





点击蓝字关注我们

想象您拥有一个高性能分析引擎,可将 Postgres 数据库瞬间变成列式数据库,无需任何 ETL 管道即可在数秒内处理数十亿行数据。再想象一下,只需一个系统就能同时查询交易数据与现代湖仓格式,计算与存储完全分离,可按工作负载独立扩缩容,并且完全保证数据主权。
本篇介绍通过 EDB Postgres AI Analytics Accelerator ,把上述愿景变为现实。了解如何在 Postgres 数据库与现代湖仓环境中运行快速的查询,同时保持完整的数据主权,并为组织提供卓越的分析能力。
Analytics Accelerator 概览
EDB Postgres AI Analytics Accelerator 将 Postgres 转变为列式分析数据库,在不牺牲交易性能的前提下运行分析。它通过存算分离的查询引擎,消除 ETL 管道,支持湖仓与传统数据存储,实现由 AI 驱动的先进商业智能。
一句话概括Analytics Accelerator 就是包含一个向量化查询引擎附加到一个临时 Postgres 实例,关键组件如下:
支持 Delta Lake 与 Apache Iceberg 格式的解耦列式存储层
用于对象存储连接的 PGFS 扩展
用于向量化查询处理的 PGAA 扩展
与 Iceberg REST Catalog 集成,用于元数据管理
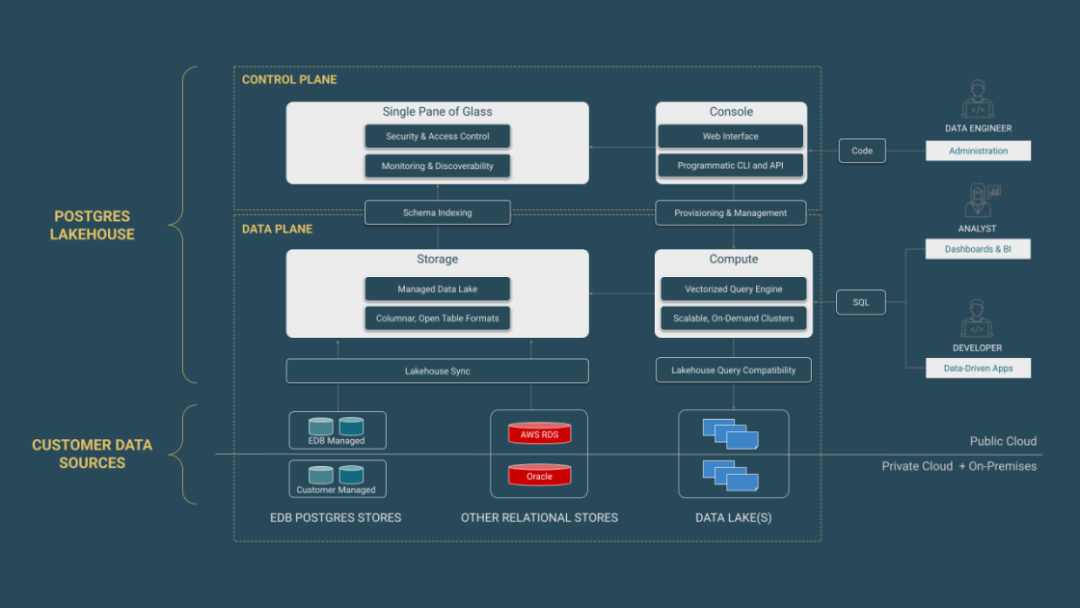
Analytics Accelerator Architecture
存算分离意味着二者可独立扩缩容,非常适合查询模式不可预测且“突发”的分析负载。由于“真正来源”位于存储层,多个 Postgres 引擎可同时查询同一份数据而互不影响。数据以高压缩格式存储在对象存储中,计算资源可按需脚本化地启动与关闭,避免闲置机器成本。
更多架构与配置信息,请参阅 [Analytics Accelerator 官方文档](https://www.enterprisedb.com/docs/edb-postgres-ai/hybrid-manager/analytics/)。
快速开始
1. 在 EDB Postgres AI Hybrid Manager 中创建 Lakehouse 集群
在 EDB Postgres AI Hybrid Manager(HM) 中新建一个 Lakehouse Analytics 集群。这是一个单节点 Postgres,已预加载了 Analytics Accelerator 扩展。也可选择自托管,从 EDB 软件仓库下载扩展 pgaa,安装到任何 Postgres 实例(支持 PostgreSQL、EnterpriseDB Advanced Server、Postgres Extended Server)。
HM Console 是 EDB Postgres AI 平台的控制平面,提供统一体验:部署数据库、运行 GenAI 工作负载、跨云/本地/混合环境扩缩 Postgres 原生分析。HM Console 可在任何 Kubernetes 上运行,附带直观 Web 界面与 REST API。
登录 HM Console 并创建项目。
在项目页点击 Create New > Lakehouse Analytics。
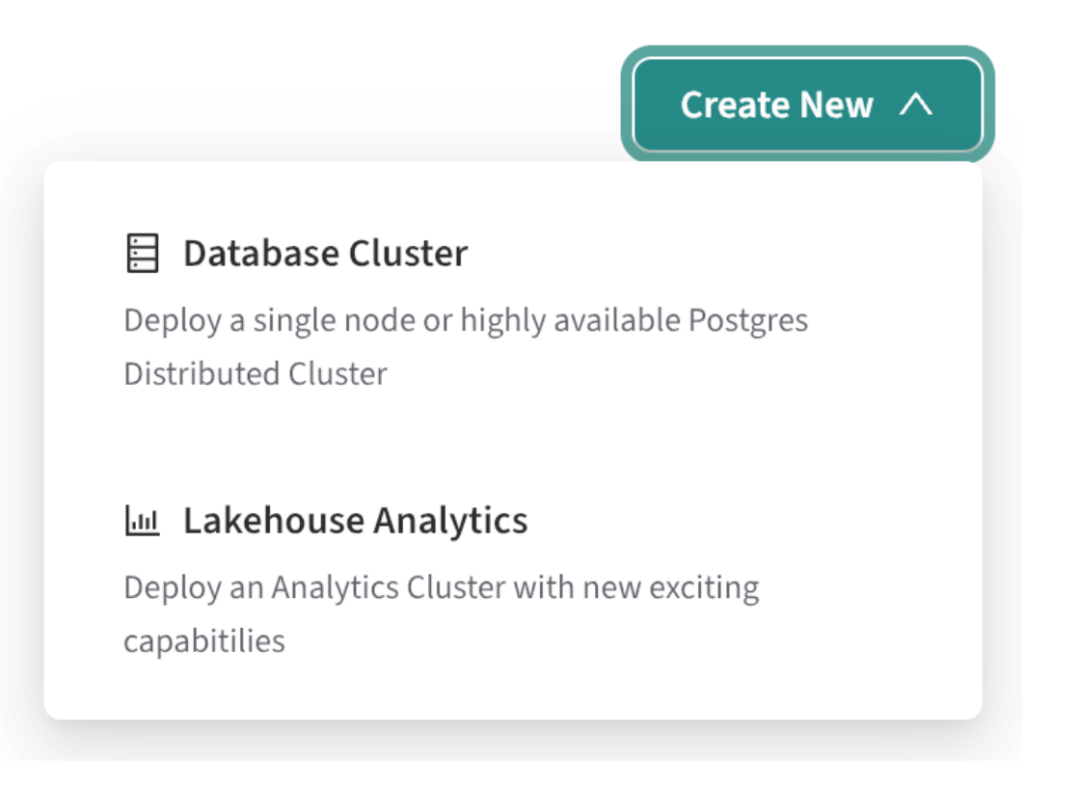
此时将打开“创建分析群集”页,可在其中选择湖仓群集的模板化生成或自定义生成:
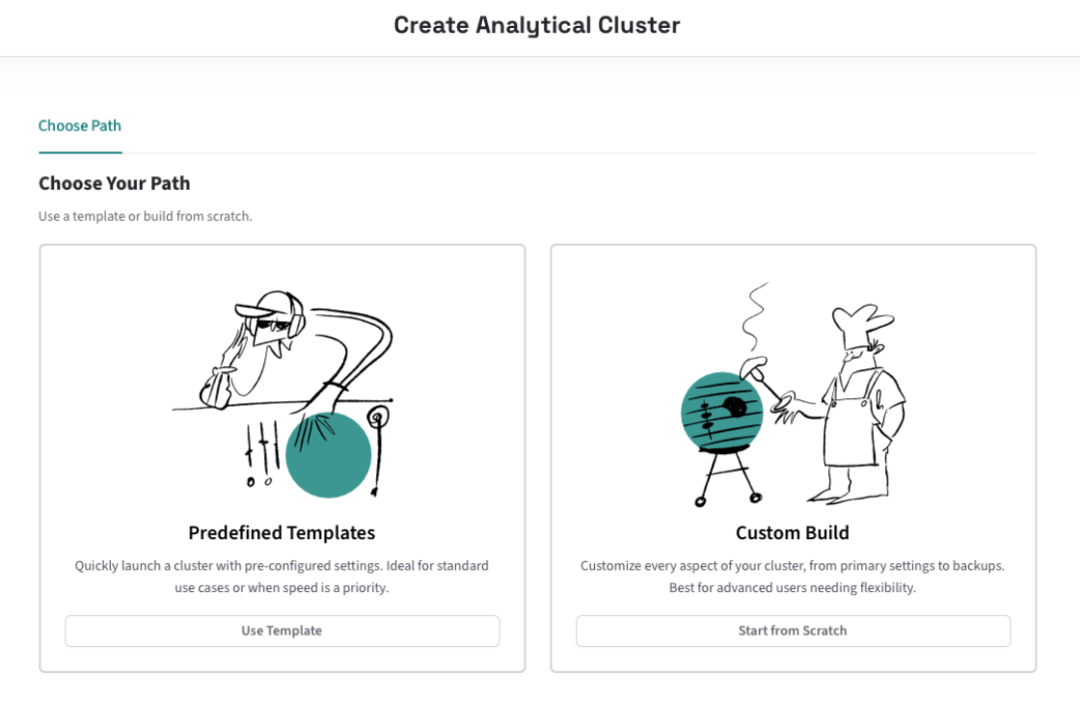
3. 选择 Custom Build → Start from Scratch,配置集群大小与参数。
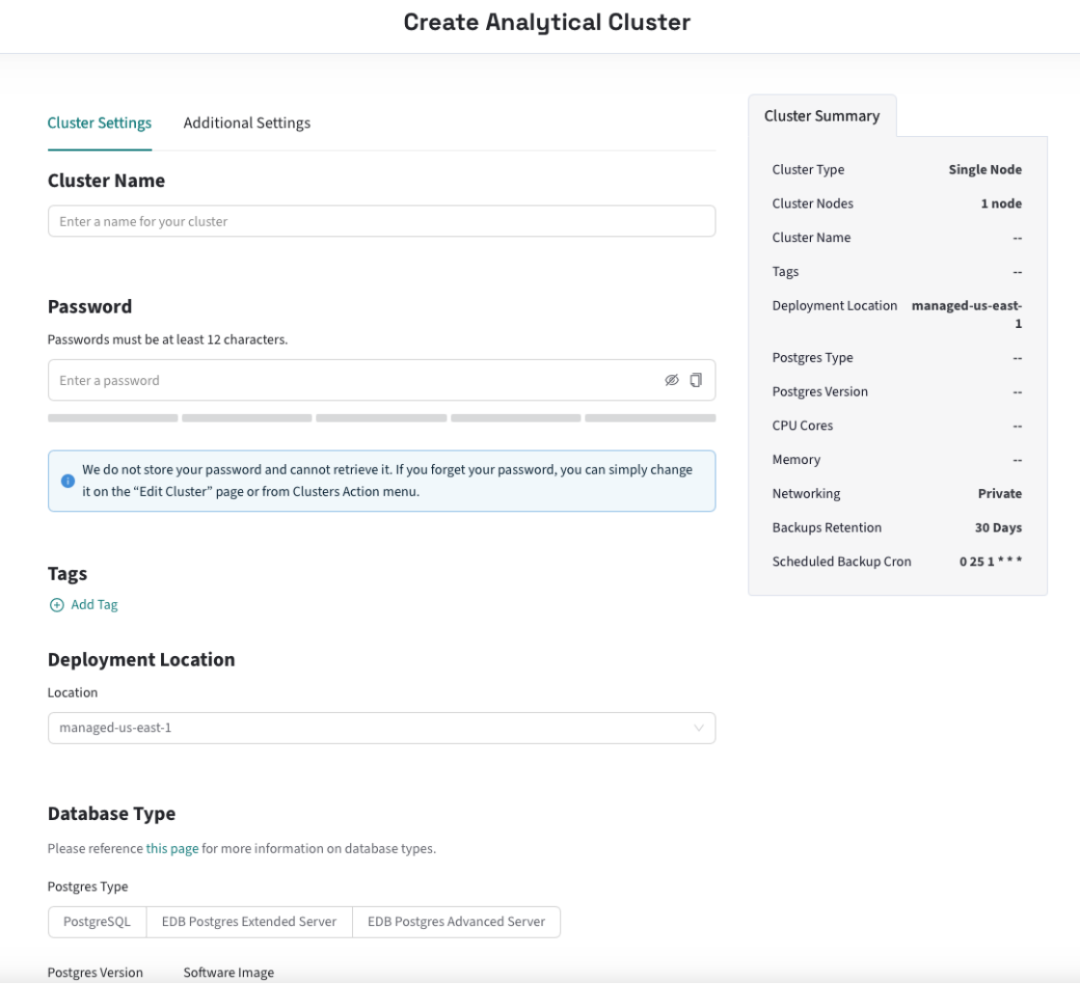
4. 返回 Clusters 页面,等待集群创建(通常 10–15 分钟,通常更快)。
Lakehouse 集群由单个 Postgres 节点组成,它们是临时的。除了内部系统表外,任何数据都不会存储在硬盘驱动器上。仅作 Parquet 数据缓存与查询溢出空间。可视为具备真正“scale to zero”能力的弹性查询引擎。
2. 连接到集群
使用任何 Postgres 客户端连接 Lakehouse 集群节点,与连接 EDB Postgres AI 平台的其他集群一样。
在集群详情页点击 Connect,复制连接串。示例:
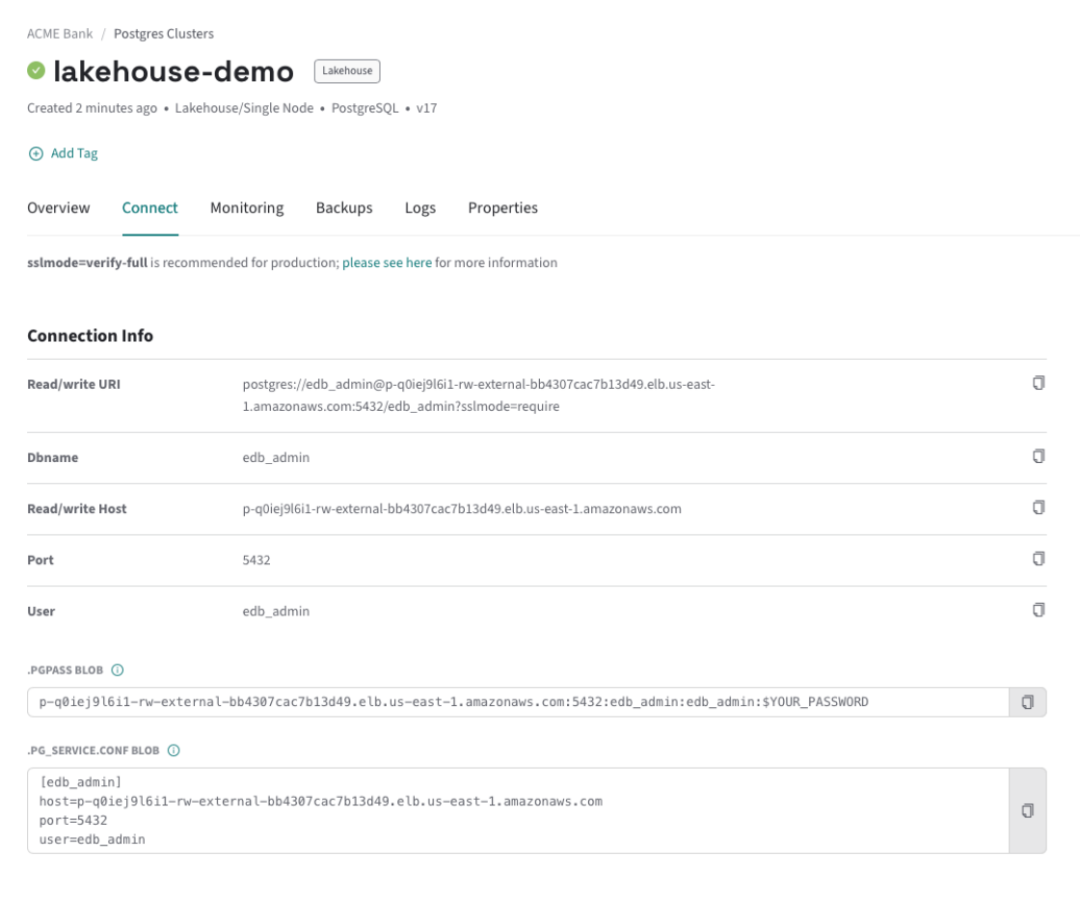
通常,可以使用任何 Postgres 客户端连接到数据库,包括 psql、pgcli、pgAdmin 等。下面示例使用psql从本地连接到lakehouse节点:
psql -U edb_admin \-h p-q0iej9l6i1-rw-external-bb4307cac7b13d49.elb.us-east-1.amazonaws.com
确保 hostname 替换为自己的地址。
3. 查看内置数据集
每个 Lakehouse 集群都预装了一套基准数据集目录(Delta Lake 表),存在公共 S3 bucket,包括 TPC-H、TPC-DS(1/10/100/1000 比例因子)、ClickBench 以及“10 亿行挑战”。
使用 psql 连入后,执行 \dn 查看可用 schema。运行简单查询体验性能:
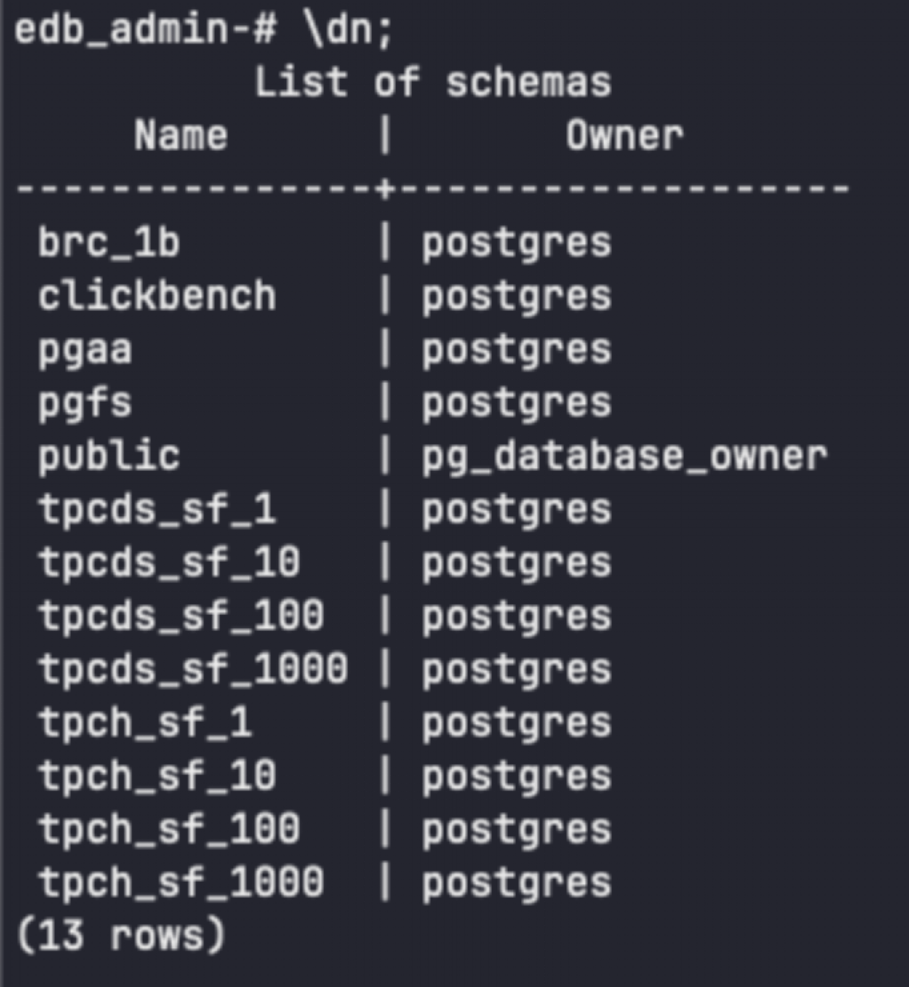
下面可以运行一些基本查询了解集群的性能:
edb_admin> select count(*) from clickbench.hits;+----------+| count ||----------|| 99997497 |+----------+SELECT 1Time: 0.945s
edb_admin> select count(*) from brc_1b.measurements;+------------+| count ||------------|| 1000000000 |+------------+SELECT 1Time: 0.651s
Analytics Accelerator 的 count(*) 是元数据操作,仅读取 Parquet 文件 footer,无需表分析或全表扫描,10 亿行与 1 千万行耗时相同。
再跑一个复杂 TPC-H 查询:
SELECTs_suppkey,s_name,s_address,s_phone,total_revenueFROMsupplier,(SELECTl_suppkey AS supplier_no,sum(l_extendedprice * (1 - l_discount)) AS total_revenueFROM lineitemWHEREl_shipdate >= CAST('1996-01-01' AS date)AND l_shipdate < CAST('1996-04-01' AS date)GROUP BYsupplier_no) revenue0WHEREs_suppkey = supplier_noAND total_revenue = (SELECTmax(total_revenue)FROM (SELECTl_suppkey AS supplier_no,sum(l_extendedprice * (1 - l_discount)) AS total_revenueFROMlineitemWHEREl_shipdate >= CAST('1996-01-01' AS date)AND l_shipdate < CAST('1996-04-01' AS date)GROUP BYsupplier_no) revenue1)ORDER BY s_suppkey;s_suppkey | s_name | s_address | s_phone | total_revenue-----------+--------------------+-------------------+-----------------+---------------8449 | Supplier#000008449 | 5BXWsJERA2mP5OyO4 | 20-469-856-8873 | 1772627.2087(1 row)Time: 634.689 ms
结果仅用 634 ms 返回,完成多表 join、聚合与排序。
查询湖仓表
湖仓表代表了一种现代数据存储方法,它结合了数据仓库和数据湖的最佳功能。这些表存储为 Parquet 文件,这是一种列式格式,它允许分析引擎仅读取查询所需的特定列而不是扫描整行,并提供引擎可用于仅读取其查询所需的精确字节范围的元数据,从而优化查询性能。这种列式结构对于通用分析、聚合和汇总大型数据集中特定列的分析工作负载特别有利。
Analytics Accelerator 支持查询流行的开放表格式,例如 Apache Iceberg 和 Delta Lake。这些格式提供了重要的功能,包括多写入器的 ACID 事务、schema演变以及与查询引擎和工具生态系统的互作性。这两种格式都将元数据与数据文件分开存储,从而实现大规模高效的数据管理。
安装在湖仓节点上的 PGAA 扩展使 Postgres 能够直接从 S3、MinIO 或 Azure Blob 存储等对象存储系统有效地读取这些湖仓表。它通过向量化查询处理来实现这一点,其中对批量数据而不是逐行执行操作,从而显着提高了分析工作负载的性能。这允许用户使用熟悉的 Postgres SQL 界面查询 PB 级数据集,同时实现与专用数据仓库解决方案相当的性能。
使用 HM 中新预配的湖仓节点,我们可以查询一些湖仓表。
查询 Iceberg 表
假设您已在 S3 兼容对象存储中准备好若干 Apache Iceberg 表,并具备相应权限。
方法 A:直接访问(无 Catalog)
创建存储位置(使用已安装的 PGFS 扩展),PGFS 提供了 PostgreSQL 和对象存储系统(或任何 POSIX 文件系统)之间的接口,使湖仓节点能够直接从对象存储访问和查询数据文件。此扩展允许您将外部对象存储位置挂载为 PostgreSQL 中的虚拟文件系统,从而在数据库和数据湖之间创建无缝集成。此连接对于查询存储在这些外部系统中的湖仓表(如 Iceberg 和 Delta)至关重要。:
SELECT pgfs.create_storage_location(name => 'my_s3_iceberg_data',url => 's3://your-bucket/path/to/iceberg',options => '{}',credentials => '{"access_key_id": "...", "secret_access_key": "..."}');
2. 创建 PGAA 外部表:
CREATE TABLE public.my_sales_iceberg_data (sales_id INT,sales_date DATE,sales_amount NUMERIC)USING PGAAWITH(pgaa.storage_location = 'my_s3_iceberg_data',pgaa.path = 'sales_records/iceberg_table_root',pgaa.format = 'iceberg');
3. 此表将iceberg表公开给Postgres,可以直接查询:
SELECT * FROM public.my_sales_iceberg_dataWHERE sales_region = 'North America'LIMIT 100;
直接访问的优点:简单、无额外 Catalog 服务、快速上手,适合即席查询。
方法 B:通过 Iceberg REST Catalog
访问 Iceberg 表的另一种方法是通过 Iceberg REST 目录:一种元数据管理系统,用于跟踪和组织 Iceberg 表,从而实现跨不同计算引擎的高效数据发现、访问和版本控制。它存储有关表位置、模式、快照和分区的信息,允许与 Spark、Trino 和 Flink 等引擎无缝集成,以查询数据湖中的大规模、可变数据集。
通过 Iceberg REST 目录查询 Iceberg 表具有显着的额外优势:
表发现:目录维护所有可用表的清单
Schema演变跟踪:目录跟踪schema随时间的变化
元数据管理:更高效地处理表元数据
集中权限:更好地控制访问管理
事务协调:确保跨多个写入器的 ACID 合规性
若要从湖仓节点连接到 Iceberg 目录,需要从任何实现 Iceberg REST 目录标准的目录中进行一些基本配置。支持的 Catalog 包括 Snowflake Open Catalog、Databricks Unity Catalog、AWS S3Tables、Lakekeeper(HM 内也提供托管版)。
设置目录后,可以使用 PGAA 将其注册到湖仓节点。以 HM 托管的 Lakekeeper 为例:
SELECT pgaa.add_catalog('hm_lakekeeper_main','iceberg-rest','{"url": "https://hm.example.com/catalog/v1","token": "your_hm_api_key","warehouse": "lakehouse_warehouse_1"}');
可以访问 HM 控制台中的“目录”部分,以访问特定于湖仓群集的目录配置。
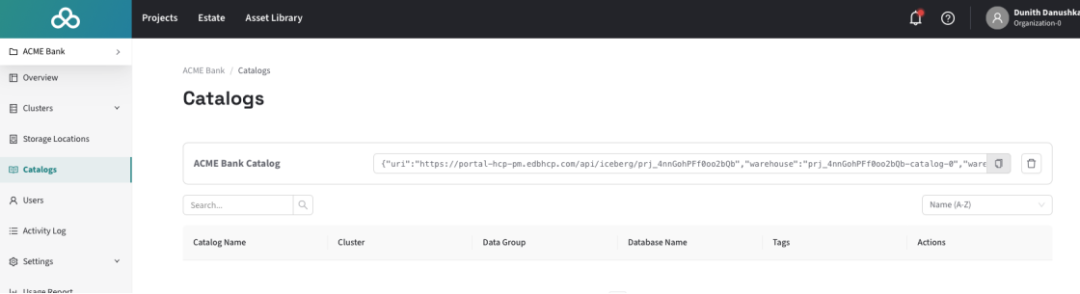
添加目录后,运行pgaa.attach_catalog()以使目录表在 Postgres 中可见和可查询。这还将启动一个后台进程,以使 Postgres 目录与 Iceberg REST 目录保持同步——因此,当在上游添加、删除或更改表时,更改也会反映在 Postgres 中。如果不想保持同步,可以运行import_catalog使用相同的语法运行元数据的一次性导入。
SELECT pgaa.attach_catalog('your_catalog_alias');
此后 Catalog 中的表会自动同步到 Postgres。也可手动建表:
CREATE TABLE public.catalog_managed_sensor_data (device_id TEXT,event_time TIMESTAMP WITH TIME ZONE,temperature FLOAT,humidity FLOAT)USING PGAAWITH(pgaa.format = 'iceberg',pgaa.managed_by = 'your_catalog_alias',pgaa.catalog_namespace = 'iot_data',pgaa.catalog_table = 'hourly_sensor_readings');
生产环境推荐使用 Catalog,便于数据治理与多用户协同。
查询 Delta 表
与 Iceberg 几乎一致,只是目前暂不支持通过 Catalog 访问。假设有一个 HM 预配的湖仓节点和 S3 兼容对象存储中的多个增量表。
创建存储位置:
SELECT pgfs.create_storage_location(name => 'my_public_delta_lake_store',url => 's3://my-public-delta-data/',options => '{"aws_skip_signature": "true"}',credentials => '{}');
2. 建外部表:
CREATE TABLE public.sales_delta_table ()USING PGAAWITH(pgaa.storage_location = 'my_private_delta_lake_assets',pgaa.path = 'path/to/delta_table_root/',pgaa.format = 'delta');
3. 查询:
SELECT order_id, customer_name, sale_amountFROM public.sales_delta_tableWHERE sale_date >= '2023-01-01'AND product_category = 'Electronics'LIMIT 100;
使用分层表(Tiered Tables)卸载旧数据
Analytics Accelerator 不仅能读湖仓表,还能写湖仓表,实现数据生命周期管理。
分层表是 EDB Postgres AI 高可用配置的原生能力,支持:
按时间将“冷”数据自动迁移到低成本对象存储(Iceberg 格式)
使用 PGD AutoPartition 自动分区并控制生命周期
使用 PGAA + PGFS 查询和访问卸载数据
可选 Iceberg Catalog 实现治理与互操作
总结
本文,我们介绍了 EDB Postgres AI Analytics Accelerator 的强大功能:
将 Postgres 变成高性能列式分析引擎
直接查询 Iceberg Delta Lake 表,无需 ETL
通过 PGAA 扩展实现向量化处理,支持 PB 级数据集
使用分层表智能管理数据生命周期,自动冷热分层
统一接口同时服务交易与分析负载,兼具 Postgres 可靠性与现代湖仓灵活性
要尝试上述步骤,可以在您喜欢的平台上安装 PG AI Hybrid Manager (HM),然后访问 HM 控制台,就可以体验。了解详情可以参考官方文档https://www.enterprisedb.com/docs/edb-postgres-ai/hybrid-manager/analytics/
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
