





点击蓝字关注我们

引言
自修复/自愈(Self-healing)是 Kubernetes 的核心特征之一。对PostgreSQL 集群,自修复通常与恢复主实例关联,通常只关注主库故障后的恢复,却忽视了只读副本(replica)的状态。事实上,副本对高可用和自修复至关重要 ——目前的 CloudNativePG在K8S环境下,可以在主库宕机后自动把最新副本提升为新主库。实现自修复/自愈的功能。
如果不使用WAL 归档(WAL archive)或 PostgreSQL 复制槽(replication slot),流复制副本可能在故障后永远失去同步,而且可能无法恢复,只能人工重克隆。这正是 CloudNativePG 引入物理故障转移槽(physical failover slots)的原因:它在高可用集群里自动管理复制槽,让副本在故障转移后仍能继续追日志,实现真正的自修复/自愈。
下面我们就了解一下 CloudNativePG 如何实现故障转移槽及其解决的问题。
什么是复制槽
PostgreSQL 中的复制槽为主服务器提供了一种自动化方式,在所有附加的流复制客户端收到 WAL 段之前,它不会回收(删除)WAL段,从而确保副本在临时故障或缓慢的日志应用程序后始终可以恢复同步。换句话说,PostgreSQL 主数据库可以根据每个备用数据库的实际消耗量自行调节要保留的 WAL 文件数量,在磁盘使用方面具有明显的优化和效率。
复制槽在所有当前支持的 PostgreSQL 版本中都可用,是 PostgreSQL 2014 年(9.4 版本)引入的机制,用于防止主库过早回收(删除)WAL 文件。
主库会按副本的实际消费进度保留 WAL,而不是盲目保留固定数量。
但原生 PostgreSQL 的复制槽“没有集群概念”:
槽只存在于创建它的实例上,并且PostgreSQL不会在备用服务器上复制它;
发生 failover 后,新主库没有旧主库的槽信息,可能已把旧副本需要的 WAL 回收,导致副本无法继续同步。
在 Kubernetes 自动调度环境里,这直接阻碍了自愈。
CloudNativePG 在引入故障转移槽之前怎么做
在 1.18 版本之前,CloudNativePG 通过 WAL 归档 实现自愈:
生产环境强烈建议打开连续归档;
副本可以从归档拉取主库已回收的 WAL;
pg_rewind 也依赖归档把旧主拉回成新备。
如果没有归档,只能退而求其次设置 wal_keep_size(或旧版本的 wal_keep_segments),但仍有窗口期风险。
如何在 CloudNativePG 中启用故障转移槽
现在的CloudNativePG故障转移槽默认开启。 所以不需要显示设定,如果你想显示指定,可以参考下面的内容 :
apiVersion: postgresql.cnpg.io/v1kind: Clustermetadata:name: cluster-examplespec:instances: 3storage:size: 1GiwalStorage:size: 512MireplicationSlots:highAvailability:enabled: truepostgresql:parameters:max_slot_wal_keep_size: "500MB"hot_standby_feedback: "on"
集群共 3 实例:1 主 + 2 备。每个实例的 PGDATA 卷为 1GB,WAL 卷为 512MB。replicationSlots 节显式启用对物理故障转移槽的支持。
max_slot_wal_keep_size 限制单个槽最大保留 500 MB WAL,防止磁盘被撑爆。
原理:主库 HA 槽与备库 HA 槽
部署集群后,主库(cluster-example-1)会出现两条主库 HA 槽(primary HA slot):
kubectl exec -ti cluster-example-1 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"
结果:
slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_3 | 0/F000110 | t_cnpg_cluster_example_2 | 0/F000110 | t(2 rows)
_cnpg_ 前缀可自定义(.spec.replicationSlots.highAvailability.slotPrefix)。
每个槽对应一个流复制备库,仅主库维护。
在 CloudNativePG 的术语中,上述物理复制槽称为主 HA 插槽,因为它们仅位于主 HA 插槽上。每个主 HA 插槽都映射到特定的流备用数据库,并且从创建到结束(例如,在故障转移或切换之后)完全由集群中的当前主数据库管理。
另一侧由所谓的备用 HA 插槽表示。这些是位于备用实例上的物理复制槽,完全由备用实例管理,并指向集群中的另一个备用实例。再看备库(cluster-example-2):
kubectl exec -ti cluster-example-2 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"
结果:
slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_3 | 0/F000110 | f(1 row)
备库上这条叫备库 HA 槽(standby HA slot),不活跃(无连接)。
备库每 30 秒(可改 updateInterval)用 pg_replication_slot_advance() 把槽推进到主库对应位置,避免落后。
再查看另一备库(cluster-example-3):
slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_2 | 0/F000110 | f
备库上这条叫备库 HA 槽(standby HA slot),不活跃(无连接)。
备库每 30 秒(可改 updateInterval)用 pg_replication_slot_advance() 把槽推进到主库对应位置,避免落后。
在后台,每个备用 HA 插槽由控制它的实例管理器定期更新,方法是调用 pg_replication_slot_advance() 并从主服务器上的 pg_replication_slots 视图轮询的restart_lsn。更新频率由 .spec.replicationSlots.updateInterval 选项确定,该选项默认设置为 30 秒。此异步更新可能会产生滞后,使备用服务器上的插槽位置等于或低于主服务器上的值,而不会产生任何不良影响。请注意,备用 HA 插槽处于非活动状态,这意味着未连接任何流式处理客户端。
故障转移 计划切换时动作
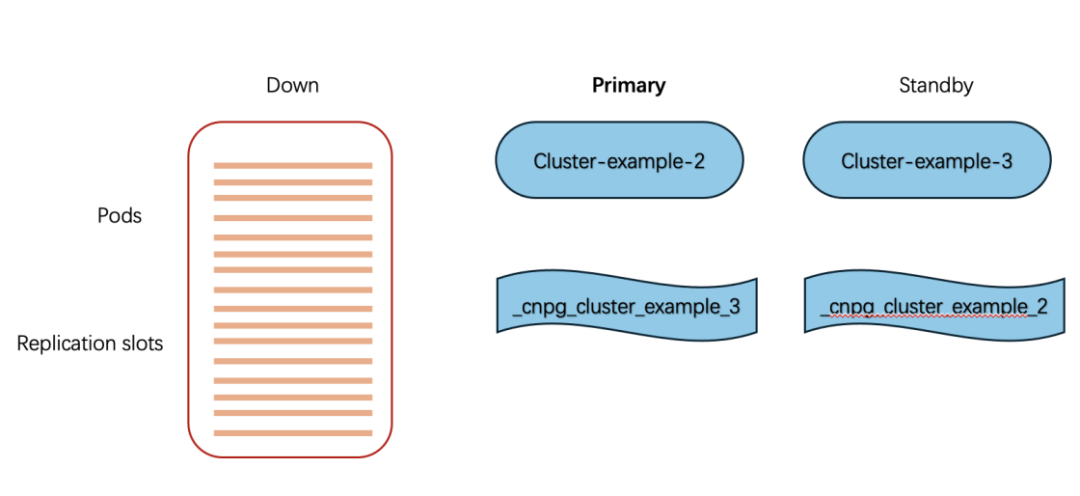
假设 cluster-example-1 宕机,cluster-example-2 被提升为新主:
cluster-example-2 成为主库
实例管理器检查本地是否已有 _cnpg_cluster-example_3(已有)和 _cnpg_cluster-example_1(无)。
创建未初始化的 _cnpg_cluster-example_1,等待旧主回归做备库。
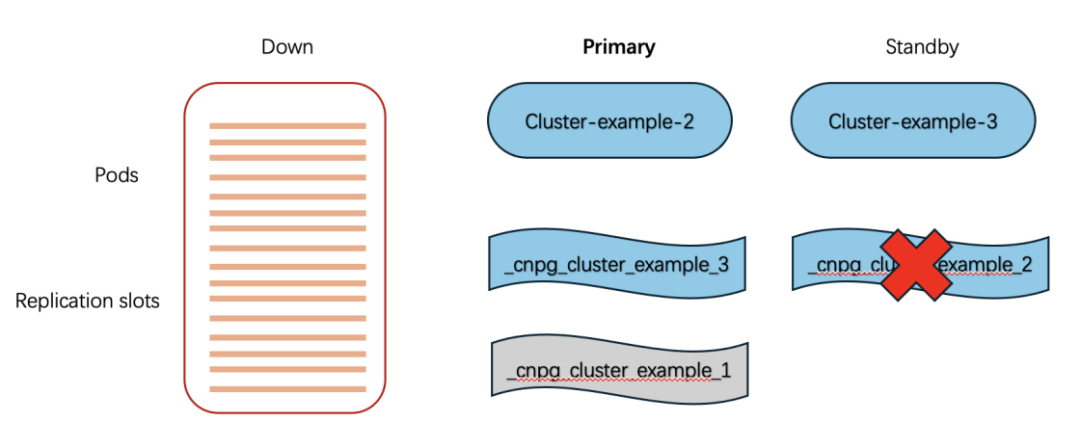
cluster-example-3 继续同步
使用 cluster-example-2 上的 _cnpg_cluster-example_3 槽,该槽位置 ≥ cluster-example-3 当前位点,可继续追日志。
cluster-example-3 更新本地 standby HA 槽
删除 _cnpg_cluster-example_2(因为 cluster-example-2 已不再是备库)。
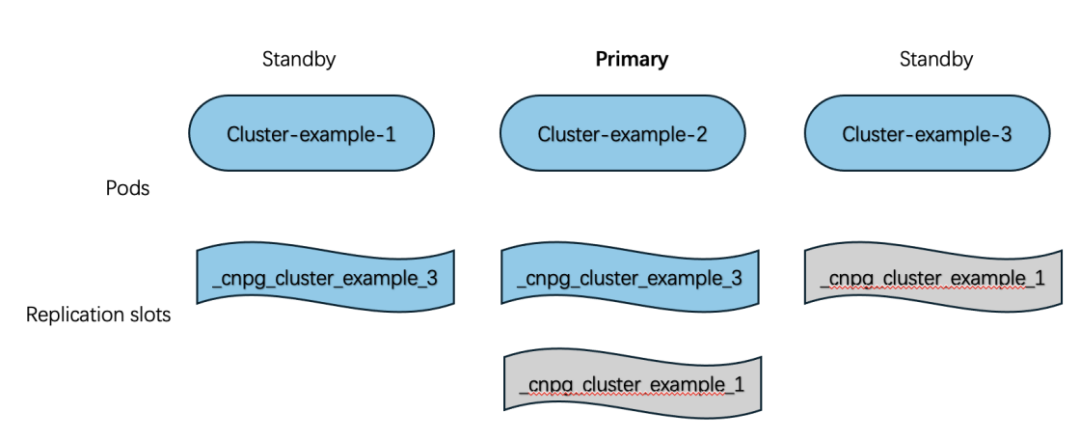
cluster-example-1 重新上线
被降为备库后,本地实例管理器创建 _cnpg_cluster-example_3 槽;
cluster-example-3 也创建 _cnpg_cluster-example_1,恢复到最优拓扑。
计划切换(switchover)流程几乎相同,只是主库优雅关闭。扩缩容也会自动增删槽。
上述部署图示过程如下:
验证切换过程:
1.查看当前pods状态:
Kubectl get pods ─╯NAME READY STATUS RESTARTS AGEcluster-example-1 1/1 Running 0 90mcluster-example-2 1/1 Running 0 58mcluster-example-3 1/1 Running 0 57m
2.查看cluster-example-1的slot情况
kubectl exec -it cluster-example-1 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_3 | 0/10000000 | t_cnpg_cluster_example_2 | 0/10000000 | t(2 rows)
3.相看cluster-example-2和cluster-example-3的slot情况
kubectl exec -it cluster-example-2 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_3 | 0/10000000 | f(1 row)kubectl exec -it cluster-example-3 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_2 | 0/10000000 | f(1 row)
4.手工删除cluster-example-1的postgresql主实例
kubectl delete pods cluster-example-1 ─╯pod "cluster-example-1" deleted
5.cluster-example-1pod会重建,只启动72s
kubectl get pods ─╯NAME READY STATUS RESTARTS AGEcluster-example-1 1/1 Running 0 72scluster-example-2 1/1 Running 0 65mcluster-example-3 1/1 Running 0 64m
6.验证slots切换情况
cluster-example-2的slot情况:
kubectl exec -it cluster-example-2 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_1 | 0/100051E8 | t_cnpg_cluster_example_3 | 0/100051E8 | t(2 rows)
cluster-example-3的slot
kubectl exec -it cluster-example-3 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_1 | 0/100051E8 | f(1 row)
cluster-example-1的slot
kubectl exec -it cluster-example-1 -c postgres -- psql -q -c "SELECT slot_name, restart_lsn, active FROM pg_replication_slotsWHERE NOT temporary AND slot_type = 'physical'"slot_name | restart_lsn | active-------------------------+-------------+--------_cnpg_cluster_example_3 | 0/100051E8 | f(1 row)
7.由上面的测试可以验证CloudnativePG在Kubernetes环境下的自动高可用配置实现。
结论
物理故障转移槽是 Kubernetes PostgreSQL Operator 把“Day-2 运维”自动化的绝佳案例 —— 它模拟了 DBA 人工脚本,补足了 PostgreSQL 原生复制槽的集群级缺陷。
当前实现仅同步由 Operator 管理的 HA 槽,尚未包含用户自建槽(后续支持)。因此,生产环境建议始终启用故障转移槽,并:
合理设置 max_slot_wal_keep_size。
监控 WAL 磁盘使用率与复制槽 lag(CloudNativePG 已暴露 Prometheus 指标)。
仍需人工干预的两种极端情况:
WAL 磁盘耗尽;
Slot lag 超过阈值,副本永久落后。
此外,逻辑复制槽的故障转移不在本文范围。CloudNativePG 已集成 EDB 开源的 pg_failover_slots 扩展,此扩展本质上提取了 EDB 之前在 pglogical 中开发的技术,以有效地管理高可用性物理复制集群中逻辑复制槽的同步。
关于公司
感谢您关注新智锦绣科技(北京)有限公司!作为 Elastic 的 Elite 合作伙伴及 EnterpriseDB 在国内的唯一代理和服务合作伙伴,我们始终致力于技术创新和优质服务,帮助企业客户实现数据平台的高效构建与智能化管理。无论您是关注 Elastic 生态系统,还是需要 EnterpriseDB 的支持,我们都将为您提供专业的技术支持和量身定制的解决方案。
欢迎关注我们,获取更多技术资讯和数字化转型方案,共创美好未来!
 |  |
|---|---|
Elastic 微信群 | EDB 微信群 |
发现“分享”和“赞”了吗,戳我看看吧
