




本文是一个在 Elasticsearch 集群管理中非常经典的“元数据管理”需求引发的思考和梳理。
很多 DBA 和 ES 运维人员都希望像查 MySQL binlog 一样查ES的写入时间,但 ES 的底层存储机制(倒排索引、Doc Values)决定了它没有“自动记录写入时间”的内置字段。
很多刚接触ES的朋友都会问:“MySQL有create_time
,ES能不能自动记录每条数据是什么时候写入的?”


一、为什么 ES 默认没有“写入时间”字段?
ES是近实时搜索引擎,数据写入后生成_id
和版本号,但不会自动添加时间戳。
如果要追溯,必须在数据摄入(ingest)阶段主动加上。
二、3种实现方案对比
方案一:Ingest Pipeline(生产标准,推荐⭐⭐⭐⭐⭐)
ES 提供内置的Ingest节点,可以在数据索引前进行加工。
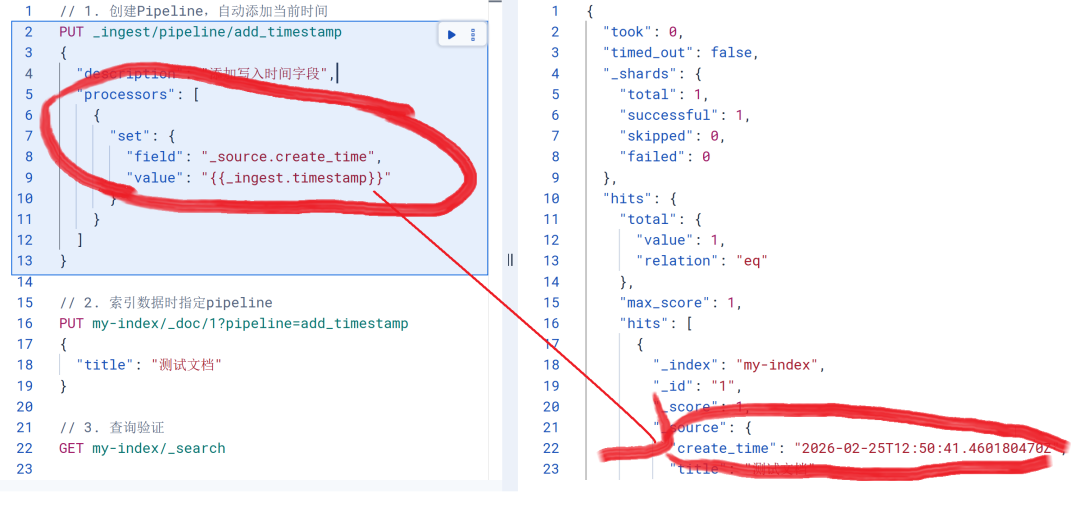
// 1. 创建Pipeline,自动添加当前时间
PUT _ingest/pipeline/add_timestamp
{
"description": "添加写入时间字段",
"processors": [
{
"set": {
"field": "_source.create_time",
"value": "{{_ingest.timestamp}}"
}
}
]
}
// 2. 索引数据时指定pipeline
PUT my-index/_doc/1?pipeline=add_timestamp
{
"title": "测试文档"
}
// 3. 查询验证
GET my-index/_search
优点:无需修改代码,统一管控;时间精确到毫秒。
注意:字段名建议用
create_time
,避免与 ES 内部@timestamp
混淆。
方案二:Logstash/Beats摄入(数据源侧方案)
如果通过Logstash同步数据,可以在配置文件中添加:
filter {
mutate {
add_field => { "write_time" => "%{[@timestamp]}" }
}
}
适用场景:日志类、从消息队列消费的数据。
方案三:应用侧写入(程序硬编码)
在Java/Go/Python客户端中,生成数据时手动添加create_time: new Date()
。
缺点:强依赖业务代码,多应用接入容易遗漏,导致时间不统一。
三、关于“历史数据”的写入时间追溯问题
正如球友截图提问:“历史的没办法知道了吧?”
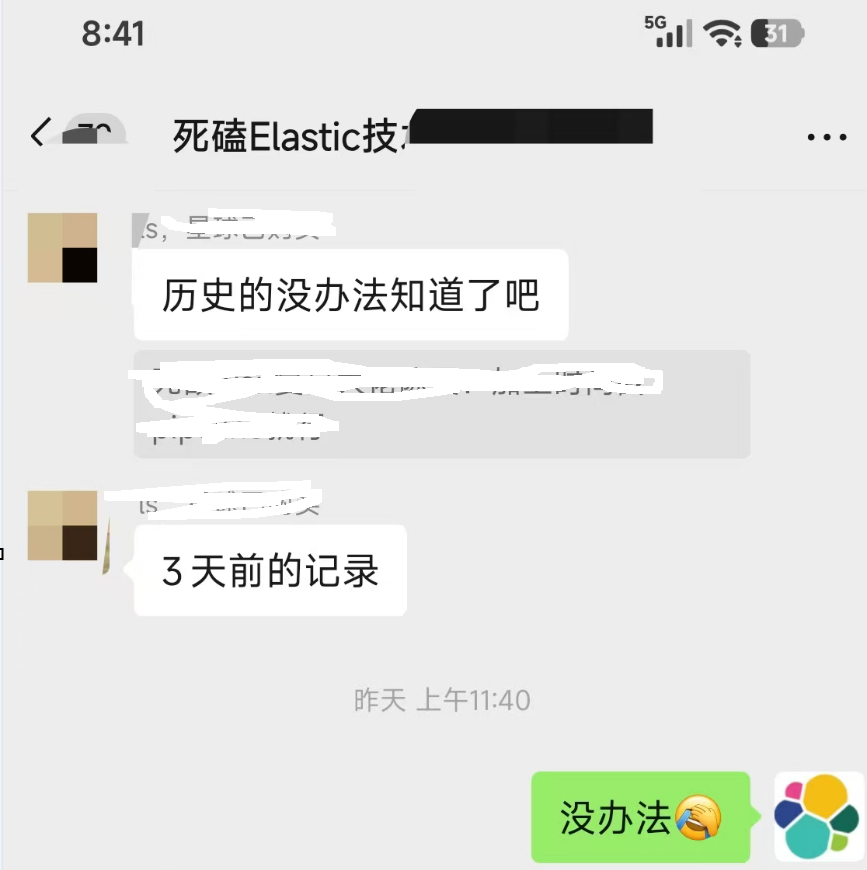
是的,历史数据无法追溯,除非:
上游数据源(如 MySQL、Kafka 消息)本身带时间戳;
通过日志或审计插件(如ES Auditbeat)辅助定位。
四、总结
立即需求实现
建 Pipeline,跑起来。
长期规划
所有索引强制使用统一 Pipeline,或索引模板中预置时间字段。
你的ES数据,现在有时间戳了吗?
欢迎留言交流。

更短时间更快习得更多干货!
和全球 2100+ Elastic 爱好者一起精进!

文章转载自铭毅天下Elasticsearch,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
