




定义
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎.
启动es
#下载curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.3.tar.gz# 2.解压tar -xvf elasticsearch-5.6.3.tar.gz# 3.启动cd elasticsearch-5.6.3/bin./elasticsearch# 指定名字启动 :./elasticsearch -Ecluster.name=my_cluster_name -Enode.name=my_node_name
#修改kibana/config下的配合文件kibana.ymlserver.host: "192.168.198.128" #修改为外网可访问的地址elasticsearch.url: "http://localhost:9200" #修改为es的地址#进入bin文件夹启动 :./kibana#浏览器访问 : http://192.168.198.128:5601/app/kibana#/dev_tools/console?_g=()#注意关闭防火墙 `service iptables stop`
lucence
lucene,最先进、功能最强大的搜索库;直接基于 lucene 开发,非常复杂,api 复杂,需要深入理解原理(各种索引结构).Elasticsearch 基于 lucene,隐藏复杂性,提供简单易用的 restful api 接口,是一个分布式的搜索引擎和分析引擎.
Lucene的抽象结构
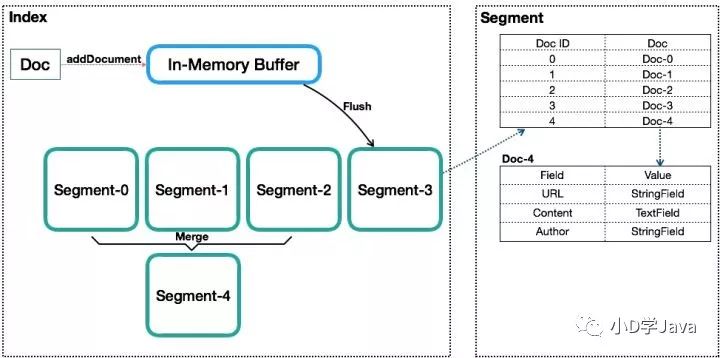
Lucene 的不足
Lucene 是一个单机的搜索库,如何能以分布式形式支持海量数据?(路由)
Lucene 中没有更新,每次都是 Append 一个新文档,如何做部分字段的更新?
Lucene 中没有主键索引,如何处理同一个 Doc 的多次写入?(es 新增了一个 "_id" 字段)
在稀疏列数据中,如何判断某些文档是否存在特定字段?("_source" 字段)
Lucene 中生成完整 Segment 后,该 Segment 就不能再被更改,此时该 Segment 才能被搜索,这种情况下,如何做实时搜索?
倒排索引
倒排索引由在文档中出现的唯一的单词列表,以及对于每个单词在文档中的位置组成。
基本元素
NRT(近实时,Near Realtime)
集群
分片(shard) - 每个 shard可创建多个 replica副本
副本(replica) - replica可以在 shard 故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能.默认的副本数为1
数据结构
索引
类型
文档
field
数据类型
text,keyword
byte,short,integer,long
float,double
boolean
date
Elasticsearch 5.0.0 版本之后 将string
拆分成两个新的类型: text和keyword.
Keyword类型:
用于存储邮箱号码、手机号码、主机名、状态码、邮政编码、标签、年龄、性别等数据。
用于筛选数据(例如: select * from x where status='open')、排序、聚合(统计)。
直接将完整的文本保存到倒排索引中。
Text类型:
用于存储全文搜索数据, 例如: 邮箱内容、地址、代码块、博客文章内容等。
默认结合standard analyzer(标准解析器)对文本进行分词、倒排索引。
默认结合标准分析器进行词命中、词频相关度打分。
//如果想让一个keyword字段既可支持精确查询又可支持全文查询,可使用`fields`属性来声明一个类型的别名{"mappings": {"my_type": {"properties": {"${field}": {"type": "keyword","fields": {"${field_searchable}": {"type": "text"}}}}}}}//想查询全文搜索时{"query": {"match": {"${field}.${field_searchable}": "${val}"}}}
乐观锁
es的记录中存在着一个_version
,用来声明当前记录的版本号.创建时初始值为0,之后每次更新成功后都会在操作后将值加一.所以如果要避免记录在更新时相互覆盖的场景,则可在更新记录时先到es获取对应记录得到版本号,然后更新时带上这个版本号来实现乐观锁更新
Bulk批量操作
Bulk 不是原子性的,不能用它来实现事务控制。每个请求是单独处理的,因此一个请求的成功或失败不会影响其他的请求。
Bulk Request 会加载到内存里,如果太大的话,性能反而会下降,因此需要反复尝试一个最佳的 bulk size。一般从 1000~5000 条数据开始,尝试逐渐增加。另外,如果看大小的话,最好是在 5~15MB 之间。
操作类型
index - 普通的put操作,可以是创建文档,也可以是全量替换文档
create -
PUT /${index}/${type}/${id}/_create
,强制创建/存在则报错update
delete
数据格式
采用这种一行定位信息,一行doc记录的行格式而不使用json格式的原因是es的数据是分片的,一行行读取后可将记录直接就转发到相应的分片上,而使用json需解析并整个数据需耗费更多的内存,更多的gc开销
{"action": {"meta"}}\n
{"data"}\n
{"action": {"meta"}}\n
{"data"}\n
路由算法
shard = hash(routing) % number_of_primary_shards
routing =
_id
or custom routing value
主分片默认为5个,一旦创建了就不能修改就是因为document记录是基于主分片数来hash取模的.
当然es支持手动指定路由键,比如说 put /${index}/${type}/${id}?routing=${user_id}|
,此时可将同一个用户的数据都路由到同一个分片中,能提升批量读取时的性能
分片之间的数据同步
在客户端请求时,主分片会将结果同步到副本分片后再返回客户端的响应
查询过程解析
客户端请求到es集群的某个节点A,此时节点A作为协调节点
A根据路由键计算记录是分布在哪一个shard上,我们假设在分片
one
上A将在分片
one
的主分片以及副本分片上随机选一个来执行这次查询
特殊情况,当查询的记录正在主分片上创建或更新时,记录还没同步到副本分片中,此时查询的结果可能是脏数据或者是查不到数据.解决方法是敏感数据只在主分片执行查询.
搜索请求的基本模块
query - 使用查询或者过滤器等
from/size
_source - 可明确指定只返回哪些字段
sort
filter与query对比
filter:仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响.而且filter可以被缓存.所以一般来讲,filter比query快.
query:会去计算每个 document 相对于搜索条件的相关度,并按照相关度进行排序
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用 query;如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用 filter;
GET /${index}/${type}/_search{"query": {"bool": {"must": [{"match": {"${field}": "${val}"}}],"filter": {"range": {"${filed2}": {"gte": ${val2} //gte表示大于等于,也可使用如gt,lte等}}}}}}
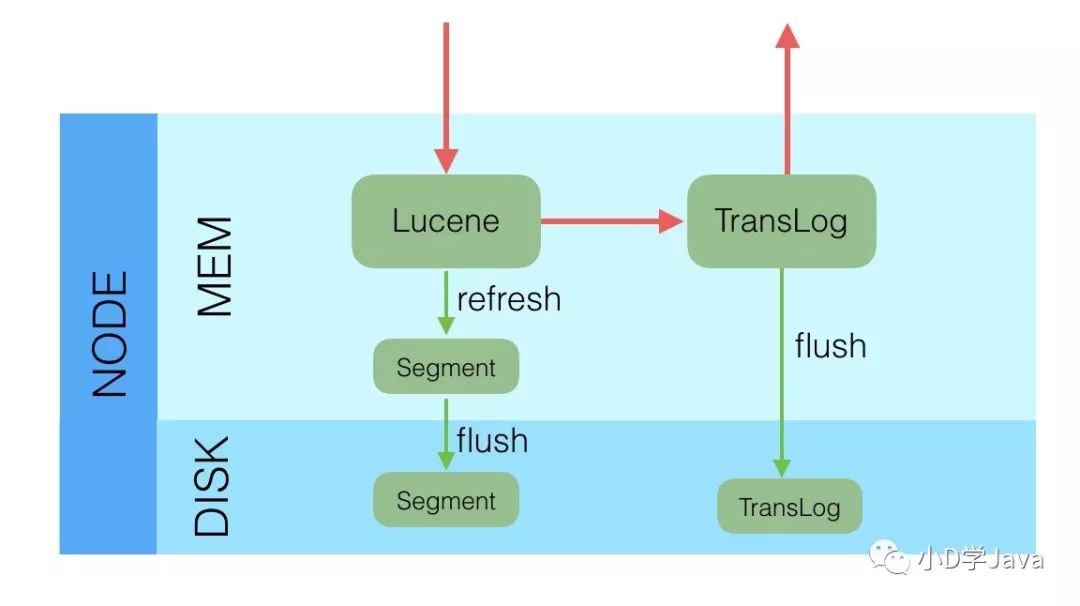
写操作解析
es写入流程是写将数据写入lucene,数据载入内存后,再将数据写入translog刷新到磁盘,写磁盘成功后,请求返回给用户。Segment是不可变的,当我们更新一个文档时,会把老的数据打上已删除的标记,然后写一条新的文档。在执行flush操作的时候,才会把已删除的记录物理删除掉。
相关度得分算法
在开始计算得分之时,Elasticsearch使用了被搜索词条的频率以及它有多常见来影响得分。一个简短的解释是,一个词条出现在某个文档中的次数越多,它就越相关。但是,如果该词条出现在不同的文档的次数越多,它就越不相关。这一点被称为TF-IDF ( TF是词频,即term frequency), IDF是逆文档频率( inverse document frequency)
影响因素
Term frequency(不同词的频率) - 某个文档出现次数越多,就越相关
Inverse document frequency(相同词的频率) - 不同文档出现的次数越多,就越不相关
Field-length norm - field越长,相关度越弱
深度查询分页常用做法
from/size
search-after
srcoll
游标查询会取某个时间点的快照数据。查询初始化之后索引上的任何变化会被它忽略。它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引 '视图' 一样。
深度分页的代价根源是结果集全局排序,如果去掉全局排序的特性的话查询结果的成本就会很低。游标查询用字段 _doc
来排序。这个指令让 Elasticsearch 仅仅从还有结果的分片返回下一批结果。
启用游标查询可以通过在查询的时候设置参数 scroll
的值为我们期望的游标查询的过期时间。游标查询的过期时间会在每次做查询的时候刷新,所以这个时间只需要足够处理当前批的结果就可以了,而不是处理查询结果的所有文档的所需时间。这个过期时间的参数很重要,因为保持这个游标查询窗口需要消耗资源,所以我们期望如果不再需要维护这种资源就该早点儿释放掉。设置这个超时能够让 Elasticsearch 在稍后空闲的时候自动释放这部分资源。
GET /old_index/_search?scroll=1m //保持游标查询窗口一分钟{"query": { "match_all": {}},"sort" : ["_doc"], //关键字 _doc 是最有效的排序顺序"size": 1000}//这个查询的返回结果包括一个字段 _scroll_id, 它是一个base64编码的长字符串 。//现在我们能传递字段 _scroll_id 到 _search/scroll 查询接口获取下一批结果:GET /_search/scroll{"scroll": "1m", //注意再次设置游标查询过期时间为一分钟。"scroll_id" : "cXVlcnlUaGVuRmV0Y2g7...."}//注意游标查询每次返回一个新字段 _scroll_id。每次我们做下一次游标查询, 我们必须把前一次查询返回的字段 _scroll_id 传递进去。//当没有更多的结果返回的时候,我们就处理完所有匹配的文档了。
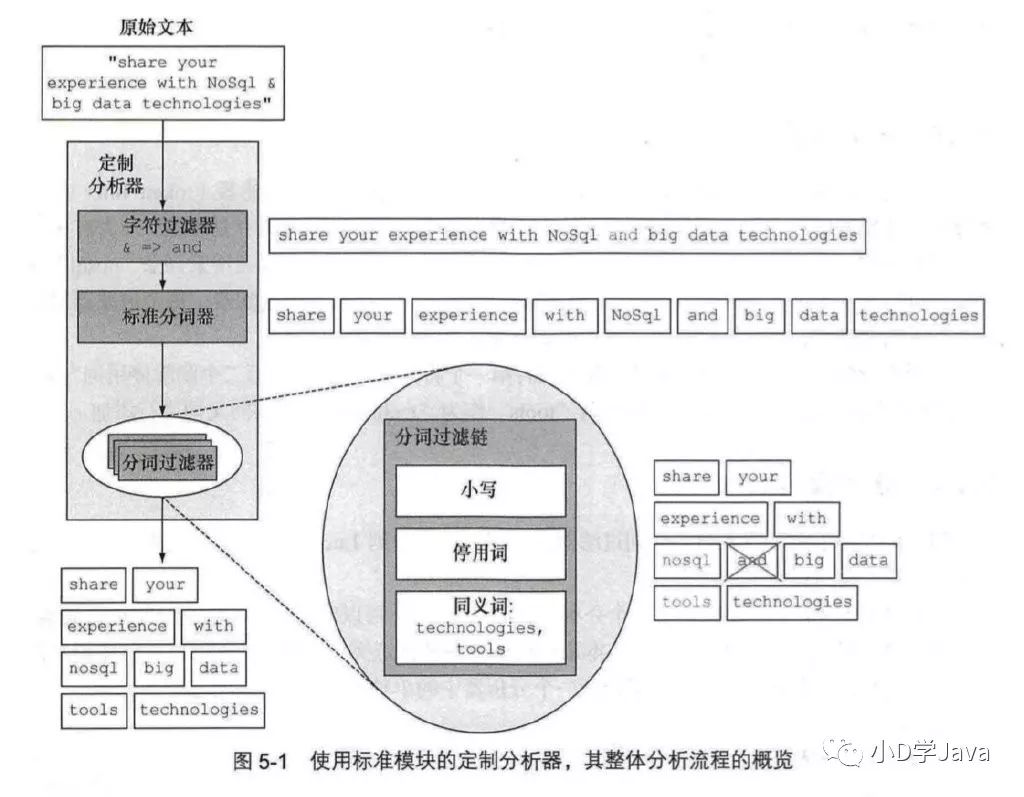
分析
分析(analysis )是在文档被发送并加人倒排索引之前,Elasticsearch在其主体上进行的操作。在文档被加人索引之前,Elasticsearch让每个被分析字段经过一系列的处理步骤。
字符过滤一使用字符过滤器转变字符。
文本切分为分词一将文本切分为单个或多个分词。
分词过滤一使用分词过滤器转变每个分词。
分词索引 - 将这些分词存储到索引中
segment分段配置优化
刷新(refresh)和冲刷( flush)的频率 - 刷新会让Elasticsearch重新打开索引,让新建的文档可用于搜索。冲刷是将索引的数据从内存写入磁盘。
合并分段 - 过多的分段搜索是很慢的,因此在后台小分段会被合并为较大的分段,保持分段的数量可控。
存储和存储限流 - 调节每秒写入的字节数,来限制合并对于I/O系统的影响
默认的行为是每秒自动地刷新每份索引,意味着你有一秒钟的数据查询延迟。你可以修改其设置,改变每份索引的刷新间隔,这个是可以在运行时完成的。例如,下面的命令将自动刷新的间隔设置为了5秒。
//设置index为5s刷新一次,curl -XPUT localhost:9200/${index}/_ settings -d '{"index. refresh interval": "5s"}'//查询设置的值curl localhost:9200/${index}/_settings?pretty//关闭自动刷新curl -XPUT localhost:9200/${index}/_ settings -d '{"index. refresh interval": "-1"}'//手动触发更新curl localhost:9200/${index}/_refresh
冲刷即将内存中的分段提交到磁盘上的Lucene索引的过程.为了确保某个节点宕机或分片移动位置的时候,内存数据不会丢失, Elasticsearch将使用事物日志来跟踪尚未冲刷的索引操作。除了将内存分段提交到磁盘,冲刷还会清理事物日志
冲刷触发的时机,以下任一满足条件即可
内存缓冲区已满。
自上次冲刷后超过了一定的时间。
事物日志达到了一-定的阈值。
//更新索引事务日志设置curl -XPUT localhost: 9200/${index}/_ settings -d '{"index. translog": {"flush_ threshold size": "500mb", //达到500M才触发冲刷" flush_ threshold period": "10m" ,//10m才触发}}'
合并分段
curl -XPUT localhost: 9200/${index}/_settings -d '{"index.merge": {"policy": {"segments_per_tier": 5,#值越大,拥有的分段数越多"max_merge_at_once": 5, #限制一次最多合并多少个分段"max_merged_segment": "1gb" #控制最大的分段大小,},#控制合并的线程数量为1”scheduler. max_ thread count": 1}}'
合并限流
因段合并会对IO产生压力,因此es提供了存储限流来限制合并时可使用的IO吞吐量.默认情况下有一个节点层级的设置,称为indices. store. throttle.max_ bytes_ per_ sec
, 在版本1.5中其默认值是20mb字节。
