




openGauss 每日一练第 19 天学习打卡,学习 openGauss 收集统计信息、打印执行计划、垃圾收集和 checkpoint 基本操作!
学习目标
学习 openGauss 收集统计信息、打印执行计划、垃圾收集和 checkpoint
前面每日一练链接:
openGauss每日一练第 1 天 | 数据库和表的基本操作(一)
openGauss每日一练第 2 天 | 数据库和表的基本操作(二)
openGauss每日一练第 3 天 | 前三课作业实操练习
openGauss每日一练第 4 天 | 角色管理及课后作业
openGauss每日一练第 5 天 | 用户管理及课后作业
openGauss每日一练第 6 天 | 模式管理及课后作业
openGauss每日一练第 7 天 | 表空间管理及课后作业
openGauss每日一练第 8 天 | 分区表管理及课后作业
openGauss每日一练第 9 天 | 普通表索引管理及课后作业
openGauss每日一练第 10 天 | 分区表索引管理及课后作业
openGauss每日一练第 11 天 | 视图管理及课后作业
openGauss每日一练第 12 天 | 自定义数据类型管理及课后作业
openGauss每日一练第 13 天 | 数据导入操作及课后作业
openGauss每日一练第 14 天 | 数据导出操作及课后作业
openGauss每日一练第 15 天 | 定义存储过程和函数及课后作业
openGauss每日一练第 16 天 | 事务控制及课后作业
openGauss每日一练第 17 天 | 定义游标及课后作业
openGauss每日一练第 18 天 | 触发器及课后作业
课程学习
学习 openGauss收集统计信息、打印执行计划、垃圾收集和 checkpoint 基本操作!
连接数据库
#第一次进入等待15秒
su - omm
gsql -r
1.准备数据
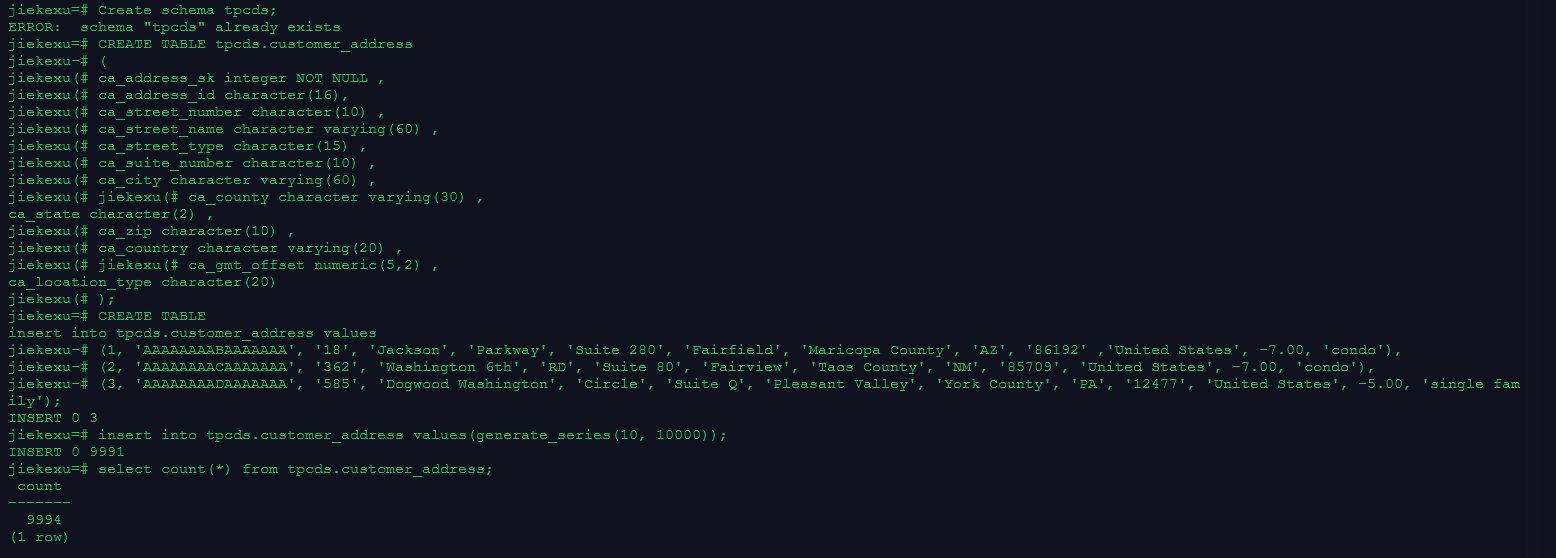
Create schema tpcds;
CREATE TABLE tpcds.customer_address
(
ca_address_sk integer NOT NULL ,
ca_address_id character(16),
ca_street_number character(10) ,
ca_street_name character varying(60) ,
ca_street_type character(15) ,
ca_suite_number character(10) ,
ca_city character varying(60) ,
ca_county character varying(30) ,
ca_state character(2) ,
ca_zip character(10) ,
ca_country character varying(20) ,
ca_gmt_offset numeric(5,2) ,
ca_location_type character(20)
);
insert into tpcds.customer_address values
(1, 'AAAAAAAABAAAAAAA', '18', 'Jackson', 'Parkway', 'Suite 280', 'Fairfield', 'Maricopa County', 'AZ', '86192' ,'United States', -7.00, 'condo'),
(2, 'AAAAAAAACAAAAAAA', '362', 'Washington 6th', 'RD', 'Suite 80', 'Fairview', 'Taos County', 'NM', '85709', 'United States', -7.00, 'condo'),
(3, 'AAAAAAAADAAAAAAA', '585', 'Dogwood Washington', 'Circle', 'Suite Q', 'Pleasant Valley', 'York County', 'PA', '12477', 'United States', -5.00, 'single family');
–使用序列的generate_series(1,N)函数对表插入数据
insert into tpcds.customer_address values(generate_series(10, 10000));
2.收集统计信息
analyze 用于收集与数据库中普通表内容相关的统计信息,统计结果存储在系统表PG_STATISTIC下。执行计划生成器会使用这些统计数据,以确定最有效的执行计划。
如果没有指定参数,ANALYZE会分析当前数据库中的每个表和分区表。同时也可以通过指定table_name、column和partition_name参数把分析限定在特定的表、列或分区表中。
ANALYZE|ANALYSE VERIFY用于检测数据库中普通表(行存表、列存表)的数据文件是否损坏。
注意事项
ANALYZE非临时表不能在一个匿名块、事务块、函数或存储过程内被执行。支持存储过程中ANALYZE临时表,不支持统计信息回滚操作。
ANALYZE VERIFY操作处理的大多为异常场景检测需要使用RELEASE版本。ANALYZE VERIFY 场景不触发远程读,因此远程读参数不生效。对于关键系统表出现错误被系统检测出页面损坏时,将直接报错不再继续检测。
如果没有指定参数,ANALYZE处理当前数据库里用户拥有相应权限的每个表。如果参数中指定了表,ANALYZE只处理指定的表。
要对一个表进行ANALYZE操作,通常用户必须是表的所有者或者被授予了指定表VACUUM权限的用户,默认系统管理员有该权限。数据库的所有者允许对数据库中除了共享目录以外的所有表进行ANALYZE操作(该限制意味着只有系统管理员才能真正对一个数据库进行ANALYZE操作)。ANALYZE命令会跳过那些用户没有权限的表。
语法格式
收集表的统计信息。
{ ANALYZE | ANALYSE } [ VERBOSE ]
[ table_name [ ( column_name [, ...] ) ] ];
收集分区表的统计信息。
{ ANALYZE | ANALYSE } [ VERBOSE ]
[ table_name [ ( column_name [, ...] ) ] ]
PARTITION ( patrition_name ) ;
说明: 普通分区表目前支持针对某个分区的统计信息的语法,但功能上不支持针对某个分区的统计信息收集。
收集多列统计信息
{ANALYZE | ANALYSE} [ VERBOSE ]
table_name (( column_1_name, column_2_name [, ...] ));
说明: - 收集多列统计信息时,请设置GUC参数default_statistics_target为负数,以使用百分比采样方式。 - 每组多列统计信息最多支持32列。 - 不支持收集多列统计信息的表:系统表。
检测当前库的数据文件
{ANALYZE | ANALYSE} VERIFY {FAST|COMPLETE};
说明: - Fast模式校验时,需要对校验的表有并发的DML操作,会导致校验过程中有误报的问题,因为当前Fast模式是直接从磁盘上读取,并发有其他线程修改文件时,会导致获取的数据不准确,建议离线操作。 - 支持对全库进行操作,由于涉及的表较多,建议以重定向保存结果gsql -d database -p port -f “verify.sql”> verify_warning.txt 2>&1。 - 对外提示NOTICE只核对外可见的表,内部表的检测会包含在它所依赖的外部表,不对外显示和呈现。 - 此命令的处理可容错ERROR级别的处理。由于debug版本的Assert可能会导致core无法继续执行命令,建议在release模式下操作。 - 对于全库操作时,当关键系统表出现损坏则直接报错,不再继续执行。
检测表和索引的数据文件
{ANALYZE | ANALYSE} VERIFY {FAST|COMPLETE} table_name|index_name [CASCADE];
说明: - 支持对普通表的操作和索引表的操作,但不支持对索引表index使用CASCADE操作。原因是由于CASCADE模式用于处理主表的所有索引表,当单独对索引表进行检测时,无需使用CASCADE模式。 - 对于主表的检测会同步检测主表的内部表,例如toast表、cudesc表等。 - 当提示索引表损坏时,建议使用reindex命令进行重建索引操作。
检测表分区的数据文件
{ANALYZE | ANALYSE} VERIFY {FAST|COMPLETE} table_name PARTITION {(patrition_name)}[CASCADE];
参考链接:https://opengauss.org/zh/docs/2.0.0/docs/Developerguide/ANALYZE-ANALYSE.html
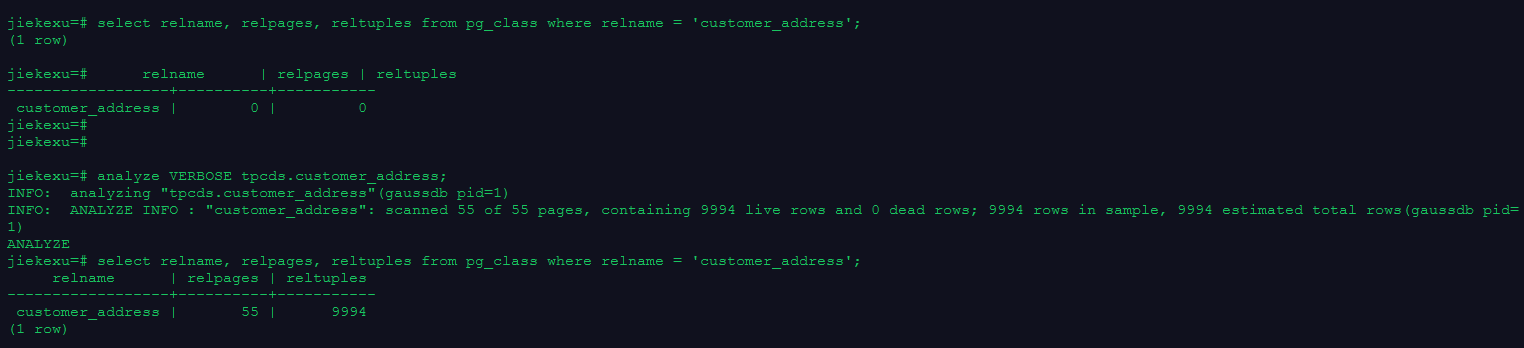
–查看系统表中表的统计信息
select relname, relpages, reltuples from pg_class where relname = 'customer_address';

—使用ANALYZE VERBOSE语句更新统计信息,并输出表的相关信息
analyze VERBOSE tpcds.customer_address;
–查看系统表中表的统计信息
select relname, relpages, reltuples from pg_class where relname = 'customer_address';
3.打印执行计划
EXPLAIN
执行计划将显示SQL语句所引用的表会采用什么样的扫描方式,如:简单的顺序扫描、索引扫描等。如果引用了多个表,执行计划还会显示用到的JOIN算法。
执行计划的最关键的部分是语句的预计执行开销,这是计划生成器估算执行该语句将花费多长的时间。
若指定了ANALYZE选项,则该语句会被执行,然后根据实际的运行结果显示统计数据,包括每个计划节点内时间总开销(毫秒为单位)和实际返回的总行数。这对于判断计划生成器的估计是否接近现实非常有用。
参考链接: https://opengauss.org/zh/docs/2.0.0/docs/Developerguide/EXPLAIN.html
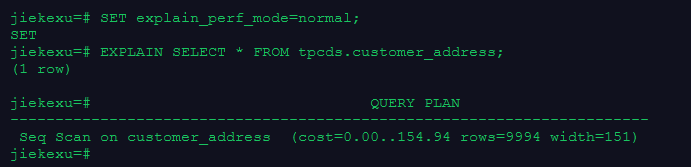
–使用默认的打印格式
SET explain_perf_mode=normal;
–显示表简单查询的执行计划
EXPLAIN SELECT * FROM tpcds.customer_address;
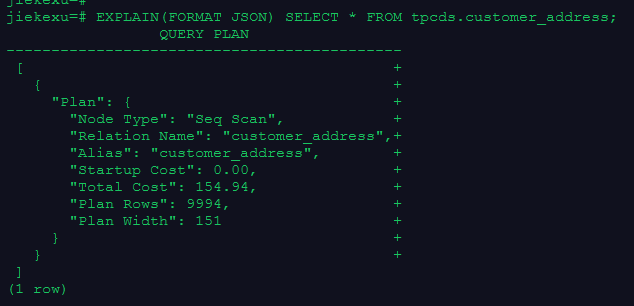
–以JSON格式输出的执行计划(explain_perf_mode为normal时)
EXPLAIN(FORMAT JSON) SELECT * FROM tpcds.customer_address;
jiekexu=# EXPLAIN(FORMAT JSON) SELECT * FROM tpcds.customer_address;
QUERY PLAN
--------------------------------------------
[ +
{ +
"Plan": { +
"Node Type": "Seq Scan", +
"Relation Name": "customer_address",+
"Alias": "customer_address", +
"Startup Cost": 0.00, +
"Total Cost": 154.94, +
"Plan Rows": 9994, +
"Plan Width": 151 +
} +
} +
]
(1 row)
–禁止开销估计的执行计划
EXPLAIN(COSTS FALSE)SELECT * FROM tpcds.customer_address;

–带有聚集函数查询的执行计划
EXPLAIN SELECT SUM(ca_address_sk) FROM tpcds.customer_address WHERE ca_address_sk<100;

–有索引条件的执行计划
create index customer_address_idx on tpcds.customer_address(ca_address_sk);
EXPLAIN SELECT * FROM tpcds.customer_address WHERE ca_address_sk<100;

4.垃圾收集
–VACUUM 回收表或 B-Tree 索引中已经删除的行所占据的存储空间
在一般的数据库操作里,那些已经DELETE的行并没有从它们所属的表中物理删除;在完成VACUUM之前它们仍然存在。因此有必要周期地运行VACUUM,特别是在经常更新的表上。
注意事项
如果没有参数,VACUUM处理当前数据库里用户拥有相应权限的每个表。如果参数指定了一个表,VACUUM只处理指定的那个表。
要对一个表进行VACUUM操作,通常用户必须是表的所有者或者被授予了指定表VACUUM权限的用户,默认系统管理员有该权限。数据库的所有者允许对数据库中除了共享目录以外的所有表进行VACUUM操作(该限制意味着只有系统管理员才能真正对一个数据库进行VACUUM操作)。VACUUM命令会跳过那些用户没有权限的表进行垃圾回收操作。
VACUUM不能在事务块内执行。
建议生产数据库经常清理(至少每晚一次),以保证不断地删除失效的行。尤其是在增删了大量记录之后,对受影响的表执行VACUUM ANALYZE命令是一个很好的习惯。这样将更新系统目录为最近的更改,并且允许查询优化器在规划用户查询时有更好的选择。
不建议日常使用FULL选项,但是可以在特殊情况下使用。例如在用户删除了一个表的大部分行之后,希望从物理上缩小该表以减少磁盘空间占用。VACUUM FULL通常要比单纯的VACUUM收缩更多的表尺寸。FULL选项并不清理索引,所以推荐周期性的运行REINDEX命令。实际上,首先删除所有索引,再运行VACUUM FULL命令,最后重建索引通常是更快的选择。如果执行此命令后所占用物理空间无变化(未减少),请确认是否有其他活跃事务(删除数据事务开始之前开始的事务,并在VACUUM FULL执行前未结束)存在,如果有等其他活跃事务退出进行重试。
VACUUM会导致I/O流量的大幅增加,这可能会影响其他活动会话的性能。因此,有时候会建议使用基于开销的VACUUM延迟特性。
如果指定了VERBOSE选项,VACUUM将打印处理过程中的信息,以表明当前正在处理的表。各种有关当前表的统计信息也会打印出来。但是对于列存表执行VACUUM操作,指定了VERBOSE选项,无信息输出。
当含有带括号的选项列表时,选项可以以任何顺序写入。如果没有括号,则选项必须按语法显示的顺序给出。
VACUUM和VACUUM FULL时,会根据参数vacuum_defer_cleanup_age延迟清理行存表记录,即不会立即清理刚刚删除的元组。
VACUUM ANALYZE先执行一个VACUUM操作,然后给每个选定的表执行一个ANALYZE。对于日常维护脚本而言,这是一个很方便的组合。
简单的VACUUM(不带FULL选项)只是简单地回收空间并且令其可以再次使用。这种形式的命令可以和对表的普通读写并发操作,因为没有请求排他锁。VACUUM FULL执行更广泛的处理,包括跨块移动行,以便把表压缩到最少的磁盘块数目里。这种形式要慢许多并且在处理的时候需要在表上施加一个排他锁。
VACUUM列存表内部执行的操作包括三个:迁移delta表中的数据到主表、VACUUM主表的delta表、VACUUM主表的desc表。该操作不会回收delta表的存储空间,如果要回收delta表的冗余存储空间,需要对该列存表执行VACUUM DELTAMERGE。
同时执行多个VACUUM FULL可能出现死锁。
如果没有打开xc_maintenance_mode参数,那么VACUUM FULL操作将跳过所有系统表。
参考链接: https://opengauss.org/zh/docs/2.0.0/docs/Developerguide/VACUUM.html
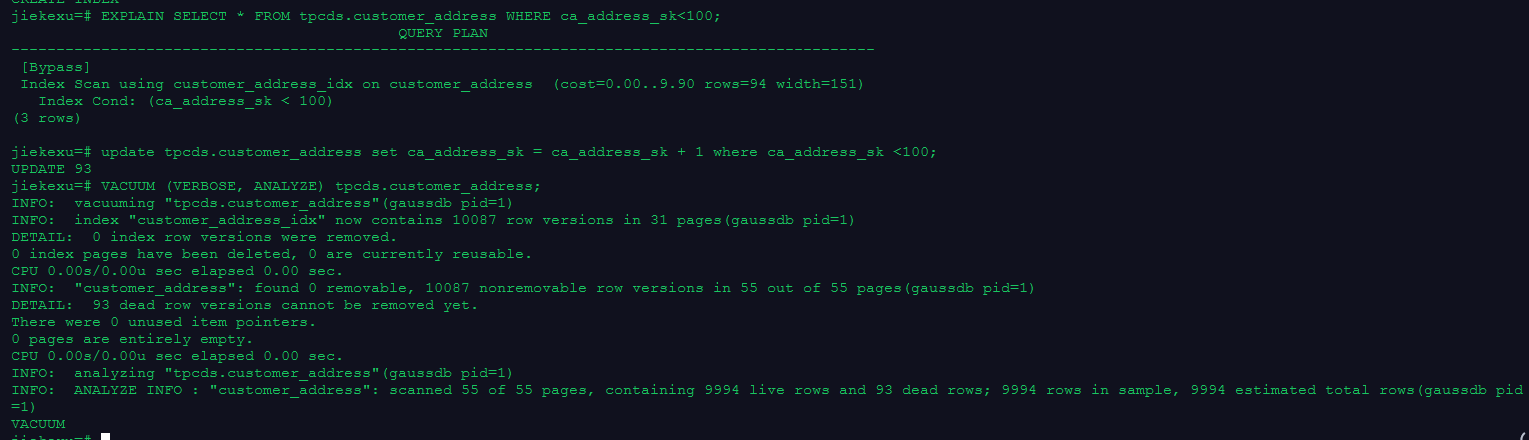
update tpcds.customer_address set ca_address_sk = ca_address_sk + 1 where ca_address_sk <100;
VACUUM (VERBOSE, ANALYZE) tpcds.customer_address;
jiekexu=# create index customer_address_idx on tpcds.customer_address(ca_address_sk);
CREATE INDEX
jiekexu=# EXPLAIN SELECT * FROM tpcds.customer_address WHERE ca_address_sk<100;
QUERY PLAN
------------------------------------------------------------------------------------------------
[Bypass]
Index Scan using customer_address_idx on customer_address (cost=0.00..9.90 rows=94 width=151)
Index Cond: (ca_address_sk < 100)
(3 rows)
jiekexu=# update tpcds.customer_address set ca_address_sk = ca_address_sk + 1 where ca_address_sk <100;
UPDATE 93
jiekexu=# VACUUM (VERBOSE, ANALYZE) tpcds.customer_address;
INFO: vacuuming "tpcds.customer_address"(gaussdb pid=1)
INFO: index "customer_address_idx" now contains 10087 row versions in 31 pages(gaussdb pid=1)
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: "customer_address": found 0 removable, 10087 nonremovable row versions in 55 out of 55 pages(gaussdb pid=1)
DETAIL: 93 dead row versions cannot be removed yet.
There were 0 unused item pointers.
0 pages are entirely empty.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: analyzing "tpcds.customer_address"(gaussdb pid=1)
INFO: ANALYZE INFO : "customer_address": scanned 55 of 55 pages, containing 9994 live rows and 93 dead rows; 9994 rows in sample, 9994 estimated total rows(gaussdb pid=1)
VACUUM
5.事务日志检查点
–检查点(CHECKPOINT)
是一个事务日志中的点,所有数据文件都在该点被更新以反映日志中的信息,所有数据文件都将被刷新到磁盘.
设置事务日志检查点。预写式日志(WAL)缺省时在事务日志中每隔一段时间放置一个检查点。可以使用gs_guc命令设置相关运行时参数(checkpoint_segments,checkpoint_timeout和incremental_checkpoint_timeout)来调整这个原子化检查点的间隔。
注意事项
只有系统管理员和运维管理员可以调用CHECKPOINT。
CHECKPOINT强制立即进行检查,而不是等到下一次调度时的检查点。
CHECKPOINT;
6.清理数据
drop schema tpcds cascade;
课后作业
1.创建分区表,并用 generate_series(1,N) 函数对表插入数据
CREATE TABLESPACE tbs_test1 RELATIVE LOCATION 'tablespace1/tbs_test1';
CREATE TABLESPACE tbs_test2 RELATIVE LOCATION 'tablespace2/tbs_test2';
CREATE TABLESPACE tbs_test3 RELATIVE LOCATION 'tablespace3/tbs_test3';
CREATE TABLESPACE tbs_test4 RELATIVE LOCATION 'tablespace4/tbs_test4';
Create schema test;
CREATE TABLE test.products
(
CA_ADDRESS_SK INTEGER NOT NULL,
CA_ADDRESS_ID CHAR(16) ,
CA_STREET_NUMBER CHAR(10) ,
CA_STREET_NAME VARCHAR(60) ,
CA_STREET_TYPE CHAR(15) ,
CA_SUITE_NUMBER CHAR(10) ,
CA_CITY VARCHAR(60) ,
CA_COUNTY VARCHAR(30) ,
CA_STATE CHAR(2) ,
CA_ZIP CHAR(10) ,
CA_COUNTRY VARCHAR(20) ,
CA_GMT_OFFSET DECIMAL(5,2) ,
CA_LOCATION_TYPE CHAR(20)
)
PARTITION BY RANGE(CA_ADDRESS_SK)
(
PARTITION p1 VALUES LESS THAN (300),
PARTITION p2 VALUES LESS THAN (500) TABLESPACE tbs_test1,
PARTITION p3 VALUES LESS THAN (MAXVALUE) TABLESPACE tbs_test2
);
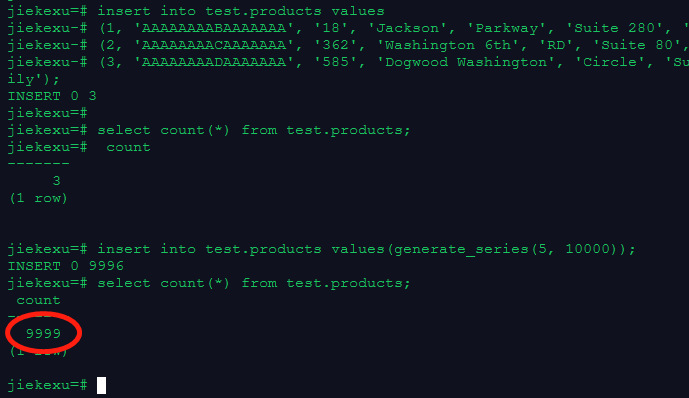
insert into test.products values
(1, 'AAAAAAAABAAAAAAA', '18', 'Jackson', 'Parkway', 'Suite 280', 'Fairfield', 'Maricopa County', 'AZ', '86192' ,'United States', -7.00, 'condo'),
(2, 'AAAAAAAACAAAAAAA', '362', 'Washington 6th', 'RD', 'Suite 80', 'Fairview', 'Taos County', 'NM', '85709', 'United States', -7.00, 'condo'),
(3, 'AAAAAAAADAAAAAAA', '585', 'Dogwood Washington', 'Circle', 'Suite Q', 'Pleasant Valley', 'York County', 'PA', '12477', 'United States', -5.00, 'single family');
insert into test.products values(generate_series(5, 10000));
2.收集表统计信息
select relname, relpages, reltuples from pg_class where relname = 'products';
analyze VERBOSE test.products PARTITION (p3);
select relname, relpages, reltuples from pg_class where relname = 'products';
VERBOSE 启用显示进度信息
jiekexu=# analyze VERBOSE test.products;
INFO: analyzing "test.products"(gaussdb pid=1)
INFO: ANALYZE INFO : "products": scanned 2 of 2 pages, containing 298 live rows and 0 dead rows; 298 rows in sample, 298 estimated total rows(gaussdb pid=1)
INFO: ANALYZE INFO : "products": scanned 2 of 2 pages, containing 200 live rows and 0 dead rows; 200 rows in sample, 200 estimated total rows(gaussdb pid=1)
INFO: ANALYZE INFO : "products": scanned 52 of 52 pages, containing 9501 live rows and 0 dead rows; 9501 rows in sample, 9501 estimated total rows(gaussdb pid=1)
ANALYZE
jiekexu=# select relname, relpages, reltuples from pg_class where relname = 'products';
jiekexu=# relname | relpages | reltuples
----------+----------+-----------
products | 56 | 9999
(1 row)
3.显示简单查询的执行计划;建立索引并显示有索引条件的执行计划
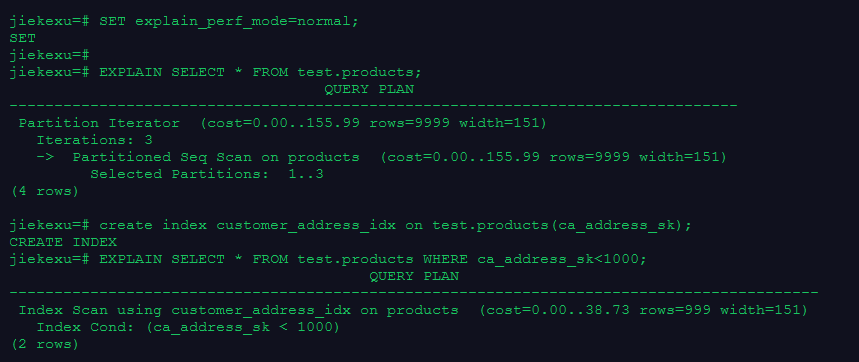
SET explain_perf_mode=normal;
EXPLAIN SELECT * FROM test.products;
create index customer_address_idx on test.products(ca_address_sk);
EXPLAIN SELECT * FROM test.products WHERE ca_address_sk<1000;
4.更新表数据,并做垃圾收集
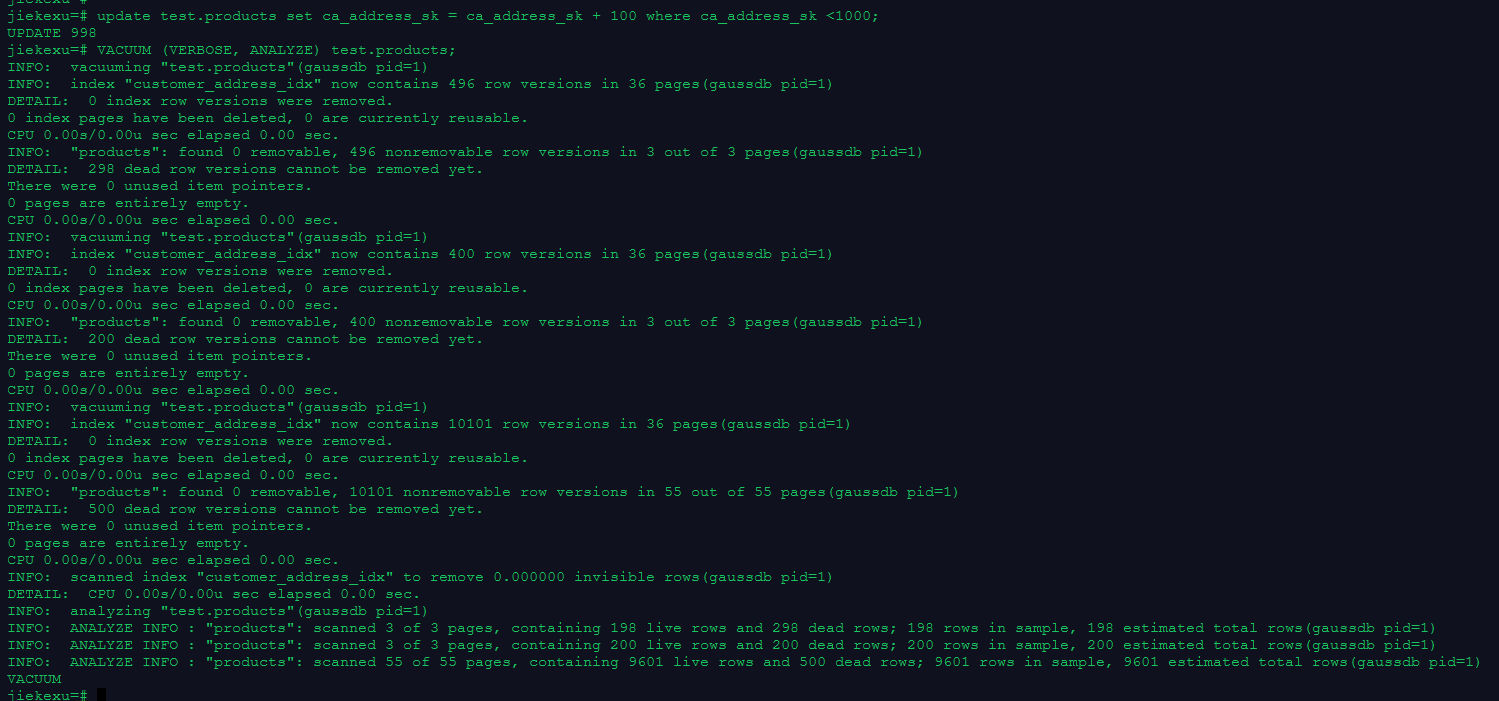
update test.products set ca_address_sk = ca_address_sk + 100 where ca_address_sk <1000;
VACUUM (VERBOSE, ANALYZE) test.products;
jiekexu=# update test.products set ca_address_sk = ca_address_sk + 100 where ca_address_sk <1000;
UPDATE 998
jiekexu=# VACUUM (VERBOSE, ANALYZE) test.products;
INFO: vacuuming "test.products"(gaussdb pid=1)
INFO: index "customer_address_idx" now contains 496 row versions in 36 pages(gaussdb pid=1)
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: "products": found 0 removable, 496 nonremovable row versions in 3 out of 3 pages(gaussdb pid=1)
DETAIL: 298 dead row versions cannot be removed yet.
There were 0 unused item pointers.
0 pages are entirely empty.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: vacuuming "test.products"(gaussdb pid=1)
INFO: index "customer_address_idx" now contains 400 row versions in 36 pages(gaussdb pid=1)
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: "products": found 0 removable, 400 nonremovable row versions in 3 out of 3 pages(gaussdb pid=1)
DETAIL: 200 dead row versions cannot be removed yet.
There were 0 unused item pointers.
0 pages are entirely empty.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: vacuuming "test.products"(gaussdb pid=1)
INFO: index "customer_address_idx" now contains 10101 row versions in 36 pages(gaussdb pid=1)
DETAIL: 0 index row versions were removed.
0 index pages have been deleted, 0 are currently reusable.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: "products": found 0 removable, 10101 nonremovable row versions in 55 out of 55 pages(gaussdb pid=1)
DETAIL: 500 dead row versions cannot be removed yet.
There were 0 unused item pointers.
0 pages are entirely empty.
CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: scanned index "customer_address_idx" to remove 0.000000 invisible rows(gaussdb pid=1)
DETAIL: CPU 0.00s/0.00u sec elapsed 0.00 sec.
INFO: analyzing "test.products"(gaussdb pid=1)
INFO: ANALYZE INFO : "products": scanned 3 of 3 pages, containing 198 live rows and 298 dead rows; 198 rows in sample, 198 estimated total rows(gaussdb pid=1)
INFO: ANALYZE INFO : "products": scanned 3 of 3 pages, containing 200 live rows and 200 dead rows; 200 rows in sample, 200 estimated total rows(gaussdb pid=1)
INFO: ANALYZE INFO : "products": scanned 55 of 55 pages, containing 9601 live rows and 500 dead rows; 9601 rows in sample, 9601 estimated total rows(gaussdb pid=1)
VACUUM
5.清理数据
DROP INDEX customer_address_idx;
DROP table test.products;
DROP tablespace tbs_test1;
DROP tablespace tbs_test2;
DROP tablespace tbs_test3;
DROP tablespace tbs_test4;
DROP schema test cascade;
欧耶,第十九课 收集统计信息、打印执行计划、垃圾收集和 checkpoint 及课后作业练习题完成啦!今天内容有点多,需要慢慢消化,也是重点内容。明天第二十课见!!!
