




在Elasticsearch中选举master节点是Elasticsearch集群中所有master-eligible节点需要一起完成的基本任务。要了解选举流程,我们需要回答几个问题,什么情况下会触发选举?具体选举流程是什么样的?与以前的版本相比,7.x都有哪些变化?现在我们来回答下这几个问题。
1.选举条件
Elasticsearch会在以下两种情况触发选举:
Elasticsearch集群启动 Elasticsearch集群当前的master节点挂掉
2.选举流程
Elasticsearch选举流程是基于Raft协议实现的:
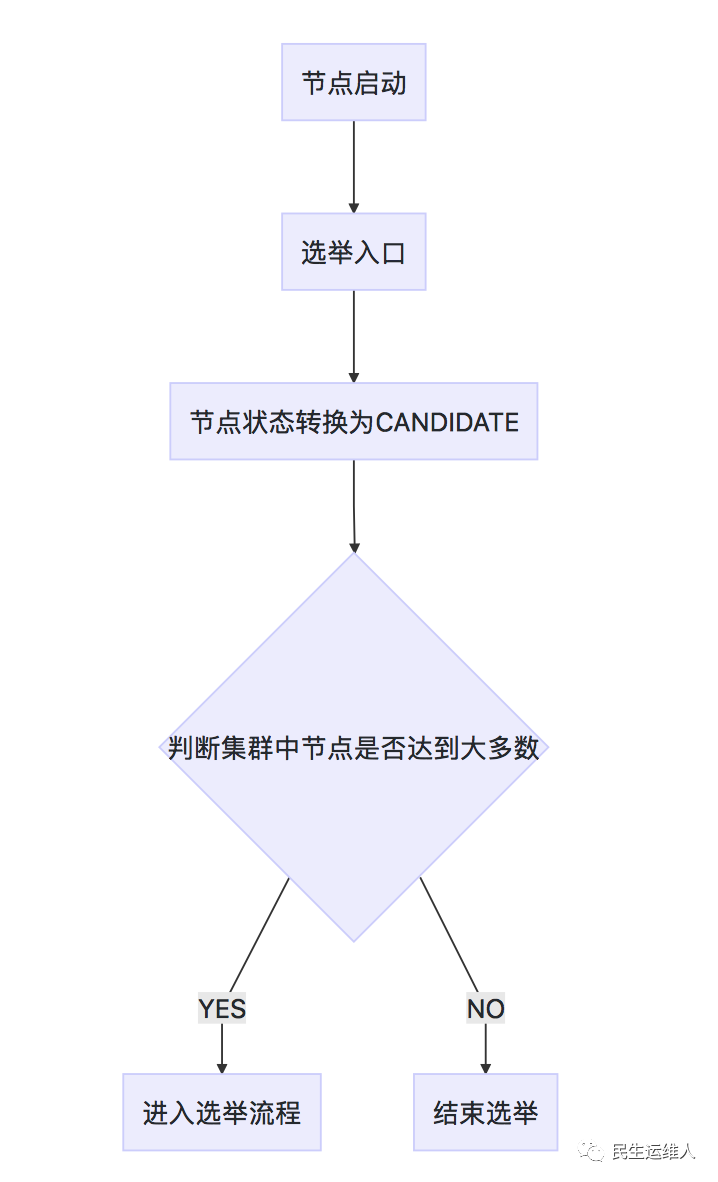
(1)节点启动
从节点启动到进入选举的流程如下所示:
整个选举流程的入口如下:
clusterService.addStateApplier(transportService.getTaskManager());
// start after transport service so the local disco is known
discovery.start(); // start before cluster service so that it can set initial state on ClusterApplierService
clusterService.start();
assert clusterService.localNode().equals(localNodeFactory.getNode())
: "clusterService has a different local node than the factory provided";
transportService.acceptIncomingRequests();
discovery.startInitialJoin();
final TimeValue initialStateTimeout = DiscoverySettings.INITIAL_STATE_TIMEOUT_SETTING.get(settings());
configureNodeAndClusterIdStateListener(clusterService);
startInitialJoin()方法如下,该方法中最重要的就是becomeCandidate()方法。
@Override
public void startInitialJoin() {
synchronized (mutex) {
becomeCandidate("startInitialJoin");
}
clusterBootstrapService.scheduleUnconfiguredBootstrap();
}
在becomeCandidate()方法中,它首先先将节点的状态转换为candidate。在activate()方法中调用onFoundPeersUpdated()方法检查集群中的节点是否达到多数,如果达到多数则会发起选举流程startElectionScheduler()。核心代码如下:
if (mode != Mode.CANDIDATE) {
final Mode prevMode = mode;
mode = Mode.CANDIDATE;
cancelActivePublication("become candidate: " + method);
joinAccumulator.close(mode);
joinAccumulator = joinHelper.new CandidateJoinAccumulator();
peerFinder.activate(coordinationState.get().getLastAcceptedState().nodes());
clusterFormationFailureHelper.start();
@Override
protected void onFoundPeersUpdated() {
synchronized (mutex) {
final Iterable<DiscoveryNode> foundPeers = getFoundPeers();
if (mode == Mode.CANDIDATE) {
final VoteCollection expectedVotes = new VoteCollection();
foundPeers.forEach(expectedVotes::addVote);
expectedVotes.addVote(Coordinator.this.getLocalNode());
final boolean foundQuorum = coordinationState.get().isElectionQuorum(expectedVotes);
if (foundQuorum) {
if (electionScheduler == null) {
startElectionScheduler();
}
} else {
closePrevotingAndElectionScheduler();
}
}
}
clusterBootstrapService.onFoundPeersUpdated();
}
}
(2)Prevote
引入prevote的原因是为了防止集群发生毫无意义的反复选举的情况,例如:集群中存在网络故障使得某个节点暂时脱离集群,在该节点重新加入到集群后会干扰到集群的运行,具体分析:当该节点脱离集群后,在timeout时间内没有收到leader的心跳后就会发起新的选举,每次发起选举时term就会加1。由于网络隔离,该节点既不会被选为leader,也收不到leader的心跳,所以它会一直发起选举,使得其term不断增大。网络恢复后,当该节点重新加入集群时,由于其term比集群中其他节点的term大,导致集群中原来的节点更新自己的term并使leader变为follower,进行重新选举。为了防止这种情况发生,在选举开始前先进行prevote,以确认集群中大多数节点认为当前集群中没有leader。详细内容见:https://github.com/elastic/elasticsearch/pull/32847
prevote流程可以用下图来描述:
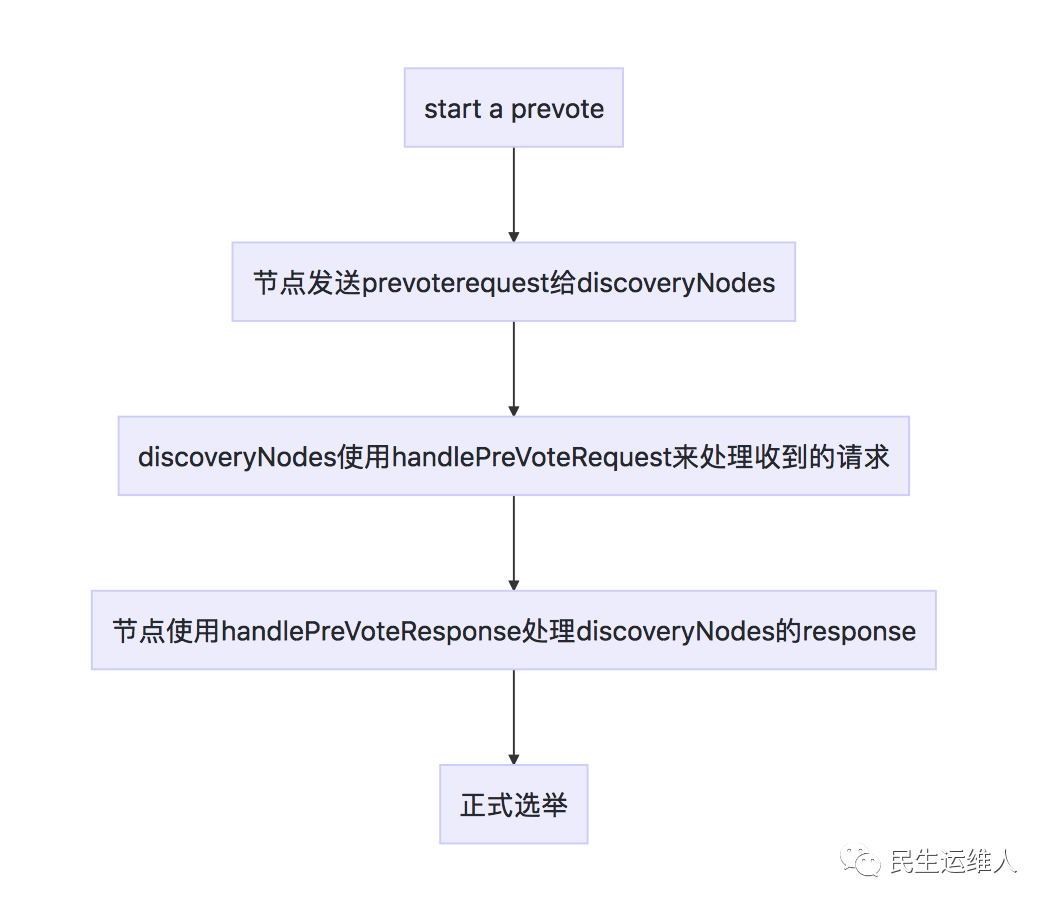
prevote流程的入口如下所示:
/**
* Start a new pre-voting round.
*
* @param clusterState the last-accepted cluster state
* @param broadcastNodes the nodes from whom to request pre-votes
* @return the pre-voting round, which can be closed to end the round early.
*/
public Releasable start(final ClusterState clusterState, final Iterable<DiscoveryNode> broadcastNodes) {
PreVotingRound preVotingRound = new PreVotingRound(clusterState, state.v2().getCurrentTerm());
preVotingRound.start(broadcastNodes);
return preVotingRound;
}
void start(final Iterable<DiscoveryNode> broadcastNodes) {
assert StreamSupport.stream(broadcastNodes.spliterator(), false).noneMatch(Coordinator::isZen1Node) : broadcastNodes;
logger.debug("{} requesting pre-votes from {}", this, broadcastNodes);
broadcastNodes.forEach(n -> transportService.sendRequest(n, REQUEST_PRE_VOTE_ACTION_NAME, preVoteRequest,
new TransportResponseHandler<PreVoteResponse>() {
在prevote流程中节点会向所有discoveredNodes发送REQUEST_PRE_VOTE_ACTION_NAME请求,等待discoveredNodes的response并调用handlePreVoteResponse()处理。discoveredNodes在收到PreVoteRequest后会调用handlePreVoteRequest来处理。
handlePreVoteRequest()的处理逻辑如下:
更新MaxTermSeen:updateMaxTermSeen.accept(request.getCurrentTerm()); 判断leader是否为空,如果为空则直接返回response 判断发起PreVoteRequest的节点是否是leader,如果是则直接返回response 如果集群存在leader,并且这个leader不是发起PreVoteRequest的节点,则抛出异常:拒绝PreVoteRequest请求,因为集群中已存在leader
private PreVoteResponse handlePreVoteRequest(final PreVoteRequest request) {
updateMaxTermSeen.accept(request.getCurrentTerm());
Tuple<DiscoveryNode, PreVoteResponse> state = this.state;
assert state != null : "received pre-vote request before fully initialised";
final DiscoveryNode leader = state.v1();
final PreVoteResponse response = state.v2();
if (leader == null) {
return response;
}
if (leader.equals(request.getSourceNode())) {
// This is a _rare_ case where our leader has detected a failure and stepped down, but we are still a follower. It's possible
// that the leader lost its quorum, but while we're still a follower we will not offer joins to any other node so there is no
// major drawback in offering a join to our old leader. The advantage of this is that it makes it slightly more likely that the
// leader won't change, and also that its re-election will happen more quickly than if it had to wait for a quorum of followers
// to also detect its failure.
return response;
}
throw new CoordinationStateRejectedException("rejecting " + request + " as there is already a leader");
}
handlePreVoteResponse()的处理逻辑如下:
更新MaxTermSeen:updateMaxTermSeen.accept(response.getCurrentTerm()); 如果满足以下两种情况之一,则忽略该response: response中lastAcceptedTerm大于clusterState中的term response中lastAcceptedTerm 等于clusterState中的term并且response中lastAcceptedVersion大于clusterState中的version 节点接收所有没有被忽略的response 节点根据接收到的response来构造Join(选票) 调用electionStrategy.isElectionQuorum()判断选票是否达到大多数,如果没有则直接返回 根据electionStarted来判断选举是否已经开始,如果已经开始则直接返回 调用startElection.run()来发起选举
handlePreVoteResponse()的核心代码如下:
updateMaxTermSeen.accept(response.getCurrentTerm());
if (response.getLastAcceptedTerm() > clusterState.term()
|| (response.getLastAcceptedTerm() == clusterState.term()
&& response.getLastAcceptedVersion() > clusterState.getVersionOrMetaDataVersion())) {
logger.debug("{} ignoring {} from {} as it is fresher", this, response, sender);
return;
}
preVotesReceived.put(sender, response);
// create a fake VoteCollection based on the pre-votes and check if there is an election quorum
final VoteCollection voteCollection = new VoteCollection();
final DiscoveryNode localNode = clusterState.nodes().getLocalNode();
final PreVoteResponse localPreVoteResponse = getPreVoteResponse();
preVotesReceived.forEach((node, preVoteResponse) -> voteCollection.addJoinVote(
new Join(node, localNode, preVoteResponse.getCurrentTerm(),
preVoteResponse.getLastAcceptedTerm(), preVoteResponse.getLastAcceptedVersion())));
if (electionStrategy.isElectionQuorum(clusterState.nodes().getLocalNode(), localPreVoteResponse.getCurrentTerm(),
localPreVoteResponse.getLastAcceptedTerm(), localPreVoteResponse.getLastAcceptedVersion(),
clusterState.getLastCommittedConfiguration(), clusterState.getLastAcceptedConfiguration(), voteCollection) == false) {
logger.debug("{} added {} from {}, no quorum yet", this, response, sender);
return;
}
if (electionStarted.compareAndSet(false, true) == false) {
logger.debug("{} added {} from {} but election has already started", this, response, sender);
return;
}
logger.debug("{} added {} from {}, starting election", this, response, sender);
startElection.run();
(3)正式选举
正式选举流程可以用下图来描述:
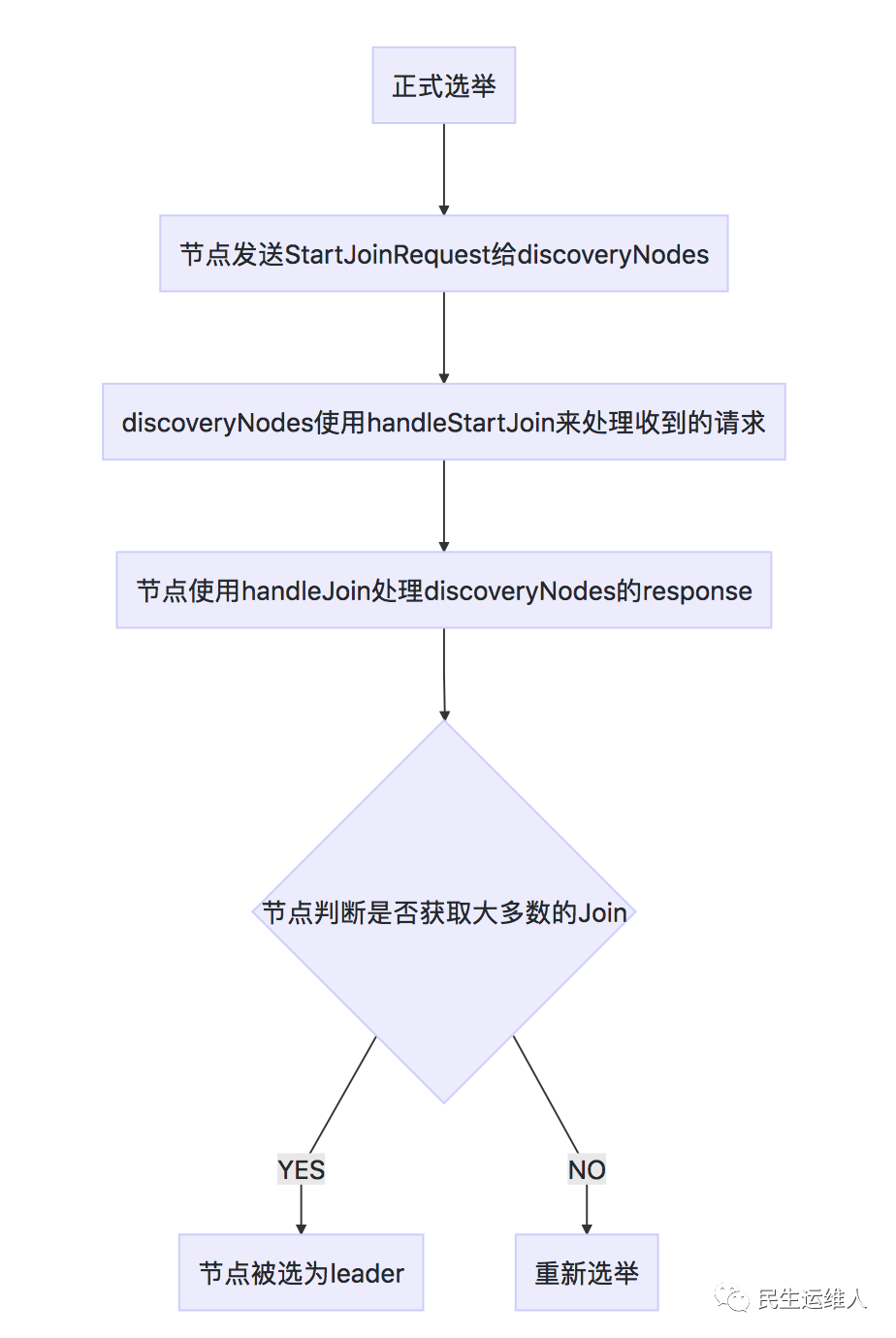
在进行正式选举时,节点会构造StartJoinRequest,并将该请求发送给discoveredNodes,请求中的term的值取节点当前 term 与maxTermSeen的最大值并加1。该节点的discoveredNodes 在接收到StartJoinRequest后会使用handleStartJoin(StartJoinRequest startJoinRequest)方法来处理该请求:如果StartJoinRequest中的term大于discoveredNodes的currentTerm,就会构造Join来为节点投票。
核心代码如下:
final StartJoinRequest startJoinRequest = new StartJoinRequest(getLocalNode(), Math.max(getCurrentTerm(), maxTermSeen) + 1);
logger.debug("starting election with {}", startJoinRequest);
getDiscoveredNodes().forEach(node -> {
if (isZen1Node(node) == false) {
joinHelper.sendStartJoinRequest(startJoinRequest, node);
}
});
public Join handleStartJoin(StartJoinRequest startJoinRequest) {
if (startJoinRequest.getTerm() <= getCurrentTerm()) {
logger.debug("handleStartJoin: ignoring [{}] as term provided is not greater than current term [{}]",
startJoinRequest, getCurrentTerm());
throw new CoordinationStateRejectedException("incoming term " + startJoinRequest.getTerm() +
" not greater than current term " + getCurrentTerm());
}
logger.debug("handleStartJoin: leaving term [{}] due to {}", getCurrentTerm(), startJoinRequest);
if (joinVotes.isEmpty() == false) {
final String reason;
if (electionWon == false) {
reason = "failed election";
} else if (startJoinRequest.getSourceNode().equals(localNode)) {
reason = "bumping term";
} else {
reason = "standing down as leader";
}
logger.debug("handleStartJoin: discarding {}: {}", joinVotes, reason);
}
persistedState.setCurrentTerm(startJoinRequest.getTerm());
assert getCurrentTerm() == startJoinRequest.getTerm();
lastPublishedVersion = 0;
lastPublishedConfiguration = getLastAcceptedConfiguration();
startedJoinSinceLastReboot = true;
electionWon = false;
joinVotes = new VoteCollection();
publishVotes = new VoteCollection();
return new Join(localNode, startJoinRequest.getSourceNode(), getCurrentTerm(), getLastAcceptedTerm(),
getLastAcceptedVersionOrMetaDataVersion());
}
当节点收到选票后会使用handleJoin()方法来处理,具体处理逻辑如下:
判断选民返回的投票(Join)中的term与当前节点的term的是否相等,如果不相等则会抛出CoordinationStateRejectedException( “incoming term does not match current term ” ),拒绝将选票添加 判断startedJoinSinceLastReboot是否为false,这个场景是指在节点reboot后term没有增加,当startedJoinSinceLastReboot为false时,抛出CoordinationStateRejectedException(“ignored join as term has not been incremented yet after reboot”),拒绝将选票添加 判断选民返回的投票(Join)中的lastAcceptedTerm与当前节点的lastAcceptedTerm的关系,如果前者大于后者,则抛出异常CoordinationStateRejectedException,拒绝将选票添加 如果选民返回的投票(Join)中的lastAcceptedTerm与当前节点的lastAcceptedTerm相等,但是Join中的lastAcceptedVersion大于当前节点的lastAcceptedVersion,则抛出CoordinationStateRejectedException并拒绝将选票添加 判断节点的lastAcceptedConfiguration是否为空,如果为空则抛出CoordinationStateRejectedException 将该选票添加到joinVotes中 判断是否到达法定人数
public boolean handleJoin(Join join) {
assert join.targetMatches(localNode) : "handling join " + join + " for the wrong node " + localNode;
if (join.getTerm() != getCurrentTerm()) {
logger.debug("handleJoin: ignored join due to term mismatch (expected: [{}], actual: [{}])",
getCurrentTerm(), join.getTerm());
throw new CoordinationStateRejectedException(
"incoming term " + join.getTerm() + " does not match current term " + getCurrentTerm());
}
if (startedJoinSinceLastReboot == false) {
logger.debug("handleJoin: ignored join as term was not incremented yet after reboot");
throw new CoordinationStateRejectedException("ignored join as term has not been incremented yet after reboot");
}
final long lastAcceptedTerm = getLastAcceptedTerm();
if (join.getLastAcceptedTerm() > lastAcceptedTerm) {
logger.debug("handleJoin: ignored join as joiner has a better last accepted term (expected: <=[{}], actual: [{}])",
lastAcceptedTerm, join.getLastAcceptedTerm());
throw new CoordinationStateRejectedException("incoming last accepted term " + join.getLastAcceptedTerm() +
" of join higher than current last accepted term " + lastAcceptedTerm);
}
if (join.getLastAcceptedTerm() == lastAcceptedTerm && join.getLastAcceptedVersion() > getLastAcceptedVersionOrMetaDataVersion()) {
logger.debug(
"handleJoin: ignored join as joiner has a better last accepted version (expected: <=[{}], actual: [{}]) in term {}",
getLastAcceptedVersionOrMetaDataVersion(), join.getLastAcceptedVersion(), lastAcceptedTerm);
throw new CoordinationStateRejectedException("incoming last accepted version " + join.getLastAcceptedVersion() +
" of join higher than current last accepted version " + getLastAcceptedVersionOrMetaDataVersion()
+ " in term " + lastAcceptedTerm);
}
if (getLastAcceptedConfiguration().isEmpty()) {
// We do not check for an election won on setting the initial configuration, so it would be possible to end up in a state where
// we have enough join votes to have won the election immediately on setting the initial configuration. It'd be quite
// complicated to restore all the appropriate invariants when setting the initial configuration (it's not just electionWon)
// so instead we just reject join votes received prior to receiving the initial configuration.
logger.debug("handleJoin: rejecting join since this node has not received its initial configuration yet");
throw new CoordinationStateRejectedException("rejecting join since this node has not received its initial configuration yet");
}
boolean added = joinVotes.addJoinVote(join);
boolean prevElectionWon = electionWon;
electionWon = isElectionQuorum(joinVotes);
assert !prevElectionWon || electionWon : // we cannot go from won to not won
"locaNode= " + localNode + ", join=" + join + ", joinVotes=" + joinVotes;
logger.debug("handleJoin: added join {} from [{}] for election, electionWon={} lastAcceptedTerm={} lastAcceptedVersion={}", join,
join.getSourceNode(), electionWon, lastAcceptedTerm, getLastAcceptedVersion());
if (electionWon && prevElectionWon == false) {
logger.debug("handleJoin: election won in term [{}] with {}", getCurrentTerm(), joinVotes);
lastPublishedVersion = getLastAcceptedVersion();
}
return added;
}
最后processJoinRequest(JoinRequest joinRequest, JoinHelper.JoinCallback joinCallback)方法中当该节点收到多数的投票后会调用becomeLeader("handleJoinRequest")方法使得该节点的状态由candidate转换为leader。至此集群的master节点就选出来了。上述的核心代码如下:
private void processJoinRequest(JoinRequest joinRequest, JoinHelper.JoinCallback joinCallback) {
final Optional<Join> optionalJoin = joinRequest.getOptionalJoin();
synchronized (mutex) {
final CoordinationState coordState = coordinationState.get();
final boolean prevElectionWon = coordState.electionWon();
optionalJoin.ifPresent(this::handleJoin);
joinAccumulator.handleJoinRequest(joinRequest.getSourceNode(), joinCallback);
if (prevElectionWon == false && coordState.electionWon()) {
becomeLeader("handleJoinRequest");
}
}
}
上述描述的正常的选举流程,我们现在来考虑以下场景中如何选举?
当集群中有一个master-eligible节点已经启动并且已经成为leader后,如果有节点要加入当前的master,具体如何实现?这个主要是靠PeerFinder 实现,PeerFinder如果发现了一个 Master 节点,就会执行 onActiveMasterFound ,调用 joinLeaderInTerm构造一个选票,然后 sendJoinRequest加入现有集群。 整个集群重启与集群第一次启动有些类似,区别在于节点在启动的时候会从data目录加载集群的clusterstate 缩容master-eligible节点分为两种情况,一种是缩容的节点是当前集群的master节点,一种是master-eligible节点。如果是master节点,则当master节点下线后,集群中会有master-eligible节点发现当前没有master,然后该节点会使自己转换为candidate然后发起选举;如果是master-eligible节点则不会对当前集群有太多影响,除了会使得集群的state发生变化。
3.选举相关信息
(1)7.x版本中Elasticsearch节点类型分为以下四种类型,选举流程主要是针对master-eligible node
master-eligible node:节点具有被选为master node的资格并且该节点的配置文件中node.master需要设置为true
(2)在7.x中引入了FollowersChecker和LeaderChecker。FollowersChecker的作用是:Leader检查follower是否可以连接及follower是否healthy。当发现follower failed后会将其从集群中删除。默认检查的频率是1s。LeaderChecker的作用是:Follower检查leader是否可以连接及leader是否healthy。
(3)在7.x版本中在配置文件中新增了cluster.initial_master_nodes配置选项,该选项必须进行配置,集群在第一次集群过程中会检查该项配置。具体如何进行配置可以参考官方链接:
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/discovery-settings.html#initial_master_nodes https://www.elastic.co/guide/en/elasticsearch/reference/7.4/modules-discovery-settings.html
public static boolean discoveryIsConfigured(Settings settings) {
return Stream.of(DISCOVERY_SEED_PROVIDERS_SETTING, LEGACY_DISCOVERY_HOSTS_PROVIDER_SETTING,
DISCOVERY_SEED_HOSTS_SETTING, LEGACY_DISCOVERY_ZEN_PING_UNICAST_HOSTS_SETTING,
INITIAL_MASTER_NODES_SETTING).anyMatch(s -> s.exists(settings));
}
(4)在集群的选举过程中会调用isElectionQuoum()方法来判断集群中的节点是否达到多数,其判断依据如下:
判断当前节点收到的投票的节点与lastCommittedConfiguration 中的节点取交集,交集中节点的个数是否大于lastCommittedConfiguration 节点个数的一半 判断 当前节点收到的投票的节点与lastAcceptedConfiguration中的节点取交集,交集中节点的个数是否大于lastAcceptedConfiguration节点个数的一半 如果前两项同样达到多数的要求则认为达到多数
核心代码如下:
/**
* Whether there is an election quorum from the point of view of the given local node under the provided voting configurations
*/
public final boolean isElectionQuorum(DiscoveryNode localNode, long localCurrentTerm, long localAcceptedTerm, long localAcceptedVersion,
VotingConfiguration lastCommittedConfiguration, VotingConfiguration lastAcceptedConfiguration,
VoteCollection joinVotes) {
return joinVotes.isQuorum(lastCommittedConfiguration) &&
joinVotes.isQuorum(lastAcceptedConfiguration) &&
satisfiesAdditionalQuorumConstraints(localNode, localCurrentTerm, localAcceptedTerm, localAcceptedVersion,
lastCommittedConfiguration, lastAcceptedConfiguration, joinVotes);
}
(5)在7.x版本中引入了coordination。cluster state的不一致会导致搜索结果不一致和数据丢失,引入coordination就是为了避免这种不一致。原来在老版本中错误的配置minimum_master_nodes是导致集群状态不一致的最常见原因之一。官方链接:
https://github.com/elastic/elasticsearch/issues/32006
(6)在Elasticsearch中有个很重要的类ElectionScheduler,它在集群中没有master时,负责随机调度选举,在出现故障时及时退出,可以在快速选举主节点以及多个node发起选举中平衡。
private static final String ELECTION_INITIAL_TIMEOUT_SETTING_KEY = "cluster.election.initial_timeout";
private static final String ELECTION_BACK_OFF_TIME_SETTING_KEY = "cluster.election.back_off_time";
private static final String ELECTION_MAX_TIMEOUT_SETTING_KEY = "cluster.election.max_timeout";
private static final String ELECTION_DURATION_SETTING_KEY = "cluster.election.duration";
/*
* The first election is scheduled to occur a random number of milliseconds after the scheduler is started, where the random number of
* milliseconds is chosen uniformly from
*
* (0, min(ELECTION_INITIAL_TIMEOUT_SETTING, ELECTION_MAX_TIMEOUT_SETTING)]
*
* For `n > 1`, the `n`th election is scheduled to occur a random number of milliseconds after the `n - 1`th election, where the random
* number of milliseconds is chosen uniformly from
*
* (0, min(ELECTION_INITIAL_TIMEOUT_SETTING + (n-1) * ELECTION_BACK_OFF_TIME_SETTING, ELECTION_MAX_TIMEOUT_SETTING)]
*
* Each election lasts up to ELECTION_DURATION_SETTING.
*/
public static final Setting<TimeValue> ELECTION_INITIAL_TIMEOUT_SETTING = Setting.timeSetting(ELECTION_INITIAL_TIMEOUT_SETTING_KEY,
TimeValue.timeValueMillis(100), TimeValue.timeValueMillis(1), TimeValue.timeValueSeconds(10), Property.NodeScope);
public static final Setting<TimeValue> ELECTION_BACK_OFF_TIME_SETTING = Setting.timeSetting(ELECTION_BACK_OFF_TIME_SETTING_KEY,
TimeValue.timeValueMillis(100), TimeValue.timeValueMillis(1), TimeValue.timeValueSeconds(60), Property.NodeScope);
public static final Setting<TimeValue> ELECTION_MAX_TIMEOUT_SETTING = Setting.timeSetting(ELECTION_MAX_TIMEOUT_SETTING_KEY,
TimeValue.timeValueSeconds(10), TimeValue.timeValueMillis(200), TimeValue.timeValueSeconds(300), Property.NodeScope);
public static final Setting<TimeValue> ELECTION_DURATION_SETTING = Setting.timeSetting(ELECTION_DURATION_SETTING_KEY,
TimeValue.timeValueMillis(500), TimeValue.timeValueMillis(1), TimeValue.timeValueSeconds(300), Property.NodeScope);
(7)在Elasticsearch中Coordinator定义了节点的三种状态:candidate, leader, follower,JoinHelper中包含了有关处理join的方法
(8)在7.x版本中引入了voting configuration,它其实是master-eligible nodes的集合,在选举新的master或者发布新的cluster state需要做出决策时,会对这些节点的响应进行计算,官方链接:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery-quorums.html
(9)Elasticsearch中的核心算法的模型可以参照:https://github.com/elastic/elasticsearch-formal-models
孙玺
中国民生银行信息科技部开源软件支持组工程师,目前主要负责与elasticsearch相关的大数据方面的工作。
