





黄玮(Fuyuncat)
资深Oracle DBA,个人网站www.HelloDBA.com,致力于数据库底层技术的研究,其作品获得广大同行的高度评价.
前期分享了ORA-01555错误的原理及相关基础概念。
参考(高频错误:ORA-01555深入剖析:https://www.modb.pro/db/4114)
今天我们来分析ORA-01555发生的场景和各种解决方案
测试环境
首先建立测试环境。由于我们只是要模拟1555错误的发生,所以需要建立一个小的回滚表空间,并且设置undo_retention时间为1(秒),以便回滚数据尽快被覆盖(呵呵,要防止1555错误发生,这就一定要避免的)。
开始读取表。
SQL> var cl refcursor
SQL> begin
open :cl for select * from demo.t_multiver;
end;
/
PL/SQL procedure successfully completed.
更新表数据,产生回滚信息。
SQL> update demo.t_multiver set b = 111 where a = 1;
1 row updated.
SQL> commit;
Commit complete.
运行大批其他事务,充满所有回滚段,以致覆盖上面的回滚信息。回滚段可以通过dba_rollback_segs查看。
SQL> begin
for i in 1..20000 loop
update demo.t_dual set dummy=1;
commit;
end loop;
end;
PL/SQL procedure successfully completed.
SQL>
PL/SQL procedure successfully completed.
查询到更新过的数据记录,回滚信息已经被覆盖,所以报1555错误。
SQL> print :cl
ERROR:
ORA-01555: snapshot too old: rollback segment number 18 with name "_SYSSMU18$"
too small
no rows selected
开始读取表
SQL> var cc refcursor
SQL>
SQL> begin
open :cc for select * from t_multiver;
end;
/
这时一个事务更新了该数据块,但在提交前,我们手工将buffer cache中的数据做了flush,再做提交。这时的数据块上只记录了锁标志,没有事务标志和Commit SCN。
PL/SQL procedure successfully completed.
SQL> update t_multiver set b=115 where a=1;
1 row updated.
SQL> alter system flush buffer_cache;
System altered;
SQL> commit;
Commit complete.
进行非常多的事务,将回滚段中的事务信息表中的数据全部覆盖:
SQL> begin
-- overwrite rollback slot
for i in 1..40000 loop
update t_dual set dummy=1;
commit;
end loop;
end;
/
PL/SQL procedure successfully completed.
读取数据块前需要到回滚段的事务信息表中读取Itl中没有标记完全的事务的状态和Commit SCN,以判断是否需要进行一致性读。但是事务信息表中的数据都已经被覆盖,所以报1555错误:
SQL> print :cc
ERROR:
ORA-01555: snapshot too old: rollback segment number 20 with name "_SYSSMU20$"
too small
no rows selected
以上两个例子看起来是好像很类似,但是,他们的本质区别是:第一个实际上是在进行一致性读得时候发生的1555错误,而第二个例子是在判断是否需要进行一致性读得时候发生的1555错误。
现在,我们已经知道了1555错误产生的原因。那么,就可以总结出以下方法来解决1555错误问题:
1、扩大回滚段
因为回滚段是循环使用的,如果回滚段足够大,那么那些被提交的数据信息就能保存足够长的时间是那些大事务完成一致性读取。
2、增加undo_retention时间
在undo_retention规定的时间内,任何其他事务都不能覆盖这些数据。
3、优化相关查询语句,减少一致性读
减少查询语句的一致性读,就降低读取不到回滚段数据的风险。这一点非常重要!
4、减少不必要的事务提交
提交的事务越少,产生的回滚段信息就越少。
5、对大事务指定回滚段
通过以下语句可以指定事务的回滚段:
SET TRANSACTION USE ROLLBACK SEGMENT rollback_segment;
给大事务指定回滚段,即降低大事务回滚信息覆盖其他事务的回滚信息的几率,又降低了他自身的回滚信息被覆盖的几率。大事务的存在,往往是1555错误产生的诱因。
6、使用游标时尽量使用显式游标,并且只在需要的时候打开游标,同时将所有可以在游标外做的操作从游标循环中拿出。
当游标打开时,查询就开始了,直到游标关闭。减少游标的打开时间,就减少了1555错误发生的几率。
下面例子中,第一段代码发生1555错误的几率就大于第二段的:
例子一
declare
cursor cl is select b from demo.t_multiver;
v_b number;
begin
open cl;
--do some thing without relation to the cursor.
fetch cl into v_b;
while cl%found loop
--do other things without relation to the cursor.
... ...
fetch cl into v_b;
end loop;
close cl;
commit;
END;
例子二:
declare
cursor cl is select * from demo.t_multiver;
begin
--do some thing without relation to the cursor.
--do other things without relation to the cursor.
open cl;
fetch cl into v_b;
while cl%found loop
... ...
fetch cl into v_b;
end loop;
close cl;
commit;
END;
7、使用回滚表空间自动管理
回滚表空间自动管理是9i后的特性。他由Oracle自动管理回滚段的创建和回收。尽管有人认为这一特性是以后牺牲性能为代价的,或者有其他缺点而不建议使用。但我认为,这确实是Oracle一个很好的特性,特别是OLTP环境下应该使用它。并且10g中,这一特性大大增强了。
而在大型的数据仓库或者报表系统中,会有一些很大的查询作业存在,这时可以考虑使用手动管理,为某些大作业创建单独的回滚段。
以上总结了解决1555错误的各种办法,具体采用哪种方式,就需要根据错误产生的实际情况来决定了。
实际上,你在了解了1555错误为什么会发生的前提,遇到了1555错误就不应该再手足无措了。但是,根据我个人的经验,大多数的1555错误的发生,其根本原因还是语句写得太烂,导致了大量的consistent gets和超长的执行时间,最后引发了1555错误。下面就是一个典型例子:
错误的发生
近来生产系统反馈,时常有作业被异常中止,导致应用程序被hung住。经过检查日志,是某个作业在运行时发生了1555错误,导致程序无法返回结果:

相关程序记录下的日志:

错误分析解决
这是一个典型的1555错误。检查引发该错误的PACKAGE,发现它只有一个入口函数main(及程序日志中记录的函数),但这个函数还调用了其他N个PACKAGE里面的函数。这是一个大作业,执行时,设置它使用了一个大的回滚段:RBS_BATCH1。
先看看相关配置:rollback tablespace空间为8G,undo_retention为1800。
看看回滚段的统计数据:

注意到RBS_BATCHT1的wait%是0.098%,这个值应该是比较好的一个值。
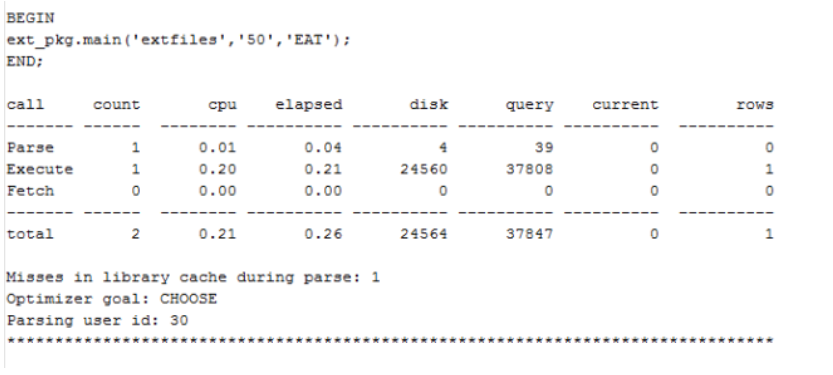
回过头再来看依法错误的语句:调用ext_pkg.main函数。在程序日志中已经记录下了输入参数,这就比较好办了:作一个trace,看看到底哪条语句的性能最差:

用tkprof处理trace文件后检查trace文件:
......
......

......

从trace文件中,发现有一条语句性能相当差,通过对这条语句做SQL Trace,发现它的consistent gets达到80万!
于是对该语句进行优化,调整了它的写法,并建立了缺少的索引(优化过程略)。最终将consistent gets数量降低到了5000。
重新安排上线,经过一周的观察,1555错误没再发生。
其实这个案例的解决是比较简单的,最终的处理就是将一条语句进行优化。
-------The End
