




本文复盘一次真实的线上排查:Bulk API 返回成功、Count 显示有文档,但 Search/Get 拿不到
_source
。Trae Cursor 辅助调试 6 小时,从 200 行膨胀到 800 行,最终根因只有一行配置。写给后来的开发者和 AI,少踩同样的坑。
一、现象:一切看起来都正常,唯独查不到数据
1.1 诡异的现象
Bulk API 返回: (10, [])
—— 成功写入 10 条,失败 0 条Count API 返回: count: 10
—— 索引里确实有 10 条文档Search API 返回: hits[]._source
全是空对象{}Get API 返回: _source
为null
或不存在
没有报错,没有异常,唯独拿不到文档内容。


就像「人到了考场,卷子交了上去,系统显示交卷成功,但老师查不到卷子内容」。
1.2 业务影响
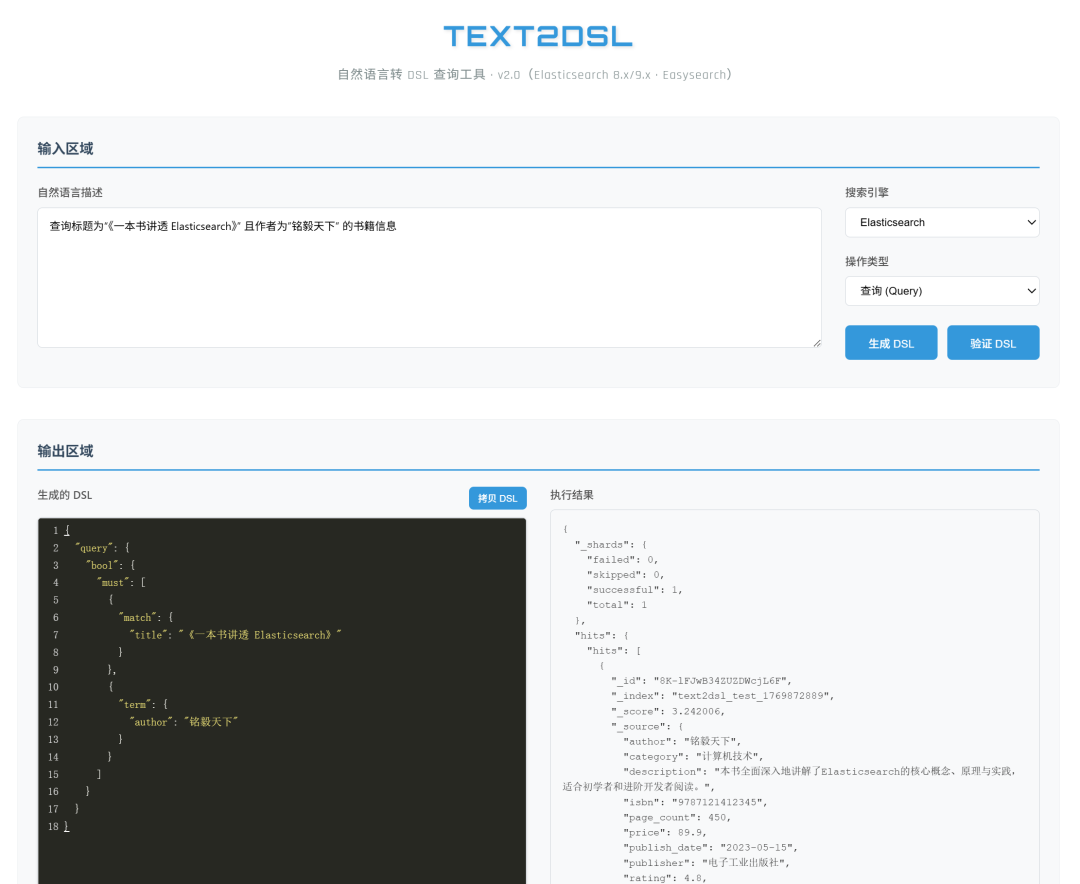
自然语言转 DSL 的验证链路:先写测试数据 → 再执行 DSL → 校验结果 数据「写进去」了却查不到,导致后续 DSL 校验始终失败 用户反复重试,以为是网络、权限或 API 调用问题 
二、弯路:AI 如何越陷越深
2.1 第一反应:Bulk 格式有问题?
假设:action 格式不对,ES 没有正确解析。
尝试:
从 { "index": {}, "doc": {...} }
改成{ "_index": "xxx", "_source": {...} }显式加 _type: "_doc"
(7.x 已废弃仍试过)调整 chunk_size
、refresh
、request_timeout
结果:Bulk 依然返回成功,Count 依然正确,Search 依然空。
教训:Bulk 本身没问题时,不要死磕格式,容易陷入「格式玄学」。
2.2 第二反应:Refresh 时机问题?
假设:数据还没 refresh,所以搜不到。
尝试:
refresh='wait_for'
或refresh=True写入后 indices.refresh()time.sleep(2)
、time.sleep(3)
再查
结果:依然拿不到 _source
。Count 能查到,说明文档已可搜索,不是 refresh 问题。
教训:Count 能查到而 Search 拿不到 _source
,问题大概率不在 refresh。
2.3 第三反应:ES 版本 API 兼容?
假设:7.x 和 8.x/9.x 的 bulk、index API 有差异。
尝试:
index(..., document=doc)
与index(..., body=doc)
双写兼容按版本分支,7.x 走一套逻辑,8.x 走另一套
结果:依然无效。
教训:API 兼容可以顺带做,但别把它当根因,否则逻辑会越来越复杂。
2.4 第四反应:Bulk 不靠谱,改用逐条 Index?
假设:Bulk 有某种「静默失败」,单条 index 更可控。
尝试:
遍历数据,逐条调用 client.index()每条都做一次验证 加上异常重试、日志
结果:单条 index 也一样——返回成功,Count 有,_source
仍然空。
教训:写入路径没问题时,换一种写入方式不会解决根本问题。
2.5 第五反应:验证逻辑不够细?
假设:可能是查询方式有问题,不是写入问题。
尝试:
Search 查不到就再用 Get 查 对每条文档做 Get 校验 增加大量 print
、日志、错误分支
结果:Get 也拿不到 _source
。验证越细,越证明「文档存在但无内容」。
教训:验证可以帮你确认现象,但不会自动指向根因。需要结合 ES 机制理解「文档存在 + 无 _source」代表什么。
2.6 代码膨胀
最初:约 200 行,一次 bulk + 简单校验 最终:约 800 行,包含: 多种 bulk 格式 多种 index 调用方式 Refresh sleep 等时序逻辑 逐条 index 兜底 Search + Get 双重验证 大量日志和分支
本质:在「写入路径」上反复加码,而根因在「索引配置」。
三、根因:_source.enabled=false
3.1 真正的原因
索引的 mapping 里把 _source
关掉了:
{
"mappings": {
"_source": { "enabled": false },
"properties": { ... }
}
}
含义很简单:
文档会被正常索引、建倒排、参与搜索 Count 能看到文档数 Bulk Index 都会返回成功 但原始 JSON 不存储,所以 Search Get 拿不到 _source
这正好解释了:写成功、Count 正常、Search/Get 无内容。
3.2 为什么会出现 _source.enabled=false
?
常见来源:
LLM 生成的 mapping:按 ES 文档示例生成,有时会带上 _source.enabled: false
(用于只搜不取场景)复制粘贴模板:日志、监控等场景的模板,为省存储会关闭 _source默认模板:某些内部模板或旧版本默认值可能关掉 _source
3.3 正确修复方式
在创建索引时,显式保证 _source
开启:
def create_index(self, index_name, mapping=None):
if mapping:
mappings_body = dict(mapping.get('mappings', mapping))
# 核心:强制启用 _source
mappings_body['_source'] = {'enabled': True}
self.client.indices.create(index=index_name, body={'mappings': mappings_body})
else:
self.client.indices.create(index=index_name)
核心只有一行:mappings_body['_source'] = {'enabled': True}
,在 mapping 里覆盖掉 enabled: false
。
四、给后来人的经验
4.1 现象与根因对照
| Bulk 成功,Count>0,_source 为空 | 索引 mapping 中 _source.enabled=false |
看到「写成功 + 能 count + 无 _source」,优先查 mapping 里的 _source
配置。
4.2 排查清单(按优先级)
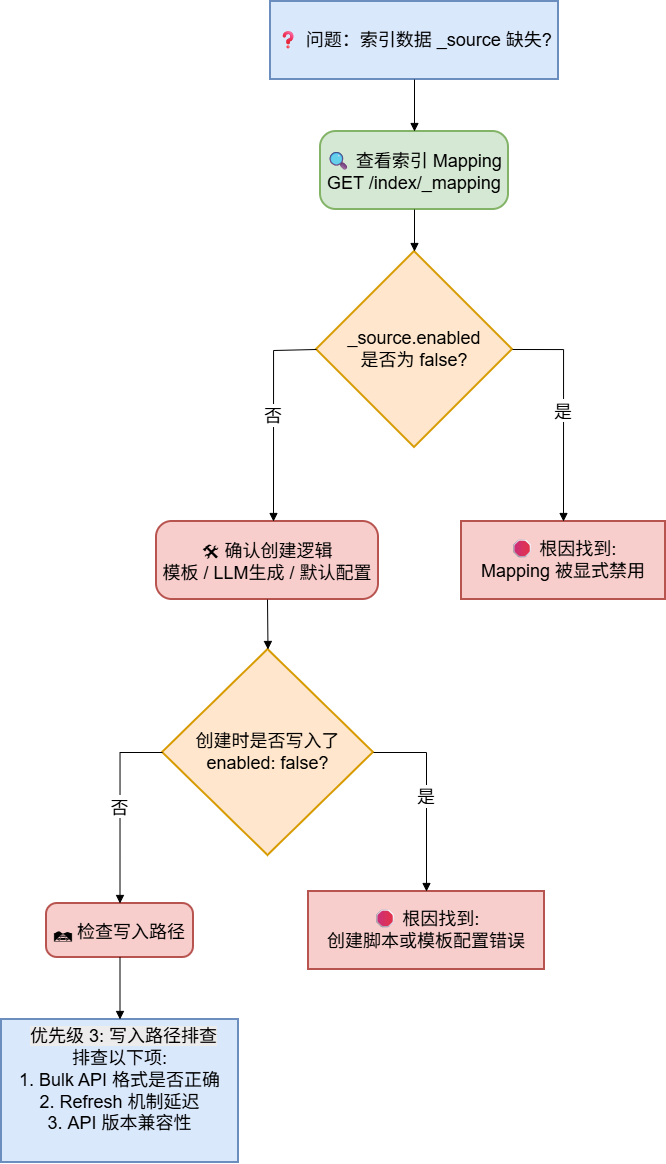
查看索引 mapping
GET /your_index/_mapping
,检查_source.enabled
是否为false
。确认索引创建逻辑
是否有地方在创建索引时写入了_source.enabled: false
(包括 LLM 生成、模板、默认配置)。再考虑写入路径
Bulk 格式、refresh、API 版本等,放在 mapping 排查之后。
4.3 给 AI 调试的建议
先做「假设排除」
Count 正常 → 基本排除 refresh、分片分配等问题 Get 也拿不到 _source → 基本排除 Search 查询写法问题 此时应优先怀疑索引元数据 / mapping,而不是继续在写入逻辑上堆代码 控制改动的 scope
不要无限加 fallback、验证、重试 每加一种方案,先想清楚:它是在验证假设,还是在盲目试错 善用官方诊断 API
GET /index/_mappingGET /index/_settingsGET /index/_doc/某id
看完整响应回归简洁
根因修好后,删掉为「弯路」加的大量分支和兼容逻辑 保留必要日志和校验即可
五、总结
现象:Bulk 成功、Count 有、Search/Get 的 _source
为空根因:索引 mapping 中 _source.enabled=false修复:创建索引时强制 _source: { enabled: true }弯路:在 bulk 格式、refresh、API 兼容、逐条写入、复杂验证上反复加码,从 200 行膨胀到 800 行
一句话:文档能被 count 却拿不到内容,先看 mapping 里的 _source
,再考虑写入和查询。
反过来看,如果自己写代码,大概率不会有今天的文章。但是现在 AI 赋能的“黑盒编程”时代,反而会引发这样、那样的 N 多问题。
代码再多,自己可控才是关键!

复盘于 Text2DSL v2.0 开发过程,与君共勉。
Text2DSL v2.0完整代码:https://t.zsxq.com/n2LB9

更短时间更快习得更多干货!
和全球 2100+ Elastic 爱好者一起精进!

