




作者:张栋,京东物流集团数据专家
京东集团 2007 年开始自建物流,2017 年 4 月正式成立京东物流集团,2021 年 5 月,京东物流于香港联交所主板上市。京东物流是中国领先的技术驱动的供应链解决方案及物流服务商,以“技术驱动,引领全球高效流通和可持续发展”为使命,致力于成为全球最值得信赖的供应链基础设施服务商。


除了以上问题,数据服务和数据分析系统也无法统一,分析产生的数据结果往往是离线的,需要额外开发数据服务,无法快速转化为线上服务赋能外部系统,使得分析和服务之间难以快速形成闭环。
而且在以往数据加工过程中存储往往只考虑了当时的需求,当后续需求场景扩展,最初的存储引擎可能不适用,导致一份数据针对不同的场景要存储到不同的存储引擎,带来数据一致性隐患和成本浪费问题。
基于以上业务痛点,京东物流运营数据产品团队研发了服务分析一体化平台——Udata。Udata 系统是以 StarRocks 引擎为技术基础实现的。Udata 把数据指标生成的过程抽象出来,用配置的方式低代码化生成数据服务,大大降低了开发复杂性和难度,让非研发同学也可以根据自己的需求配置和发布数据服务。指标的开发时间由之前的一两天缩短为 30 分钟,大大解放了研发力。
平台化的指标管理体系和数据地图的功能,让用户更加直观和方便地查找与维护指标,同时也让指标复用变成可能。在数据分析方面,我们用基于 StarRocks 的联邦查询方案打造了 Udata 统一查询引擎,解决了查询引擎不统一和数据孤岛问题。
同时 StarRocks 提供了强悍的数据查询性能,无论是大宽表还是多表关联查询性能都十分出色。StarRocks 提供数据实时摄入的能力和多种实时数据模型,可以很好支持数据实时更新场景。Udata 系统把分析和服务结合在一起,让分析和服务不再是分割的两个过程,用户分析出有价值的数据后可以立即生成对应的数据服务,让服务分析快速闭环。
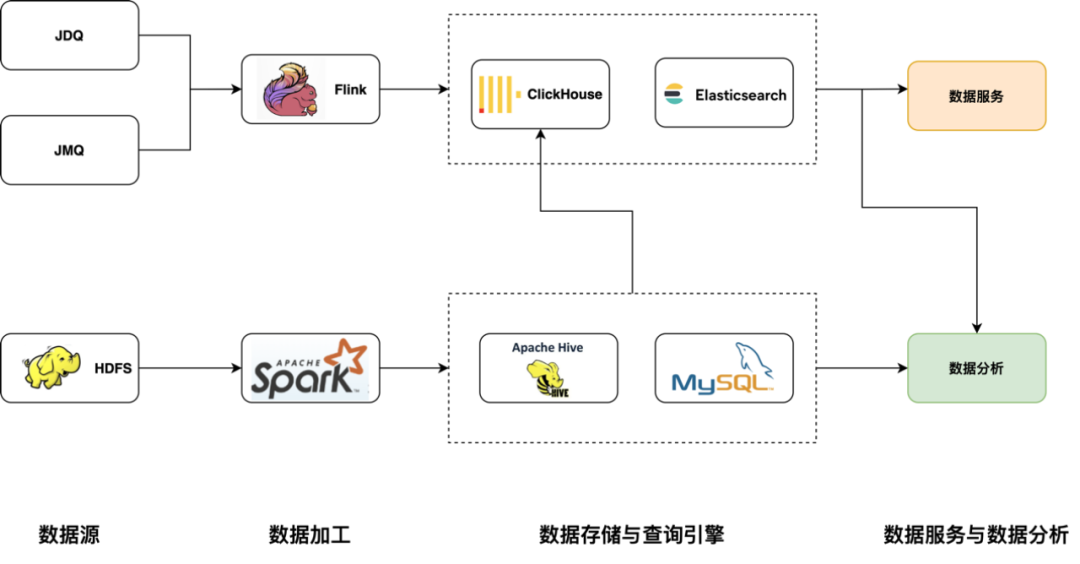

此架构中,在数据服务和数据分析是两个分隔的部分,分析工具由于要跨多数据源和不同的查询语言做数据分析比较困难的,数据服务也是烟囱式开发。
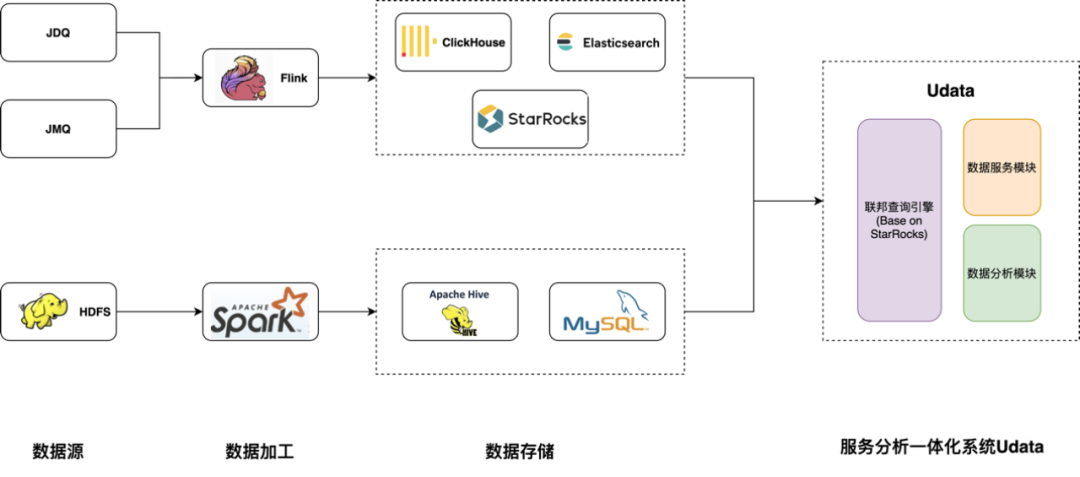

后面我们又以 StarRocks 为基础打造统一查询引擎。统一查询引擎根据京东的业务特点增加了数据源和聚合下推等功能,Udata 在统一查询引擎的基础上,统一了数据分析和数据服务功能。

4)自适应低基数优化:StarRocks 可以自适应地根据数据分布,对低基数的字符串类型的列构建一张全局字典,用 Int 类型做存储和查询,使得内存开销更小,有利于 SIMD 指令执行,加快了查询速度。ClickHouse 也有低基数优化,只是在建表时候需要声明,使用起来会麻烦一些。

StarRocks 在联邦查询上支持了多种外表如 ElasticSearch、MySQL、Hive、数据湖等,已经有了很好的联邦查询基础。不过在实际的业务场景中,一些聚合类查询需要从外部数据源拉取数据再聚合,加上这些数据源自身的聚合性能也不错,反而增加了查询时间。
MySQL、ElasticSearch 的聚合下推功能
现在 StarRocks 对于聚合外部数据源的方案是,拉取谓词下推后的全量数据。虽然谓词下推后已经过滤了一部分数据,但是把数据拉取到 StarRocks 再聚合是一个很重的操作,导致聚合时间不理想。我们选择下推聚合操作,让外部表引擎自己做聚合,节省数据拉取时间,同时本地化聚合效率更高。

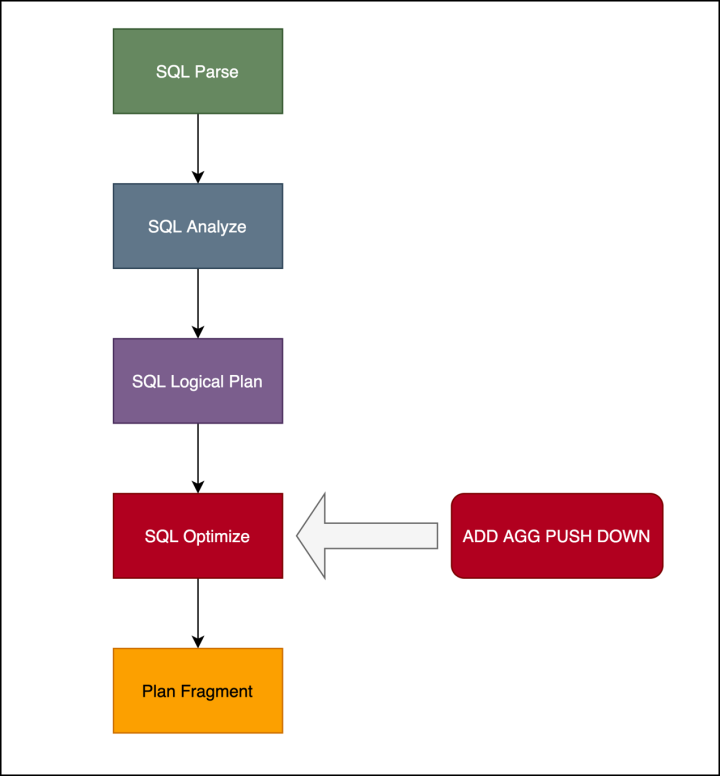
我们在步骤 4 中对生成的物理执行计划再次优化,当遇到 ElasticSearch 或者 MySQL 的聚合操作时,会把 ScanNode+AGGNode 的执行计划优化为 QueryNode。QueryNode 为一种特殊的ScanNode,与普通 ScanNode 的区别在于, QueryNode 会把聚合查询请求直接发送到对应外部引擎,而不是 Scan 数据后在本地执行聚合。
其中,用到 ElasticSearch QueryNode 时,我们会在 FE 端就生成 ElasticSearch 查询的 DSL 语句,直接下推到 BE 端查询 。同时在 BE 端,我们实现了 ElasticSearch QueryNode 和 MySQL QueryNode 这两种 QueryNode。我们也为这个 feature 设置了 agg_push_down 的开关,默认是关闭的。


增加 JSF(京东内部 RPC 服务)/ HTTP 数据源
数据服务中可能会涉及到整合外部数据服务和复用原先已开发指标的场景。我们的思路是,把JSF(京东内部 RPC 服务)/ HTTP 也抽象成 StarRocks 的外部表,用户可以通过 SQL 像查询数据库一样访问数据服务。

基于 ElasticSearch 的实时更新方案



基于 ClickHouse 实现准实时的方案






1)Merge on read :StarRocks 的聚合、Unique 模型和 ClickHouse 的ReplacingMergeTree、AggregatingMergeTree 都是用的此方案。此方案特点是 Append 方式写入性能好,但是查询时需要合并多版本数据,导致查询性能不佳。适合数据查询性能要求不高的实时分析场景。
2)Copy on write :目前一些数据湖系统如 Apache Hudi、Apache Iceberg 都有 Copy on write 的方案。此方案原理是,当有更新数据后,会合并新老数据并重写一份新的文件替换掉老文件,查询时无需做 Merge 操作,所以查询性能很好。带来的问题是,写入和合并数据的操作很重,所以此方案不适合实时性强的写入场景。
3)Delete and insert:此方案是 Upsert 方案,通过内存中的主键索引定位要更新的行,标记删除然后插入。在牺牲了部分写入性能的情况下,带来数倍于 Merge on read 的查询性能提升,同时也提升了并发性能。
实时更新在 OLAP 领域一直是一个技术难点,以往的解决方案很难同时具备写入性能好、读取性能好、使用简单这几个特性。StarRocks 的 Delete and insert 方式目前更接近于理想的方案,在读写方面都有很优秀的性能,在支持 MySQL 协议方面非常简单友好。同时 Udata 的离线分析也是用 StarRocks 完成,让京东物流实现了实时离线分析一体化的目标。
架构图如下:
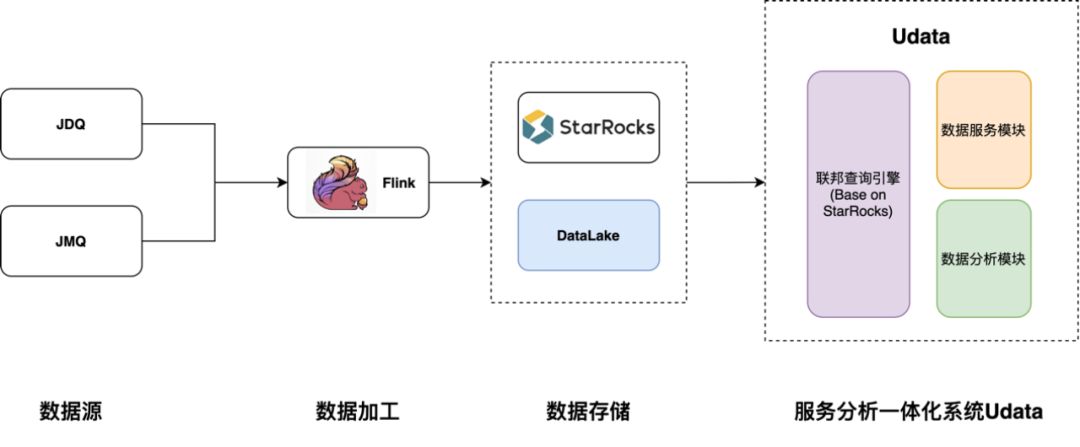
目前系统中有多套实时存储方案,运维成本还是相当高,我们会逐步把 ElasticSearch、ClickHouse 替换为 StarRocks,在实时层做到存储统一。我们也很期待 StarRocks 后期关于主键模型支持 Detele 语句方式删除数据的功能,从而可以解决目前的数据清除问题。
今后我们还会支持更多的数据源,如 Redis、Apache HBase 等 KV 类型的 NoSQL 数据库,增强 StarRocks 的点查能力。
后续我们也会和社区讨论如何实现集群间的联邦功能,如果有对此感兴趣的社区小伙伴也可以一起来参与共建。
StarRocks 在 2.2 版本开始推出资源组的功能,可以有效隔离大小查询负荷,后续还会在大查询熔断、导入和查询负荷资源隔离方面推出更多功能。因此,一些体量较小的业务混合在同一集群上通过资源隔离的形式运行,将成为可能。
StarRocks 是一款十分优秀的 OLAP 数据库产品,在社区小伙伴的帮助下,我们解决了很多技术难题。在这里感谢 StarRocks 社区,我们后续也会大力参与社区建设,并希望能有更多的小伙伴参与到 StarRocks 社区共建中来!




StarRocks 技术内幕:
