





点击蓝字关注我们
前言
随着现代应用程序产生的时序数据量不断增长,如何高效地存储、管理和查询这些数据成为了一个重要挑战。Elasticsearch 在 7.9 版本中引入了 Data streams 功能,为时序数据管理提供了一个优雅的解决方案。本文将深入探讨 Data streams 的概念、优势、使用方法以及最佳实践。
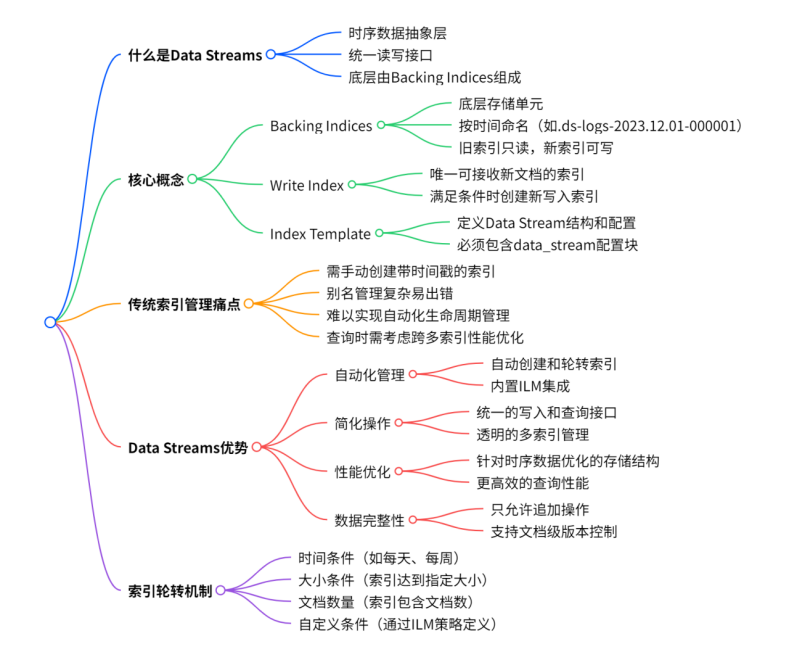
什么是 Data Streams
Data streams 是 Elasticsearch 中用于管理时序数据的抽象层。它将多个相关的索引(称为 backing indices)组织在一起,为用户提供统一的数据写入和查询接口。从用户角度来看,Data stream 就像一个单一的索引,但在底层,它由多个按时间顺序排列的索引组成。
核心概念
Backing Indices(后备索引)
Data stream 的底层存储单元
按时间顺序命名,如 .ds-logs-2023.12.01-000001
只有最新的索引可以接收写入操作
旧索引变为只读状态
Write Index(写入索引)
Data stream 中唯一可以接收新文档的索引
当满足轮转条件时,会创建新的写入索引
Index Template(索引模板)
定义 Data stream 的结构和配置
必须包含 data_stream 配置块
为什么需要 Data Streams
传统索引管理的痛点
在 Data streams 出现之前,管理时序数据通常需要:
# 手动创建带时间戳的索引PUT logs-2023.12.01PUT logs-2023.12.02PUT logs-2023.12.03# 使用别名管理多个索引POST _aliases{"actions": [{"add": {"index": "logs-2023.12.*", "alias": "logs"}}]}
这种方式存在以下问题:
需要手动管理索引的创建和轮转
别名管理复杂,容易出错
难以实现自动化的生命周期管理
查询时需要考虑跨多个索引的性能优化
Data Streams 的优势
1. 自动化管理
自动创建和轮转索引
无需手动管理索引生命周期
内置与 ILM(Index Lifecycle Management)的集成
2. 简化操作
统一的写入和查询接口
透明的多索引管理
减少运维复杂度
3. 性能优化
针对时序数据优化的存储结构
更高效的查询性能
支持并行处理
4. 数据完整性
只允许追加操作,保证数据不被意外修改
支持文档级别的版本控制
Data Streams 的工作原理
数据写入流程
graph TD
A[客户端写入请求] --> B[Data Stream]
B --> C[路由到写入索引]
C --> D[检查轮转条件]
D -->|满足条件| E[创建新的写入索引]
D -->|不满足| F[写入当前索引]
E --> G[更新写入索引指针]
G --> F
索引轮转机制
索引轮转可以基于多种条件触发:
时间条件:如每天、每周轮转
大小条件:索引达到指定大小
文档数量:索引包含的文档数量
自定义条件:通过 ILM 策略定义
Data streams的脉络图:
实战:创建和使用 Data Streams
步骤1:创建索引模板
PUT _index_template/logs-template{"index_patterns": ["logs-*"],"data_stream": {},"template": {"settings": {"number_of_shards": 1,"number_of_replicas": 1,"index.lifecycle.name": "logs-lifecycle-policy"},"mappings": {"properties": {"@timestamp": {"type": "date"},"service": {"type": "keyword"},"level": {"type": "keyword"},"message": {"type": "text","analyzer": "standard"},"host": {"type": "keyword"},"user_id": {"type": "keyword"}}}},"priority": 200,"composed_of": ["logs-mappings", "logs-settings"],"_meta": {"description": "Template for application logs data stream"}}
步骤2:配置生命周期策略
PUT _ilm/policy/logs-lifecycle-policy{"policy": {"phases": {"hot": {"actions": {"rollover": {"max_size": "10GB","max_age": "7d","max_docs": 10000000},"set_priority": {"priority": 100}}},"warm": {"min_age": "7d","actions": {"set_priority": {"priority": 50},"allocate": {"number_of_replicas": 0},"forcemerge": {"max_num_segments": 1}}},"cold": {"min_age": "30d","actions": {"set_priority": {"priority": 0},"allocate": {"number_of_replicas": 0}}},"delete": {"min_age": "90d","actions": {"delete": {}}}}}}
步骤3:写入数据
# 第一次写入会自动创建 data streamPOST logs-application/_doc{"@timestamp": "2023-12-01T10:00:00Z","service": "user-service","level": "INFO","message": "User authentication successful","host": "server-01","user_id": "user123"}# 批量写入POST logs-application/_bulk{"index":{}}{"@timestamp":"2023-12-01T10:01:00Z","service":"order-service","level":"ERROR","message":"Database connection failed","host":"server-02"}{"index":{}}{"@timestamp":"2023-12-01T10:02:00Z","service":"payment-service","level":"WARN","message":"Payment processing delayed","host":"server-03"}
步骤4:查询数据
# 简单查询GET logs-application/_search{"query": {"range": {"@timestamp": {"gte": "2023-12-01T00:00:00Z","lte": "2023-12-01T23:59:59Z"}}}}# 聚合查询GET logs-application/_search{"size": 0,"aggs": {"services": {"terms": {"field": "service","size": 10},"aggs": {"levels": {"terms": {"field": "level"}}}},"error_timeline": {"filter": {"term": {"level": "ERROR"}},"aggs": {"timeline": {"date_histogram": {"field": "@timestamp","calendar_interval": "1h"}}}}}}
高级特性和配置
1. 自定义索引命名
PUT _index_template/custom-logs-template{"index_patterns": ["custom-logs-*"],"data_stream": {},"template": {"settings": {"index.lifecycle.name": "custom-logs-policy","index.lifecycle.rollover_alias": "custom-logs"}}}
2. 多租户 Data Streams
# 为不同租户创建独立的 data streamsPOST logs-tenant-a/_doc{"@timestamp": "2023-12-01T10:00:00Z", "tenant": "tenant-a", "message": "Tenant A log"}POST logs-tenant-b/_doc{"@timestamp": "2023-12-01T10:00:00Z", "tenant": "tenant-b", "message": "Tenant B log"}
3. 跨集群复制
# 在从集群上配置跨集群复制PUT _ccr/follow/logs-replica{"remote_cluster": "primary-cluster","leader_index": "logs-application","follow_index": "logs-application-replica"}
监控和管理
查看 Data Stream 信息
1.列出所有 data streams
GET _data_stream
2.查看特定 data stream 的详细信息
GET _data_stream/logs-application
3.查看 backing indices
GET logs-application/_ilm/explain
性能监控
# 监控索引统计信息GET logs-application/_stats# 查看分片分配情况GET _cat/shards/logs-application?v# 监控 ILM 策略执行状态GET logs-application/_ilm/explain
故障排查
# 检查模板匹配情况GET _index_template/logs-template# 查看索引健康状态GET _cluster/health/logs-application# 检查写入索引状态GET _cat/indices/.ds-logs-application-*?v&s=index
最佳实践
1. 合理设计索引模板
PUT _index_template/optimized-logs-template{"index_patterns": ["logs-*"],"data_stream": {},"template": {"settings": {"number_of_shards": 1,"number_of_replicas": 1,"refresh_interval": "30s","index.lifecycle.name": "logs-policy","index.codec": "best_compression","index.sort.field": "@timestamp","index.sort.order": "desc"}}}
2. 优化 ILM 策略
Hot 阶段:设置合理的轮转条件,避免索引过大或过小
Warm 阶段:减少副本数,执行段合并
Cold 阶段:进一步降低存储成本
Delete 阶段:根据数据保留策略及时删除过期数据
3. 监控关键指标
写入性能和延迟
索引轮转频率
存储空间使用情况
查询性能
4. 安全考虑
# 配置索引级别的安全策略PUT _security/role/logs-reader{"indices": [{"names": ["logs-*"],"privileges": ["read", "view_index_metadata"]}]}
性能优化技巧
1. 分片策略
根据数据量和查询模式确定分片数量
避免过多小分片,影响集群性能
考虑使用索引排序提高查询效率
2. 映射优化
{"mappings": {"properties": {"@timestamp": {"type": "date"},"message": {"type": "text","index": false, // 如果不需要全文搜索"doc_values": false},"status_code": {"type": "integer"},"ip_address": {"type": "ip","ignore_malformed": true}}}}
3. 查询优化
使用时间范围过滤器
利用索引排序特性
合理使用聚合和分析
常见问题和解决方案
1. Data Stream 无法写入
问题:新建的 data stream 无法接收数据
解决方案:
检查索引模板是否正确配置
验证文档是否包含 @timestamp 字段
确认集群状态正常
2. 索引轮转不按预期执行
问题:ILM 策略没有按预期轮转索引
解决方案:
# 手动执行 ILM 策略
POST logs-application/_ilm/retry
# 检查 ILM 状态
GET _ilm/status
3. 查询性能问题
问题:跨多个 backing indices 的查询性能较差
解决方案:
使用时间范围过滤器限制查询范围
优化索引设置和映射
考虑使用索引排序
总结
Data streams 是 Elasticsearch 为时序数据管理提供的强大功能,它简化了索引管理、提高了运维效率,并提供了更好的性能表现。通过合理的配置和最佳实践,Data streams 可以显著改善时序数据的存储和查询体验。
在实际应用中,建议从小规模开始尝试,逐步优化配置参数,并建立完善的监控体系。随着对 Data streams 理解的深入,你将能够充分发挥其在大规模时序数据处理中的优势。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
