





从mysql同步ES看似简单的技术,但实际操作起来并没有想象的简单,我们基于canal对数据同步进行了全新的设计,以基于配置的方式,实现了数据库表变更无需二次开发的效果,极大地提升了数据同步效率。
from Atome Financial 首席技术官丁豪
日常业务中,我们常常会使用MySQL用做OLTP,同时将MySQL的数据同步到其他数据存储引擎支持OLAP业务。本文将探讨基于canal的通用型数据同步适配器对于MySQL到Elasticsearch的简单实现。
一般来说,同步数据的方式有以下几种:
代码双写,即在业务代码中同时写入MySQL和elasticsearch(同步或者异步)。优点是实现简单。缺点也很明显,容易造成代码冗杂和不必要的藕合,数据结构修改的开发和测试成本高。同时,数据一致性也不容易保证,比如偶尔的ad-hoc的sql update操作,需要额外的手工同步工作。
定时任务同步。优点是与OLTP业务解藕合,实现也比较简单。缺点是数据实时性不足,批量查询的SQL性能也常常遭遇挑战。
基于MySQL的增量binlog解析。解决了1和2的缺点,但是实现复杂度比较高。幸好,有不少开源工具帮助我们简化binlog的处理工作,其中代表是canal。
canal提供了比较简单易用的client API,可以很方便地使用这套API实现自己的数据同步业务。并且,canal还提供了一个基于配置的ES client adapter。然而可惜的是,对这个adatper稍微研究一下就会发现,它没有什么实用性,不大可能在生产环境中应用:不但有诸多的限制导致适配度不高,最致命的是性能比较差。在有关联表的情况下,每一条数据变更,子查询都要执行一次关联表的全表扫描。
Larry Wall有名言,程序员有三大美德,懒惰居首。为每一张业务表去写一堆同步代码,显然谁都不乐意去做这么一件枯燥乏味又容易出错的的事。但是想“偷懒”,就得自己实现一个可以“偷懒”的工具。
首先,考虑有如下表结构:
person(id, name, active tinyint, create_time)
person_age(person_id, age)
relative(id, person_id_1, person_id_2, relation)
job(person_id, employer, job_title, is_full_time tinyint)
event(id, person_id, event_name, create_time)
同步到elasticsearch之后,变成以下结构:

上面的例子基本覆盖了我们日常使用的多数场景:
1. 主表原有字段:原样复制,有时会有类型变更需求。
2. age字段:1:1关系,子表字段同步后做为主表的一个普通字段。
3. children字段:1:n关系,子表字段的列表作为主表的一个列表字段。
4. job字段:1:1关系,子表的一行数据作为主表的一个对象字段。
5. events字段:1:n关系,子表字段列表作为主表的一个列表对象字段。
6. 另外,上述字段中,有的字段可以直接从binlog的RowData里读取,有的字段需要经过一些计算语句获取到。
考虑到上述几点后,我们基本上可以将需求用yaml格式表达为如下:



有了上述结构定义,我们就可以开始代码实现了,这本身属于比较简单的事情。将上述yaml结构映射到spring boot支持的ConfigurationProperties类,剩下的就大部分是基于此的CRUD的工作。最主要的考虑是怎么尽量减少mysql的查询和elasticsearch的update操作,canal采用ROW模式拉取mysql binlog,CannalConnector又可以按批量拉取,根据此特点,合并多个相关联的ROW数据为一次操作,并利用elasticsearch的bulk接口,可以大大提升性能。
多线程不能作为考虑选项,因为binlog队列有着严格的先入先出顺序,多线程处理会造成数据混乱。另外因为无关具体业务,所以不需要hibernate或者mybatis这样的ORM支持,标准jdbc接口又过于刀耕火种,spring jdbc template成为一个理想的选择,适度封装,但无需太多高级功能。
另外值得一说的是CanalConnector接口有两类实现,一类是直接连接canal server的SimpleCanalConnector和ClusterCanalConnector,一类是通过kafka或者RocketMQ的CanalMQConnector,但是这两者之间是完全不兼容的,也就是说你绝无可能注入一个CanalConnector的bean而无需关心他是哪种实现。方便起⻅,我们干脆将他们封装一下再使用。
1. 先定义一个接口。考虑到我们使用的方式,只需要少量的几个方法就够了。目标是connect、subscribe、getList等方法由配置决定,对下游实现细节,提供统一无参的傻瓜式调用方法。

2. 直连canal server的实现:



kafka连接的实现:


3. Configuration根据配置决定使用哪种方式。

4. CanaClient。起一个while死循环,当收到shutdown信号时退出。

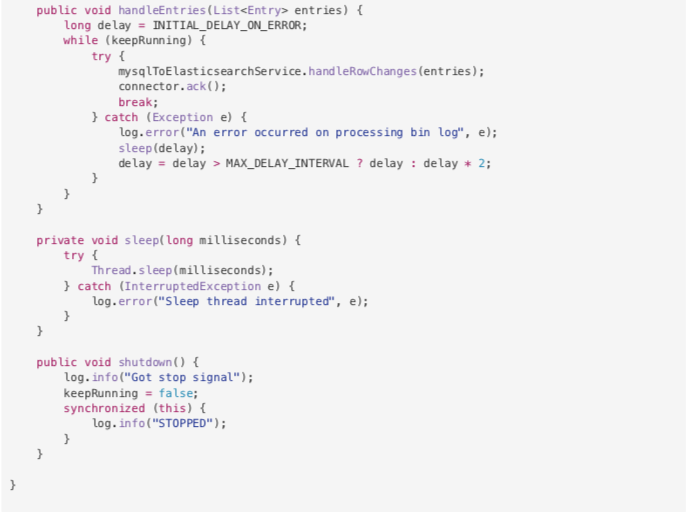
5. 启动类Main,添加一个ContextClosedEvent事件监听,让CanalClient可以优雅退出。

总结
以上,便是个人关于MySQL到Elasticsearch数据同步工具的一些想法和实践。我们已经在实际环境中应用了一段时间,面对日常的数据结构定义和变更,我们的开发精力已经从中解放了出来,小小的实现了write once, run anywhere的目标。当然,还有很多值得改进的地方,比如非SQL的普通计算表达式的支持。本文的代码已经上传至github:tristanchenxm/mysql-es-adapter,欢迎提出您的建议,轻拍。

