




前言
春节前期南方政务某现场搭建了大规模100节点ES集群。最近开始上线新业务流程:FlinkCDC将业务数据库日志写入Kafka,然后Flink消费Kafka数据写入ES集群。新业务流程上线以后不能长时间稳定运行,差不多每隔24H都会失败重启。本文从异常日志出发,虽然中间走了弯路,最终定位清楚解决故障现象。笔者文章只发布微信公众号:大数据从业者,其他均为转载,欢迎关注转发!

现象描述
据客户研发反馈,每次故障期间查看Flink日志都存在大量连接ES集群的IO异常,如下:
Caused by: java.lang.IllegalStateException: Request cannot be executed; I/O reactor status: STOPPED

根据笔者经验只要有异常日志都不可能是啥疑难杂症,只需以异常日志入手排查即可。之所以这么讲是因为回想起N年前某高校校园集群的一次故障现象:系统内核日志和组件日志等都没异常,但是服务老异常,最后耗时数周发现是中毒了!!言归正传,继续说回到这个问题。
问题分析
根据上述IO异常的日志记录,刚开始以为是ES集群瓶颈或者机房网络异常(这个很常见,仅网线没插牢固这一点就见过好几次)之类的。但是,一通排查之后,都未见异常。检索了相关资源说是elasticsearch-rest-high-level-client引入的httpclient版本太低有相关bug,会导致上述IO异常。从flink-connector-elasticsearch源码pom来看,httpcore-nio已经重新引入为新版本,如图:
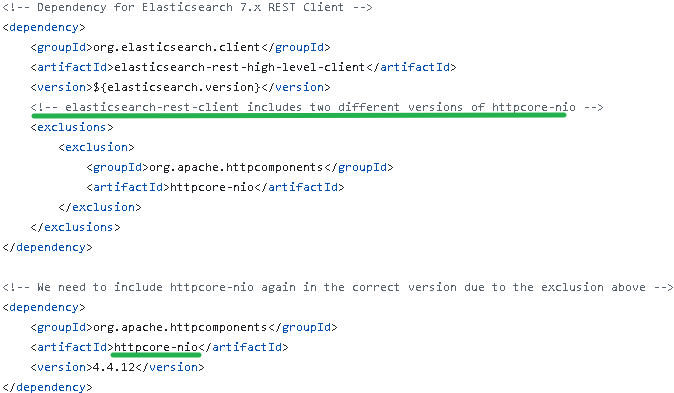
尝试通过exclusion将httpclient、httpcore-nio、httpcore等都排除后都重新引入了最高版本,如下所示:
<dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.14</version></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpcore-nio</artifactId><version>4.4.16</version></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpcore</artifactId><version>4.4.16</version></dependency>
Caused by: java.lang.OutOfMemoryError: Direct buffer memory

确认了上次的日志,也存在OOM异常,只不过客户没看到。至此,那算是从弯路走上正道了!
解决措施
基于上述分析基本确认根因就是:堆外内存Driect memory OOM造成的IO异常。NIO确实是会使用堆外内存的,那就是Flink作业配置的堆外内存不够用,尝试调大继续观察。TaskManager堆外内存默认值为128M,通过参数-Dtaskmanager.memory.framework.off-heap.size=1G调大。
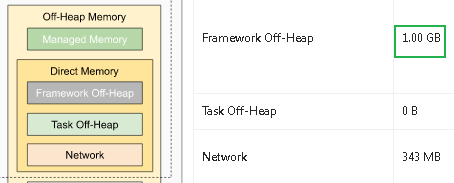
保险起见,通过NMT跟踪一段时间内的堆外内存使用情况:
-Denv.java.opts.taskmanager=-XX:NativeMemoryTracking=summaryjcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale=KB | MB | GB]
经过NMT跟踪观察,堆外内存DirectMemory也就是Internal committed稳定在1G以内。笔者文章只发布微信公众号:大数据从业者,其他均为转载,欢迎关注转发!
场景复现
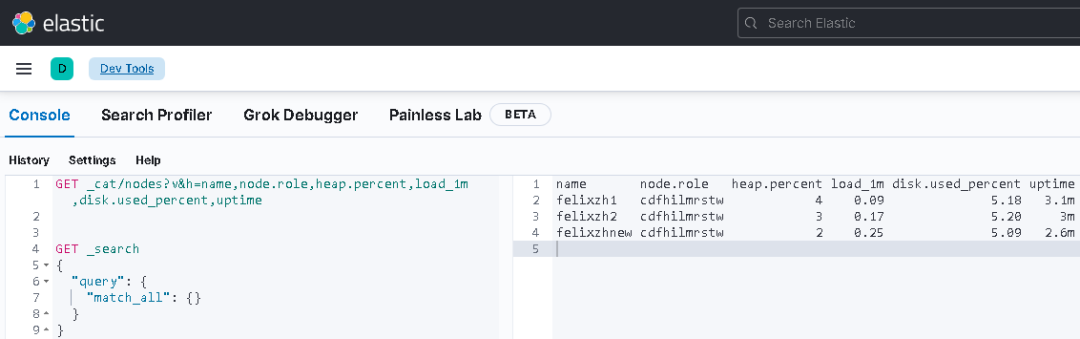
本来实验室尝试复现问题现象的,但是无奈机器资源有限,未果。这里记录下ES、Kibana本地化部署实践记录。
ES部署
cat <<EOF > etc/yum.repos.d/es.repo[es7.x]name=Elasticsearch7.xbaseurl=https://mirrors.tuna.tsinghua.edu.cn/elasticstack/7.x/yum/gpgcheck=1gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearchenabled=1EOF
yum install -y elasticsearch-7.17.7
服务脚本/usr/lib/systemd/system/elasticsearch.service
mkdir -p /opt/disk/elasticsearchchown -R elasticsearch:elasticsearch /opt/disk/elasticsearchmkdir -p /var/log/elasticsearch/chown -R elasticsearch:elasticsearch /var/log/elasticsearch/
vim etc/elasticsearch/elasticsearch.yml
cluster.name: my-applicationnode.name: felixzhnewpath.data: /opt/disk/elasticsearchpath.logs: /var/log/elasticsearchbootstrap.memory_lock: truenetwork.host: felixzhnewhttp.port: 9200discovery.seed_hosts: ["felixzhnew", "felixzh1", "felixzh2"]cluster.initial_master_nodes: ["felixzhnew", "felixzh1", "felixzh2"]xpack.security.enabled: false
systemctl start elasticsearchsystemctl status elasticsearch
vim etc/elasticsearch/jvm.options
-Dcom.sun.management.jmxremote.port=9999-Dcom.sun.management.jmxremote.ssl=false-Dcom.sun.management.jmxremote.authenticate=false-Djava.rmi.server.hostname=felixzhnew
Kibana部署
复用/etc/yum.repos.d/es.repo即可!
yum install kibana
服务脚本/etc/systemd/system/kibana.service
vim etc/kibana/kibana.yml
server.port: 5601server.host: "felixzhnew"elasticsearch.hosts: ["http://felixzhnew:9200","http://felixzh1:9200","http://felixzh2:9200"]xpack.security.enabled: false
systemctl start kibanasystemctl status kibana
结束
本文主要通过客户反馈日志解决Flink作业堆外内存OOM现象,涉及NMT等内容。强电一点,眼见为实耳听为虚!客户描述内容谨慎核实。笔者文章只发布微信公众号:大数据从业者,其他均为转载,欢迎关注转发!
