




1、问题背景
早期Elasticsearch版本在数据存在以下问题:
在发生节点异常后,即使异常持续的时间很短,异常节点数据与正常数据的差异很小,仍然需要基于文件全量将数据从正常节点同步到异常节点,导致异常节点恢复时间过程较长 数据在主分片写入后需要复制到副本分片,在这期间数据主分片有可能发生异常,导致主分片发生切换,但是原有的主分片仍然可能向副本分片发出数据操作请求(发生网络分区的情况下),导致旧的数据操作(来自于旧的主分片)有可能覆盖新的数据操作(来自于新的主分片) 在分布式的并发环境下,由于没有顺序地记录数据变化的过程,导致无法实现复杂的数据复制功能(Change API、Reindexing API)
2、解决方案
为了解决这些问题,最主要的是需要记录每次数据操作顺序情况。虽然早期版本通过version可以记录每条记录的变化情况,但是不能体现每个操作的发生顺序。同时需要考虑到在各种异常场景下(服务器重启、网络异常、硬件故障、Java长时间GC、软件升级等),仍然能够正常地、一致地记录、恢复这些操作到一致点。由此Elasticsearch引入了以下设计:
Sequence Number:在数据的主分片上会分配一个唯一的、递增的序号,用于记录数据更新的情况,每次数据更新后都会自动增加,保证新的数据更新一定会比旧的数据更新获得更大的Sequence Number Term:在数据的主分片上分配一个递增的序号,用于记录数据主分片是否发生切换,当主分片发生切换时会自动增加,保证拥有较大term的分片一定是较新的主分片。每个分片最新的term计数存储在cluster state元数据中。该设计类似于Raft中的term、Zab中的epoch、Viewstamped Replication中的view-number Local checkpoint:在节点本地已完成数据处理的最低Sequence Number,然后取最大的一个值,确保在本地节点上所有低于该值的数据操作都是已经全部完成了的 Global checkpoint:在所有的主副本分片上都已经完成数据处理的最大Sequence Number,确保在数据所有的主副本分片上低于该值的数据操作都是已经完成了的。该数据根据各个数据副本所反馈的Local checkpoint在主分片上生成,并随下一次数据复制同步到各数据副本 Translog:记录数据变化的情况,每个数据分片有一个translog,变化的数据首先写入内存中的lucene结构,写入成功后再写入translog。用于在数据恢复、数据复制中可以根据记录恢复数据到一致点
下面通过一个动画来具体说明该设计是如何应用的:
在term 1,主分片上发生了数据更新seq 0 本地的更新操作完成后被复制到副本1和副本2
主分片上的local checkpoint更新至seq 0 同时副本1和副本2的local checkpoint也更新至seq 0,并向主分片反馈local checkpoint的更新情况(seq 0)
在term 1,主分片上发生了数据更新seq 1 本地的更新操作完成后被复制到副本1和副本2,同时将global checkpoint更新至seq 0,该信息随数据复制操作被更新到副本1和副本2 各副本的local checkpoint更新至seq 1,并向主分片反馈local checkpoint的更新情况(seq 1)
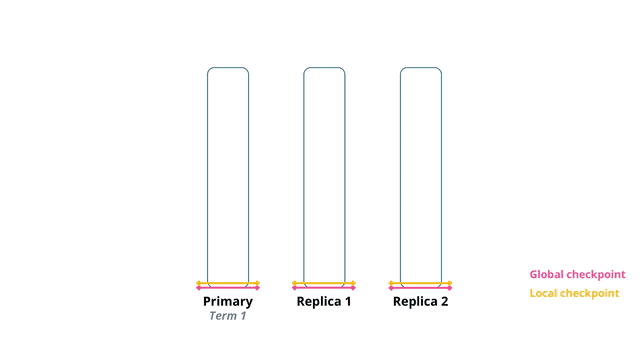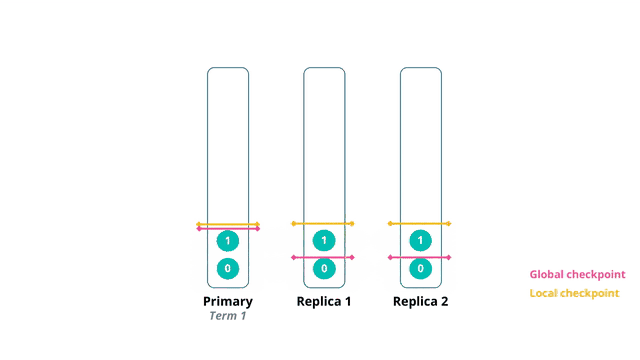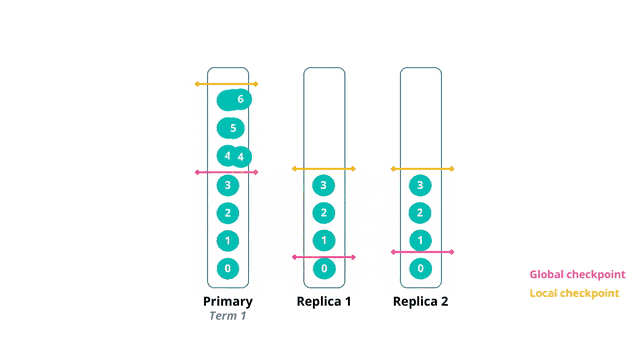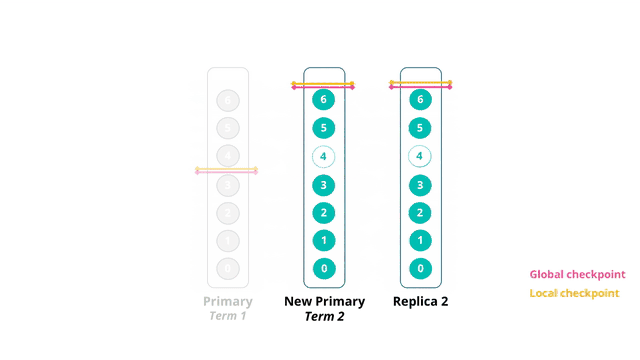
在term 1,主分片上发生了数据更新seq 2和3 本地的更新操作完成后被复制到副本1和副本2,同时将global checkpoint更新至seq 1,该信息随数据复制操作被更新到副本1和副本2 但副本1和副本2接受到的数据顺序有差异:副本1先接收到seq 2,local checkpoint更新至seq 2;副本2先接收到seq 3,由于seq 2未处理,因此local checkpoint暂未更新 后续副本1接收到seq 3,副本2接收到seq2,则local checkpoint都更新到seq 3,并向主分片反馈local checkpoint的更新情况(seq 3)
在term 1,主分片上发生了数据更新seq 4、5和6 本地的更新操作完成后被复制到副本1和副本2,同时将global checkpoint更新至seq 3,该信息随数据复制操作被更新到副本1和副本2 主分片的local checkpoint更新至seq 6 seq 5和6被复制到了副本1,local checkpoint暂未更新;seq 4和6被复制到了副本2,local checkpoint更新至seq 4 这时主分片发生了异常,导致主分片切换到原副本1,同时term更新为2。
在term 2,新的主分片local checkpoint更新至seq 6 新的主分片将数据更新seq 5和6复制到了原副本2,同时覆盖掉了原副本2上的数据更新seq 4 副本分片更新local checkpoint至seq 6,并向主分片反馈local checkpoint的更新情况(seq 6) 在后续的数据更新中global checkpoint也更新至seq 6
这时即使原主分片恢复正常,但由于其拥有的term较低,其他的数据分片不会接受其发出的数据写入请求,不会发生旧数据覆盖新数据的问题 同时其发现有比自身term更高的主分片出现后,会自动转换自身角色为副本分片,接受新主分片的数据同步请求 从新的主分片同步自异常前最后一个global checkpoint以来的数据变化,完成分片恢复过程,最终所有数据副本重新达到一致状态
下面通过实际操作来演示数据操作的变化过程:
1.1 产生第一条数据
PUT test/_doc/1
{
"col1":1
}
1.2 返回,同时返回_seq_no,_primary_term
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
2.1 修改同一条数据
PUT test/_doc/1
{
"col1":11
}
2.2 返回,成功更新。注意_seq_no,_version均发生变化,由于主分片未发生变化,因此_primary_term未变
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
3.1 在指定seq_no及primary_term的情况下再次修改数据
PUT test/_doc/1?if_seq_no=1&if_primary_term=1
{
"col1":111
}
3.2 返回,成功更新。注意_seq_no,_version均发生变化,由于主分片未发生变化,因此_primary_term未变
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
4.1 仍然使用前面的修改语句进行操作
PUT test/_doc/1?if_seq_no=1&if_primary_term=1
{
"col1":1111
}
4.2 返回错误,更新失败,发生写入冲突,因为上一次操作后seqNo已经更新至2,而本次提交seqNo的仍为1,因此写入操作被拒绝
{
"error" : {
"root_cause" : [
{
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, required seqNo [1], primary term [1]. current document has seqNo [2] and primary term [1]",
"index_uuid" : "XcT0zdVjSoWtcooht9EoNA",
"shard" : "0",
"index" : "test"
}
],
"type" : "version_conflict_engine_exception",
"reason" : "[1]: version conflict, required seqNo [1], primary term [1]. current document has seqNo [2] and primary term [1]",
"index_uuid" : "XcT0zdVjSoWtcooht9EoNA",
"shard" : "0",
"index" : "test"
},
"status" : 409
}
5.1 检查全部的数据情况:
GET test/_search
{
"seq_no_primary_term":true
}
5.2 返回,在设置seq_no_primary_term为true的情况下返回信息包含_seq_no及_primary_term
{
"took" : 453,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_seq_no" : 2,
"_primary_term" : 1,
"_score" : 1.0,
"_source" : {
"col1" : 111
}
}
]
}
}
6.1 检查数据的元数据情况:
GET _cluster/state?filter_path=**metadata.indices.test
6.2 返回,当数据的主分片发生切换时,primary_terms会增加
{
"metadata" : {
"indices" : {
"test" : {
"version" : 5,
"mapping_version" : 2,
"settings_version" : 1,
"aliases_version" : 1,
"routing_num_shards" : 1024,
"state" : "open",
"settings" : {
"index" : {
"creation_date" : "1596856892760",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "XcT0zdVjSoWtcooht9EoNA",
"version" : {
"created" : "7080199"
},
"provided_name" : "test"
}
},
"mappings" : {
"_doc" : {
"properties" : {
"col1" : {
"type" : "long"
}
}
}
},
"aliases" : [ ],
"primary_terms" : {
"0" : 1
},
"in_sync_allocations" : {
"0" : [
"VB08Ya0CRdKzuhvLyPtgqw",
"AKb9HqfdTBSRP0dSEGuf5w"
]
},
"rollover_info" : { }
}
}
}
}
3、方案优势
快速数据恢复
采用上述设计方案,当发生数据分片由于故障需要恢复的时候,不再完全需要进行全量文件的复制恢复,只需要找到故障分片最后一个global checkpoint(在该点之前所有的数据操作在所有数据分片上都已经是一致的,无需进行再处理),以此为起点将新主分片上之后发生的差异数据同步过来就可以完成全部的数据恢复(数据的差异信息来源于新主分片上的translog),达到数据一致点,整个恢复过程所需的工作量极大减少,数据恢复所需的时间也极大缩短。 只有当translog中记录的数据太多或者时间太久,导致通过逐条数据恢复的代价太大,在这种情况下引擎仍然会选用旧的文件同步的机制完成数据恢复。
远程数据复制
由于我们已经顺序地记录了完整的数据变化信息,因此也使远程数据复制的功能可以实现。我们可以获知每个数据分片需要进行数据复制的起点位置,同时可以通过translog顺序地在远程进行数据的重演。在复制过程中如果出现异常,也可以从正确的位置重新开始。
4、附录
https://www.elastic.co/blog/elasticsearch-sequence-ids-6-0[1]
https://github.com/elastic/elasticsearch/blob/master/docs/reference/docs/concurrency-control.asciidoc[2]
https://github.com/elastic/elasticsearch/issues/10708[3]
詹玉林
中国民生银行信息科技部开源软件支持组工程师。曾经担任过银行核心系统开发工程师,IBM informix数据库L2支持工程师,民生银行数据库DBA等角色。目前主要负责与elasticsearch相关的大数据方面的工作。

参考资料
https://www.elastic.co/blog/elasticsearch-sequence-ids-6-0: https://www.elastic.co/blog/elasticsearch-sequence-ids-6-0
[2]https://github.com/elastic/elasticsearch/blob/master/docs/reference/docs/concurrency-control.asciidoc: https://github.com/elastic/elasticsearch/blob/master/docs/reference/docs/concurrency-control.asciidoc
[3]https://github.com/elastic/elasticsearch/issues/10708: https://github.com/elastic/elasticsearch/issues/10708
