




1、问题来源
书接上一回。
做企业级搜索系统改造时遇到了一个老生常谈但又必须解决的问题:传统关键词搜索的语义理解能力实在太弱了。用户搜索"适合学生党的平价耳机",系统只能匹配到标题中包含"学生"、"平价"、"耳机"这些关键词的商品,而那些真正物美价廉但描述为"性价比超高无线蓝牙耳机"的产品却检索不到。
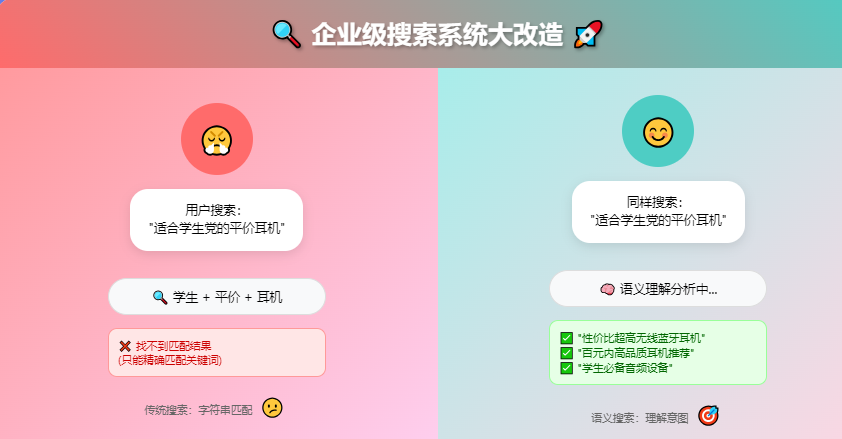
更典型的场景是技术文档搜索。开发同学搜索"如何优化数据库查询性能",传统搜索只能找到标题完全匹配的文章,而那些内容中深入讲解 SQL 优化、索引设计的优质文档因为标题措辞不同就被埋没了。这种语义鸿沟让搜索体验大打折扣,用户经常需要尝试多种关键词组合才能找到想要的信息。

从技术层面分析,传统搜索基于倒排索引和 TF-IDF 算法,本质上还是在做字符串匹配和统计计算,无法理解文本的真实语义。而现在大模型时代,向量检索技术已经相当成熟,完全可以通过语义相似度来提升搜索效果。

更重要的是,考虑到数据安全和成本控制,我们希望能够本地化部署整套语义搜索方案,而不是依赖外部 API。
经过技术选型,最终选择了 Ollama + Easysearch 的组合:Ollama 负责本地化的文本向量化,Easysearch 作为搜索引擎提供向量检索能力。

2、问题分析
技术上看,传统搜索的核心问题在于:严格的词汇匹配要求,同义词扩展只是治标不治本;缺乏语义理解能力,无法处理上下文关系;对查询意图的理解完全依赖关键词,缺乏推理能力。

而语义搜索通过将文本转换为高维向量表示,在向量空间中通过余弦相似度等度量方式计算语义相关性,能够很好地解决这些问题。向量空间中语义相近的文本会聚集在相近的位置,即使用词不同也能被检索到。
3、解决方案探讨
本地化的语义搜索方案核心架构包括两个组件:
Ollama 作为本地向量化服务,负责将文本转换为向量表示; Easysearch 作为搜索引擎,提供向量存储和检索能力。
3.1 选择 Ollama 的原因很实际:
完全本地化部署,数据不出企业内网;
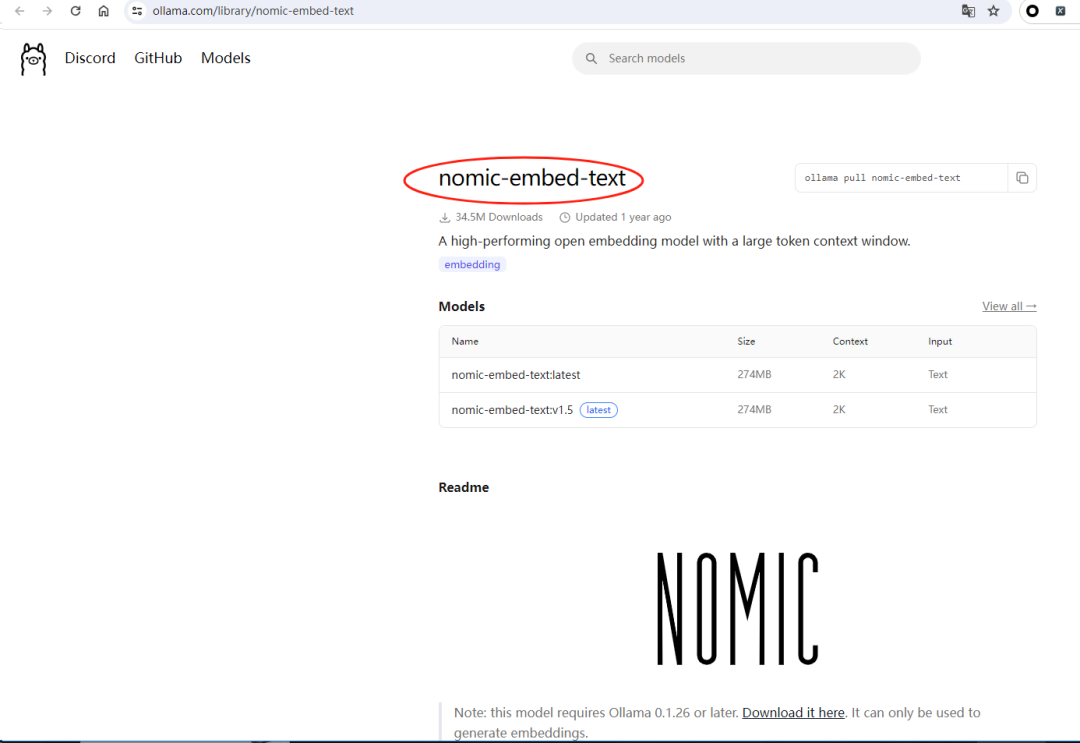
支持多种开源 embedding 模型,比如 nomic-embed-text、mxbai-embed-large 等;
资源消耗相对可控,单机部署即可满足中等规模应用需求;
API接口简洁,集成成本低。
3.2 Easysearch的选择基于几个考虑
作为Elasticsearch的国产化替代,API 兼容性好,迁移成本低;
原生支持向量检索,kNN 算法实现成熟;
内置 Pipeline 机制,可以无缝集成外部 AI 服务;
支持混合检索,能够结合传统关键词搜索和语义搜索的优势。
3.3 整体架构设计采用双管道模式
Ingest Pipeline 在数据写入时调用Ollama API生成向量并存储;
Search Pipeline 在查询时将用户输入转换为向量进行相似度检索。
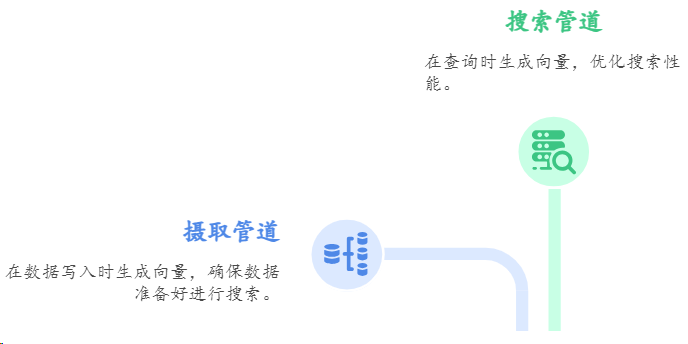
这种设计的好处是对业务代码完全透明,现有的索引和查询逻辑基本不需要修改。
3.4 技术实现上有几个关键决策:
向量维度选择适合维度,在存储成本和检索精度之间找到平衡;
相似度算法选择余弦相似度,对向量长度不敏感更适合文本比较;
索引算法选择 LSH(Locality Sensitive Hashing),在保证检索精度的同时大幅提升查询性能。
4、解决问题实战
4.1 环境准备
首先部署 Ollama 服务,这个过程比想象中简单。在服务器上安装Ollama后,拉取 embedding 模型:
# 安装并启动Ollama
curl -fsSL https://ollama.ai/install.sh | sh
ollama serve
# 拉取embedding模型
ollama pull nomic-embed-text:latest
nomic-embed-text是一个轻量级但效果不错的文本向量化模型,768 维输出,对中英文都有不错的支持。启动后可以通过简单的 HTTP 请求测试:
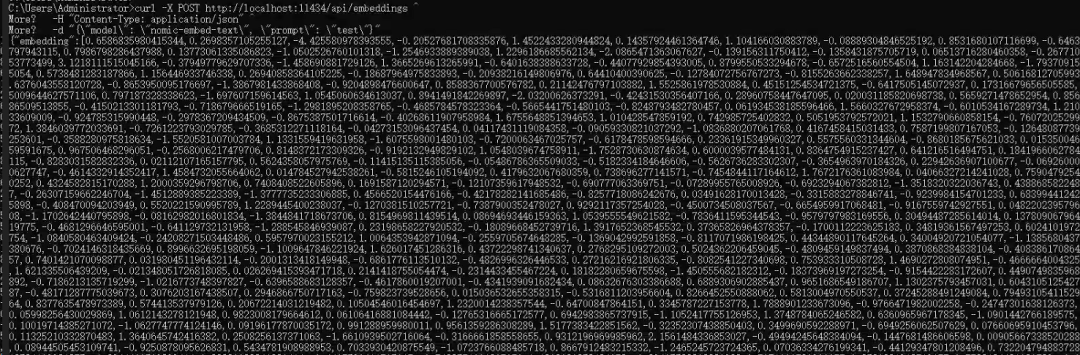
curl -X POST http://localhost:11434/api/embeddings ^
-H "Content-Type: application/json" ^
-d "{\"model\": \"nomic-embed-text\", \"prompt\": \"test\"}"
4.2 配置 Easysearch 管道
前置条件:已安装最新版本的 Easysearch。
接下来配置 Easysearch 的 Ingest Pipeline,用于在数据写入时自动生成向量:
PUT _ingest/pipeline/ollama-embedding-pipeline
{
"description": "Ollama embedding 示例",
"processors": [
{
"text_embedding": {
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"text_field": "content",
"vector_field": "content_vector",
"model_id": "nomic-embed-text:latest"
}
}
]
}
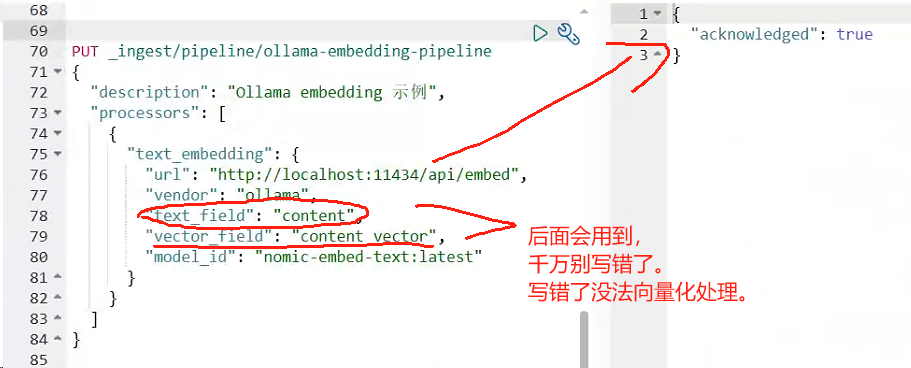
这里几个参数需要特别说明:
text_field 指定需要向量化的源文段,我们选择 content 字段因为它通常包含最丰富的语义信息; vector_field 是生成向量的存储字段名; batch_size 设置为5,可以提高处理效率但也要考虑Ollama的处理能力。
4.3 创建向量索引
索引映射的配置直接影响后续的检索性能,特别是向量字段的设置:
PUT knowledge-base
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"content": {
"type": "text",
"analyzer": "ik_max_word"
},
"category": {
"type": "keyword"
},
"content_vector": {
"type": "knn_dense_float_vector",
"knn": {
"dims": 768,
"model": "lsh",
"similarity": "cosine",
"L": 99,
"k": 1
}
}
}
}
}
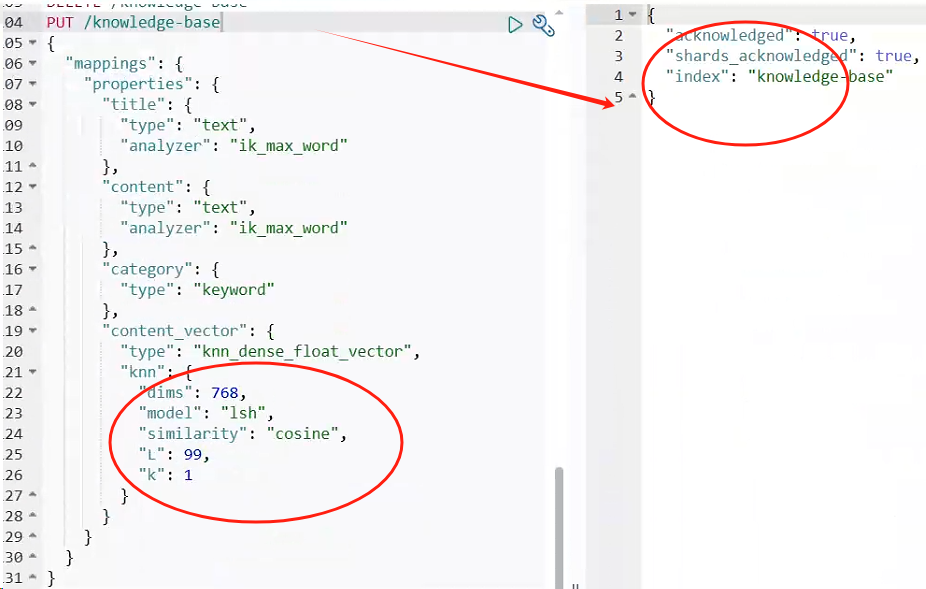
向量字段配置是整个方案的关键。
type 设置为 knn_dense_float_vector 表示这是向量检索字段; dims 必须与 embedding 模型输出维度保持一致,nomic-embed-text是768维; model 选择 lsh 算法,在检索精度和性能之间取得很好的平衡; similarity 选择 cosine 余弦相似度,更适合文本语义比较。
4.4 批量导入数据
使用配置好的 Pipeline 批量导入文档,系统会自动为每个文档生成向量:
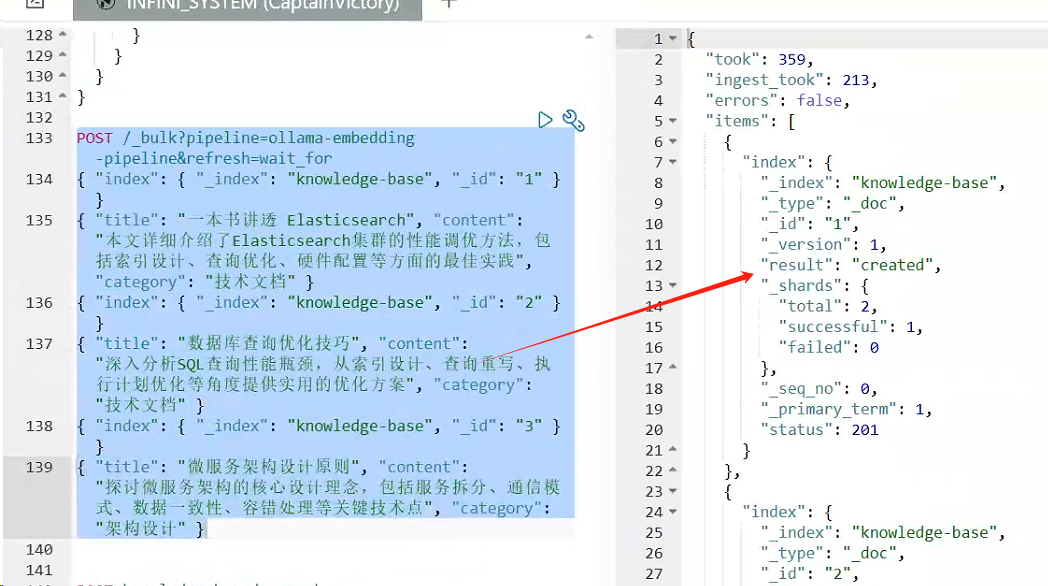
POST _bulk?pipeline=ollama-embedding-pipeline&refresh=wait_for
{ "index": { "_index": "knowledge-base", "_id": "1" } }
{ "title": "一本书讲透 Elasticsearch", "content": "本文详细介绍了Elasticsearch集群的性能调优方法,包括索引设计、查询优化、硬件配置等方面的最佳实践", "category": "技术文档" }
{ "index": { "_index": "knowledge-base", "_id": "2" } }
{ "title": "数据库查询优化技巧", "content": "深入分析SQL查询性能瓶颈,从索引设计、查询重写、执行计划优化等角度提供实用的优化方案", "category": "技术文档" }
{ "index": { "_index": "knowledge-base", "_id": "3" } }
{ "title": "微服务架构设计原则", "content": "探讨微服务架构的核心设计理念,包括服务拆分、通信模式、数据一致性、容错处理等关键技术点", "category": "架构设计" }
4.5 配置搜索管道
Search Pipeline 负责在搜索时将用户查询转换为向量:
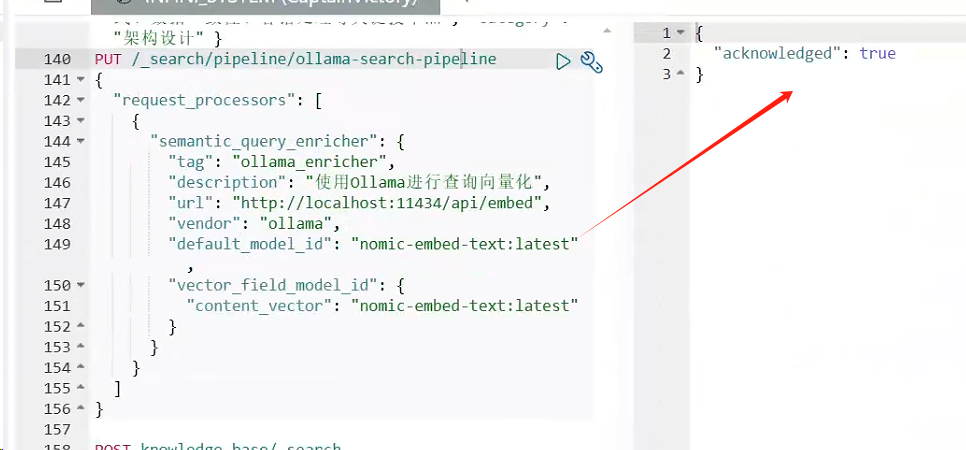
PUT _search/pipeline/ollama-search-pipeline
{
"request_processors": [
{
"semantic_query_enricher": {
"tag": "ollama_enricher",
"description": "使用Ollama进行查询向量化",
"url": "http://localhost:11434/api/embed",
"vendor": "ollama",
"default_model_id": "nomic-embed-text:latest",
"vector_field_model_id": {
"content_vector": "nomic-embed-text:latest"
}
}
}
]
}
然后将这个Pipeline设置为索引的默认搜索管道:

PUT knowledge-base/_settings
{
"index.search.default_pipeline": "ollama-search-pipeline"
}
4.6 执行语义搜索
完成所有配置后,就可以执行语义搜索了:
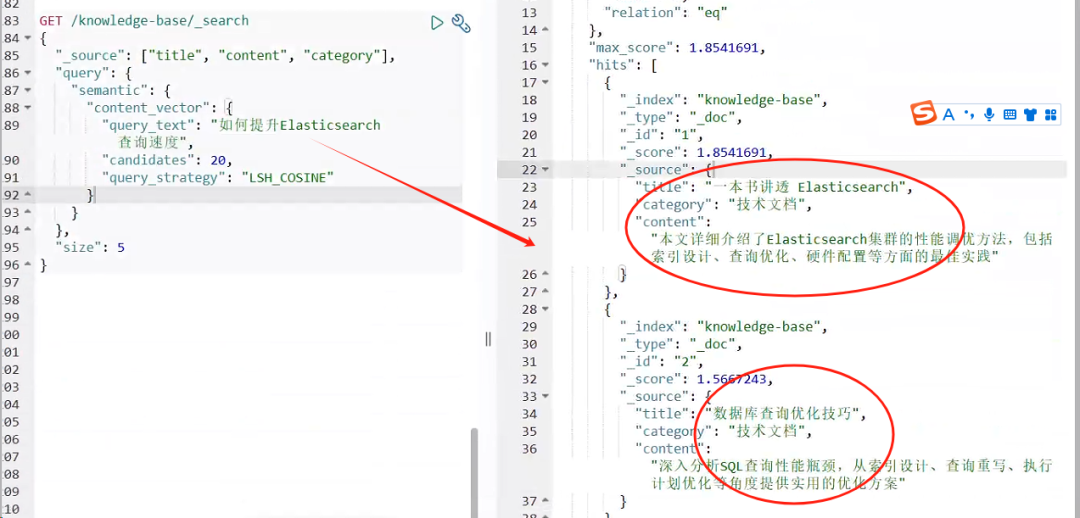
GET knowledge-base/_search
{
"_source": ["title", "content", "category"],
"query": {
"semantic": {
"content_vector": {
"query_text": "如何提升Elasticsearch 查询速度",
"candidates": 20,
"query_strategy": "LSH_COSINE"
}
}
},
"size": 5
}
这个查询的效果令人惊喜。即使用户搜索"如何提升 Elasticsearch 查询速度",系统也能准确返回“一本书讲透 Elasticsearch"和"数据库查询优化技巧"等文档,因为它们在语义上高度相关。相关度高的排在前面。
4.7 混合检索优化
如下是一个混合检索查询,同时使用传统关键词匹配(multi_match)和AI语义理解(semantic)两种方式搜索"数据库查询优化",
其中关键词搜索权重更高(boost: 1.5),语义搜索作为补充(boost: 1.0),确保既能精确匹配技术术语,又能理解用户意图,提供更全面准确的搜索结果。
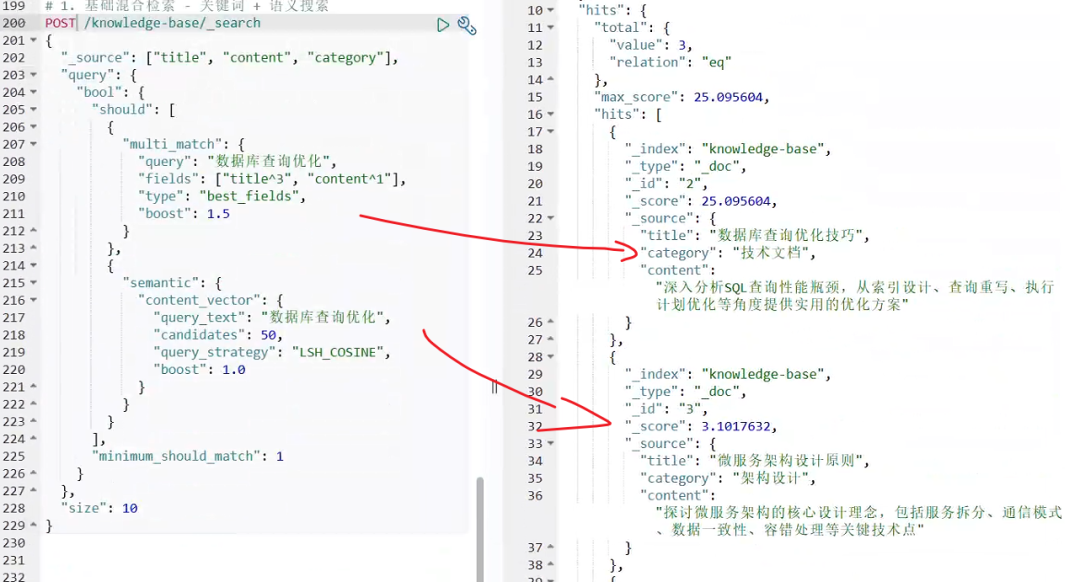
# 1. 基础混合检索 - 关键词 + 语义搜索
POST knowledge-base/_search
{
"_source": ["title", "content", "category"],
"query": {
"bool": {
"should": [
{
"multi_match": {
"query": "数据库查询优化",
"fields": ["title^3", "content^1"],
"type": "best_fields",
"boost": 1.5
}
},
{
"semantic": {
"content_vector": {
"query_text": "数据库查询优化",
"candidates": 50,
"query_strategy": "LSH_COSINE",
"boost": 1.0
}
}
}
],
"minimum_should_match": 1
}
},
"size": 10
}
5、小结
本地化部署的价值不仅仅是数据安全,更重要的是可控性和定制化能力。我们可以根据业务特点选择最合适的 embedding 模型,可以灵活调整算法参数,可以与现有系统无缝集成。
语义搜索让搜索引擎真正具备了理解能力,从简单的字符串匹配升级为语义理解。这不仅仅是技术升级,更是用户体验的本质改善。对于任何需要处理大量文本信息的业务场景,语义搜索都值得深入实践。
投标环节:如何科学、合理地介绍 Elasticsearch 国产化替代方案——Easysearch?
将斯坦福 GloVe 词向量数据集索引到 Easysearch 以实现语义搜索
Elasticsearch 国产化替代方案之一 Easysearch 的介绍与部署指南
