




1、问题来源
在生产环境维护 Elasticsearch 集群的过程中,经常会遇到这样的场景:

业务需求变更导致某些字段不再使用,或者早期设计时添加了一些冗余字段,现在需要清理掉。
最近球友在公司的一个项目中就遇到了这个问题,用户行为分析索引中存在十几个历史遗留的字段,这些字段不仅占用存储空间,还影响查询性能。
传统的解决方案是通过重建索引(reindex)来实现字段删除,但对于有几十个索引、单个索引数据量达到百万级别的生产环境来说,重建索引的成本相当高昂。
数据迁移过程中不仅要考虑服务可用性,还要处理增量数据同步问题,整个过程可能需要数小时甚至更长时间。
在寻找更优雅解决方案的过程中,Elasticsearch 的设计哲学决定了 mapping 一旦创建就不能直接删除字段,这个限制让很多开发者感到困扰。
但经过深入研究、探讨和实践验证,找到了几种在不重建索引的情况下实现字段"删除"的方法。
2、分析问题
要理解为什么 Elasticsearch 不允许直接删除 mapping 中的字段,需要从其底层存储机制说起。
Elasticsearch 基于 Lucene 构建,Lucene 的段(Segment)设计是不可变的,这意味着已经写入的数据结构无法直接修改。
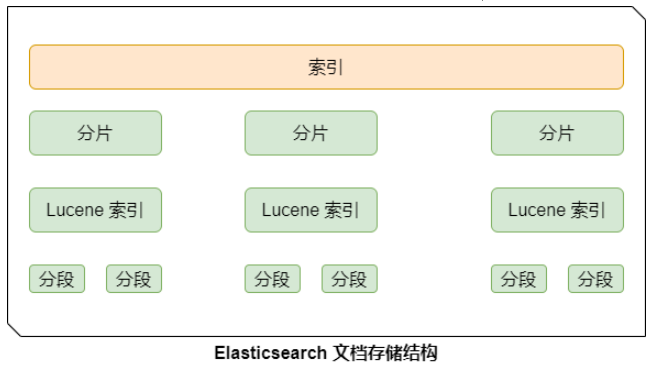
向索引中添加文档时,字段信息会被写入到段的元数据中,删除字段意味着要修改所有相关段的结构,这在技术上是不可行的。
从 Elasticsearch 的 mapping API 来看,可以添加新字段,也可以修改某些字段的属性(如增加新的分析器),但确实无法删除已存在的字段。这个设计虽然在某些场景下带来不便,但保证了数据的一致性和系统的稳定性。
在生产环境中,通常面临的场景包括:
首先是历史遗留字段清理,早期版本留下的无用字段占用存储空间;
其次是敏感数据删除,某些包含敏感信息的字段需要从索引中移除;
第三是性能优化,减少不必要的字段可以提升查询和存储性能;
最后是合规要求,某些行业规范要求定期清理特定类型的数据字段。
3、解决方案探讨
经过调研和实践,总结出了几种不重建索引就能实现字段"删除"的方法,每种方法都有其适用场景和局限性。
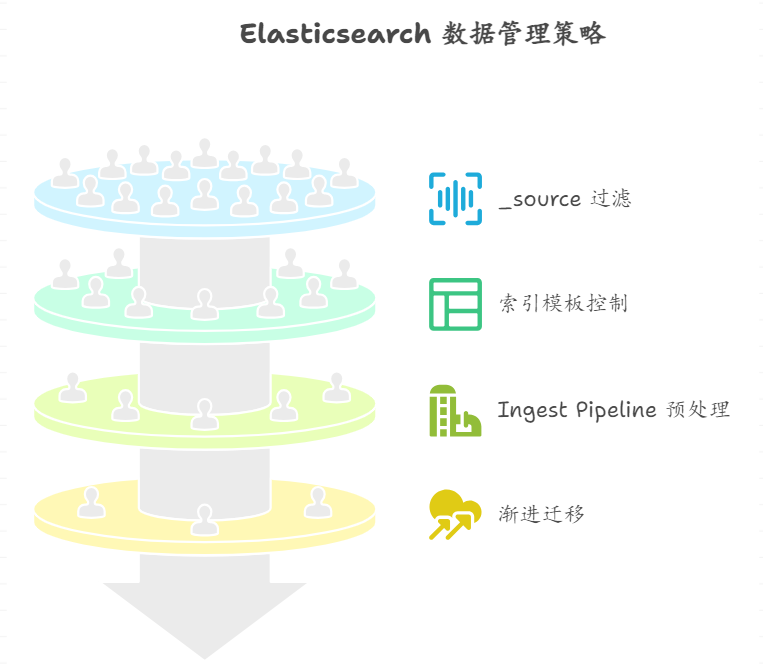
3.1 方案一:使用 _source 过滤实现逻辑删除
这是最简单也是最常用的方法。通过修改索引模板或者在查询时使用 _source 过滤,可以让特定字段在结果中不可见。
这种方法实际上并没有物理删除字段,而是在应用层面屏蔽了这些字段。
优点是实施简单,对现有数据无影响,可以随时恢复。
缺点是字段数据仍然存在,占用存储空间,对存储成本优化效果有限。这种方法适用于临时屏蔽字段或者测试环境。
3.2 方案二:通过 Index Template 控制新数据
对于持续写入的索引,我们可以通过修改索引模板来控制新文档不再包含特定字段(单独索引也可以实现)。
虽然历史数据中的字段仍然存在,但至少可以阻止问题继续恶化。
这种方法的优势在于操作安全,对现有数据无风险,适合滚动索引场景。劣势是只能控制新数据,历史数据问题依然存在,需要配合其他方案使用。
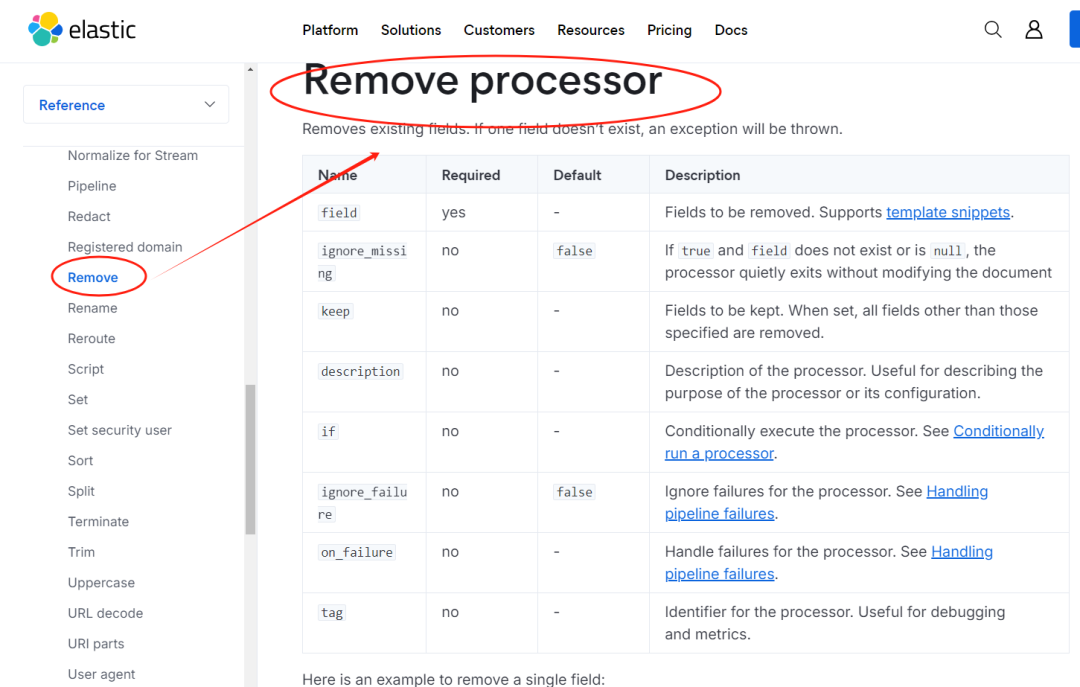
3.3 方案三:利用 Ingest Pipeline 预处理
在数据写入阶段使用 Ingest Pipeline 来删除不需要的字段,这种方法可以在源头解决问题。
通过配置 remove 处理器,可以在文档索引前就把指定字段移除(如下是官网截图)。
3.4 方案四:结合 alias 和新索引的渐进迁移
这是一种相对温和的迁移策略。创建新的索引(不包含需要删除的字段),然后通过别名逐步将流量切换到新索引。
这种方法可以实现零停机迁移,但需要一定的规划和协调。
4、解决问题实战
接下来展示具体的实施步骤。
假设我们有一个名为 user_behavior 的索引,需要删除其中的 deprecated_field 和 temp_data 字段。
针对第3部分讨论的内容,实战如下:
4.1 实战场景一:使用 _source 过滤实现逻辑删除
首先查看当前索引的 mapping 结构:
PUT user_behavior
{
"mappings": {
"properties": {
"user_id": { "type": "keyword" },
"action": { "type": "keyword" },
"timestamp": { "type": "date" },
"deprecated_field": { "type": "text" },
"temp_data": { "type": "object" }
}
}
}
POST _bulk
{ "index" : { "_index" : "user_behavior", "_id" : "1" } }{ "user_id": "U1001", "action": "login", "timestamp": "2025-08-21T08:00:00Z", "deprecated_field": "old_session", "temp_data": { "browser": "Chrome", "ip": "192.168.1.1" }}{ "index" : { "_index" : "user_behavior", "_id" : "2" } }{ "user_id": "U1002", "action": "purchase", "timestamp": "2025-08-21T08:05:00Z", "deprecated_field": "legacy_cart", "temp_data": { "items": 3, "amount": 49.99 }}{ "index" : { "_index" : "user_behavior", "_id" : "3" } }{ "user_id": "U1001", "action": "logout", "timestamp": "2025-08-21T08:10:00Z", "deprecated_field": "session_end", "temp_data": { "duration": 600 }}{ "index" : { "_index" : "user_behavior", "_id" : "4" } }{ "user_id": "U1003", "action": "view", "timestamp": "2025-08-21T08:15:00Z", "deprecated_field": "page_load", "temp_data": { "page": "product", "load_time": 1.2 }}{ "index" : { "_index" : "user_behavior", "_id" : "5" } }{ "user_id": "U1002", "action": "search", "timestamp": "2025-08-21T08:20:00Z", "deprecated_field": "query_log", "temp_data": { "keyword": "laptop", "results": 15 }}
GET user_behavior/_mapping
假设返回的结果包含我们要删除的字段:
{
"user_behavior": {
"mappings": {
"properties": {
"user_id": {"type": "keyword"},
"action": {"type": "keyword"},
"timestamp": {"type": "date"},
"deprecated_field": {"type": "text"},
"temp_data": {"type": "object"}
}
}
}
}
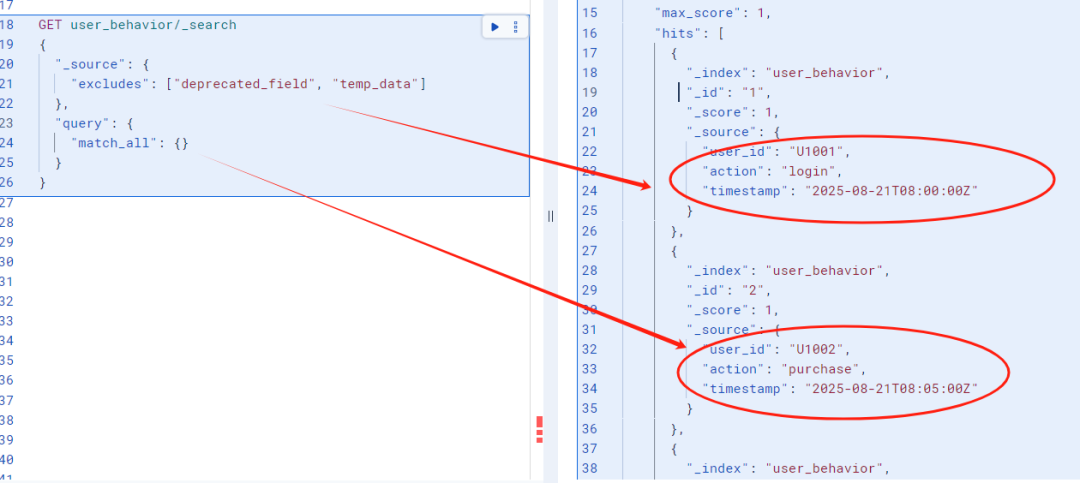
在应用层面实现字段过滤,通过查询时指定 _source 参数:
GET user_behavior/_search
{
"_source": {
"excludes": ["deprecated_field", "temp_data"]
},
"query": {
"match_all": {}
}
}
如果希望在索引级别设置默认的 _source 过滤,可以通过 settings 配置。
4.2 实战场景二:通过 Ingest Pipeline 预处理新数据
创建一个用于移除指定字段的 Ingest Pipeline:
PUT _ingest/pipeline/remove_fields_pipeline
{
"description": "Remove deprecated fields from documents",
"processors": [
{
"remove": {
"field": "deprecated_field",
"ignore_missing": true
}
},
{
"remove": {
"field": "temp_data",
"ignore_missing": true
}
}
]
}
测试 Pipeline 是否正常工作:
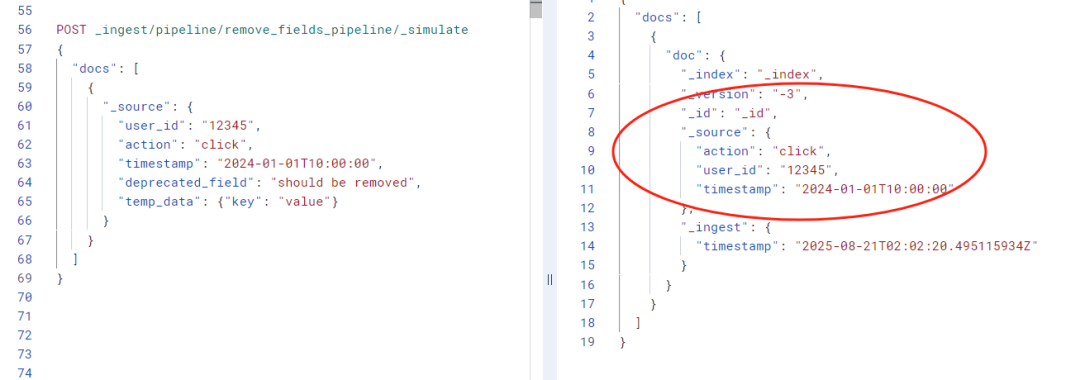
POST _ingest/pipeline/remove_fields_pipeline/_simulate
{
"docs": [
{
"_source": {
"user_id": "12345",
"action": "click",
"timestamp": "2024-01-01T10:00:00",
"deprecated_field": "should be removed",
"temp_data": {"key": "value"}
}
}
]
}
将 Pipeline 应用到索引的默认处理流程:
PUT user_behavior/_settings
{
"index.default_pipeline": "remove_fields_pipeline"
}
POST user_behavior/_doc/6
{
"user_id": "U1006",
"action": "search",
"timestamp": "2025-08-21T08:20:00Z",
"deprecated_field": "query_log",
"temp_data": {
"keyword": "laptop",
"results": 15
}
}
GET user_behavior/_doc/6
PUT user_behavior/_settings
{
"index": {
"default_pipeline": "remove_fields_pipeline"
}
}

4.3 实战场景三:基于别名的渐进迁移策略
首先创建一个新的索引,mapping 中不包含需要删除的字段:
PUT user_behavior_v2
{
"mappings": {
"properties": {
"user_id": {"type": "keyword"},
"action": {"type": "keyword"},
"timestamp": {"type": "date"}
}
}
}
创建别名指向原索引:
POST _aliases
{
"actions": [
{
"add": {
"index": "user_behavior",
"alias": "user_behavior_alias"
}
}
]
}
使用 reindex API 将数据迁移到新索引,同时过滤掉不需要的字段:
POST _reindex
{
"source": {
"index": "user_behavior",
"_source": {
"excludes": ["deprecated_field", "temp_data"]
}
},
"dest": {
"index": "user_behavior_v2"
}
}
监控迁移进度:
GET _tasks?detailed=true&actions=*reindex
迁移完成后,切换别名指向新索引:
POST _aliases
{
"actions": [
{
"remove": {
"index": "user_behavior",
"alias": "user_behavior_alias"
}
},
{
"add": {
"index": "user_behavior_v2",
"alias": "user_behavior_alias"
}
}
]
}
4.4 实战场景四:处理持续写入的索引
对于需要持续写入数据的场景,可以使用滚动索引策略。首先修改索引模板:
PUT _index_template/user_behavior_template
{
"index_patterns": ["user_behavior-*"],
"template": {
"mappings": {
"properties": {
"user_id": {"type": "keyword"},
"action": {"type": "keyword"},
"timestamp": {"type": "date"}
}
},
"settings": {
"index.default_pipeline": "remove_fields_pipeline"
}
}
}
配置 ILM 策略实现自动滚动:
PUT _ilm/policy/user_behavior_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "30d",
"max_size": "50gb"
}
}
}
}
}
}
5、方案对比与选择
在实际项目中,不同场景需要选择不同的方案。对于开发和测试环境,推荐使用 _source 过滤方案,操作简单且风险低。
对于生产环境中的小规模索引(数据量在 GB 级别),可以考虑使用别名切换的方式进行一次性迁移。
对于大规模生产环境,建议采用 Ingest Pipeline + 滚动索引的组合方案。这种方式虽然不能立即清理历史数据,但可以确保新数据不再包含不需要的字段,同时通过 ILM 策略逐步淘汰旧数据。
在存储成本敏感的场景下,如果历史数据中不需要的字段占用空间很大,还是建议在业务低峰期执行 reindex 操作。可以通过设置合适的 batch size 和 requests_per_second 参数来控制迁移速度,减少对业务的影响。
6、小结
通过实际项目的实践发现虽然 Elasticsearch 不支持直接删除 mapping 字段,但通过合理的设计和实施策略,完全可以实现字段的"逻辑删除"。
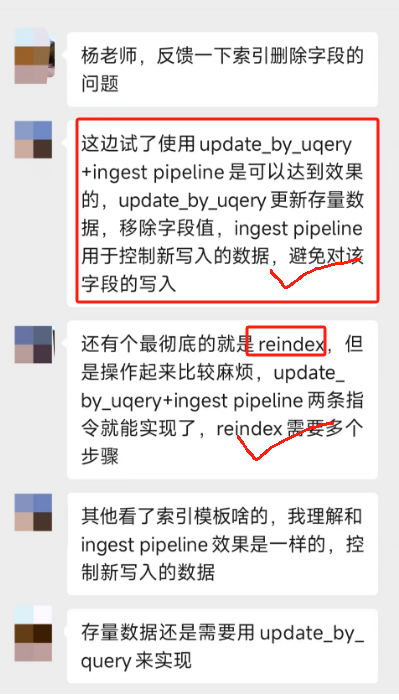
在球友项目中,最终采用了 Ingest Pipeline + update_by_query修改的组合方案,解决了开篇提到的问题。
更多推荐:
Elasticsearch 8.X 防止 Mapping “爆炸”的三种方案 【视频】系统学习 Elastic Stack 技术栈,请先看这一套视频(基础篇01-10) 【视频】系统学习 Elastic Stack 技术栈,请先看这一套视频(进阶篇11-17) 【视频】系统学习 Elastic Stack 技术栈,请先看这一套视频(实战篇18-21) 
更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!
