





搜索引擎技术在房多多的应用场景
现在有个比较热的术语叫”产业互联网”,房多多在房地产服务行业用互联网技术提高行业服务和交易效率的探索已经多个年头。从技术的角度看,这个过程中一些比较深刻的体会如:
行业产业链条比较长,参与的用户角色比较多,因此多产品多用户的协同效率要求高;
用互联网技术改造传统行业,需要从技术层面真正提高用户的体验,也就是每个产品功能节点的SLA (Service Level Agreement) 要有高要求,真正提高用户效率。
下图举例几个实际前后台产品的搜索和复杂查询场景:
C端用户产品为用户提供多场景的楼盘、房源、最新动态等海量信息的搜索查询服务;
经纪用户产品为经纪人提供更多复杂作业场景的楼盘、房源、咨询、线上访客等信息的检索和查询服务;
各中后台运营类产品的信息检索场景更加复杂,检索条件多,关联数据广,数据量大。
这里就从比较常见的技术场景出发,讲讲房多多利用 Elasticsearch 提高各产品的用户在信息搜索、复杂查询方面的性能和效率方面的平台化工作。
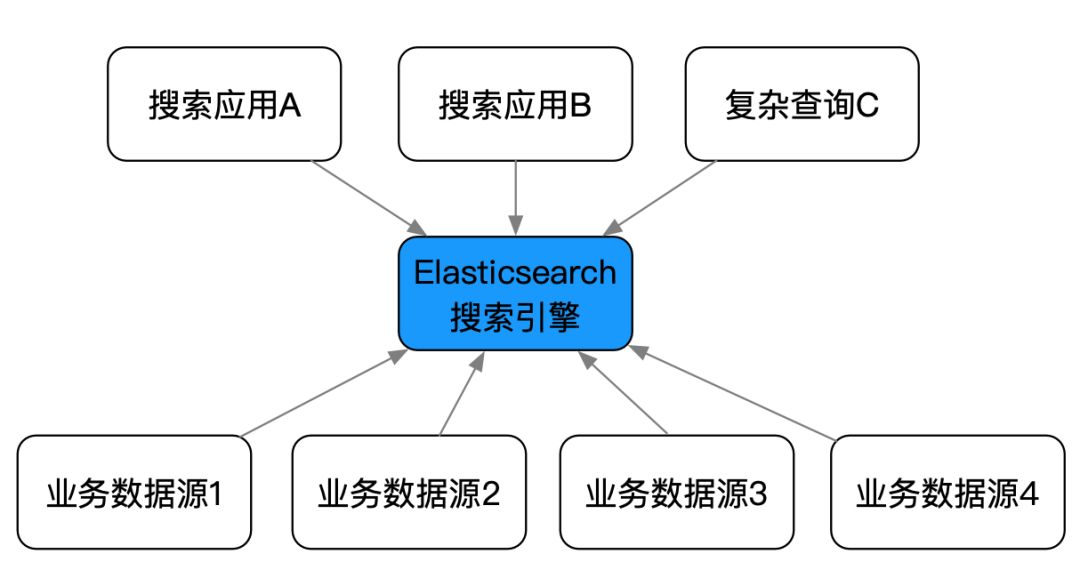
除了明确的搜索业务场景,在技术架构层面,利用 Elasticsearch 可以非常好地把复杂查询场景从基本业务逻辑的微服务中剥离出来,既实现更高的性能,又降低微服务的复杂度和数据库设计的复杂度。如下图举例我们在新房订单交易业务领域,将订单的基本业务逻辑和复杂查询场景从存储和服务上分离,实现更简洁和高性能的架构。
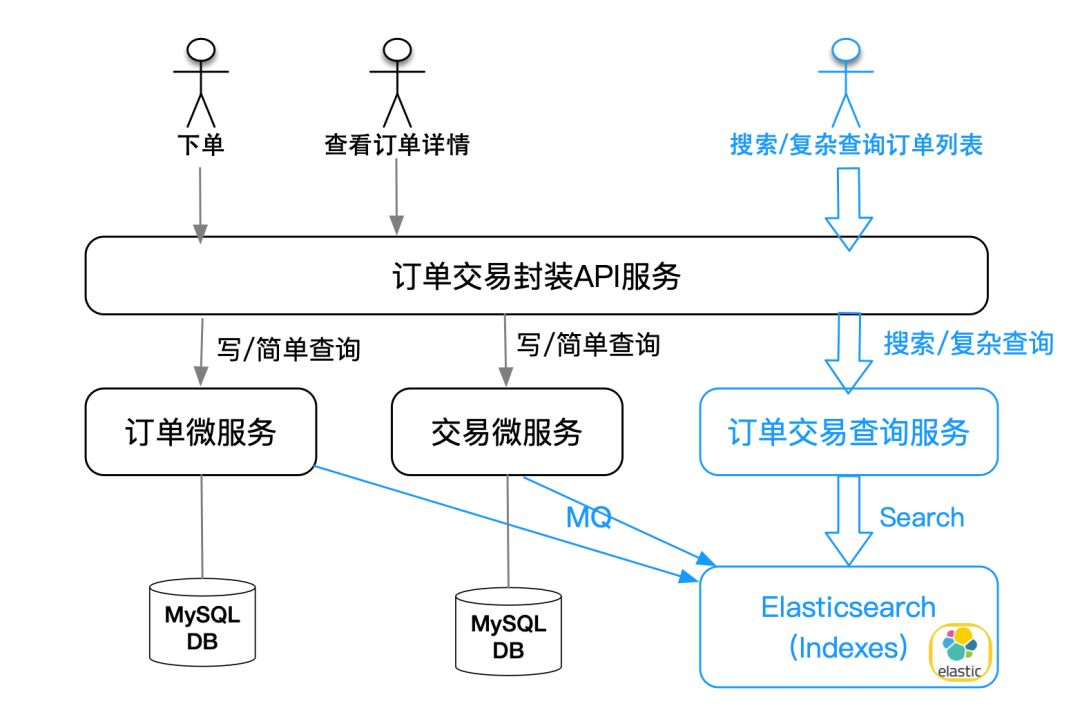
上图中,我们实现基本业务逻辑的微服务有订单微服务和交易微服务(这里为了简洁省略了其他业务细节的服务),当产生订单、交易支付和订单流转的时候,这两个微服务基本可以实现所有的写订单、写交易流水和详情查询服务,这些服务的数据都存储在 MySQL 相应的数据模型中。但如果我们要应对复杂的查询,甚至某些查询要关联多个微服务中的数据的时候,如果不采用上图方案,就要设计更复杂的数据模型、数据库索引和代码逻辑来实现,甚至跨服务数据冗余。这时候,我们就要单独构建一个查询服务,将查询服务需要检索的索引数据,通过 MQ 从各其他服务异步实时同步到 Elasticsearch 建立索引,进而对外提供服务。类似这种技术场景的架构在系统中非常常见且能非常好地解决问题,让我们的微服务架构越来越简洁稳健。
实际使用中面临的问题
随着业务的发展,搜索需求在业务中的比重越来越大,索引个数越来越多,覆盖的产品线和开发团队也越来越多。多个产品开发团队根据需要建立了各自的 Elasticsearch 集群应对产品的需要。这时候就出现了下列问题:
多套 Elasticsearch 占用了更多的服务器资源,各业务的数据量和搜索流量不同,不能共享资源,造成一定的浪费;
业务开发团队忙于业务开发,没有太多时间运维和优化集群,无法保障搜索服务的高可用性;
有很多业务场景实际上需要有搜索引擎支撑,但因为搭建和接入 Elasticsearch 需要一定的学习成本和资源成本,因此就会暂时忍受,这提高了现有服务的数据模型和代码逻辑的复杂性,对架构发展不利。
为了提高开发效率,降低使用门槛,规范搜索引擎的使用,我们把一些共性的问题抽取出来统一处理,让各个需要搜索服务的业务应用只关注业务逻辑本身,无需过多考虑搜索基础技术。现阶段我们简单地抽象出搜索的共性问题如下:
创建索引、更新索引;
全量或批量重建索引;
索引查询;
索引查询时的身份认证,权限控制,监控等;
平台的维护管理。
搜索引擎平台化的简单设计
下图为我们设计的一个简单的平台化搜索服务架构:
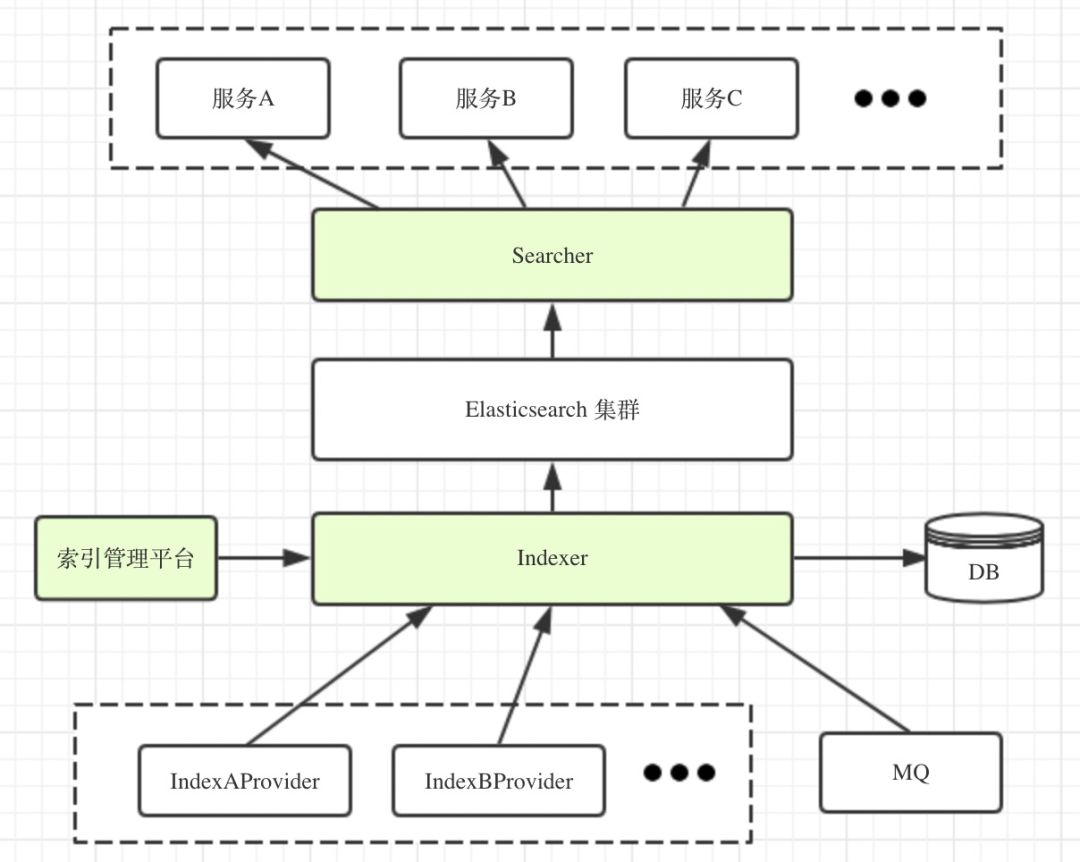
基本的设计思路
上图基本的设计思路是,把创建索引和查询索引分离,用 Searcher 和 Indexer 两个服务对 Elasticsearch 进行封装,其他服务对 Elasticsearch 的建索引和检索操作都通过这两个服务来实现。其中:
Indexer 提供创建索引、增量更新和全量重建等功能;
Searcher 提供查询索引数据的接口,同时会进行身份校验,权限认证和监控等;
索引管理平台用于索引的配置和管理,这是个可视化的Web界面。
索引的创建
我们把索引创建的问题抽象成几个子问题:
索引数据的范围;
如何获取索引数据并写到索引;
数据更新时,如何同步更新索引里的数据。
针对这几个问题,我们在Indexer服务中定义了一个服务接口 IndexInfoProvider,其中:
getMinId 和 getMaxId 用于获取索引数据的范围;
getDocsByIdRange 用于获取某个 id 区间内的索引数据并写入索引;
getDocsByIds 用于获取某些 id 的索引数据并更新索引。
public interface IndexInfoProvider {/*** 该索引文档的最小id* @return*/public long getMinId();/*** 该索引内文档的最大id* @return*/public long getMaxId();/*** 获取文档id 在[start, end) 之间的所有索引文档* @param start* @param end* @return*/public List<IndexDocument> getDocsByIdRange(long start, long end);/*** 获得文档ids 的所有索引文档* @param ids* @return*/public List<IndexDocument> getDocsByIds(List<Long> ids);}
索引数据的提供方实现 IndexInfoProvider 接口,并对外提供 Dubbo 服务的 provider,用 Dubbo 中的 group 属性对索引进行分组,保证不同索引属于不同的组,例如:
<dubbo:service group="amc_port" ref="amcPortIndexInfoProvider" interface="com.fangdd.searchplatform.indexer.protocol.IndexInfoProvider" version="1.0.0"/>
接着,索引创建者需要在“索引管理平台”配置新增一个索引,如下图所示。其中“重建时间”是每天全量重建索引的时间,mapping 是索引字段类型的映射关系。新增好索引后,Indexer 能够感知到新增的索引,并用 dubbo reference API 自动注册一个 xxxPortIndexInfoProvider 的 dubbo 消费者。
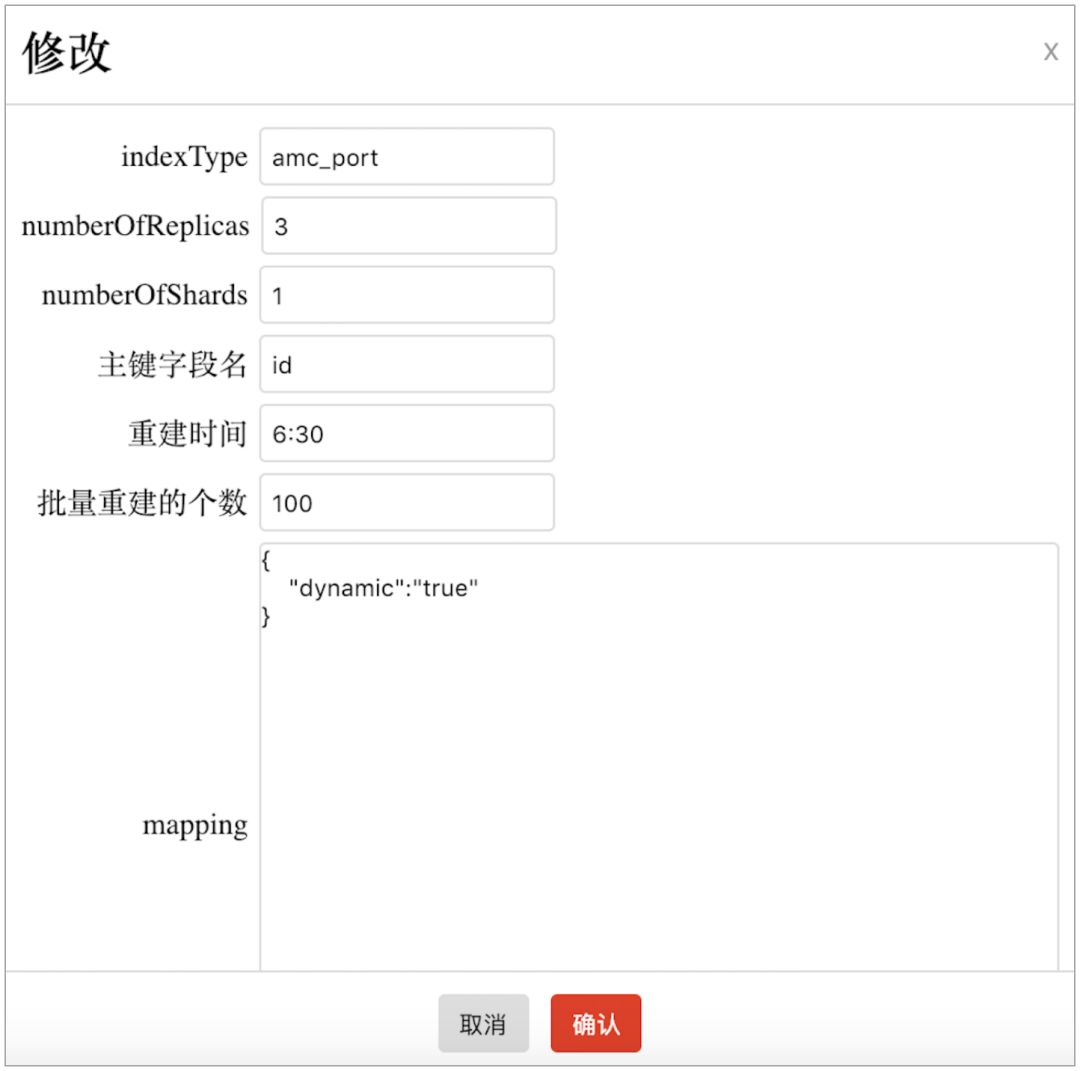
最后,通过“索引管理平台”触发索引的重建,这样就完成新索引的创建。索引的创建者无需了解 Elasticsearch 索引创建的过程和接口,只需实现 IndexInfoProvider 并完成相应配置即可新建一个索引。
全量重建索引
Indexer 全量重建索引的时序图如下:
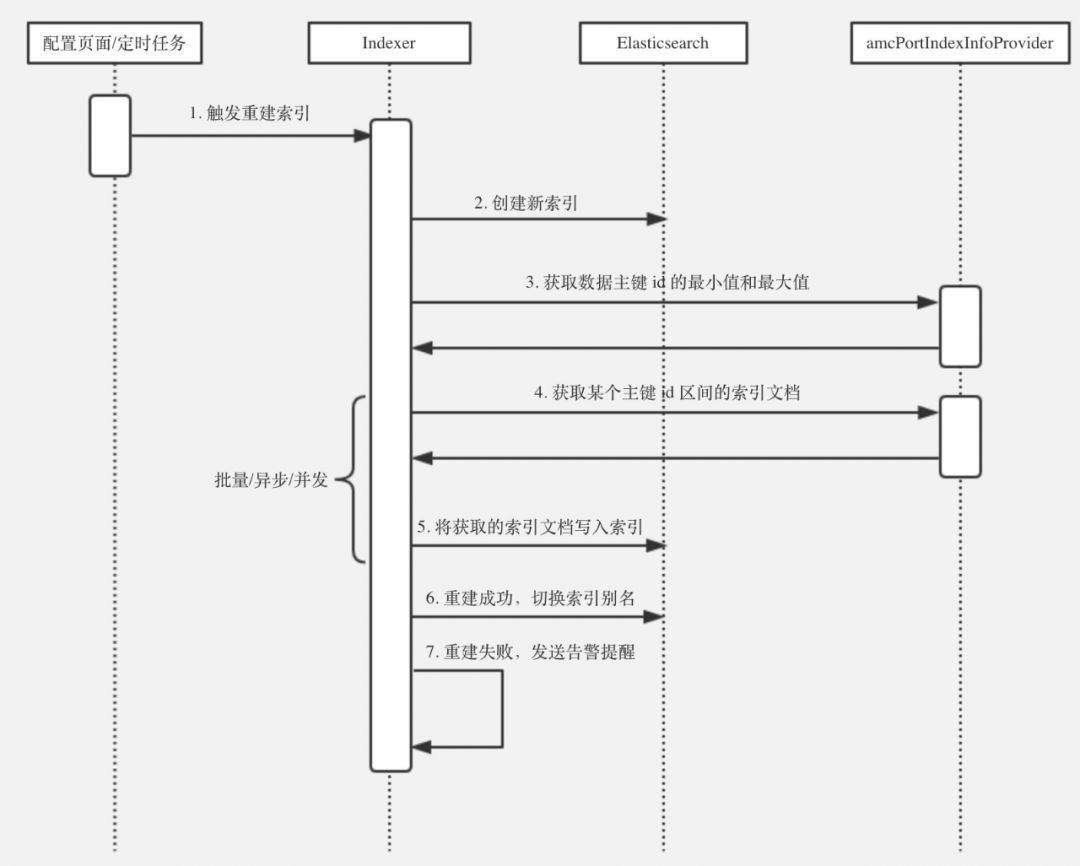
在上图的4-5步,把主键 id 区间 [min, max] 按照固定步长(步长在“索引管理平台”里定义),分成多个主键 id 区间,如 [min, min+x], [min+x+1, min+2x], ... , [y, max],然后调用 IndexInfoProvider 中的 getDocsByIdRange 方法获得索引的文档,并写入新创建的索引中。
增量更新索引
当业务数据变更时,需要更新索引里的数据。数据更新方将需要更新的索引名称和主键 id 列表发送到消息队列,Indexer 从消息队列中消费这条消息,并通过 IndexInfoProvider 中的 getDocsByIds 方法来获取新的文档数据,并更新到 Elasticsearch。这种通过 MQ 消息机制基本可实现准实时的索引增量更新,对大多数查询场景都可以满足要求。
索引的查询
每个应用服务需要查询 Elasticsearch 的时候,都需要申请应用 appId 和 appKey,用于身份认证。每次通过 Searcher 查询时,先校验身份和权限。然后把调用方、调用的接口、调用的索引等信息打点记录到监控服务。这样我们可以区分哪些索引被查的次数比较多,哪个服务查询的次数比较多,哪些索引已经没有使用等,后续还可以进一步增加限流等功能。
Searcher 提供了几种索引查询的接口:
对 Elasticsearch 查询请求进行封装,支持大多数查询场景,比如筛选、模糊匹配、聚合等;
支持 Elasticsearch HTTP 查询接口;
支持 Elasticsearch Java API 查询接口。
未完的计划
目前这个架构和实现还是个满足于当下基本要求的基本版本,还有更进一步的问题需要解决:
上述设计的代码假设 doc 的 id 都是自增连续的 id,这不满足某些实际场景,我们需要进一步抽象出新的增量接口;
Elasticsearch 的功能非常强大,查询接口也非常灵活,某些复杂的大负载请求,例如大数据量的聚合请求,会消耗大量的集群资源,影响其他服务的服务性能和可用性。因此我们还需要进一步考虑业务的隔离和如何限制大负载请求;
在查询请求接口上,我们还需要有实时监控反馈和限流能力;
集群的运维和优化是个长期的工作,需要有更好的维护和优化工具。
实际的部署
考虑到不同的业务面对的用户群体和业务行为特性的不同,我们实际上基于业务场景的不同特点部署多套 Elasticsearch。例如:
针对 toC 和 toB 两类用户的用户群体规模和开放性/封闭性的不同特点,从物理上隔离 Elasticsearch,避免业务的影响。toC 用户量大且完全公开,有时候甚至还会受到流量攻击;toB 是类似 SaaS 的体系,面向企业用户,用户量级和开放性都比 toC 小若干数量级,但索引的复杂性以及对服务的 SLA 要求非常高,特别是对付费用户的 SLA 要有极高的保障;
和业务应用的“写少读多”特点不同,开发和运维层面的日志监控系统 (ELK) 的特点是是“写多读少”,且一般只关注和查询近期的日志,但数据量巨大,因此这种集群有不同的存储策略 (如冷热数据、淘汰机制) 和查询策略要求。
欢迎关注房多多技术微信公众号,一起交流和成长,用互联网技术改变行业,为产业创造价值。

