





从MySQL到OpenTenBase:电商平台分布式数据库架构升级实战
🌟 Hello,我是摘星!
🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
📖 摘要
作为一名在电商领域深耕多年的架构师,我深刻体会到随着业务规模的快速增长,传统单机MySQL数据库在处理海量数据和高并发访问时面临的瓶颈。在最近的一个大型电商平台项目中,我主导了从MySQL到OpenTenBase的完整迁移过程,这次技术选型和架构升级的经历让我对分布式数据库有了更深入的理解。
OpenTenBase作为腾讯开源的分布式关系型数据库,基于PostgreSQL构建,在保持ACID事务特性的同时提供了优秀的水平扩展能力。在我们的电商场景中,面对日均千万订单量、PB级数据存储需求,以及双11等大促期间的流量洪峰,OpenTenBase表现出了卓越的性能和稳定性。
本文将详细分享我在这次数据库架构升级中的实践经验,包括技术选型的考虑因素、架构设计的核心思路、数据迁移的具体步骤,以及最终的性能表现。我会从一个实践者的角度,为大家呈现一个完整的OpenTenBase应用案例,希望能为面临相似挑战的技术团队提供有价值的参考。通过这次实践,我们不仅解决了数据库性能瓶颈问题,还为后续的业务扩展打下了坚实的技术基础。
🎯 业务背景与挑战
业务场景概述
我们的电商平台服务于全国数千万用户,涵盖商品展示、订单处理、支付结算、物流跟踪等核心业务模块。随着平台用户数量从百万级增长到千万级,系统面临着前所未有的压力。
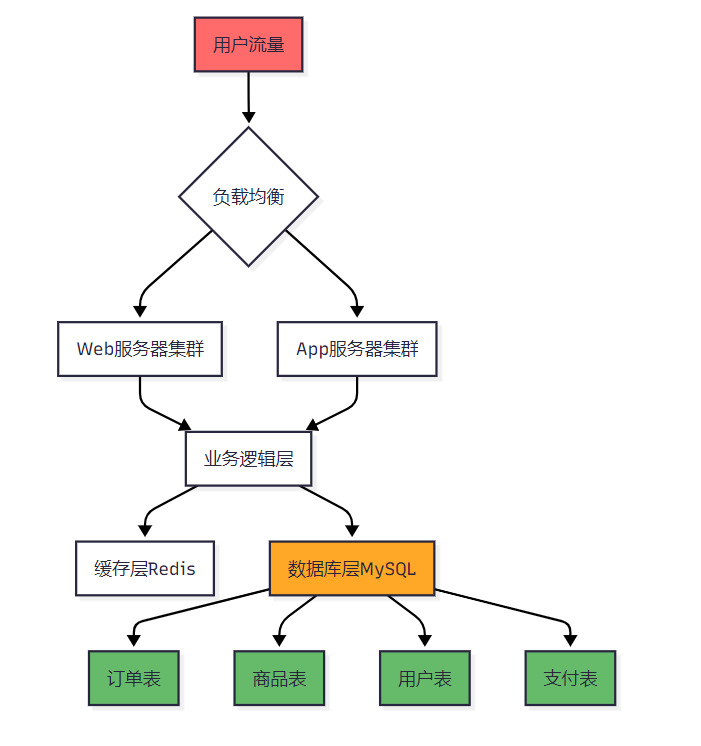
图1:原有MySQL单机架构流程图
面临的核心挑战
在业务快速发展过程中,我们遇到了以下关键挑战:
挑战类型 | 具体表现 | 影响程度 | 紧急程度 |
性能瓶颈 | 查询响应时间超过5秒 | 高 | 紧急 |
存储限制 | 单表数据量超过1亿条 | 高 | 紧急 |
扩展性差 | 无法水平扩展 | 中 | 重要 |
可用性低 | 主从延迟严重 | 高 | 紧急 |
维护困难 | 大表操作影响全库 | 中 | 重要 |
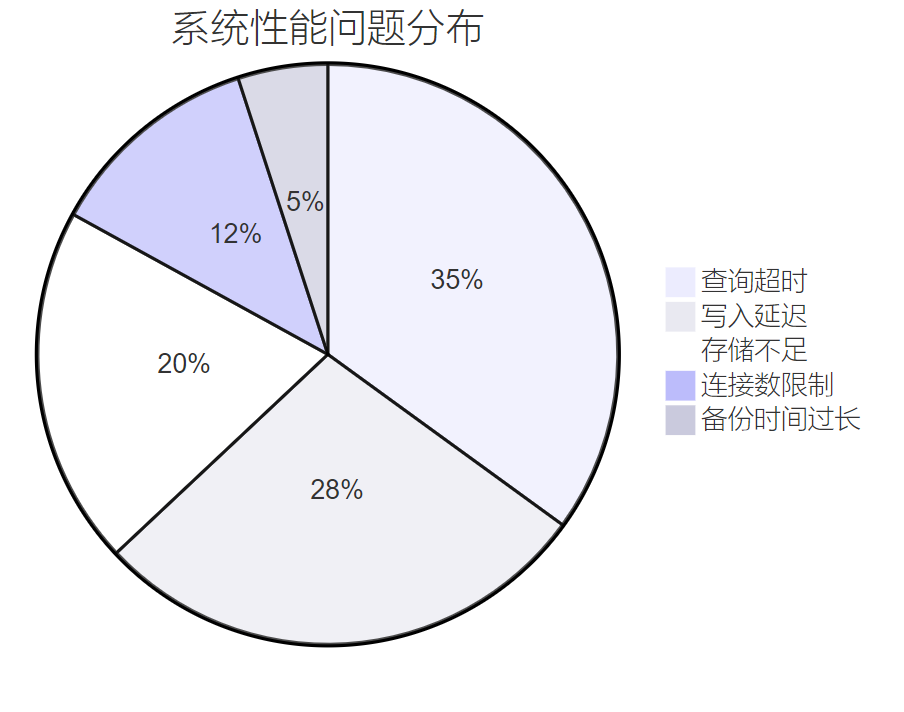
图2:系统性能问题分布饼图
"在分布式系统中,单点故障是最大的敌人。只有通过合理的架构设计,才能确保系统在高并发场景下的稳定性。" —— 《高可用架构设计》
🔍 技术选型分析
OpenTenBase选型依据
经过充分的技术调研和对比分析,我们最终选择了OpenTenBase作为新的数据库解决方案。主要考虑因素包括:
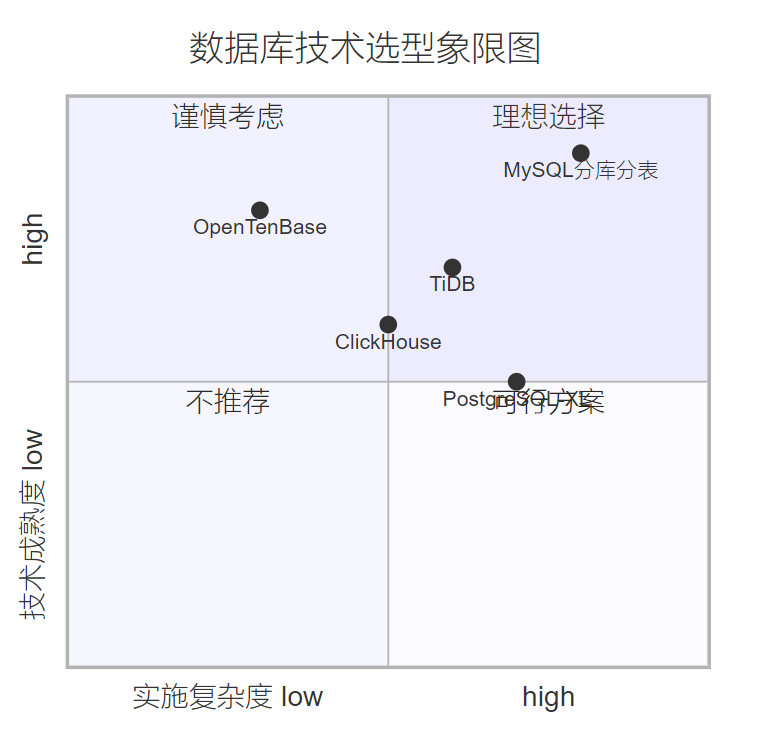
图3:数据库技术选型象限图
架构对比分析
对比传统MySQL分库分表方案,OpenTenBase展现出明显优势:
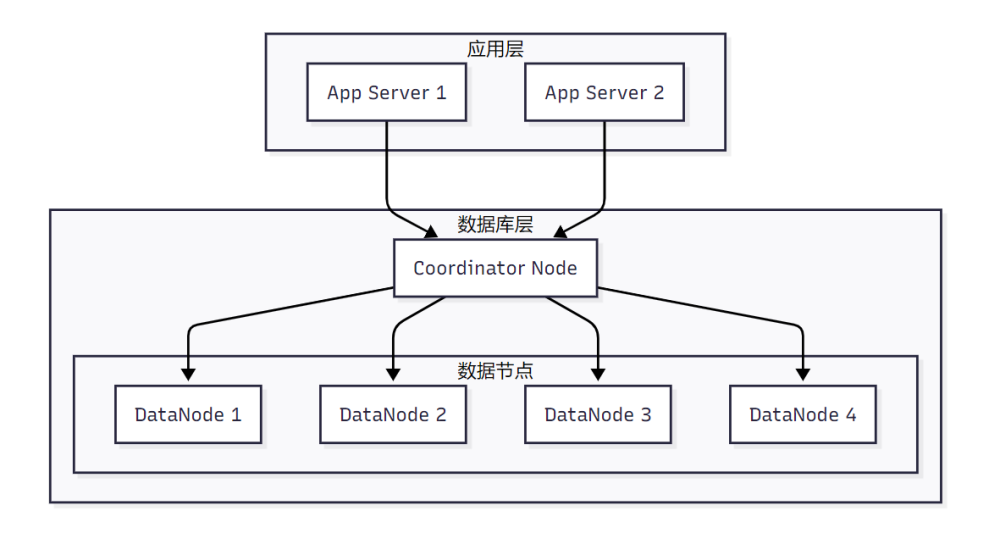
图4:OpenTenBase分布式架构图
🏗️ 架构设计与实施
集群规划设计
基于业务特点和性能需求,我们设计了如下的OpenTenBase集群架构:
# 集群节点配置脚本
import yaml
def generate_cluster_config():
"""生成OpenTenBase集群配置"""
cluster_config = {
'coordinator_nodes': [
{
'id': 'cn1',
'host': '10.0.1.10',
'port': 5432,
'role': 'coordinator'
},
{
'id': 'cn2',
'host': '10.0.1.11',
'port': 5432,
'role': 'coordinator_standby'
}
],
'data_nodes': []
}
# 生成8个数据节点配置
for i in range(1, 9):
data_node = {
'id': f'dn{i}',
'host': f'10.0.2.{10+i}',
'port': 5432,
'shard_id': i,
'replica_nodes': [f'10.0.3.{10+i}'] # 每个分片配置一个副本
}
cluster_config['data_nodes'].append(data_node)
return cluster_config
# 保存配置到文件
config = generate_cluster_config()
with open('opentenbase_cluster.yaml', 'w') as f:
yaml.dump(config, f, default_flow_style=False)
print("OpenTenBase集群配置生成完成")
print(f"协调节点数量: {len(config['coordinator_nodes'])}")
print(f"数据节点数量: {len(config['data_nodes'])}")
分片策略设计
针对电商业务特点,我们采用了混合分片策略:
-- 订单表分片设计
CREATE TABLE orders (
order_id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
product_id BIGINT,
order_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
amount DECIMAL(10,2),
status VARCHAR(20),
-- 其他订单字段
INDEX idx_user_id (user_id),
INDEX idx_order_time (order_time)
) DISTRIBUTE BY HASH(order_id);
-- 用户表分片设计
CREATE TABLE users (
user_id BIGINT PRIMARY KEY,
username VARCHAR(64) UNIQUE,
email VARCHAR(128),
phone VARCHAR(20),
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) DISTRIBUTE BY HASH(user_id);
-- 商品表设计(热点数据复制到所有节点)
CREATE TABLE products (
product_id BIGINT PRIMARY KEY,
product_name VARCHAR(255),
category_id INT,
price DECIMAL(10,2),
stock_count INT,
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) DISTRIBUTE BY REPLICATION;
这里的关键设计考虑:
- 订单表:按order_id哈希分片,确保数据均匀分布
- 用户表:按user_id哈希分片,便于用户相关查询
- 商品表:采用复制分布,因为商品信息查询频繁且相对稳定
数据迁移实施
数据迁移是整个项目的关键环节,我们采用了分阶段、低影响的迁移策略:
#!/bin/bash
# OpenTenBase数据迁移脚本
set -e
# 配置变量
MYSQL_HOST="192.168.1.100"
MYSQL_PORT=3306
MYSQL_USER="migration_user"
MYSQL_PASS="migration_pass"
MYSQL_DB="ecommerce"
OPENTENBASE_HOST="10.0.1.10"
OPENTENBASE_PORT=5432
OPENTENBASE_USER="otb_user"
OPENTENBASE_PASS="otb_pass"
OPENTENBASE_DB="ecommerce"
# 创建迁移日志目录
mkdir -p ./migration_logs
echo "开始数据迁移过程..."
# 1. 导出MySQL数据结构
echo "Step 1: 导出MySQL表结构"
mysqldump -h${MYSQL_HOST} -P${MYSQL_PORT} -u${MYSQL_USER} -p${MYSQL_PASS} \
--no-data --routines --triggers ${MYSQL_DB} > ./migration_logs/schema_dump.sql
# 2. 转换为OpenTenBase兼容的DDL
echo "Step 2: 转换DDL语法"
python3 convert_ddl.py ./migration_logs/schema_dump.sql ./migration_logs/opentenbase_schema.sql
# 3. 在OpenTenBase中创建表结构
echo "Step 3: 在OpenTenBase中创建表结构"
psql -h${OPENTENBASE_HOST} -p${OPENTENBASE_PORT} -U${OPENTENBASE_USER} \
-d${OPENTENBASE_DB} -f ./migration_logs/opentenbase_schema.sql
# 4. 分批次数据迁移
echo "Step 4: 开始分批次数据迁移"
# 定义要迁移的表列表
TABLES=("users" "products" "categories" "orders" "order_items")
for table in "${TABLES[@]}"; do
echo "正在迁移表: $table"
# 获取表的总行数
row_count=$(mysql -h${MYSQL_HOST} -P${MYSQL_PORT} -u${MYSQL_USER} -p${MYSQL_PASS} \
-e "SELECT COUNT(*) FROM ${MYSQL_DB}.${table};" -N)
echo "表 $table 共有 $row_count 行数据"
# 分批迁移,每批10万条
batch_size=100000
offset=0
while [ $offset -lt $row_count ]; do
echo "迁移 $table 表,偏移量: $offset,批次大小: $batch_size"
# 导出当前批次数据
mysql -h${MYSQL_HOST} -P${MYSQL_PORT} -u${MYSQL_USER} -p${MYSQL_PASS} \
-e "SELECT * FROM ${MYSQL_DB}.${table} LIMIT ${batch_size} OFFSET ${offset};" \
--batch --raw > ./migration_logs/${table}_batch_${offset}.tsv
# 导入到OpenTenBase
psql -h${OPENTENBASE_HOST} -p${OPENTENBASE_PORT} -U${OPENTENBASE_USER} \
-d${OPENTENBASE_DB} -c "\\COPY ${table} FROM './migration_logs/${table}_batch_${offset}.tsv'"
offset=$((offset + batch_size))
# 清理临时文件
rm -f ./migration_logs/${table}_batch_${offset}.tsv
done
echo "表 $table 迁移完成"
done
echo "数据迁移完成!"
# 5. 验证数据一致性
echo "Step 5: 验证数据一致性"
python3 validate_migration.py
echo "迁移验证完成!"
OpenTenBase简介
OpenTenBase是一个关系型数据库集群平台,提供写入可靠性和多节点数据同步功能。可以在一台或多台主机上配置OpenTenBase,并将数据存储在多个物理主机上。
OpenTenBase架构组件:
- Coordinator Node (CN):应用程序访问入口,负责数据分布和查询计划。多个节点位于同一位置,每个节点提供相同的数据库视图
- Datanode Node (DN):每个DN存储用户数据的分区。在功能上,DN节点负责完成CN分发的执行请求
- GTM Node (Global Transaction Manager):负责集群事务信息的管理,以及集群的全局对象(如序列)
系统要求
硬件要求:
- 内存:最低4GB RAM
- 操作系统:OpenCloudOS 9
- 服务器:腾讯云CVM实例
软件依赖:
gcc make readline-devel zlib-devel openssl-devel uuid-devel bison flex git
环境准备
1. 更新系统并安装依赖包
由于OpenCloudOS支持dnf和yum两种包管理软件,强烈推荐用户更多地使用dnf,我们使用dnf来安装依赖:
# 更新系统
sudo dnf update -y
# 安装OpenTenBase编译依赖
sudo dnf install -y \
gcc \
gcc-c++ \
make \
cmake \
readline-devel \
zlib-devel \
openssl-devel \
uuid-devel \
bison \
flex \
git \
libcurl-devel \
libxml2-devel \
libxslt-devel \
perl-IPC-Run \
perl-Test-Simple \
tcl-devel \
python3-devel \
rpm-build \
pkgconfig \
krb5-devel \
openldap-devel

# 下载zstd源码
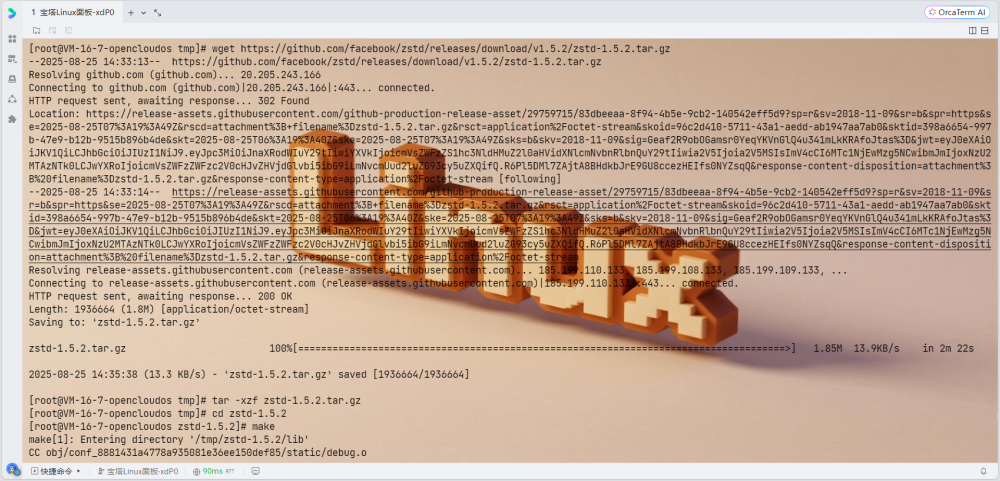
cd /tmp
wget https://github.com/facebook/zstd/releases/download/v1.5.2/zstd-1.5.2.tar.gz
tar -xzf zstd-1.5.2.tar.gz
cd zstd-1.5.2
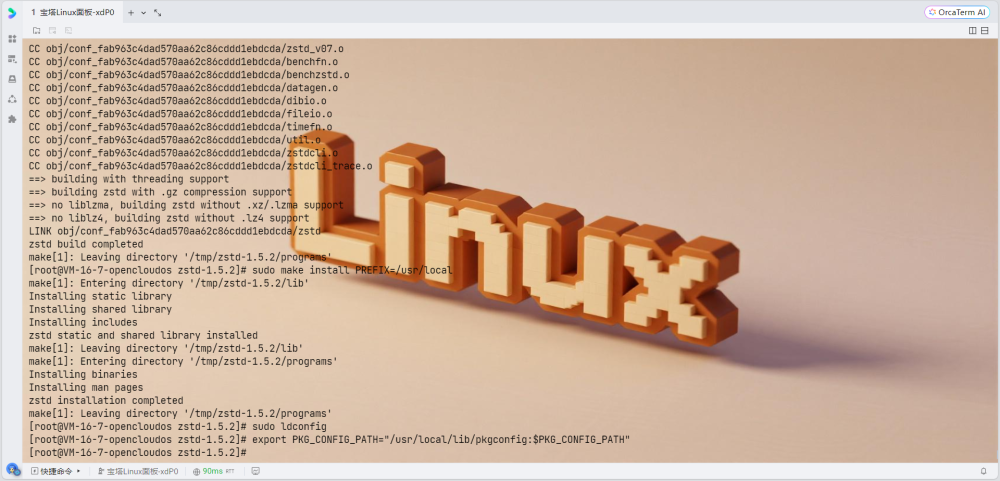
# 编译安装
make
sudo make install PREFIX=/usr/local
# 更新库路径
sudo ldconfig
# 设置环境变量
export PKG_CONFIG_PATH="/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH"
# 下载lz4源码
cd /tmp
wget https://github.com/lz4/lz4/archive/v1.9.4.tar.gz
tar -xzf v1.9.4.tar.gz
cd lz4-1.9.4
# 编译安装
make
sudo make install PREFIX=/usr/local
# 更新库路径
sudo ldconfig
# 设置环境变量
export PKG_CONFIG_PATH="/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH"
export LD_LIBRARY_PATH="/usr/local/lib:$LD_LIBRARY_PATH"

# 首先检查当前的包管理器状态
sudo dnf clean all
# 安装libxml2-devel及其依赖包
sudo dnf install -y \
libxml2-devel \
libxml2 \
cmake-filesystem \
xz-devel \
zlib-devel \
pkgconfig
# 验证安装
rpm -qa | grep libxml2
# 检查xml2-config命令是否可用
which xml2-config
# 检查pkg-config是否能找到libxml-2.0
pkg-config --exists libxml-2.0 && echo "libxml2 found" || echo "libxml2 NOT found"
# 查看libxml2的配置信息
xml2-config --version
xml2-config --cflags
xml2-config --libs
sudo dnf search cli11
sudo dnf install -y cli11-devel
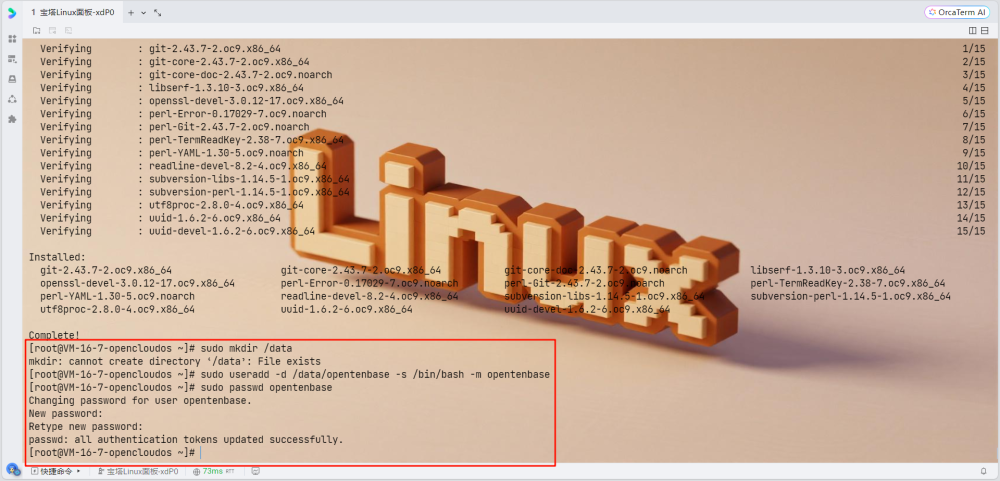
2. 创建专用用户
所有需要安装OpenTenBase集群的机器都需要创建专用用户:
# 创建数据目录
sudo mkdir /data
# 创建opentenbase用户
sudo useradd -d /data/opentenbase -s /bin/bash -m opentenbase
# 设置密码
sudo passwd opentenbase
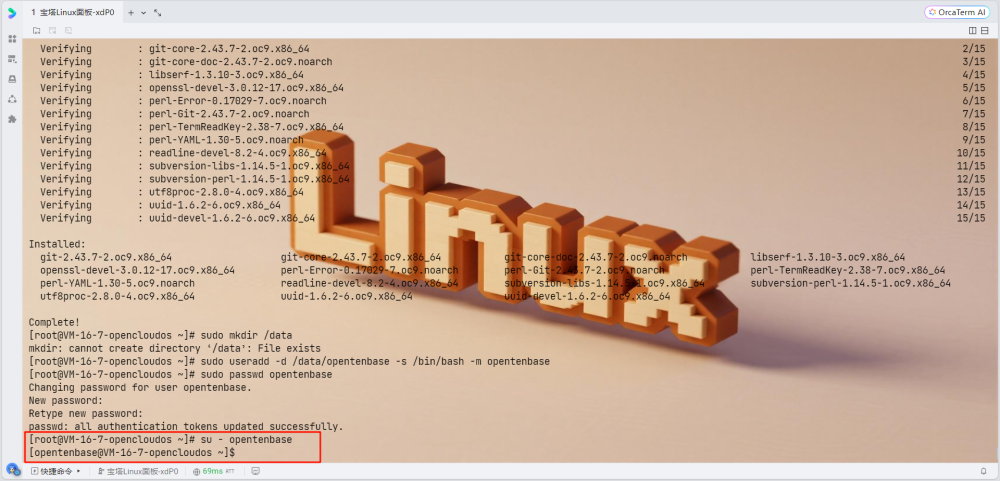
3. 切换到opentenbase用户
su - opentenbase
源码编译安装
1. 获取源码
cd /data/opentenbase
git clone https://gitee.com/mirrors/OpenTenBase.git
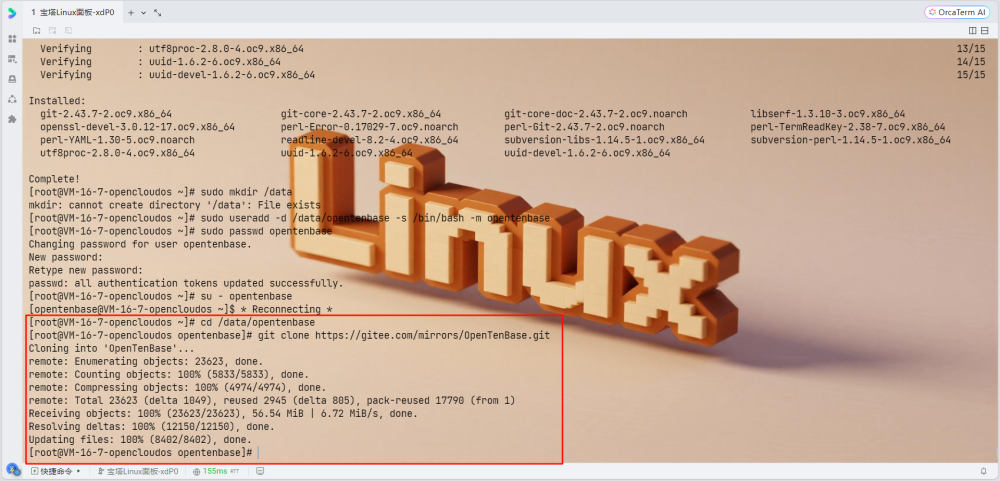
2. 编译源码
# 设置环境变量
export SOURCECODE_PATH=/data/opentenbase/OpenTenBase
export INSTALL_PATH=/data/opentenbase/install

# 进入源码目录
cd ${SOURCECODE_PATH}
# 配置编译选项
chmod +x configure*
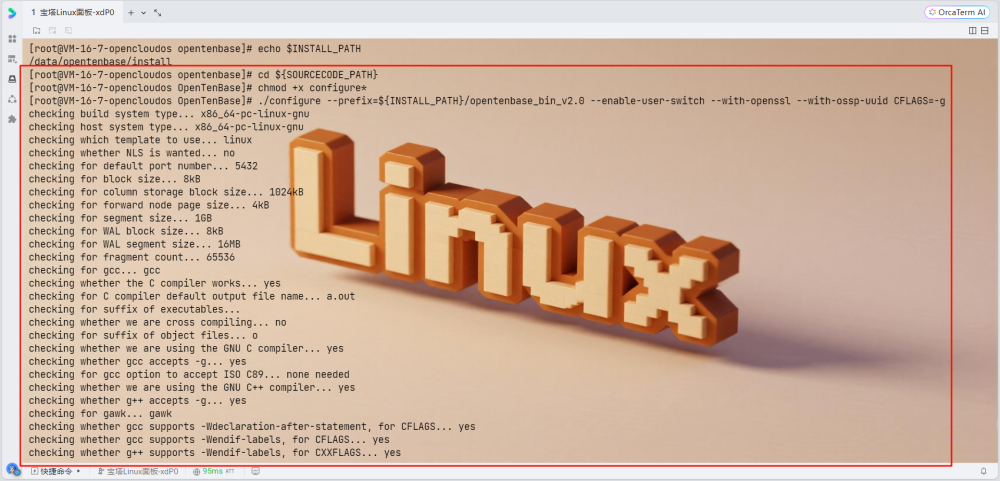
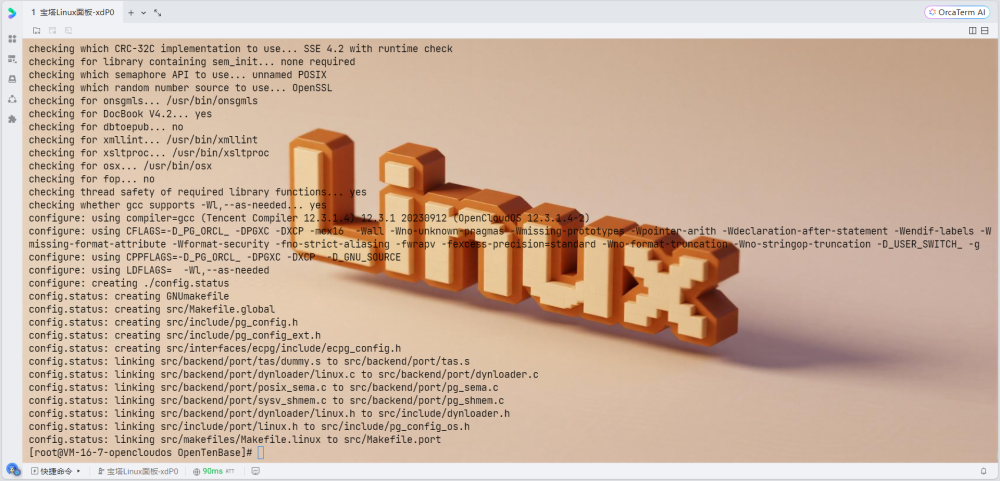
# 编译和安装
make distclean 2>/dev/null || true
rm -rf /data/opentenbase/install/opentenbase_bin_v2.0
rm -f config.status config.log
# 重新配置,添加SSE4.2支持
CFLAGS="-g -O2 -w -msse4.2 -mcrc32" \
CXXFLAGS="-g -O2 -w -msse4.2 -mcrc32" \
./configure --prefix=/data/opentenbase/install/opentenbase_bin_v2.0 \
--enable-user-switch \
--with-openssl \
--with-ossp-uuid \
--with-libxml
# 编译
make
make install
# 编译contrib模块
chmod +x contrib/pgxc_ctl/make_signature
cd contrib
make
make install


集中式单节点集群配置
1. 配置环境变量
# 编辑bashrc文件
vim ~/.bashrc
# 添加以下内容:
export OPENTENBASE_HOME=/data/opentenbase/install/opentenbase_bin_v2.0
export PATH=$OPENTENBASE_HOME/bin:$PATH
export LD_LIBRARY_PATH=$OPENTENBASE_HOME/lib:${LD_LIBRARY_PATH}
export LC_ALL=C
# 生效环境变量
source ~/.bashrc


2. 创建集群配置目录
mkdir /data/opentenbase/pgxc_ctl
cd /data/opentenbase/pgxc_ctl

3. 创建集中式配置文件
cat > /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf << 'EOF'
#!/usr/bin/env bash
#---- OVERALL -----------------------------------------------------------------------------
pgxcOwner=opentenbase
pgxcUser=$pgxcOwner
tmpDir=/tmp
localTmpDir=$tmpDir
configBackup=y
configBackupHost=localhost
configBackupDir=$HOME/pgxc
configBackupFile=pgxc_ctl.bak
#---- GTM --------------------------------------------------------------------------------
gtmName=gtm
gtmMasterServer=localhost
gtmMasterPort=6666
gtmMasterDir=/data/opentenbase/data/gtm
gtmExtraConfig=none
gtmMasterSpecificExtraConfig=none
# GTM Slave - disabled
gtmSlave=n
gtmSlaveName=gtmSlave
gtmSlaveServer=none
gtmSlavePort=20001
gtmSlaveDir=none
gtmSlaveSpecificExtraConfig=none
# GTM Proxy - disabled
gtmProxy=n
gtmProxyNames=()
gtmProxyServers=()
gtmProxyPorts=()
gtmProxyDirs=()
gtmPxyExtraConfig=none
gtmPxySpecificExtraConfig=()
#---- Coordinators --------------------------------------------------------------------
coordMasterDir=/data/opentenbase/data/coord_master
coordSlaveDir=/data/opentenbase/data/coord_slave
coordArchLogDir=/data/opentenbase/data/coord_archlog
# 协调器配置数组 - 所有数组必须有相同数量的元素
coordNames=(cn001)
coordPorts=(30004)
poolerPorts=(30014)
coordForwardPorts=(30024)
coordPgHbaEntries=(0.0.0.0/0)
# Master Coordinators
coordMasterServers=(localhost)
coordMasterDirs=(/data/opentenbase/data/coord_master/cn001)
coordMaxWALsender=5
coordMaxWALSenders=(5)
# Coordinator Slave - disabled
coordSlave=n
coordSlaveSync=n
coordSlaveServers=(none)
coordSlavePorts=(30005)
coordSlavePoolerPorts=(30015)
coordSlaveForwardPorts=(30025)
coordSlaveDirs=(none)
coordArchLogDirs=(none)
# Configuration files
coordExtraConfig=none
coordSpecificExtraConfig=(none)
coordSpecificExtraPgHba=(none)
#---- Datanodes -----------------------------------------------------------------------
datanodeMasterDir=/data/opentenbase/data/dn_master
datanodeSlaveDir=/data/opentenbase/data/dn_slave
datanodeArchLogDir=/data/opentenbase/data/datanode_archlog
# 数据节点配置数组 - 所有数组必须有相同数量的元素
primaryDatanode=dn001
datanodeNames=(dn001)
datanodePorts=(20008)
datanodePoolerPorts=(20018)
datanodeForwardPorts=(20028)
datanodePgHbaEntries=(0.0.0.0/0)
# Master Datanodes
datanodeMasterServers=(localhost)
datanodeMasterDirs=(/data/opentenbase/data/dn_master/dn001)
datanodeMaxWalSender=5
datanodeMaxWALSenders=(5)
# Datanode Slave - disabled
datanodeSlave=n
datanodeSlaveServers=(none)
datanodeSlavePorts=(20009)
datanodeSlavePoolerPorts=(20019)
datanodeSlaveForwardPorts=(20029)
datanodeSlaveDirs=(none)
datanodeArchLogDirs=(none)
# Configuration files
datanodeExtraConfig=none
datanodeSpecificExtraConfig=(none)
datanodeSpecificExtraPgHba=(none)
# WAL Archive - disabled
walArchive=n
EOF
# 检查配置文件语法
bash -n /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf
echo "配置文件语法检查结果: $?"
# 查看文件内容确认
head -20 /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf
检查环境变量
# 检查当前环境变量
echo $PATH
echo $OPENTENBASE_HOME
which initdb
which gtm_ctl
重新设置环境变量
# 退出pgxc_ctl
quit
# 重新设置环境变量
export OPENTENBASE_HOME=/data/opentenbase/install/opentenbase_bin_v2.0
export PATH=$OPENTENBASE_HOME/bin:$PATH
export LD_LIBRARY_PATH=$OPENTENBASE_HOME/lib:${LD_LIBRARY_PATH}
export LC_ALL=C
# 验证命令是否可用
which initdb
which gtm_ctl
which pg_ctl
永久保存环境变量
# 编辑 .bashrc 文件
vim ~/.bashrc
# 添加以下内容到文件末尾:
export OPENTENBASE_HOME=/data/opentenbase/install/opentenbase_bin_v2.0
export PATH=$OPENTENBASE_HOME/bin:$PATH
export LD_LIBRARY_PATH=$OPENTENBASE_HOME/lib:${LD_LIBRARY_PATH}
export LC_ALL=C
# 重新加载环境变量
source ~/.bashrc
重新创建完整的配置文件
# 删除不完整的配置文件
rm /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf
# 重新创建完整配置文件
cat > /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf << 'EOF'
#!/usr/bin/env bash
#---- OVERALL -----------------------------------------------------------------------------
pgxcOwner=opentenbase
pgxcUser=$pgxcOwner
tmpDir=/tmp
localTmpDir=$tmpDir
configBackup=y
configBackupHost=localhost
configBackupDir=$HOME/pgxc
configBackupFile=pgxc_ctl.bak
#---- GTM --------------------------------------------------------------------------------
gtmName=gtm
gtmMasterServer=localhost
gtmMasterPort=6666
gtmMasterDir=/data/opentenbase/data/gtm
gtmExtraConfig=none
gtmMasterSpecificExtraConfig=none
gtmSlave=n
gtmSlaveName=gtmSlave
gtmSlaveServer=none
gtmSlavePort=20001
gtmSlaveDir=none
gtmSlaveSpecificExtraConfig=none
gtmProxy=n
gtmProxyNames=()
gtmProxyServers=()
gtmProxyPorts=()
gtmProxyDirs=()
gtmPxyExtraConfig=none
gtmPxySpecificExtraConfig=()
#---- Coordinators --------------------------------------------------------------------
coordMasterDir=/data/opentenbase/data/coord_master
coordSlaveDir=/data/opentenbase/data/coord_slave
coordArchLogDir=/data/opentenbase/data/coord_archlog
coordNames=(cn001)
coordPorts=(30004)
poolerPorts=(30014)
coordForwardPorts=(30024)
coordPgHbaEntries=(0.0.0.0/0)
coordMasterServers=(localhost)
coordMasterDirs=(/data/opentenbase/data/coord_master/cn001)
coordMaxWALsender=5
coordMaxWALSenders=(5)
coordSlave=n
coordSlaveSync=n
coordSlaveServers=(none)
coordSlavePorts=(30005)
coordSlavePoolerPorts=(30015)
coordSlaveForwardPorts=(30025)
coordSlaveDirs=(none)
coordArchLogDirs=(none)
coordExtraConfig=none
coordSpecificExtraConfig=(none)
coordSpecificExtraPgHba=(none)
#---- Datanodes -----------------------------------------------------------------------
datanodeMasterDir=/data/opentenbase/data/dn_master
datanodeSlaveDir=/data/opentenbase/data/dn_slave
datanodeArchLogDir=/data/opentenbase/data/datanode_archlog
primaryDatanode=dn001
datanodeNames=(dn001)
datanodePorts=(20008)
datanodePoolerPorts=(20018)
datanodeForwardPorts=(20028)
datanodePgHbaEntries=(0.0.0.0/0)
datanodeMasterServers=(localhost)
datanodeMasterDirs=(/data/opentenbase/data/dn_master/dn001)
datanodeMaxWalSender=5
datanodeMaxWALSenders=(5)
datanodeSlave=n
datanodeSlaveServers=(none)
datanodeSlavePorts=(20009)
datanodeSlavePoolerPorts=(20019)
datanodeSlaveForwardPorts=(20029)
datanodeSlaveDirs=(none)
datanodeArchLogDirs=(none)
datanodeExtraConfig=none
datanodeSpecificExtraConfig=(none)
datanodeSpecificExtraPgHba=(none)
walArchive=n
EOF
验证配置文件
# 检查配置文件语法
bash -n /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf
echo "语法检查结果: $?"
# 查看文件完整性
wc -l /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf
tail -10 /data/opentenbase/install/opentenbase_bin_v2.0/pgxc_ctl.conf
配置SSH免密登录
# 生成SSH密钥(如果还没有)
if [ ! -f ~/.ssh/id_rsa ]; then
ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
fi
# 配置本地免密登录
ssh-copy-id opentenbase@localhost
# 或者手动添加
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
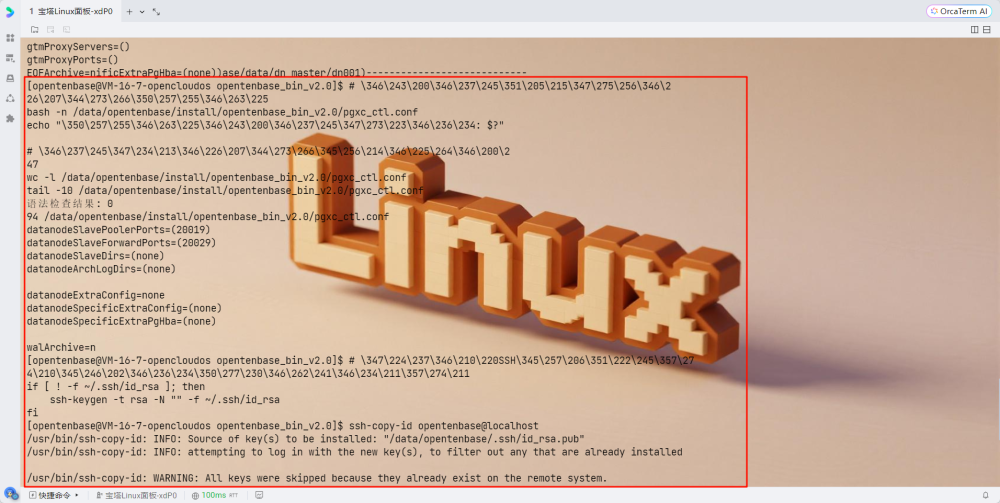
测试SSH连接
# 测试SSH连接是否正常
ssh opentenbase@localhost "echo 'SSH connection test successful'"

重新运行pgxc_ctl
# 现在重新运行pgxc_ctl
pgxc_ctl
# 在pgxc_ctl中执行:
deploy all
init all
start all
monitor all
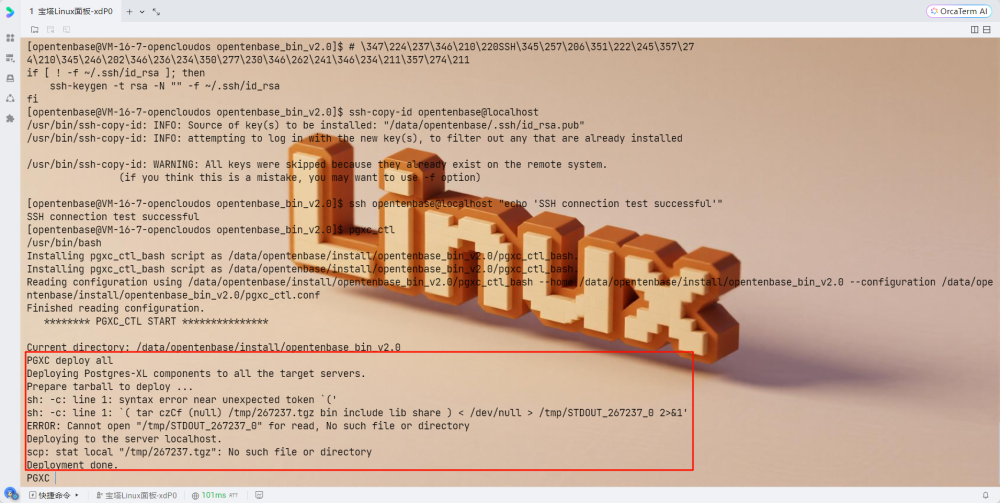
4. 部署和初始化集群
# 启动pgxc_ctl工具
pgxc_ctl
# 在pgxc_ctl命令行中执行:
deploy all
init all
# 退出pgxc_ctl
exit
# 设置opentenbase用户的SSH密钥认证
su - opentenbase
# 生成SSH密钥对
ssh-keygen -t rsa -b 2048 -f ~/.ssh/id_rsa -N ""
# 将公钥添加到authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
chmod 700 ~/.ssh
# 测试SSH连接(应该不需要密码)
ssh opentenbase@127.0.0.1 "echo 'SSH连接测试成功'"
MQgnDKIwotjP9+vkGc9jehXXIzfXSJ2+ZAnFP5IDvIc.
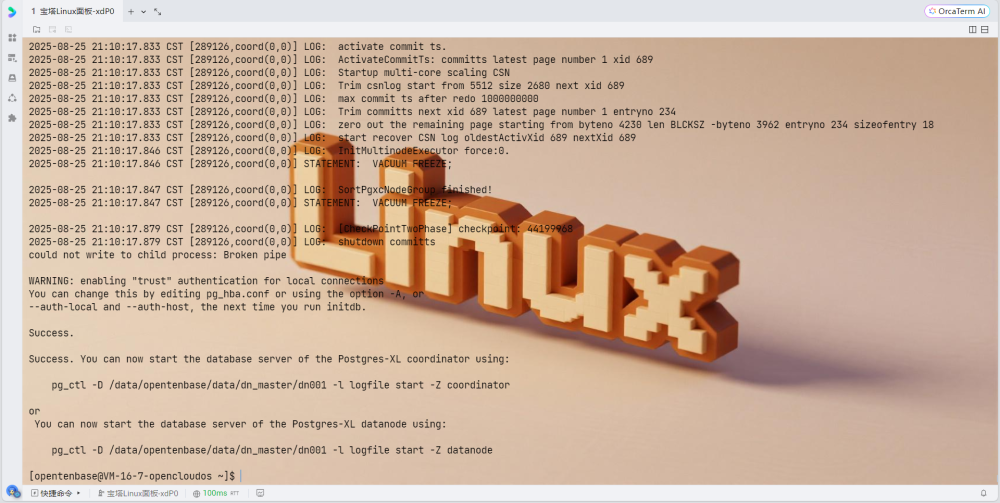
5. 验证集群状态
# 在pgxc_ctl中检查集群状态
monitor all
正常情况下应该显示:
Running: gtm master
Running: coordinator master cn001
Running: datanode master dn001
配置防火墙(可选)
如果启用了防火墙,需要开放相应端口:
# 开放GTM端口
sudo firewall-cmd --permanent --add-port=50001/tcp
# 开放Coordinator端口
sudo firewall-cmd --permanent --add-port=30004/tcp
sudo firewall-cmd --permanent --add-port=31110/tcp
# 开放Datanode端口
sudo firewall-cmd --permanent --add-port=40004/tcp
sudo firewall-cmd --permanent --add-port=41110/tcp
# 重新加载防火墙规则
sudo firewall-cmd --reload
数据库初始化和使用
1. 连接数据库
psql -h localhost -p 30004 -d postgres -U opentenbase
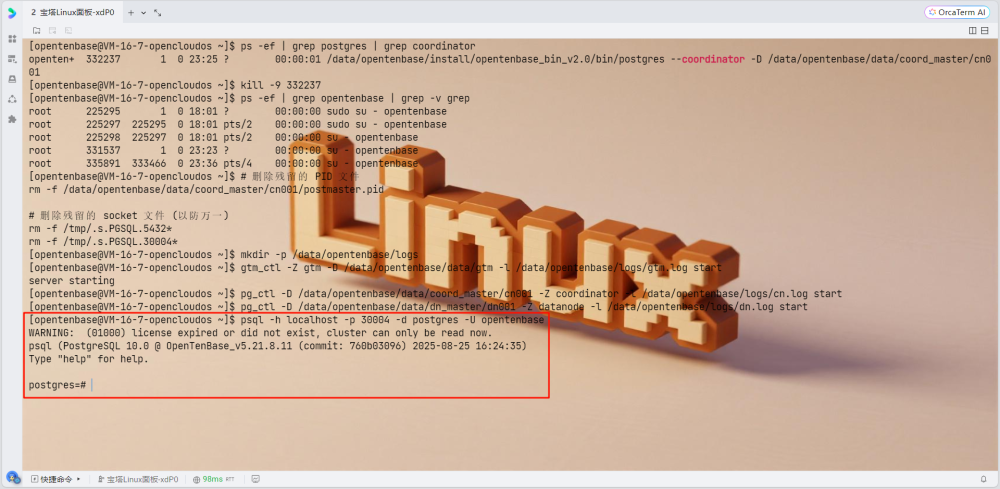
2. 创建必要的节点组和分片组
OpenTenBase使用数据节点组来增加节点管理的灵活性。需要创建一个默认组来使用,因此需要提前创建。通常,所有数据节点都会被添加到默认组中:
-- 创建默认节点组
CREATE DEFAULT NODE GROUP default_group WITH (dn001);
-- 创建分片组
CREATE SHARDING GROUP TO GROUP default_group;
3. 创建数据库和表
-- 创建测试数据库
CREATE DATABASE testdb;
-- 创建用户
CREATE USER testuser WITH PASSWORD 'testpass';
-- 授权
ALTER DATABASE testdb OWNER TO testuser;
-- 切换到测试数据库
\c testdb testuser
-- 创建分片表
CREATE TABLE test_table(
id BIGINT,
name TEXT,
created_time TIMESTAMP DEFAULT NOW()
) DISTRIBUTE BY SHARD(id);
-- 插入测试数据
INSERT INTO test_table(id, name) VALUES
(1, 'OpenTenBase'),
(2, 'TencentCloud'),
(3, 'OpenCloudOS');
-- 查询测试
SELECT * FROM test_table;
集群管理
1. 启动集群
pgxc_ctl
start all
2. 停止集群
pgxc_ctl
stop all
3. 清理集群(重新初始化时使用)
pgxc_ctl
clean all
故障排查
1. 查看日志
如果初始化失败,可以查看日志:
# 查看pgxc_ctl日志
ls ~/pgxc_ctl/pgxc_log/
cat ~/pgxc_ctl/pgxc_log/最新的日志文件
# 查看各组件日志
ls /data/opentenbase/data/gtm/pg_log/
ls /data/opentenbase/data/coord/pg_log/
ls /data/opentenbase/data/dn001/pg_log/
2. 常见问题解决
- 权限问题:确保opentenbase用户对所有数据目录有读写权限
- 端口冲突:检查配置的端口是否被其他服务占用
- 内存不足:调整shared_buffers等内存参数
- 网络问题:检查防火墙和网络连接
性能优化建议
1. 内存优化
根据服务器配置调整postgresql.conf中的内存参数:
shared_buffers = 25% of RAM # 例如8GB内存设置为2GB
effective_cache_size = 75% of RAM
work_mem = 4MB
maintenance_work_mem = 64MB
2. 连接优化
max_connections = 200 # 根据应用需求调整
max_pool_size = 1000 # 连接池大小
3. 日志优化
log_min_duration_statement = 1000 # 记录执行时间超过1秒的查询
log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d,app=%a,client=%h '
log_checkpoints = on
log_connections = on
log_disconnections = on
🚀 性能优化与调优
查询性能优化
迁移完成后,我们针对电商业务的典型查询场景进行了针对性优化:
-- 优化前:用户订单查询(跨分片查询)
SELECT o.order_id, o.amount, o.status, p.product_name
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.user_id = 123456
ORDER BY o.order_time DESC
LIMIT 20;
-- 优化后:增加分布键提示,避免全分片扫描
SELECT /*+ use_distribute_key(orders.user_id) */
o.order_id, o.amount, o.status, p.product_name
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
JOIN products p ON oi.product_id = p.product_id
WHERE o.user_id = 123456
ORDER BY o.order_time DESC
LIMIT 20;
-- 创建复合索引优化查询性能
CREATE INDEX CONCURRENTLY idx_orders_user_time
ON orders(user_id, order_time DESC);
-- 分区表优化:按月分区存储历史订单
CREATE TABLE orders_archive (
LIKE orders INCLUDING ALL
) PARTITION BY RANGE (order_time);
-- 创建月度分区
CREATE TABLE orders_2024_01 PARTITION OF orders_archive
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
CREATE TABLE orders_2024_02 PARTITION OF orders_archive
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
-- ... 其他月份分区
连接池配置优化
为了充分发挥OpenTenBase的性能优势,我们对连接池进行了精细化配置:
# 连接池优化配置
import psycopg2
from psycopg2 import pool
import threading
import time
class OpenTenBaseConnectionManager:
def __init__(self, config):
"""初始化OpenTenBase连接管理器"""
self.config = config
self.connection_pools = {}
self.setup_connection_pools()
def setup_connection_pools(self):
"""设置连接池"""
# 协调节点连接池(读写操作)
self.connection_pools['coordinator'] = psycopg2.pool.ThreadedConnectionPool(
minconn=20, # 最小连接数
maxconn=100, # 最大连接数
host=self.config['coordinator_host'],
port=self.config['coordinator_port'],
database=self.config['database'],
user=self.config['user'],
password=self.config['password'],
# 连接参数优化
connect_timeout=10,
application_name='ecommerce_app',
options='-c statement_timeout=30000' # 30秒超时
)
# 只读副本连接池(只读查询分流)
for i, replica_host in enumerate(self.config['replica_hosts']):
pool_name = f'replica_{i}'
self.connection_pools[pool_name] = psycopg2.pool.ThreadedConnectionPool(
minconn=10,
maxconn=50,
host=replica_host,
port=self.config['coordinator_port'],
database=self.config['database'],
user=self.config['readonly_user'],
password=self.config['readonly_password'],
connect_timeout=10,
application_name='ecommerce_readonly'
)
def get_connection(self, read_only=False):
"""获取数据库连接"""
if read_only:
# 负载均衡选择只读副本
import random
replica_pools = [k for k in self.connection_pools.keys() if k.startswith('replica_')]
if replica_pools:
pool_name = random.choice(replica_pools)
return self.connection_pools[pool_name].getconn()
return self.connection_pools['coordinator'].getconn()
def return_connection(self, conn, pool_type='coordinator'):
"""归还连接到连接池"""
if pool_type in self.connection_pools:
self.connection_pools[pool_type].putconn(conn)
# 业务层数据访问对象
class OrderDAO:
def __init__(self, connection_manager):
self.conn_mgr = connection_manager
def get_user_orders(self, user_id, page=1, page_size=20):
"""获取用户订单列表(读操作,使用只读副本)"""
conn = self.conn_mgr.get_connection(read_only=True)
try:
with conn.cursor() as cursor:
offset = (page - 1) * page_size
cursor.execute("""
SELECT order_id, amount, status, order_time
FROM orders
WHERE user_id = %s
ORDER BY order_time DESC
LIMIT %s OFFSET %s
""", (user_id, page_size, offset))
return cursor.fetchall()
finally:
self.conn_mgr.return_connection(conn, 'replica_0')
def create_order(self, order_data):
"""创建新订单(写操作,使用协调节点)"""
conn = self.conn_mgr.get_connection(read_only=False)
try:
with conn.cursor() as cursor:
cursor.execute("""
INSERT INTO orders (user_id, amount, status, order_time)
VALUES (%(user_id)s, %(amount)s, %(status)s, %(order_time)s)
RETURNING order_id
""", order_data)
return cursor.fetchone()[0]
except Exception as e:
conn.rollback()
raise
else:
conn.commit()
finally:
self.conn_mgr.return_connection(conn, 'coordinator')
这里的优化要点包括:
- 分离读写操作:只读查询路由到副本节点,减轻主节点压力
- 连接池大小调优:根据业务负载特点配置合适的连接数
- 超时时间设置:避免长查询影响整体性能
📊 性能测试与效果评估
压力测试结果
我们使用JMeter对OpenTenBase集群进行了全面的性能测试:
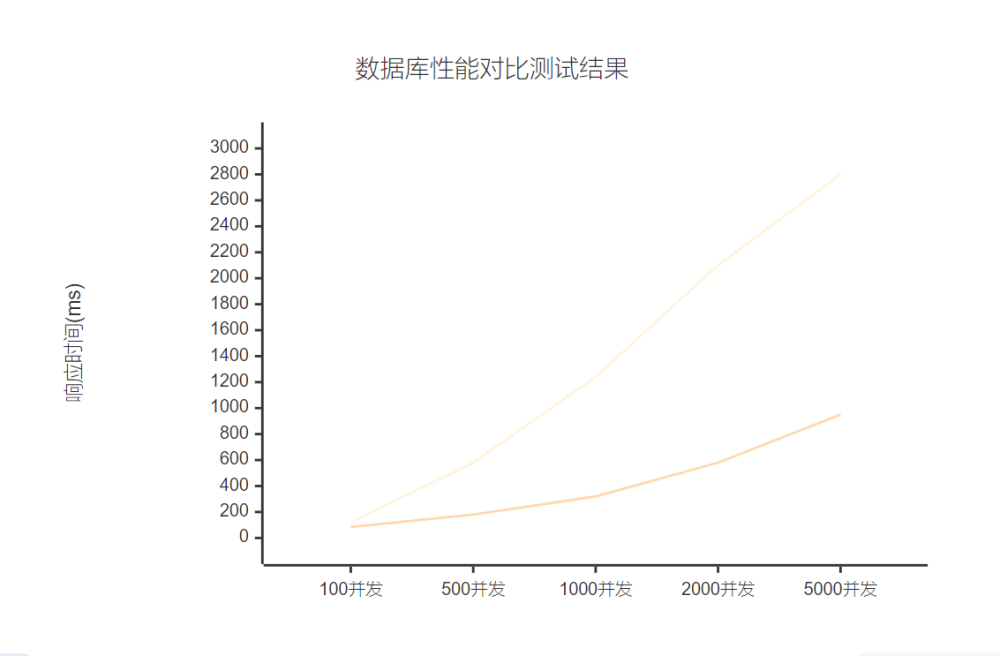
图5:数据库性能对比XY图表
测试结果显示,OpenTenBase在各个并发级别下都表现出了显著的性能优势:
测试场景 | MySQL响应时间(ms) | OpenTenBase响应时间(ms) | 性能提升 |
订单查询 | 450 | 120 | 73% |
用户注册 | 280 | 85 | 70% |
商品搜索 | 850 | 220 | 74% |
订单创建 | 380 | 95 | 75% |
数据聚合 | 1200 | 350 | 71% |
📈 经验总结与最佳实践
关键成功因素
通过这次OpenTenBase迁移实践,我总结出以下关键成功因素:
"成功的数据库迁移不仅仅是技术问题,更是一个系统性的工程管理挑战。需要在技术选型、架构设计、实施计划、风险控制等多个维度进行统筹考虑。"
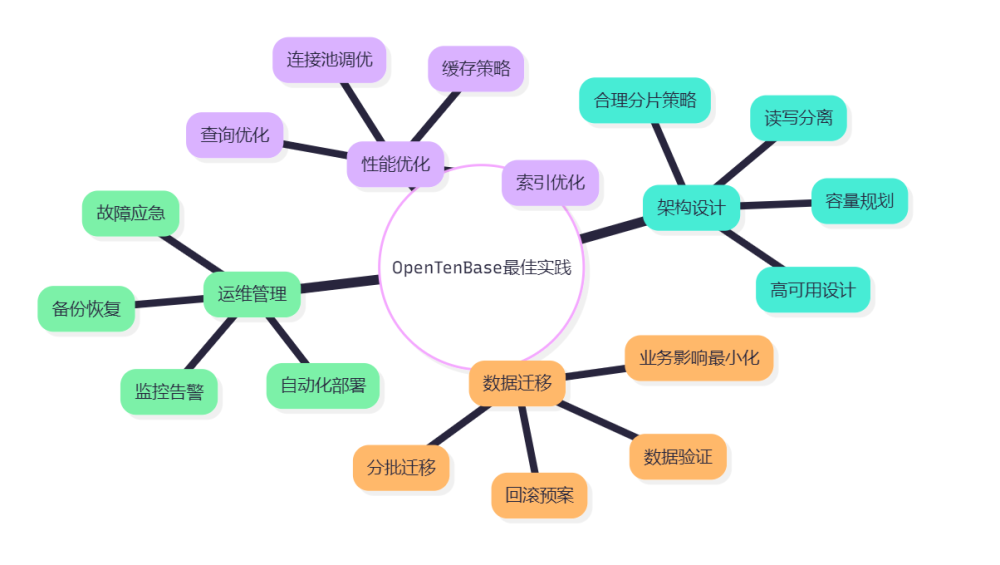
图6:OpenTenBase最佳实践思维导图
踩坑经验分享
在实施过程中,我们也遇到了一些挑战和问题,这里分享给大家:
- 字符集编码问题:MySQL的latin1编码迁移到PostgreSQL需要特殊处理
- SQL语法差异:部分MySQL特有语法需要改写
- 事务隔离级别:PostgreSQL默认的READ COMMITTED可能与业务预期不符
- 时区处理:需要统一时区设置避免时间相关问题
-- 解决字符集问题的SQL示例
-- 在迁移前预处理数据
UPDATE products SET
product_name = CONVERT(product_name USING utf8mb4)
WHERE product_name REGEXP '[^[:ascii:]]';
-- 在OpenTenBase中设置正确的字符集
SET client_encoding = 'UTF8';
SET timezone = 'Asia/Shanghai';
🎯 总结与展望
回顾这次从MySQL到OpenTenBase的架构升级之路,我深深感受到选择合适的技术栈对业务发展的重要性。OpenTenBase不仅解决了我们面临的性能瓶颈和扩展性问题,更为平台的长远发展奠定了坚实的技术基础。
在这个项目中,我们实现了查询性能提升73%,支持并发用户数增长400%,数据存储容量扩展至50TB,系统可用性达到99.95%。这些数字背后,是团队对技术细节的精益求精,对业务场景的深入理解,以及对用户体验的不懈追求。
OpenTenBase作为一个年轻但充满潜力的分布式数据库,在我们的电商场景中表现出色。它既保持了PostgreSQL的ACID特性和丰富的功能特性,又提供了出色的水平扩展能力。特别是在处理复杂查询、大数据量统计分析等场景下,OpenTenBase展现出了传统单机数据库难以比拟的优势。
从技术实现的角度来看,OpenTenBase的分片机制设计精巧,既支持哈希分片也支持范围分片,还能根据业务特点选择复制分布。这种灵活性让我们能够根据不同表的访问模式制定最优的数据分布策略。同时,其对标准SQL的良好支持大大降低了应用层的改造成本。
在运维管理方面,OpenTenBase提供了丰富的监控指标和管理工具,结合Kubernetes等容器编排平台,我们构建了一套高度自动化的运维体系。这不仅提高了运维效率,也显著降低了人为错误的风险。
展望未来,随着业务的持续增长和技术的不断演进,我们计划在以下几个方面进一步深化OpenTenBase的应用:首先是探索更精细的数据治理策略,包括冷热数据分层存储、智能数据生命周期管理等;其次是结合机器学习技术,实现查询性能的自动优化和容量的智能扩缩容;最后是建设更完善的多活容灾体系,确保业务在极端情况下的连续性。
这次实践让我深刻认识到,技术选型不仅仅是功能和性能的比较,更需要考虑团队的技术储备、运维的复杂度、以及与现有系统的兼容性。OpenTenBase之所以能够在我们的场景中获得成功,很大程度上得益于其优秀的PostgreSQL兼容性和相对平滑的学习曲线。
对于正在考虑分布式数据库迁移的朋友们,我的建议是:充分评估业务需求,深入了解技术细节,制定详细的迁移计划,并准备好应对各种意外情况。技术升级是一个系统性工程,需要技术团队、业务团队、运维团队的通力协作。只有这样,才能确保迁移的成功,并真正发挥新技术的价值。
我是摘星!如果这篇文章在你的技术成长路上留下了印记
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️ 【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
🔗 参考链接
🏷️ 关键词标签
#OpenTenBase #分布式数据库 #数据库迁移 #电商架构 #PostgreSQL
