




哪怕已经发展了50年,SQL还是那么重要!
大数据领域,说是“万物皆可SQL化”也不为过。
而由此催生出的SQL on Hadoop系统,更是所有大数据引擎中的一个超级大类,Hive、Spark SQL、Presto、Impala等都包括在内。
大家都知道,稳和快,是衡量大数据可用性的重要指标。而要保证这两个指标,系统的性能是关键,其中做好SQL的优化,更是关键中的关键。
但遗憾的是,很多小伙伴只是掌握了怎么写好SQL,或者掌握了一些优化规则、参数,但却始终停留在“怎么用”的层面,对SQL的执行流程和优化原理没有认知,也不了解那些优化规则、参数背后的逻辑所在。
也就始终没法形成自己的技术壁垒,遇到的问题稍稍变换一下题型,就抓瞎了,“大数据人肉运维”的苦,真是谁做谁知道……
那怎么打破这样的困境呢?
给你推荐一个超级干货的体验课“SQL解析和优化实践”,用三节课,带你从原理到实践,从Spark SQL入手,吃透通用SQL的执行流程和优化原理。
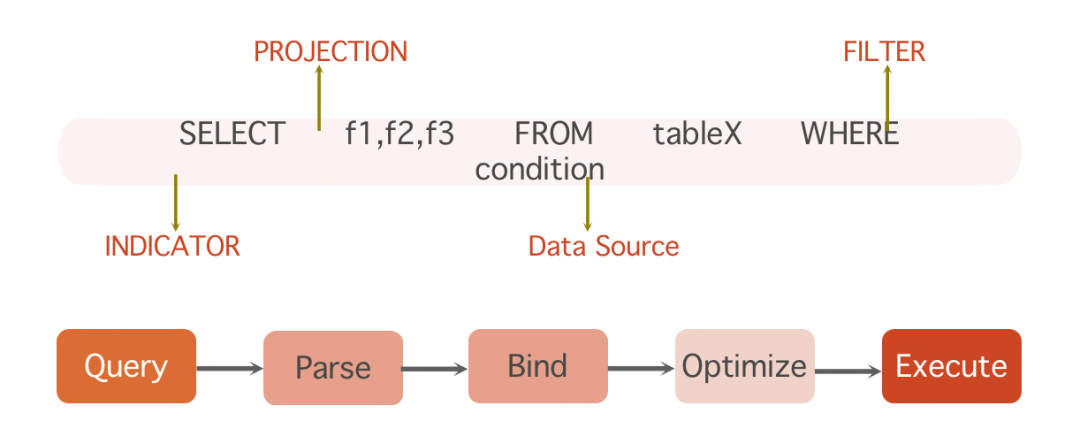
毕竟在所有的主流引擎中,Spark SQL对SQL的优化是做得最深、最好的!
可以说,只要掌握Spark SQL相关的优化原理与实践,其他各类SQL基本上就是手到擒来,稍微花点心思就能融会贯通。
而在第三节课中,老师更是会拔高一层,从Flink、Hive、Kylin等主流引擎的SQL优化挑战讲起,带大家站到更普适的角度,吃透SQL的通用优化思路,掌握通用工具Calcite的原理和实践。
这一套组合拳下来,不论你实际工作中用的是啥引擎,遇到再复杂的问题,也能轻松做好优化,让系统更稳、更快!
对了,这个体验的主讲老师是前eBay中国资深大数据专家金澜涛,还是复旦大学MSE外聘教师,不仅技术牛,讲课也厉害,复杂的技术也能带你轻松掌握。
限时特惠只要¥0.99 👇

好内容不容错过,扫码立即报名

添加学习助理
获取优惠报名链接和配套课件
📢课程有效期7天,报名后尽快学习
📢本专题不适合学生群体
如有相关编程经验可酌情考虑
现在报名,另加赠一套程序员提升书单,从工具到框架到实战到方法论,全都囊括,全方面助你提升技术水平~

金澜涛老师的这个提升课,可以说是从Spark SQL入手,给你把通用SQL的执行流程和优化原理及相关工具、实践都讲透了,口说无凭,咱可以看看大纲感受一下~

最后想跟大家多唠几句,大规模的数据往往意味着大规模的问题,从事大数据方向,平时遇到的问题会很多,如果没有掌握核心竞争力,只是浮于表面或者单纯遇到问题解决问题,往往会把自己逼得非常累,被动陷入“内卷”。
这是我们一定要避免的,平时的工作、学习中一定要多问几个为什么,多去探寻技术背后的本质~
共勉~
好内容不容错过,扫码立即报名
限时特惠¥0.99!!!
获取优惠报名链接和配套课件
📢课程有效期7天,报名后尽快学习
📢本专题不适合学生群体
如有相关编程经验可酌情考虑
