




1、之前视频讲解了 RAG 系统
相对比较复杂。
需要部署:Elasticsearch、FSCrawler、通义本地模型、ollama、Gradio 等。
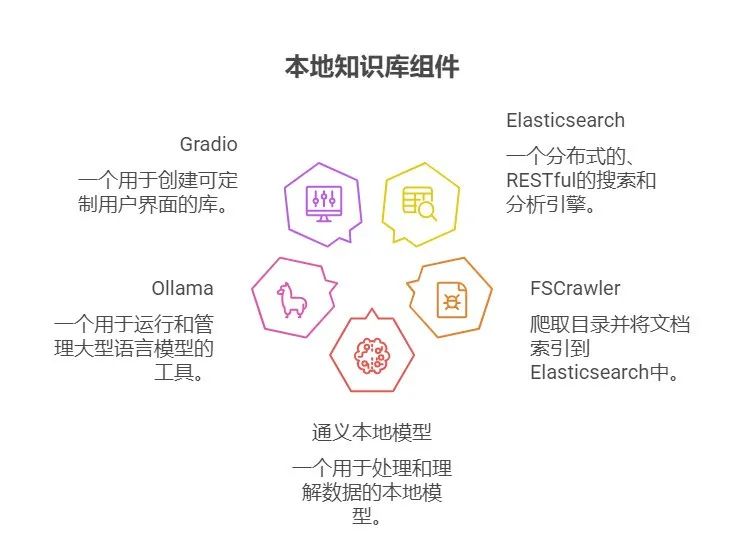
全部前后端代码都需要自己实现,有一定的学习成本。 那有没有极简的方式构建呢?
之前一篇文章介绍了:《如何将 Coco AI 与自定义数据源集成 ?》 基于这个自定义数据源的思路,再进一步呢?
其实再进一步就是本文题目的内容了。
2、基于 Coco AI 的本地文档知识库+智能问答系统效果图
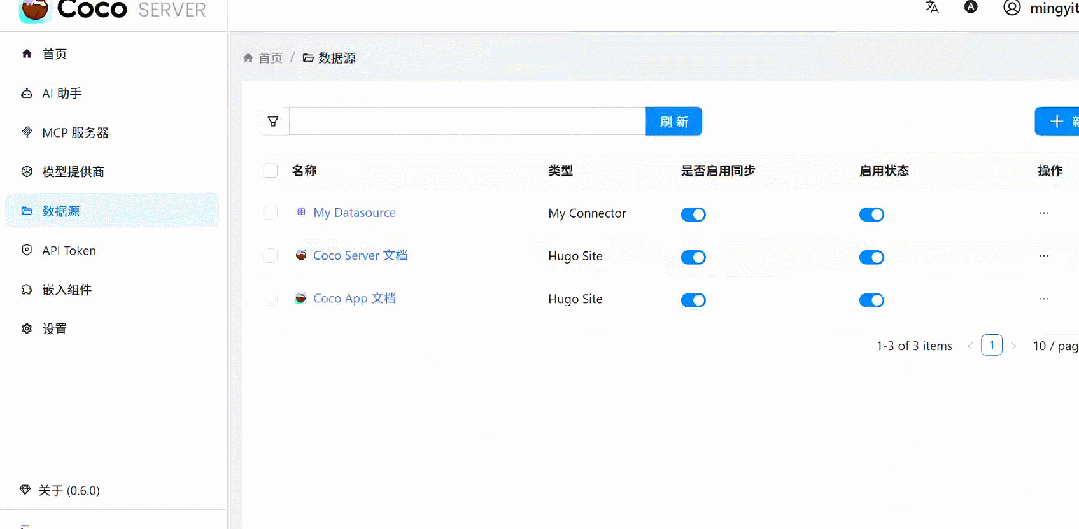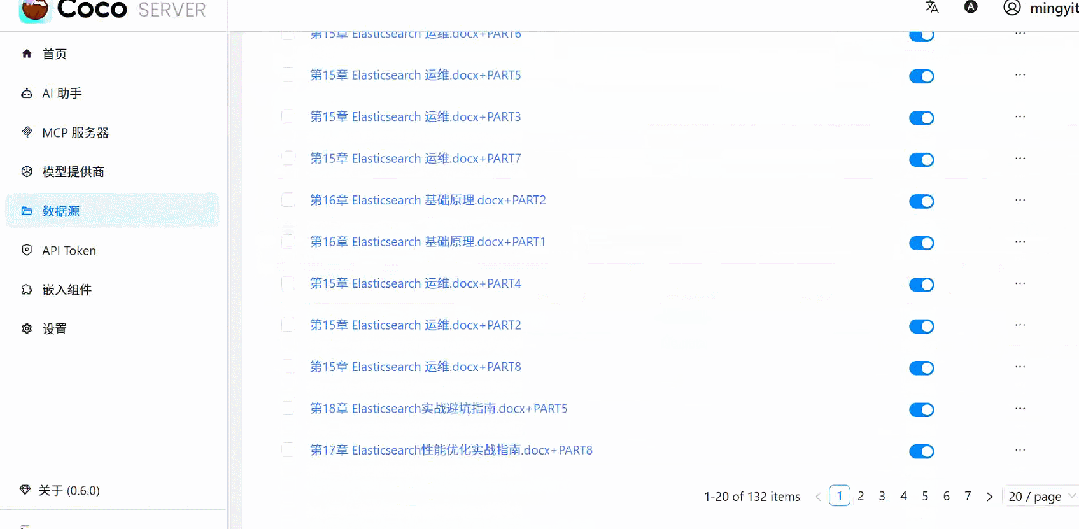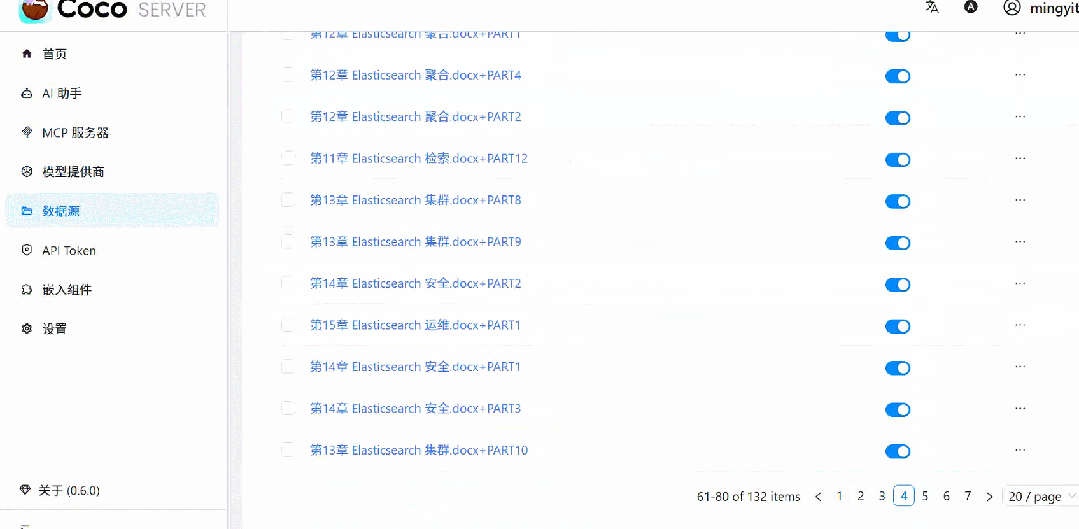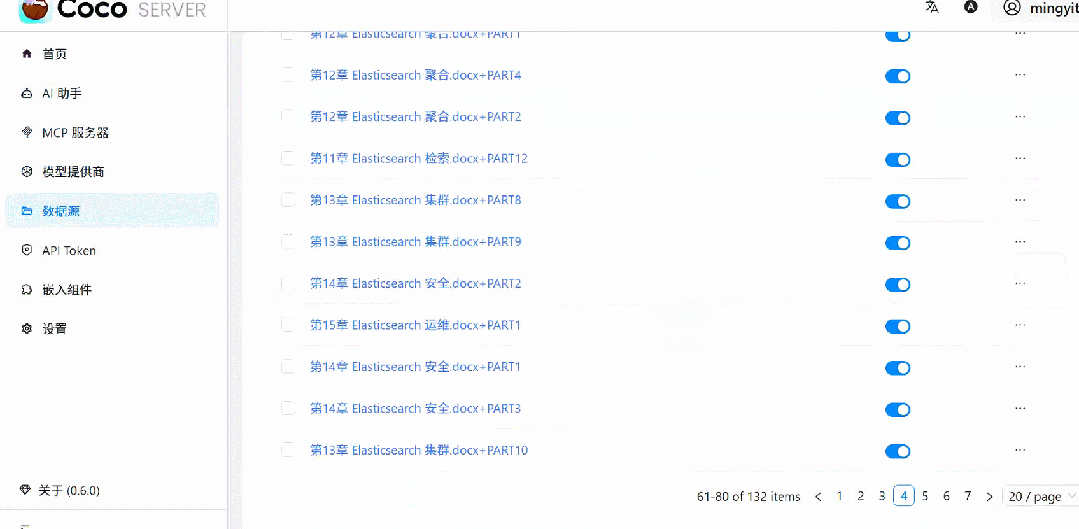
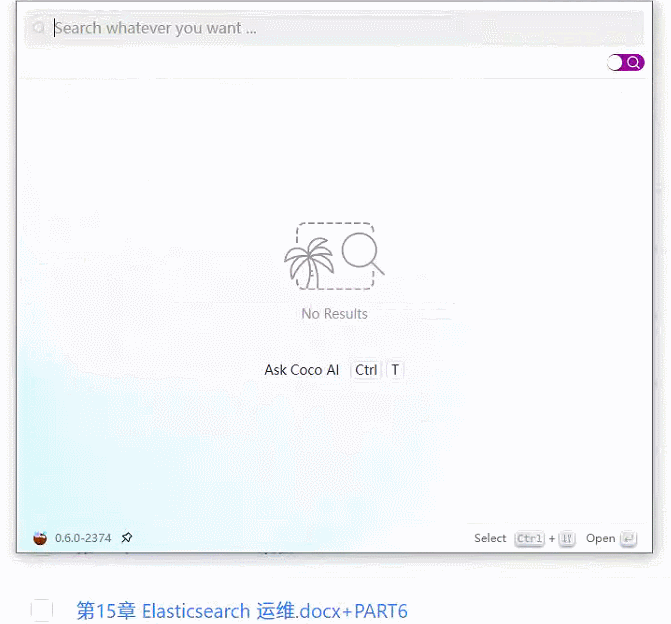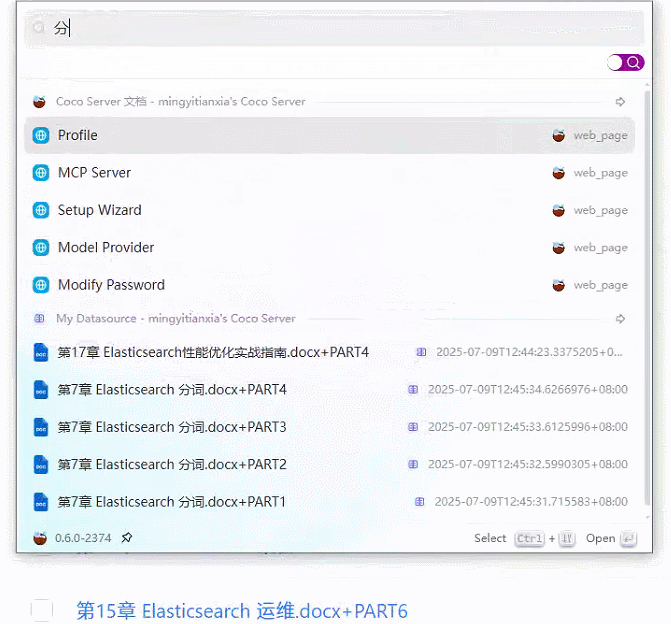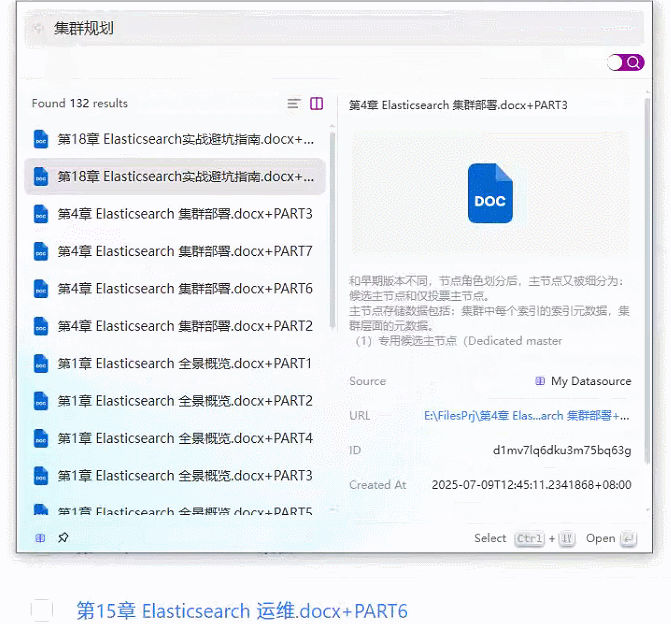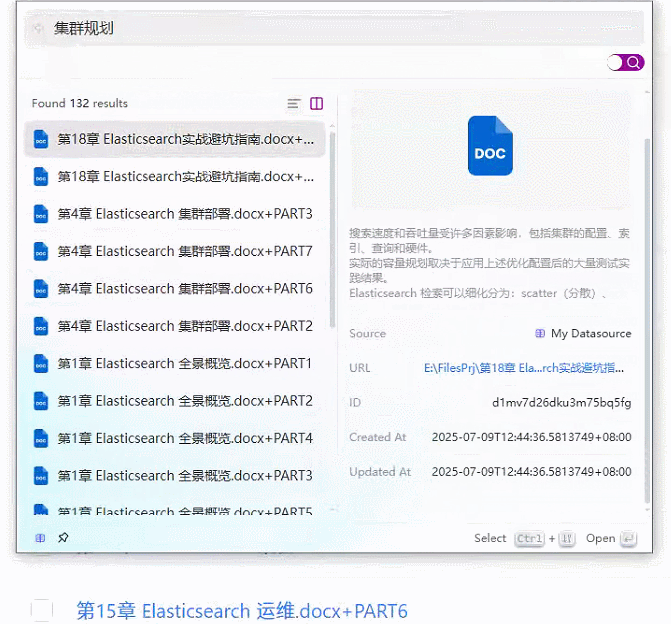
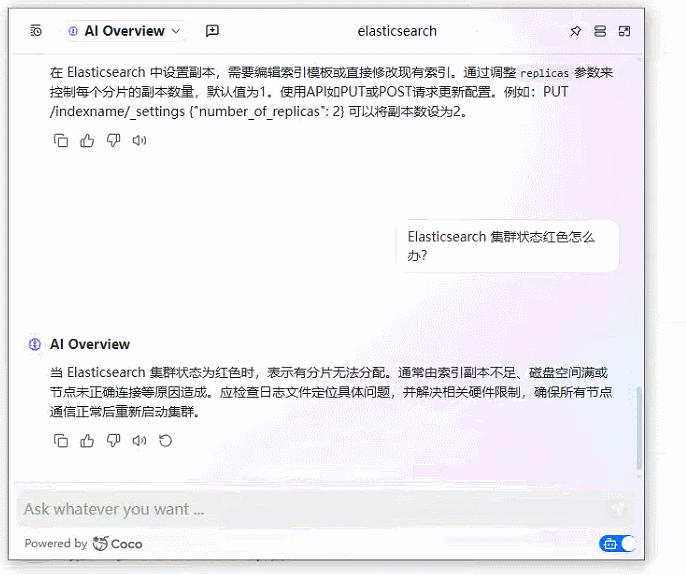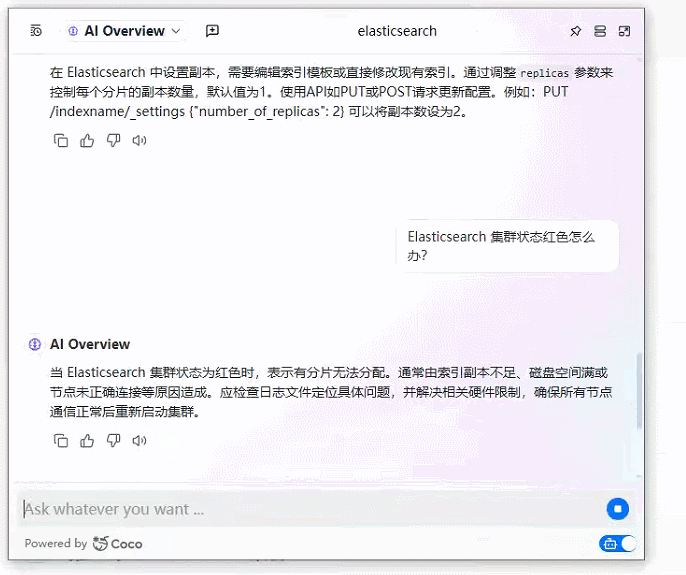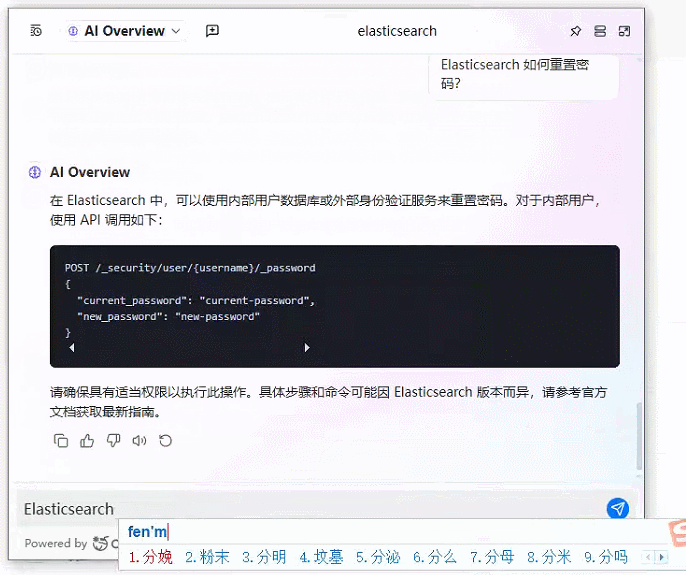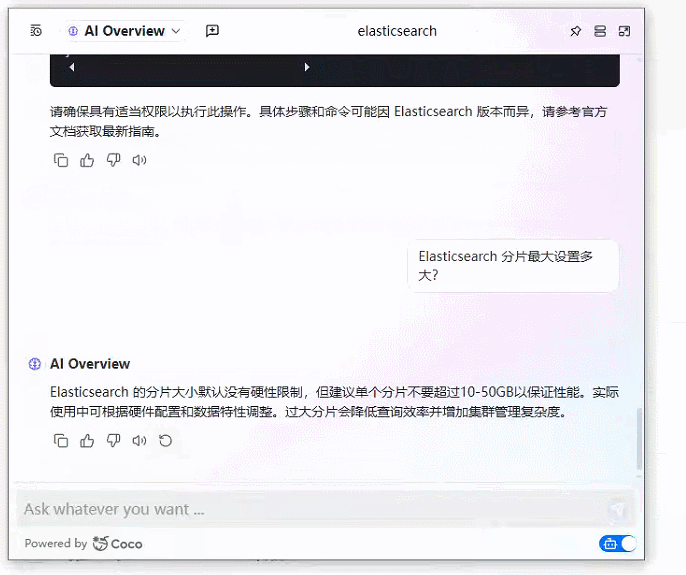
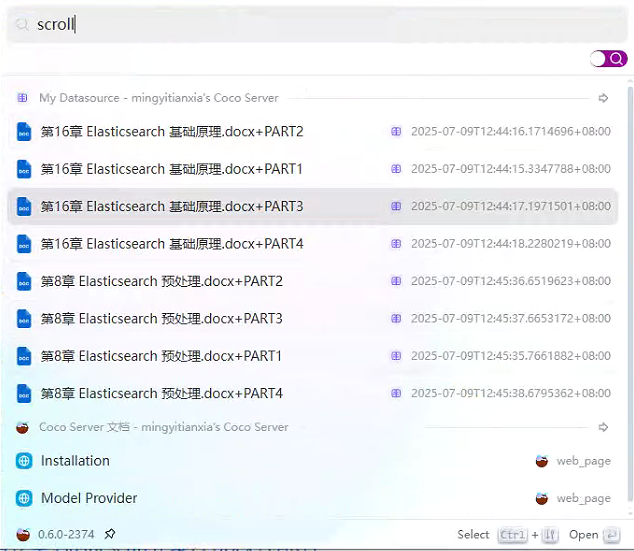
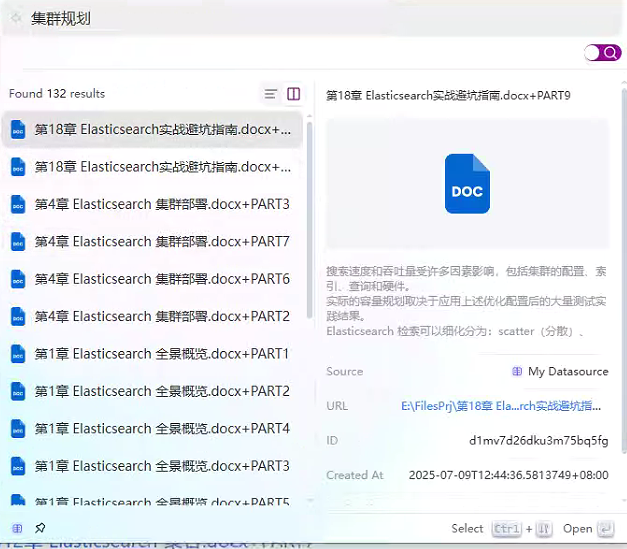
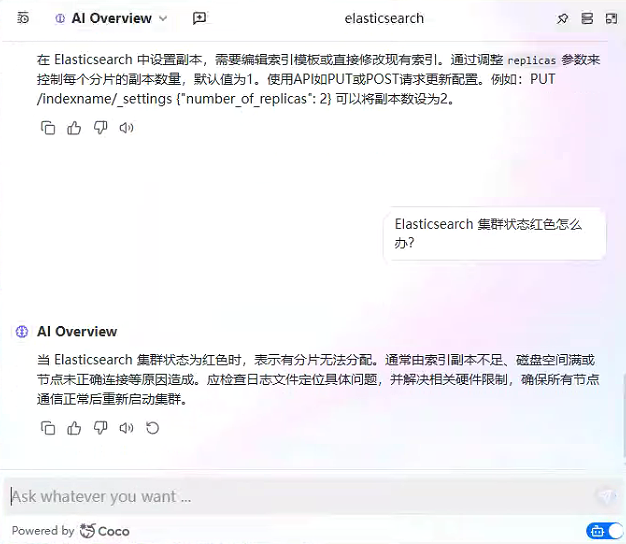
3、基于 Coco AI 的本地文档知识库+智能问答系统完整实现步骤
3.1 前置部署要求
Step1:安装 Easysearch Step2: 安装 Cocoserver 服务器端 Step3:安装 Coco APP 客户端
Step4: 安装 ollama,且部署好本地相关模型 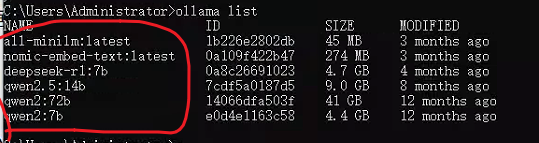
3.2 创建数据源
step1 :创建连接器。

Step2:基于连接器创建数据源。 上一步生成的连接器 id:d1mv3g26dku3m75bq3d0 可以用来创建数据源。

数据源唯一id:d1mv5ci6dku3m75bq3tg。
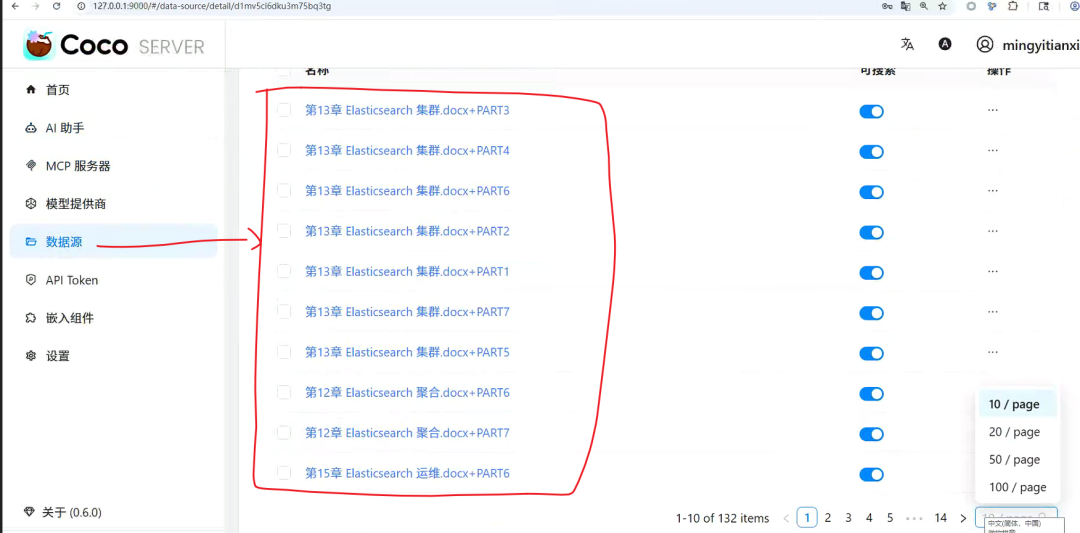
创建完数据源结构如下图所示:
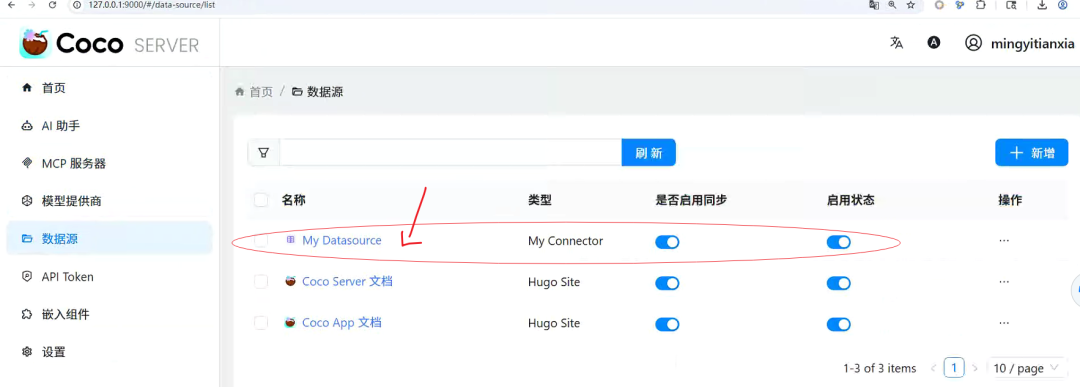
特别说明:目前这里只支持 API 方式生成,0.6 版本不支持通过可视化界面配置生成。
3.3 确保CocoServer 服务端相关配置ok
3.3.1 模型提供部分本地模型设置没有问题。
基于 ollama 本地部署的模型进行添加。
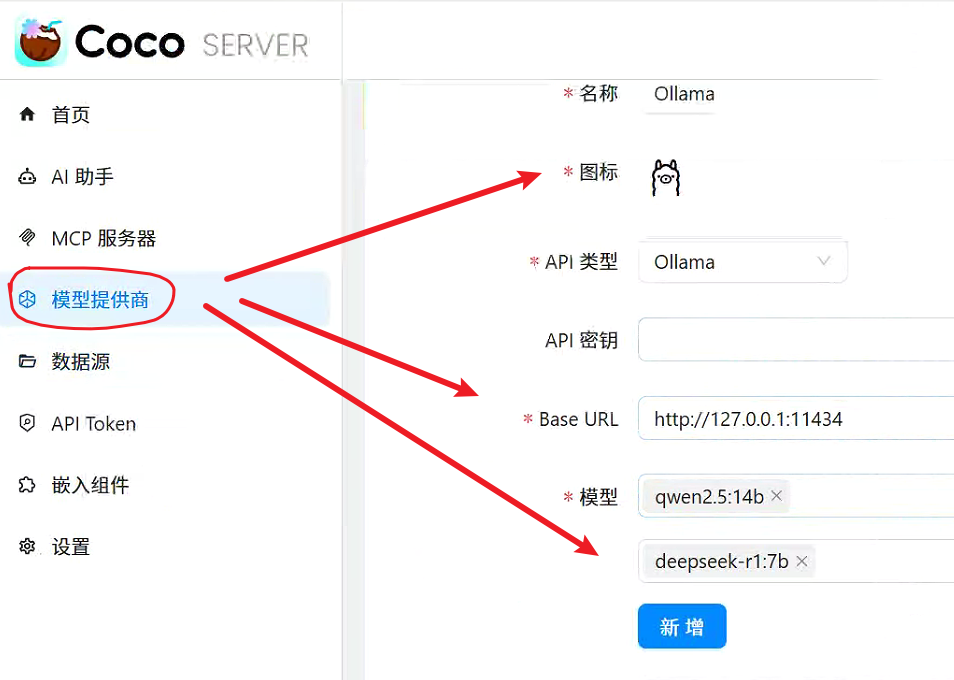
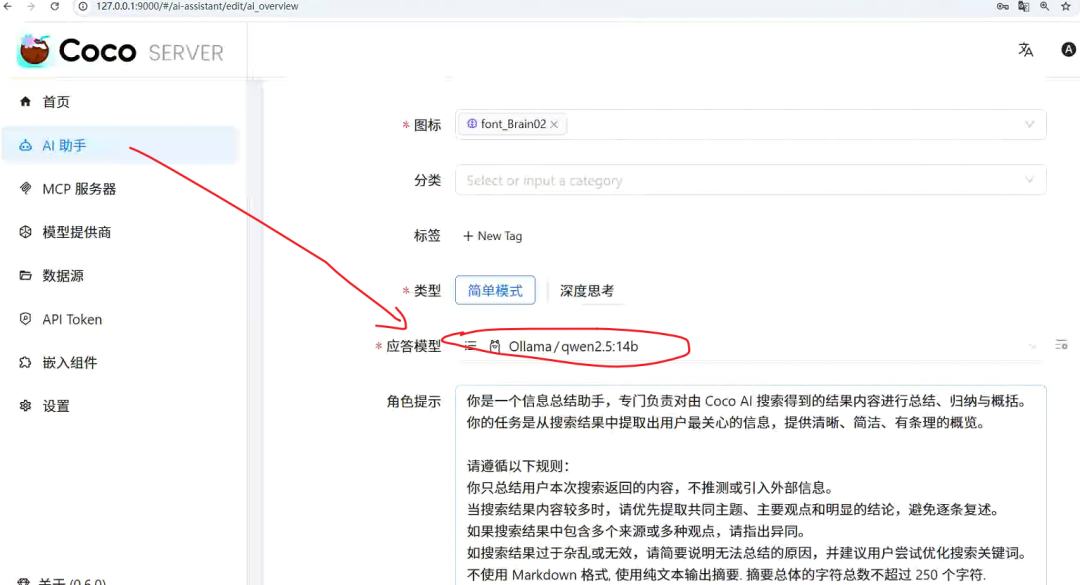
3.3.2 AI 助手设置
应答模型选择好,如下图所示。
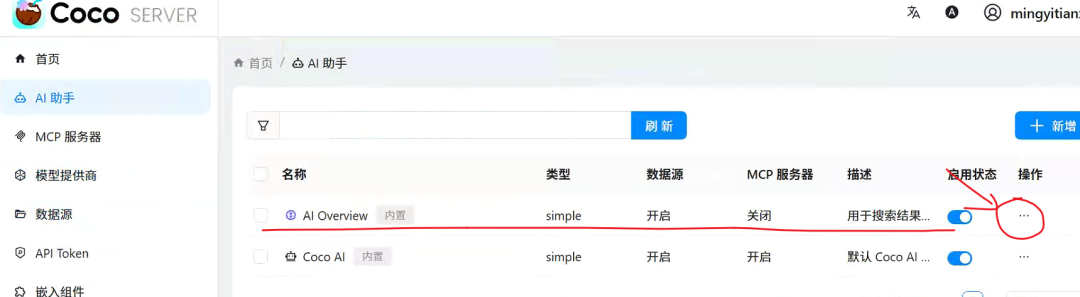
数据源头对应好,如下图所示。
3.4 切分大文档为小文档并写入 CocoServer
代码包括读取、分割文档内容并上传至 Elasticsearch 实例的实用工具。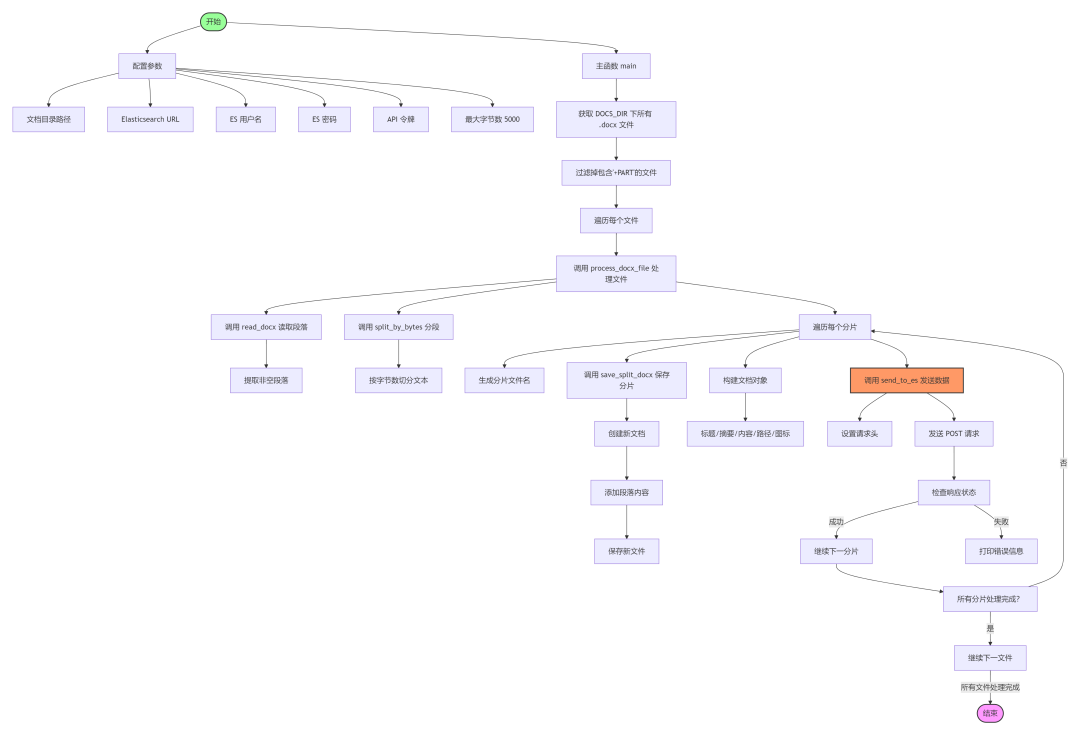
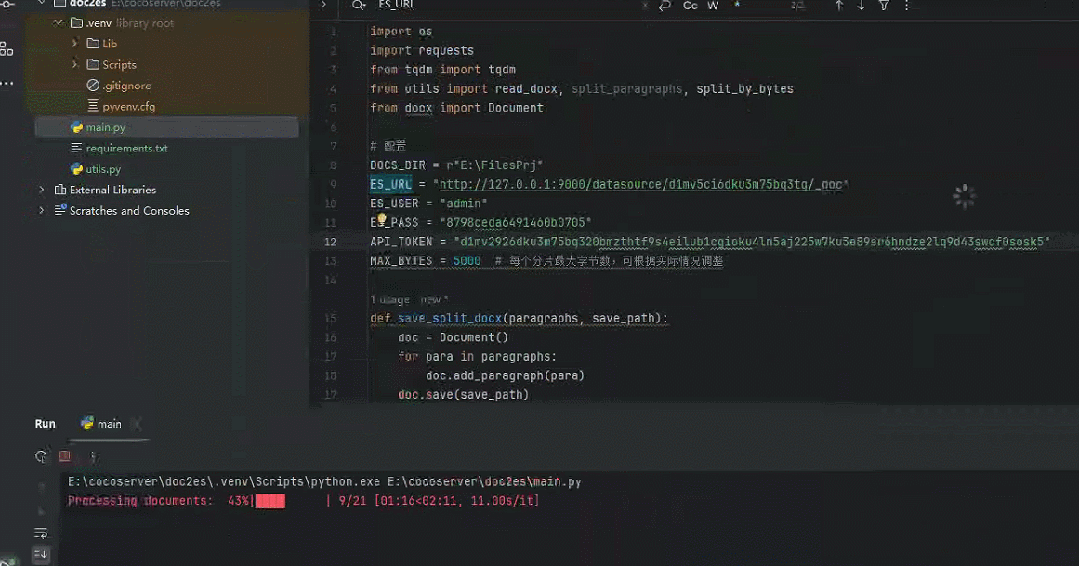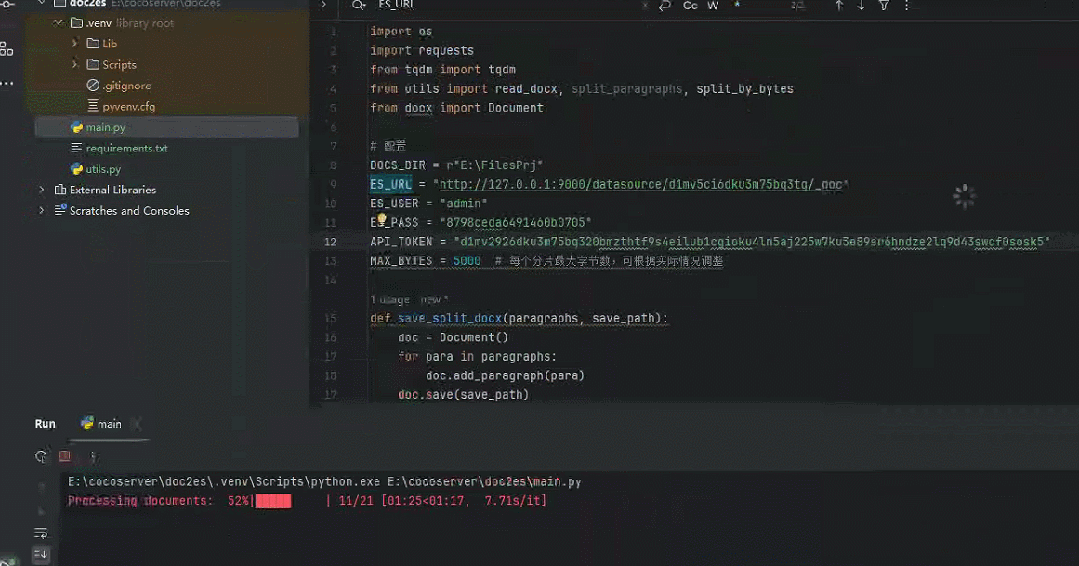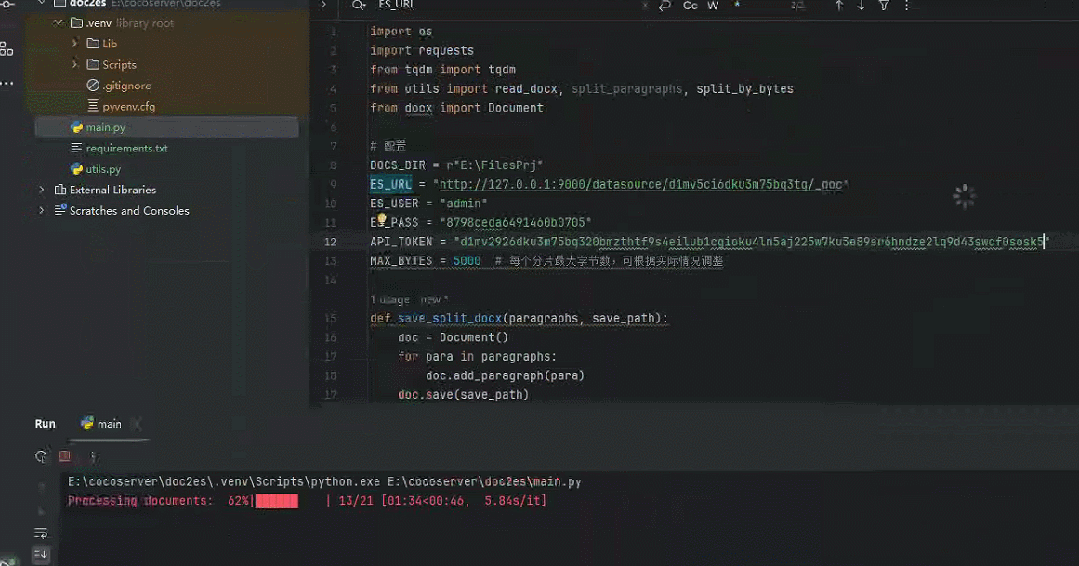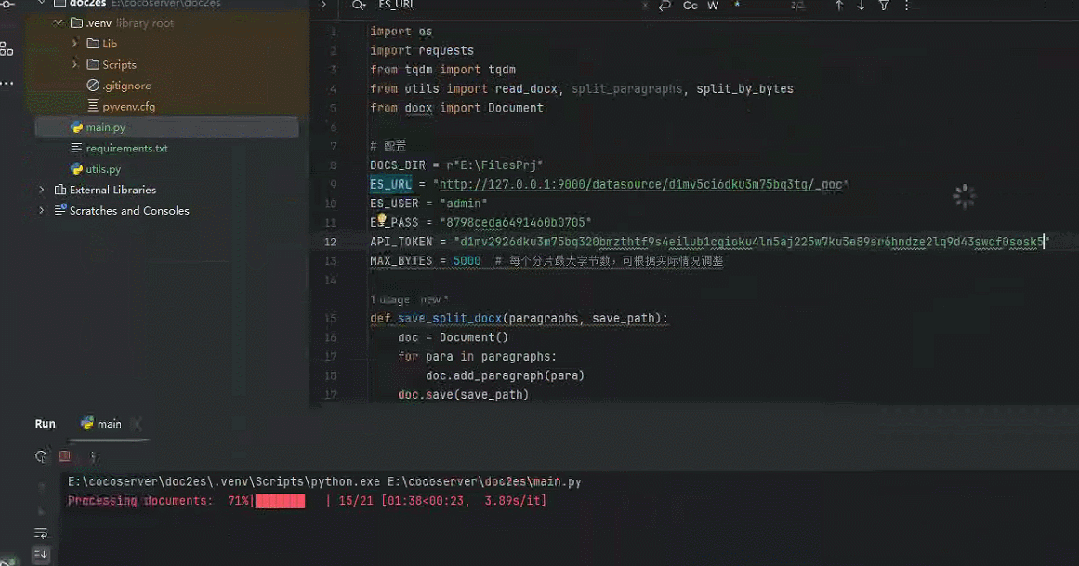
将《一本书讲透 Elasticsearch 》400页+书稿导入效果如下所示。
详细代码参见:https://articles.zsxq.com/id_5ea0h58pdae2.html
read_docx | file_path.docx文件路径 | .docx文件并提取非空段落作为字符串列表。 | ||
split_paragraphs | paragraphsmax_chars(整数): 每块最大字符数 (默认: 3000) | |||
split_by_bytes | paragraphsmax_bytes(整数): 每块最大字节数 (默认: 5000) | |||
save_split_docx | paragraphssave_path(字符串): 保存新 .docx文件的路径 | .docx文件并保存到指定路径。 | ||
process_docx_file | file_path.docx文件路径 | .docx文件,将其分割成块,保存为新 .docx文件,并准备 Elasticsearch 的元数据。 | ||
send_to_es | document | |||
main | .docx文件,处理并上传至 Elasticsearch。 |
4、小结
文章转载自铭毅天下Elasticsearch,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
