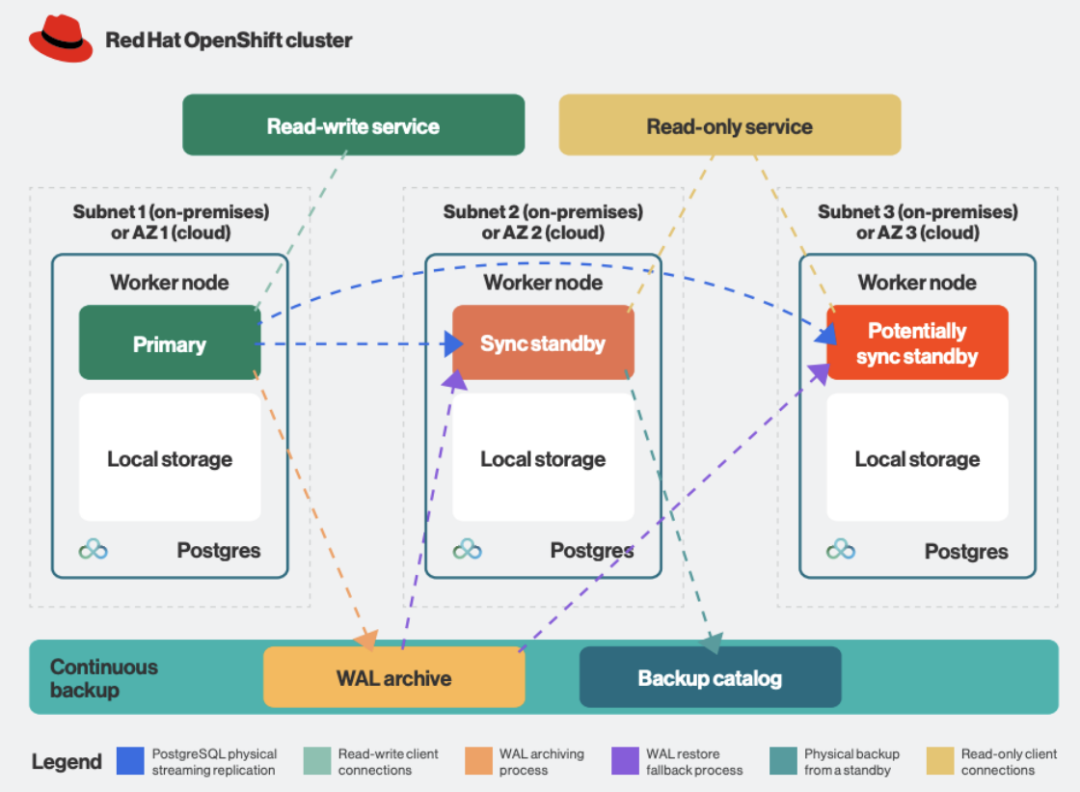
图 6.高可用性 PostgreSQL 集群的典型架构,服务和持续备份
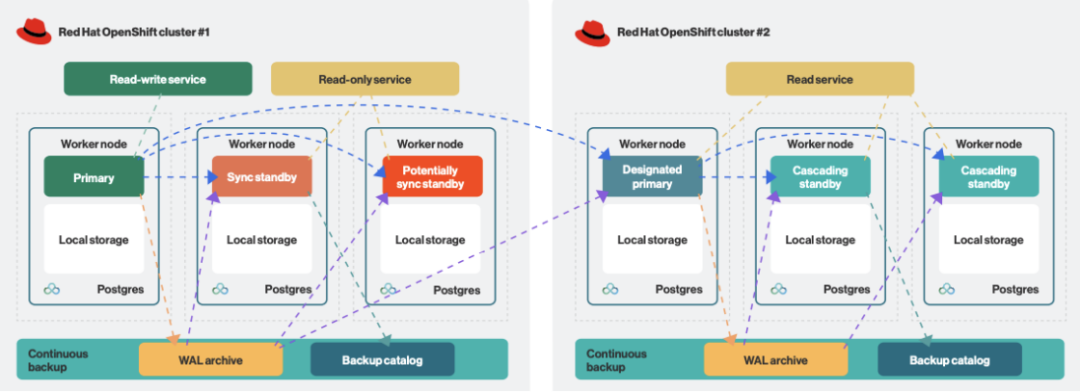
图 7.跨两个 Red Hat OpenShift 集群进行级联复制的 Postgres 集群的示例架构
本文旨在将单个 Red Hat OpenShift 集群描绘成由 EDB PG4K 管理的每个 PostgreSQL 集群的单点故障(SPoF)。在云环境中,SPoF 通常是区域,这得益于可用区的存在。在大多数本地环境中,SPoF 则相当于一个数据中心。在这两种情况下,EDB PG4K 均可透明且无缝地为 Red Hat OpenShift 集群内的每个 PostgreSQL 集群处理高可用性和灾难恢复。EDB PG4K 可配置备份策略,以实现极低的恢复时间目标(RTO)和有保证的恢复点目标(RPO)。
最为关键的建议是专门配置工作节点以运行 PostgreSQL 工作负载,从而确保性能的可预测性。每个 Red Hat OpenShift 集群应从三个 PostgreSQL 工作节点开始,并在这些节点上设置污点(taints),以确保只有由 EDB PG4K 管理的 PostgreSQL 工作负载能够在这些节点上运行。当 Red Hat OpenShift 集群无法容纳更多的 PostgreSQL 集群时,可以按照每次添加三个的倍数增加工作节点,同时采用相同的基于污点的方法。
在选择存储组件时,需要仔细评估,并考虑将本地存储直接挂载到每个工作节点上,尤其是当您计划使用裸金属服务器运行 PostgreSQL 时。无论如何,务必根据 EDB PG4K 的文档对存储和数据库进行基准测试。
对于 PostgreSQL,建议采用三实例集群配置,其中包括一个主节点和两个副本节点,并配置基于法定人数的同步复制,确保其中一个副本能够实现同步复制。这种设置可确保高可用性且无数据丢失。至少应确保通过配置 pod 反亲和性规则使每个实例位于不同的工作节点上。这种配置还确保了在 Red Hat OpenShift 层进行节点维护时,会触发每个 PostgreSQL 集群的滚动更新,从而将停机时间降至最低。这种架构被称为无共享架构。
通过使用 EDB PG4K,可以在 Red Hat OpenShift 基础设施内实现高度集成的 PostgreSQL 集群,包括安全性、可观测性、日志记录等功能。一旦 Red Hat OpenShift 集群成为每个 PostgreSQL 集群的 SPoF,即可利用 EDB PG4K 的功能,例如对称架构、级联复制以及分布式拓扑中的副本集群,将高可用性和灾难恢复扩展到更多的 Red Hat OpenShift 集群。
这些功能完全采用声明式方式,使其适合跨多个 Red Hat OpenShift 集群进行基础架构即代码(IaC)管理。这对于在单个数据中心内进行的本地 Red Hat OpenShift 部署至关重要。尽管在这种情况下,EDB PG4K 无法自动控制超越 Red Hat OpenShift 集群范围的自动故障转移,这需要外部干预。
参考EDB官方白皮书
https://www.enterprisedb.com/sites/default/files/2024-10/Reference-Architecture_High-Availability-and-Disaster-Recovery-of-PostgreSQL-Databases-with-EDB-and-Red-Hat-OpenShift.pdf
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
